Nodejs notes
# (一)Node.js 初识
# 1. Node.js 诞生史
Node.js 之父:Ryan Dahl(瑞安・达尔)
- 并非科班出身的开发者,在 2004 年在纽约的罗彻斯特大学数学系读博士。
- 2006 年退学,来到智利的 Valparaiso 小镇。
- 期间曾熬夜做了一些不切实际的研究,例如如何通过云进行通信。
- 偶然的机会,走上了编程之路,生活方式变为接项目,然后去客户的地方工作。
- 工作中遇到了主流服务器的瓶颈问题,尝试着自己去解决,费尽周折没有办法。
- 2008 年 Google 公司 Chrome V8 引擎横空出世,JavaScript 脚本语言的执行效率得到质的提升,他的想法与 Chrome V8 引擎碰撞出激烈的火花。
- 2009 年的 2 月,按新的想法他提交了项目的第一行代码,这个项目的名字最终被定名为 “node”。
- 2009 年 5 月,正式向外界宣布他做的这个项目。
- 2009 年底,Ryan Dahl 在柏林举行的 JSConf EU 会议上发表关于 Node.js 的演讲,之后 Node.js 逐渐流行于世。
- Ryan Dahl 于 2010 年加入 Joyent 公司,全职负责 Node.js 项目的开发。此时 Node.js 项目已经从个人项目变成一个公司组织下的项目。
# 2. Node.js 是什么
Node.js 是一个基于 Chrome V8 引擎的 JavaScript 运行环境。
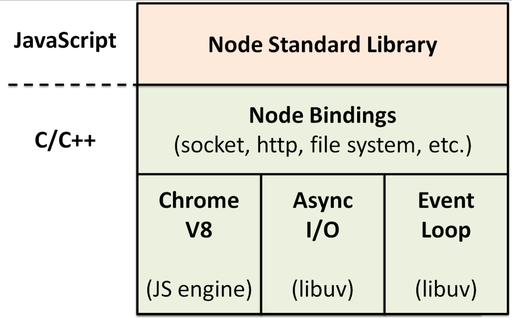
传统的 JavaScript 只能运行在浏览器端,脱离浏览器不能运行,也就不能操作本地的文件或者创建文件,也不能进行网络编程,Node.js 的出现打破了这一局面。
Node.js 编写的代码还是 JS,所以开发者需要利用 Chrome V8 来运行 JS。Node.js 借助了 C/C++ 中的 libuv 库来实现文件读取和事件循环。我们不必深挖其中的原理,只需要知道如何使用就行,Node.js 已经为我们打包好了相关接口。
# 3. Node.js 的特点
# 3.1 优点
- 异步非阻塞的 I/O(I/O 线程池)
- 特别适用于 I/O 密集型应用(对比传统 Java 服务器)
- 事件循环机制
- 单线程(成也单线程,败也单线程)
- 跨平台
解释:
-
异步非阻塞的 I/O(I/O 线程池)
I/O 是指 inout/ouput,这里是指文件的读写,数据库的操作等等。同步会造成阻塞问题,按照顺序来进行操作。异步是指做这一件事的时候可以做其他事情,非阻塞。
I/O 线程池:让一个线程随时随地处于待命状态,以便下次更加快速的执行任务。 -
特别适用于 I/O 密集型应用
某个项目需要频繁进行 I/O 操作,就成为 I/O 密集型应用。
-
事件循环机制
Node.js 脱离了浏览器,浏览器有事件循环机制,但 Node.js 也提供了自己的独有的一个事件循环机制。
-
单线程(成也单线程,败也单线程)
单线程要想实现异步,就必须要有自己的 “事件循环模型”。
-
跨平台
- JS 跨平台:js——js 引擎 —— 由谷歌等设计
- java 跨平台:java——jvm 虚拟机
- Node.js 也跨平台
# 3.2 不足之处
- 回调函数嵌套太多、太深(俗称回调地狱)
- 单线程,处理不好 CPU 密集型任务
CPU 密集型与 IO 密集型:
- CPU 密集型:需要过多判断,要做的事情不明确
- IO 密集型:事情明确
简单 web 交互模型:
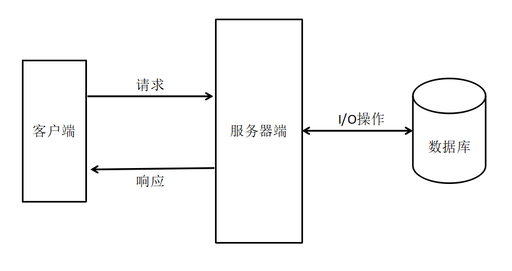
Node.js 和 Java 服务器对比:
- Java 服务器可以有多 “服务员” ,增加服务器空间来实现高并发,成本也高,适用于大企业。
- Node.js 的服务器只有一个 “服务员”,每次收到任务请求的时候,一对一的服务,向数据库请求数据,通过回调函数实现高并发。适用于 I/O 密集型应用,适用于 个人或中小型企业或者微信小程序搭建服务器。
- 所以对于 CPU 密集型应用,会频繁 “点餐”,这时候一对一的 “Node” 就废掉了。
# 4. Node.js 的应用场景
- Web 服务 API,比如 RESTful API(本身没有太多的逻辑,只需要请求 API,组织数据进行返回即可)
- 服务器渲染页面,提升速度
- 后端的 Web 服务,例如跨域、服务器端的请求
# 5. Node 中函数的特点
Node 中 任何一个模块(js 文件)都被一个外层函数所包裹。现在我们获得这个外层函数,那我们就有这样一个需求:在函数体内输出自身这个函数。使用 arguments.callee 可以做到:
function demo() {
// 输出函数本身
console.log(arguments.callee);
}那么可以直接在 Node 中执行这段代码,获取这个外层函数:
console.log(arguments.callee.toString());执行这段代码,我们可以得到 Node 中的外层函数:
function (exports, require, module, __filename, __dirname) { }这意味这些参数在 Node 中可以直接调用:
console.log(__filename);
console.log(__dirname);exports:用于支持 CommonJS 模块化的暴露语法require:用于支持 CommonJS 模块化的引入语法module:用于支持 CommonJS 模块化的暴露语法__filename:当前运行文件的绝对路径__dirname:当前运行文件所在文件夹的绝对路径
那么,这个外层函数有什么作用?
- 用于支持模块化语法
- 隐藏服务器内部实现(从作用域角度去看,但不仅仅是这个方面,有自己的安全保护机制),服务器安全。
# 6. Node 中的 global
# 6.1 Node 的组成
浏览器端的 JS 由三部分组成:
- BOM
- DOM
- ECMAScript
Node 端的 JS:
- 没有 BOM,因为服务器不需要
- 没有 DOM,因为没有浏览器窗口,也就没有文档对象模型
- 几乎包含了所有的 ES 规范
- 没有
window对象,取而代之的是一个叫global的全局变量 - 在 Node 中禁止函数的
this指向global,所以执行console.log(this)的结果为{}
# 6.2 global 的一些常用属性
console.log(global);setInterval:设置循环定时器clearInterval:清空循环定时器setTimeout:设置延迟定时器clearTimeout:清空延迟定时器setImmediate:设置立即执行函数clearImmediate:清空立即执行函数
# 7. Node 中的事件循环模型(了解)
概览:
┌───────────────────────────┐
┌─>│ timers │
│ └─────────────┬─────────────┘
│ ┌─────────────┴─────────────┐
│ │ pending callbacks │
│ └─────────────┬─────────────┘
│ ┌─────────────┴─────────────┐
│ │ idle, prepare │
│ └─────────────┬─────────────┘ ┌───────────────┐
│ ┌─────────────┴─────────────┐ │ incoming: │
│ │ poll │<─────┤ connections, │
│ └─────────────┬─────────────┘ │ data, etc. │
│ ┌─────────────┴─────────────┐ └───────────────┘
│ │ check │
│ └─────────────┬─────────────┘
│ ┌─────────────┴─────────────┐
└──┤ close callbacks │
└───────────────────────────┘Node 事件循环模型包括 6 个阶段:
-
第一个阶段: timers(定时器阶段:
setTimeout、setInterval)- 开始计时
- 执行计时器的回调(timers 独有)
-
第二个阶段: pending calLbacks(系统阶段,我们一般不关注)
-
第三个阶段: idle, prepare(准备阶段,我们一般不关注)
-
第四个阶段: poll(轮询阶段)
- 如果回调队列里有待执行的回调函数
- 从回调队列中取出回调函数,同步执行(依次执行),直到回调队列为空,或者达到系统最大限制。
- 如果回调队列为空
- 如果设置过
setImmediate,则进入下一个 check 阶段,为了执行setImmediate所设置的回调。 - 如果未设置
setImmediate: 在此阶段停留,等待回调函数被插入回调队列。 若定时器到点了,进入下一 check 阶段。目的:为,了走第五阶段,随后走第六阶段(最终目的)
- 如果设置过
- 如果回调队列里有待执行的回调函数
-
第五个阶段: check(专门用于执行
setImmediate所设置的回调) -
第六个阶段: close callbacks(关闭回调阶段)
-
process.nextTick():设置立即执行函数(“人民币玩家”—— 能在任意阶段优先执行)
特殊情况:
- 当没有主线程事件的时候,
setTimeout(()=>{})和setImmediate(()=>{})的执行顺序不确定,取决于事件轮询的时间,看 timers 阶段是否来得及定时以及执行setTimeout。 - 当有了主线程事件的时候,那么 timers 阶段是完全有时间来定时以及执行
setTimeout的,所以setTimeout(()=>{})将执行在setImmediate前面。
// 延迟执行函数
setTimeout(() => {
console.log("setTimeout指定的回调");
});
// 立即执行函数(回调)
setImmediate(() => {
console.log("我是setImmediate执行的回调");
});
// 立即执行函数(VIP回调)
process.nextTick(() => {
console.log("process.nextTick指定的回调函数");
});
console.log("我是主线程上的代码");以上代码输出:
我是主线程上的代码
process.nextTick指定的回调函数
setTimeout指定的回调
我是setImmediate执行的回调# (二) 包与 npm 包管理器
# 1. package 包
Node.js 的包基本遵循 CommonJS 规范,包将一组相关的模块组合在一起,形成一组完整的工具。
包由包结构和包描述文件两个部分组成。
- 包结构:用于组织包中的各种文件
- 包描述文件:描述包的相关信息,以供外部读取分析
# 1.1 包结构
包实际上就是一个压缩文件,解压以后还原为目录。符合 CommonJS 规范的目录,应该包含如下文件:
- package.json 描述文件
- bin 可执行二进制文件(“说明书”,必须有)
- lib js 代码
- doc 文档(说明文档、bug 修复文档、版本变更记录)
- test 单元测试
Tip
实际上开发的时候也不必严格遵循这个规则,但
package.json是必需的。
如何让一个普通文件夹变成一个包?
-
让这个文件夹拥有一个: package.json 文件即可,且 package.json 里面的内容要合法。执行命令:
npm init -
包名的要求:不能有中文、不能有大写字母、尽量不要以数字开头,不能与 npm 仓库上其他包同名。
# 1.2 包描述文件
包描述文件用于表达非代码相关的信息,它是一个 JSON 格式的文件: package.json
包描述文件包含以下字段:name、version、description、keywords、maintainers、contributors、bugs、licenses、repositories、dependencies、homepage、os、cpu、engine、builtin、directories、implements、scripts、author、bin、main、devDependencies。
# 2. NPM
# 2.1 NPM 是什么
全称:Node Package Manager,Node 的包管理器。
NPM 与 Node 的关系:
- 安装 node 后自动安装 npm(npm 是 node 官方出的包管理器,专门用于管理包)
# 2.2 NPM 能干什么
通过 NPM 可以对 Node 的包进行搜索、下载、安装、删除、上传。
# 2.3 NPM 常用命令
-
【搜索】
npm search xxx- 通过网址搜索:https://www.npmjs.com
-
【安装】
前提:安装之前必须保证文件夹里面有 package.json,且里面的内容格式合法。
-
npm install xxx --save或npm i xxx -S或npm i xxx备注:
- 局部安装完的第三方包,放在当前目录中 node_modules 这个文件夹里
- 安装完毕会自动产生一个 package-lock.json (npm 版本在 5 以后才有),里面缓存的是每个包的地址,目的是下次快一些。
- 当安装完一个包,该包的名字会自动写入到 package.json 中的【dependencies (生产依赖) npm5 及之前版本要加上
--save后缀才可以。
-
npm install xxx --save-dev或npm i xxx -D安装包并将该包写入到【devDependencies (开发依赖中)】
备注:什么是生产依赖与开发依赖?- 只在开发时 (写代码时) 时才用到的库,就是开发依赖 ----- 例如:语法检查、压缩代码、扩展 css 前缀的包。
- 在生产环境中 (项目上线) 不可缺少的,就是生产依赖 ------ 例如:jquery、bootStrap 等等。
- 注意:某些包即属于开发依赖,又属于生产依赖 ------- 例如:jquery。
-
npm i xxx -g- 全局安装 xxxx 包(一般来说,带有指令集的包要进行全局安装,例如:browserify、babel 等)
- 全局安装的包,其指令到处可用,如果该包不带有指令,就无需全局安装。
- 查看全局安装的位置:
npm root -g
-
npm i xxx@yyy安装 xxx 包的 yyy 版本
-
npm i:安装 (当前我们自己包里面的) package.json 中声明的 (依赖中的) 所有包
-
-
【移除】
-
npm remove xxx在 node_module 中删除 xxx 包,同时会删除该包在 package.json 中的声明。
-
-
【其他命令】
npm aduit fix:检测项目依赖中的一些问题,并且尝试着修复。npm view xxxxx versions:查看远程 npm 仓库中 xxx 包的所有版本信息npm view xxxxx version:查看 npm 仓库中 xxx 包的最新版本npm ls xxxx:查看我们所安装的 xxx 包的版本
-
【关于版本号的说明】
"^3.x.x":锁定大版本,以后安装包的时候,保证包是 3.x.x 版本,x 默认取最新的。"~3.1.x":锁定小版本,以后安装包的时候,保证包是 3.1.x 版本,x 默认取最新的。"3.1.1":锁定完整版本,以后安装包的时候,保证包必须是 3.1.1 版本。
# 3. cnpm 的简介与使用
# 3.1 国内使用 npm 存在的问题
- 安装 npm 后,每次我们安装包时,我们的电脑都要和 npm 服务器进行对话,去 npm 仓库获取包。
- npm 默认的仓库地址为:http://registry.npmjs.org
- 查看当前 npm 仓库地址命令:
npm config get registry,提示如下图:
- 因为 npm 的远程服务器在国外,所以有时候难免出现访问过慢,甚至无法访问的情况。
- 为了解决这个问题,我们有以下几个解决办法

# 3.2 使用淘宝的 cnpm 代替 npm
淘宝为我们搭建了一个国内的 npm 服务器,它目前是每隔 10 分钟将国外 npm 仓库的所有内容 “搬运” 回国内的服务器上,这样我们直接访问淘宝的国内服务器就可以了,它的地址是:https://registry.npm.taobao.org
使用方法:
-
第一种(不建议):直接安装 cnpm 安装淘宝提供的 cnpm,并更改服务器地址为淘宝的国内地址, 命令:
npm install -g cnpm --registry=https://registry.npm.taobao.org以后安装直接采用
cnpm替代npm。
例如原生 npm 命令为:npm install uniq --save,cnpm 命令为:cnpm install uniq --save。 -
第二种(建议):替换 npm 仓库地址为淘宝镜像地址
命令:
npm config set registry https://registry.npm.taobao.org查看是否更改成功:
npm config get registry,以后安装时,依然用npm命令,但是实际是从淘宝国内服务器下载的。
# 4. yarn 的简介与使用
Yarn 发布于 2016 年 10 月,截至当前 2019 年 1 月,gitHub 上的 Start 数量为:34.3k,已经超过 npm 很多了, yarn 使用本地缓存,有时甚至无需互联网连接就能安装本地已经缓存过的依赖项,安装方法:
npm install -g yarn# 4.1 注意配置环境变量
由于 yarn 的全局安装位置与 npm 不同,所以要配置 yarn 的全局安装路径到环境变量中,否则全局安装的包不起作用。 具体操作如下:
- 安装 yarn 后分别执行
yarn global dir命令,yarn global bin命令。 - 将上述两步返回的路径配置到电脑环境变量中即可。
# 4.2 yarn 命令与 npm 命令的对应关系
-
初始化项目:
yarn init -y npm init -y -
下载项目的所有声明的依赖:
yarn npm install -
下载指定的运行时依赖包:
yarn add xxxx@3.2.1 npm install xxxxx@3.2.1 -S -
下载指定的开发时依赖:
yarn add xxxxx@3.2.1 -D npm install xxxxx@3.2.1 -D -
全局下载指定包:
yarn global add xxxxxx npm install xxxxxxx -g -
删除依赖包:
yarn remove xxxxx yarn global remove xxxxxx npm remove xxxxxxx -g -
查看某个包的信息:
yarn info xxx npm info xxx -
设置淘宝镜像:
yarn config set registry https://registry.npm.taobao.org npm config set registry https://registry.npm.taobao.org
# (三)Buffer 缓冲器
背景:
- 浏览器没有储存图片文件等媒体文件的需求,JS 存的都是一些基本数据类型。
- 服务器需要存储图片 / 视频 / 音频等媒体文件,因此有了 Buffer 缓冲器。
# 1. Buffer 是什么
Buffer 是一个和数组类似的对象,不同是 Buffer 是专门用来保存二进制数据的。
# 2. Buffer 特点
- 它是一个【类似于数组】的对象,用于存储数据(存储的是二进制数据)。
- Buffer 的效率很高,存储和读取很快,它是直接对计算机的内存进行操作。
- Buffer 的大小一旦确定了,不可修改。
- 每个元素占用内存的大小为 1 字节。
- Buffer 是 Node 中的非常核心的模块,无需下载、无需引入,直接即可使用
# 3. Buffer 的操作
# 3.1 Buffer 的创建
// 创建一个指定size大小的Buffer
// 安全,里面全是0
var buf = Buffer.alloc(size);
//不安全,可能包含旧数据,需要重写所有数据
var buf = Buffer.allocUnsafe(size);-
方式一:
let buf = new Buffer(10); console.log(buf);new Buffer方式创建一个 Buffer 的实例对象,性能特别差(需要在堆里开辟空间,然后清理空间 - 置零) -
方式二
let buf2 = Buffer.alloc(10); console.log(buf2);创建一个 Buffer 的实例对象,性能比
new Buffer()稍强一点,在堆中开辟一块空间(该块空间没有人用过) -
方式三
let buf3 = Buffer.allocUnsafe(10); console.log(buf3);创建一个 Buffer 的实例对象,性能最好的,在堆里开辟空间。
# 3.2 获取 Buffer 的长度
// 获取Buffer的长度
buf.length;# 3.3 Buffer 的转换
// 相当于Buffer.alloc(size);
var buf = Buffer.allocUnsafe(size);
buf.fill(0); //将可能出现的敏感数据用0全部填充
// 将一个字符串转换为Buffer
var buf = Buffer.from(str);
// 将一个Buffer转换为字符串
var str = buf.toString();注意:
-
输出的 Buffer 为什么不是二进制?
输出的是 16 进制,但是存储的是二进制吗,输出的时候会自动转 16 进制。
-
输出的 Buffer 不为空?
在堆里开辟空间,可能残留着别人用过的数据,所以 allocUnsafe
# (四)fs 文件系统
# 1. Node 中的 fs 文件系统
-
在 Node 中有一个文件系统,所谓的文件系统,就是对计算机中的文件进行增删改查等操作。
-
在 NodeJs 中,给我们提供了一个模块,叫做 fs 模块 (文件系统),专门用于操作文件。
-
fs 模块是 Node 的核心模块,使用的时候,无需下载,直接引入。
// 引入fs模块 var fs = require("fs");
fs 中的大部分方法都为我们提供了两个版本:
-
同步方法:带
sync的方法- 同步方法会阻塞程序的执行
- 同步方法通过返回值返回结果
-
异步方法:不带
sync的方法- 异步方法不会阻塞程序的执行
- 异步方法都是通过回调函数来返回结果的
Tip
Nodejs 的一个特点是异步非阻塞,所以学习的都是异步方法。
# 2. fs 文件写入
文件写入有两种方法,一种是 writeFileSync (同步),另一种是 writeFile (异步的)。
// 同步方法
fs.writeFileSync(file, data[, options])
// 异步方法
fs.writeFile(file, data[, options], callback)# 2.1 简单文件写入
Tip
简单文件写入方式是一种异步操作,事实上,后面讲的都是异步操作。
语法:
fs.writeFile(file, data[, options], callback(err) => {})file:要写入的文件路径 + 文件名 + 后缀data:要写入的数据options:配置对象 (可选参数)encoding:设置文件的编码方式,默认值:utf8(万国码)mode:设置文件的操作权限,默认值是:0o666 = 0o222 + 0o4440o111:文件可被执行的权限,.exe .msc 几乎不用,linux 有自己一套操作方法。0o222:文件可被写入的权限0o444:文件可别读取的权限
flag:打开文件要执行的操作,默认值是'w'a:追加w:写入
callback:回调函数err:错误对象
举例:
//引入内置的fs模块
let fs = require("fs");
//调用writeFile方法
fs.writeFile(
__dirname + "/demo.txt",
"kobe,123",
{ mode: 0o666, flag: "a" },
(err) => {
if (err) console.log("文件写入失败", err);
else console.log("文件写入成功");
}
);Tip
在 Node 中有这样一个原则:错误优先。所以有了回调:
err=>{}。
# 2.2 流式文件写入
流式文件写入适用于一些比较大的文件,可以分多次向文件中写入内容,有效避免内存溢出的问题。
Tip
可以把流式文件写入比作是使用水管从河里往家里运水,流式文件写入首先要创建流(水管),然后要检测流的状态,文件传输完毕,则要关闭流(拿开水管)。
创建一个文件可写流:
fs.createWriteStream(path[, options])参数说明:
path:要写入文件的路径 + 文件名 + 文件后缀options:配置对象(可选参数)flags:打开文件要执行的操作,默认值:wencoding:设置文件的编码方式,默认值:utf8fd: 文件统一标识符,linux 下文件标识符mode:设置文件的操作权限,默认值是:0o666 = 0o222 + 0o444autoClose: 自动关闭文件,默认值:trueemitClose: 关闭文件,默认值:truestart: 整数值,写入文件的起始位置(偏移量)
- 返回值:
<fs.WriteStream>(一个可写流)
文件流写入的过程:
-
创建一个可写流(水管搭建好了)
let ws = fs.createWriteStream(__dirname + "/demo.txt", { start: 10 }); -
检测流的状态(只要用到了流,就必须监测流的状态)
ws.on("open", function () { console.log("可写流打开了"); }); ws.on("close", function () { console.log("可写流关闭了"); }); -
使用可写流写入数据
ws.write("美女\n"); ws.write("霉女?\n"); ws.write("到底是哪一个?\n"); -
关闭可写流(水管不用了,得收起来)
方式一:在 Node 的 v8 版本中,要用
end方法关闭流,否则可能造成数据丢失。ws.end();方式二:
close方法关闭流在 Node V8 可能造成数据丢失。ws.close();
# 3. 文件读取
文件读取也有两种方法:
// 同步
fs.readFileSync(path[, options])
// 异步
fs.readFile(path[, options], callback)# 3.1 简单文件读取
语法:
fs.readFile(path[, options], callback(arr, data))参数说明:
path:要读取文件的路径 + 文件名 + 后缀options:配置对象(可选)callback:回调函数err:错误对象data:读取出来的数据
Tip
当文件读入成功,则
err为null,data为读取到的数据。若当文件读入失败,则err为异常对象,data为空。
let fs = require("fs");
fs.readFile(__dirname + "/test.mp4", function (err, data) {
if (err) console.log(err);
else console.log(data);
fs.writeFile("../haha.mp4", data, function (err) {
if (err) console.log(err);
else console.log("文件写入成功");
});
});为什么读取出来的东西是 Buffer? 用户存储的不一定是纯文本。
Warning
简单文件写入和简单文件读取,都是一次性把所有要读取或要写入的内容加到内存中,容易造成内存泄露。
# 3.2 流式文件读取
对于一个较大的文件,我们不能通过简单方式读取。因为简单方式是一次性读取,内存可能不够用。这个时候我们可以使用流式读取,分多次读取。
创建一个文件读取流语法:
fs.createReadStream(path[, options])参数说明:
path:要读取的文件路径 + 文件名 + 后缀options:可选配置项flagsencodingfdmodeautoCloseemitClosestart:起始偏移量end:结束偏移量highWaterMark:每次读取数据的大小,默认值是64 * 1024(64KB)
流式读取(并写入到一个新文件中)文件过程:
let { createReadStream, createWriteStream } = require("fs");
//创建一个可读流
let rs = createReadStream(__dirname + "/music.mp3", {
// 10M
highWaterMark: 10 * 1024 * 1024,
// start end 参数一般不用
// start:60000,
// end:120000
});
//创建一个可写流
let ws = createWriteStream("../haha.mp3");
// 只要用到了流,就必须监测流的状态
rs.on("open", function () {
console.log("可读流打开了");
});
rs.on("close", function () {
console.log("可读流关闭了");
// 正确关闭流方式:当没有数据可读,读取流关闭,则写入流也关闭
ws.close();
});
ws.on("open", function () {
console.log("可写流打开了");
});
ws.on("close", function () {
console.log("可写流关闭了");
});
// 给可读流绑定一个data事件,就会触发可读流自动读取内容。
rs.on("data", function (data) {
// Buffer实例的length属性,是表示该Buffer实例占用内存空间的大小
// 输出的是65536,每次读取64KB的内容
console.log(data.length);
ws.write(data);
// ws.close()
//若在此处关闭流,会写入一次,后续数据丢失
});
// ws.close()
//若在此处关闭流,导致无法写入数据# (五)MongoDB 非关系型数据库
# 1. 数据库简介
# 1.1 数据库是什么
数据库(DataBase)是按照数据结构来组织、存储和管理数据的仓库。
# 1.2 为什么要使用数据库
我们的程序都是在内存中运行的,一旦程序运行结束或者计算机断电,程序运行中的数据都会丢失。所以我们就需要将一些程序运行的数据持久化到硬盘之中,以确保数据的安全性。而数据库就是数据持久化的最佳选择。说白了,数据库就是存储数据的仓库。
# 1.3 数据库的分类
# 1.3.1 关系型数据库(RDBS)
-
代表有:MySQL、Oracle、DB2、SQL Server…
-
特点:关系紧密,表结构
-
优点:
- 易于维护:都是使用表结构,格式一致;
- 使用方便:SQL 结构化查询通用,可用于复杂查询;
- 高级查询:可用于一个表以及多个表之间非常复杂的查询。
-
缺点:
- 读写性能比较差,尤其是海量数据的高效率读写;
- 有固定的表结构,字段不可随意更改,灵活度稍欠;
- 高并发读写需求,传统关系型数据库来说,硬盘 I/O 是一个很大的瓶颈。
# 1.3.2 非关系型数据库(NoSQL)
-
代表有:MongoDB、Redis…
-
特点:关系不紧密,文档存储,有键值对
-
优点:
- 格式灵活:存储数据的格式可以是 key,value 形式。
- 速度快:nosql 可以内存作为载体,而关系型数据库只能使用硬盘;
- 易用:nosql 数据库部署简单。
-
缺点:
- 不支持 sql,学习和使用成本较高;
- 不支持事务;
- 复杂查询时语句过于繁琐。
# 2. MongoDB 的简介和安装
# 2.1 MongoDB 简介
- MongoDB 是为 快速开发互联网 Web 应用而设计的数据库系统。
- MongoDB 的设计目标是极简、灵活、作为 Web 应用栈的一部分。
- MongoDB 的数据模型是面向文档的,所谓文档是一种类似于
JSON的结构,简单理解 MongoDB 这个数据库中存的是各种各样的 JSON。(BSON)
# 2.2 MongoDB 安装和基本配置
# 2.2.1 MongoDB 安装
- 下载安装 MongoDB 数据库系统,安装好后需要配置环境变量,在系统高级设置中添加 MongoDB 安装路径下的
bin的路径即可。(一般都是安装在 C 盘,无法修改。) - 在 c 盘根目录创建文件夹
C:\data\db - 打开命令行窗口输入
mongod启动数据库服务器 - 打开一个新的命令行窗口输入
mongo启动数据库的客户端
# 2.2.2 MongoDB 服务器的启动
-
服务器负责在计算机创建数据库,使用数据库需要先启动服务器
-
MongoDB 的默认端口号 **
27017**- 可以通过
--port来指定端口号 - 端口号尽量使用四位以上,不要超过最大端口号 65535
- 不能使用其他服务占用的端口号
- 可以通过
-
MongoDB 数据库默认会存放在 C 盘根目录下的
data/db,可以通过--dbpath指令来指定数据库的目录
结合使用:
mongod --dbpath C:\Users\web\Desktop\database --port 12345Warning
注意:目前为止,启动服务的命令行窗口不能关闭。
# 2.2.3 MongoDB 客户端
- 我们通过客户端来管理数据库
- 在 CMD 输入
mongo来启动客户端
# 2.3 将 MongoDB 设置为 windows 系统服务
每次使用服务都要手动启动依次服务器,且启动服务窗口不能关闭。这里我们将将 MongoDB 设置为 windows 系统服务,使其开机自启。
-
在 c 盘根目录创建如下文件夹
C:\data\log C:\data\db -
在 MongoDB 的安装目录添加一个配置文件
mongod.cfg。其中,目录位置如下(根据自己数据库版本确定):
// 目录 C:\Program Files\MongoDB\Server\4.4mongod.cfg的文件内容如下:systemLog: destination: file path: c:\data\log\mongod.log storage: dbPath: c:\data\db net: port: 27017 -
以管理员身份打开命令行,执行以下指令(注意版本号根据自己的修改):
sc.exe create MongoDB binPath= "\"C:\Program Files\MongoDB\Server\3.2\bin\mongod.exe\" --service --config=\"C:\Program Files\MongoDB\Server\3.2\mongod.cfg\"" DisplayName= "MongoDB" start= "auto" -
打开系统服务器,启动名为 MongoDB 的服务,将其启动方式设置为自动。
-
如果无法启动服务,在管理员的命令行窗口中输入如下指令,然后重复步骤 1。
sc delete MongoDB
# 2.4 安装 MongoDB 图形化工具
数据库图形化管理工具 极大地方便了数据库的操作与管理,推荐的 MongoDB 图形化管理工具 有:
# 2.5 常用端口号总结
端口号: 1-65535 ,不建议使用 1--199 的端口号,这些是预留给系统的,一般使用 4 位的,4 位的也不要用 1 开头的。
常见端口号:
21端口:FTP 文件传输服务22端口:SSH 端口23端口:TELNET 终端仿真服务25端口:SMTP 简单邮件传输服务53端口:DNS 域名解析服务80端口:HTTP 超文本传输服务110端口:POP3 “邮局协议版本 3” 使用的端口443端口:HTTPS 加密的超文本传输服务1433端口:MS SQL*SERVER 数据库 默认端口号1521端口:Oracle 数据库服务1863端口:MSN Messenger 的文件传输功能所使用的端口3306端口:MYSQL 默认端口号3389端口:Microsoft RDP 微软远程桌面使用的端口5631端口:Symantec pcAnywhere 远程控制数据传输时使用的端口5632端口:Symantec pcAnywhere 主控端扫描被控端时使用的端口5000端口:MS SQL Server 使用的端口27017端口:MongoDB 实例默认端口
# 3. MongoDB 的使用
# 3.1 MongoDB 中的基本概念
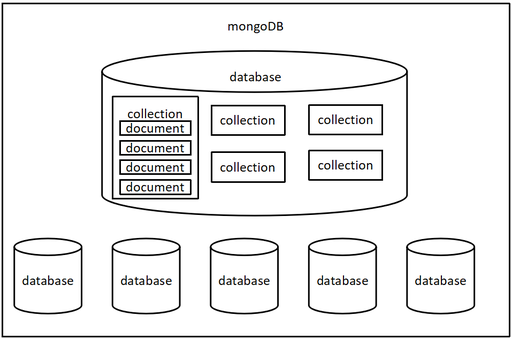
-
数据库(database)
数据库是一个仓库,在仓库中可以存放集合。
-
集合(collection)
集合类似于 JS 中的数组,在集合中可以存放文档。 说白了,集合就是一组文档。
-
文档(document)
文档数据库中的最小单位,我们存储和操作的内容都是文档。类似于 JS 中的对象,在 MongoDB 中每一条数据都是一个文档。
和 MySQL 的对比:
| MySQL | MongoDB | 描述 |
|---|---|---|
| 数据库 | 数据库 | 一个数据库文件 |
| 表 | 集合 | 关系型数据库:一张表,非关系型:一个集合 |
| 字段 | 字段 | 每列的头,在关系型数据库中,某些字段是唯一标识,则称为主键 |
| 一条数据 | 一条文档 | 一行数据 |
# 3.2 命令行基本命令
-
显示所有的数据库
show dbs show databases -
切换到指定的数据库
use 数据库名 -
显示当前所在的数据库
db -
删除当前数据库
db.dropDatabase() -
显示当前数据库中的所有集合
show collections -
删除当前集合
db.collection.drop()
在 MongoDB,数据库和集合都不需要创建,当 我们向集合或数据库中第一次插入文档时,集合和数据库会自动创建。
-
向集合中插入文档
db.<collection>.insert(doc)如:
db.stus.insert({name:"sunwukong",age:18}) -
查询集合中的文档
db.<collection>.find()如:
db.stus.find()
# 3.3 MongoDB 原生 CRUD(增删改查)
# 1. C-creat(新增数据)
db.集合名.insert(文档对象)
db.集合名.insertOne(文档对象)
db.集合名.insertMany([文档对象,文档对象])# 2. R-read(查询数据)
(1)语法: db.集合名.find(查询条件[, 投影])
举例:查找年龄为 18 的所有信息
db.students.find({age:18})举例:查找年龄为 18 且名字为 jack 的学生
db.students.find({age:18,name:'jack'})(2)常用操作符:
-
< , <= , > , >= , !==对应为:$lt $lte $gt $gte $ne举例:年龄是大于等于 20 的
db.集合名.find({age:{$gte:20}}) -
逻辑或:使用
$in或$or举例:查找年龄为 18 或 20 的学生
db.students.find({age:{$in:[18,20]}}) db.students.find({$or:[{age:18},{age:20}]}) -
逻辑非:
$nin -
正则匹配: 举例:
db.students.find({name:/^T/}) -
$where能写函数:db.students.find({$where:function(){ return this.name === 'zhangsan' && this.age === 18 }})
(3)投影:过滤掉不想要的数据,只保留想要展示的数据 举例:过滤掉 id 和 name
db.students.find({},{_id:0,name:0})举例:只保留 age
db.students.find({},{age:1})(4)补充:默认只要找到一个
db.集合名.findOne(查询条件[,投影])# 3. U-update(更新数据)
语法:
db.集合名.update(查询条件,要更新的内容[,配置对象])如下写法会将更新内容替换掉整个文档对象,但 _id 不受影响
db.students.update({name:'zhangsan'},{age:19})使用 $set 修改指定内容,其他数据不变,不过只能匹配一个 zhangsan
db.students.update({name:'zhangsan'},{$set:{age:19}})修改多个文档对象,匹配多个 zhangsan, 把所有 zhangsan 的年龄都替换为 19
db.students.update({name:'zhangsan'},{$set:{age:19}},{multi:true})补充:
db.集合名.updateOne(查询条件,要更新的内容[,配置对象])
db.集合名.updateMany(查询条件,要更新的内容[,配置对象])# 4. D-delete(删除数据)
语法:
db.集合名.remove(查询条件)删除所有年龄小于等于 19 的学生
db.students.remove({age:{$lte:19}})Tip
学过关系型数据库的写 MongoDB 原生怎删改查确实很难受,于是有了 Nodejs 模块:Mongoose。
# 4. Mongoose 的使用
# 4.1 简介
Mongoose 是一个对象文档模型(ODM)库,它对 Node 原生的 MongoDB 模块进行了进一步的优化封装,并提供了更多的功能。
# 4.2 优势
- 可以为文档创建一个模式结构(Schema)
- 可以对模型中的对象 / 文档进行验证
- 数据可以通过类型转换转换为对象模型
- 可以使用中间件来应用业务逻辑挂钩
- 比 Node 原生的 MongoDB 驱动更容易
# 4.3 核心对象(概念)
-
Schema
模式对象,通过
Schema可以对集合进行 约束。 -
Model
模型对象,相当于数据库中的集合,通过该对象可以 对集合进行操作。 3。 Document
文档对象,它和数据库中的文档相对应,通过它可以读取文档的信息,也可以对文档进行各种操作。
# 4.4 Mongoose 的使用
首先通过 npm 或 yarn 下载安装 Mongoose。
npm i mongoose --save# 1. 连接数据库
语法:
// 1. 引入 Mongoose
let mongoose = require("mongoose");
// 2. 连接数据库
mongoose.connect("mongodb://[ip地址]:[端口号]/[数据库名]");举例:
let mongoose = require("mongoose");
mongoose.connect("mongodb://localhost:27017/demo", {
useNewUrlParser: true, // 使用新解析器,解决一些安全性问题
useUnifiedTopology: true, // 使用一个统一的拓扑结构
});# 2. 绑定数据库连接的监听
语法:
mongoose.connection.on("open", (err) => {
if (err) {
console.log("数据库连接失败", err);
} else {
console.log("数据库连接成功");
// 进行下一步操作
}
});# 3. 创建核心对象
进行下一步操作:
-
创建
Schema对象,内部传入约束对象// 引入 Schema 约束对象 var Schema = mongoose.Schema; var xxxSchema = new Schema({ 字段: 类型, 字段: 类型, 字段: 类型, 字段: 类型, }); -
生成某个集合所对应的 Model 模型对象
var xxxModel = mongoose.model("集合名", xxxSchema); -
进行 CRUD 增删改查操作
实例:
// 引入 mongoose
let mongoose = require("mongoose");
// 1. 连接数据库
mongoose.connect("mongodb://localhost:27017/demo", {
useNewUrlParser: true, // 使用新解析器,解决一些安全性问题
useUnifiedTopology: true, // 使用一个统一的拓扑结构
});
// 2. 绑定数据库连接的监听
mongoose.connection.on("open", (err) => {
if (err) {
console.log("数据库连接失败", err);
} else {
console.log("数据库连接成功");
// 1. 引入模式对象
let Schema = mongoose.Schema;
// 2. 创建约束对象
let studentSchema = new Schema({});
// 3. 生成某个集合所对应的模型对象
let stuModel = mongoose.model("students", studentSchema);
// 4. 进行增删改查
stuModel.create({}, (err, data) => {});
}
});# 4.5 Mongoose 的 CRUD 增删改查
-
Create
模型对象.create(文档对象,回调函数) 模型对象.create(文档对象) -
Read
模型对象.find(查询条件[,投影])不管有没有数据,都返回一个数组 模型对象.findOne(查询条件[,投影])找到了返回一个对象,没找到返回null -
Update
模型对象.updateOne(查询条件,要更新的内容[,配置对象]) 模型对象.updateMany(查询条件,要更新的内容[,配置对象])备注:存在
update方法,但是即将废弃,查询条件匹配到多个时,依然只修改一个,强烈建议用updateOne或updateMany -
Delete
模型对象.deleteOne(查询条件); 模型对象.deleteMany(查询条件);备注:没有
delete方法,会报错!
Mongoose 增删改查案例:
(1)新增操作
stuModel.create(
{
stu_id: "004",
name: "静静",
age: 16,
sex: "女",
hobby: ["看番", "听音乐", "喝奶茶"],
info: "温柔的女生",
},
function (err, data) {
// err:错误对象,data:写入的数据
if (!err) {
console.log(data);
} else {
console.log(err);
}
}
);(2)查询操作:
// find 方法,返回数组(即使是一条数据),查询结果为空,则返回 []
stuModel.find({ name: "静静1" }, function (err, data) {
if (!err) {
console.log(data);
} else {
console.log(err);
}
});
// findOne 方法,若有结果,则返回一个对象,没有则返回 null
stuModel.findOne({ name: "静静1" }, function (err, data) {
if (!err) {
console.log(data);
} else {
console.log(err);
}
});
// 投影
stuModel.findOne({ name: "瑞秋" }, { age: 1, _id: 0 }, function (err, data) {
if (!err) {
console.log(data);
} else {
console.log(err);
}
});(3)更新操作:
stuModel.updateOne({ name: "静静" }, { age: 14 }, (err, data) => {
if (!err) {
console.log(data);
} else {
console.log(err);
}
});(4)删除操作:
stuModel.deleteMany({ age: 22 }, (err, data) => {
if (!err) {
console.log(data);
} else {
console.log(err);
}
});# 4.6 Mongoose 的模块化编码
直接按照上述方法依次执行,代码都写在一个文件中,代码不好维护管理,使用模块化解决。
-
数据库连接模块
该模块连接数据库,判断连接状态。
db/db.js文件内容:let mongoose = require("mongoose"); // 暴露模块,返回一个 Promise 对象 module.exports = new Promise((resolve, reject) => { // 1. 连接数据库 mongoose.connect("mongodb://localhost:27017/demo", { useNewUrlParser: true, // 使用新解析器,解决一些安全性问题 useUnifiedTopology: true, // 使用一个统一的拓扑结构 }); // 2. 绑定数据库连接的监听 mongoose.connection.on("open", (err) => { if (err) reject(err); resolve("数据库连接成功!"); }); }); -
Mongoose 关键对象模块 该模块用于提供模型对象,需要哪个模型对象就新建一个,例如
teacherModel.js。module/studentModel.js文件内容:let mongoose = require("mongoose"); // (1)引入模式对象 let Schema = mongoose.Schema; // (2)创建约束对象 let studentSchema = new Schema({}); // (3) 生成某个集合所对应的模型对象 module.exports = mongoose.model("students", studentSchema); -
入口文件:
app.js// 1. 引入数据库连接模块 let p = require("./db/db"); // 2. 引入学生模型对象 let stuModel = require("./module/studentModel"); // 3. 判断数据库连接状态,成功则进行CRUD // 异步操作,使用 Promise 封装 p.then( (value) => { console.log(value); // !CRUD return new Promise((resolve, reject) => { stuModel.create( { // 相关数据插入 }, function (err, data) { // err:错误对象,data:写入的数据 if (err) reject(err); resolve(data); } ); }); }, (reason) => { console.log("数据库连接失败!", reason); } ).then( (value) => { console.log("数据添加成功!", value); }, (reason) => { console.log("数据添加错误!", reason); } );







