Java big Summary
# Java 基础语法特性
# 1. 注释
空白行,或者注释的内容,都会被 Java 编译器忽略掉。
Java 支持多种注释方式,下面的示例展示了各种注释的使用方式:
public class HelloWorld {
/*
* JavaDoc 注释
*/
public static void main(String[] args) {
// 单行注释
/* 多行注释:
1. 注意点a
2. 注意点b
*/
System.out.println("Hello World");
}
}# 2. 基本数据类型

👉 扩展阅读:深入理解 Java 基本数据类型
# 3. 变量
Java 支持的变量类型有:
局部变量- 类方法中的变量。实例变量(也叫成员变量)- 类方法外的变量,不过没有static修饰。类变量(也叫静态变量)- 类方法外的变量,用static修饰。
特性对比:
| 局部变量 | 实例变量(也叫成员变量) | 类变量(也叫静态变量) |
|---|---|---|
| 局部变量声明在方法、构造方法或者语句块中。 | 实例变量声明在方法、构造方法和语句块之外。 | 类变量声明在方法、构造方法和语句块之外。并且以 static 修饰。 |
| 局部变量在方法、构造方法、或者语句块被执行的时候创建,当它们执行完成后,变量将会被销毁。 | 实例变量在对象创建的时候创建,在对象被销毁的时候销毁。 | 类变量在第一次被访问时创建,在程序结束时销毁。 |
| 局部变量没有默认值,所以必须经过初始化,才可以使用。 | 实例变量具有默认值。数值型变量的默认值是 0,布尔型变量的默认值是 false,引用类型变量的默认值是 null。变量的值可以在声明时指定,也可以在构造方法中指定。 | 类变量具有默认值。数值型变量的默认值是 0,布尔型变量的默认值是 false,引用类型变量的默认值是 null。变量的值可以在声明时指定,也可以在构造方法中指定。此外,静态变量还可以在静态语句块中初始化。 |
| 对于局部变量,如果是基本类型,会把值直接存储在栈;如果是引用类型,会把其对象存储在堆,而把这个对象的引用(指针)存储在栈。 | 实例变量存储在堆。 | 类变量存储在静态存储区。 |
| 访问修饰符不能用于局部变量。 | 访问修饰符可以用于实例变量。 | 访问修饰符可以用于类变量。 |
| 局部变量只在声明它的方法、构造方法或者语句块中可见。 | 实例变量对于类中的方法、构造方法或者语句块是可见的。一般情况下应该把实例变量设为私有。通过使用访问修饰符可以使实例变量对子类可见。 | 与实例变量具有相似的可见性。但为了对类的使用者可见,大多数静态变量声明为 public 类型。 |
| 实例变量可以直接通过变量名访问。但在静态方法以及其他类中,就应该使用完全限定名:ObejectReference.VariableName。 | 静态变量可以通过:ClassName.VariableName 的方式访问。 | |
| 无论一个类创建了多少个对象,类只拥有类变量的一份拷贝。 | ||
| 类变量除了被声明为常量外很少使用。 |
变量修饰符
- 访问级别修饰符
- 如果变量是实例变量或类变量,可以添加访问级别修饰符(public/protected/private)
- 静态修饰符
- 如果变量是类变量,需要添加 static 修饰
- final
- 如果变量使用
fianl修饰符,就表示这是一个常量,不能被修改。
- 如果变量使用
# 4. 数组

👉 扩展阅读:深入理解 Java 数组
# 5. 枚举

👉 扩展阅读:深入理解 Java 数组
# 6. 操作符
Java 中支持的操作符类型如下:

👉 扩展阅读:Java 操作符
# 7. 方法

👉 扩展阅读:深入理解 Java 方法
# 8. 控制语句

👉 扩展阅读:Java 控制语句
# 9. 异常


👉 扩展阅读:深入理解 Java 异常
# 10. 泛型

👉 扩展阅读:深入理解 Java 泛型
# 11. 反射


👉 扩展阅读:深入理解 Java 反射和动态代理
# 12. 注解




👉 扩展阅读:深入理解 Java 注解
# 13. 序列化

# 深入理解 Java 基本数据类型
📦 本文以及示例源码已归档在 javacore(opens new window)
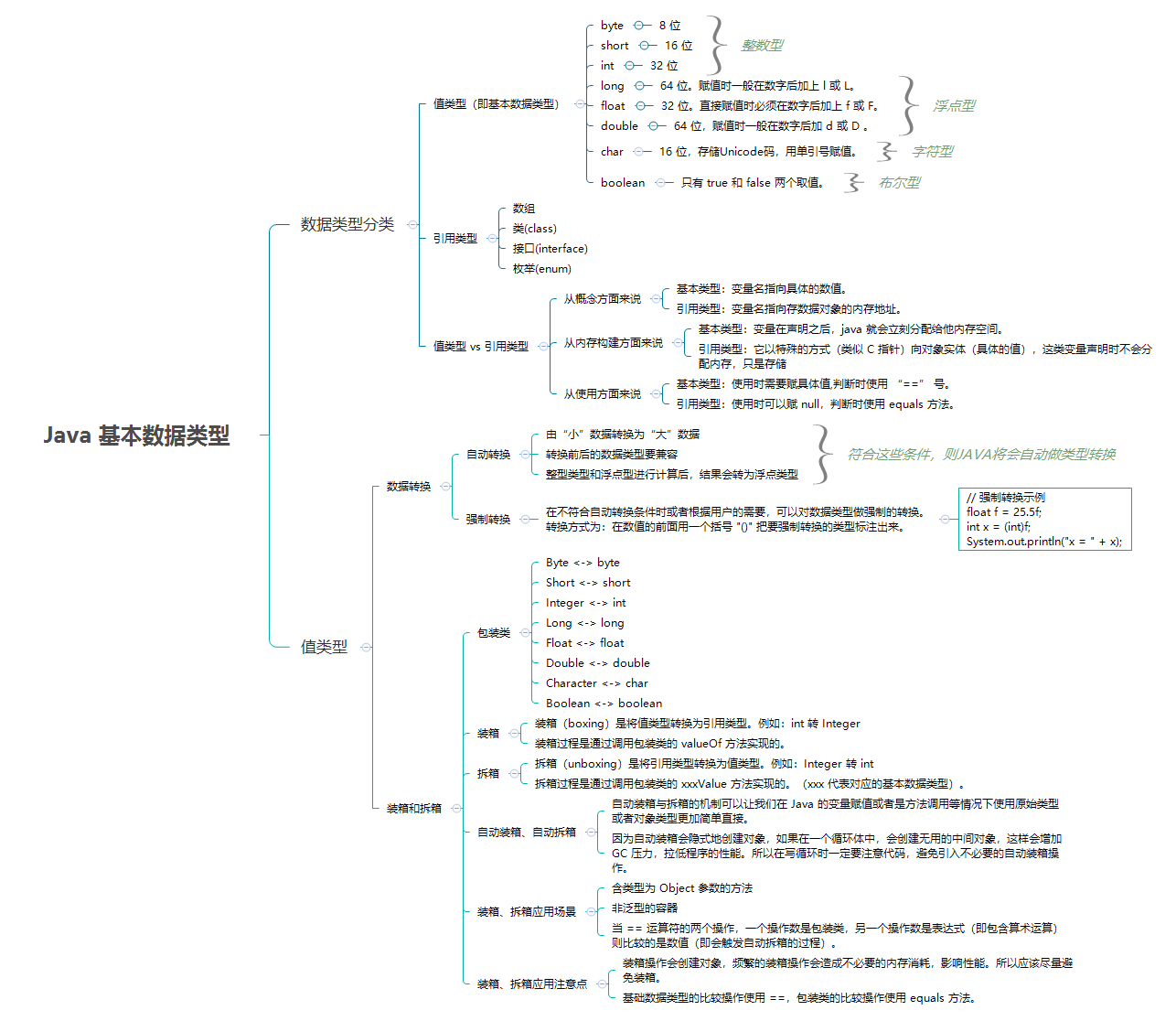
- \1. 数据类型分类
- \2. 数据转换
- \3. 装箱和拆箱
- \4. 判等问题
- \5. 数值计算
- 6. 参考资料
# #1. 数据类型分类
Java 中的数据类型有两类:
- 值类型(又叫内置数据类型,基本数据类型)
- 引用类型(除值类型以外,都是引用类型,包括
String、数组)
# #1.1. 值类型
Java 语言提供了 8 种基本类型,大致分为 4 类
| 基本数据类型 | 分类 | 比特数 | 默认值 | 取值范围 | 说明 |
|---|---|---|---|---|---|
boolean |
布尔型 | 8 位 | false |
||
char |
字符型 | 16 位 | '\u0000' |
[0, ] | 存储 Unicode 码,用单引号赋值 |
byte |
整数型 | 8 位 | 0 |
[-, ] | |
short |
整数型 | 16 位 | 0 |
[-, ] | |
int |
整数型 | 32 位 | 0 |
[-, ] | |
long |
整数型 | 64 位 | 0L |
[-, ] | 赋值时一般在数字后加上 l 或 L |
float |
浮点型 | 32 位 | +0.0F |
[, ] | 赋值时必须在数字后加上 f 或 F |
double |
浮点型 | 64 位 | +0.0D |
[, ] | 赋值时一般在数字后加 d 或 D |
尽管各种数据类型的默认值看起来不一样,但在内存中都是 0。
在这些基本类型中, boolean 和 char 是唯二的无符号类型。
# #1.2. 值类型和引用类型的区别
- 从概念方面来说
- 基本类型:变量名指向具体的数值。
- 引用类型:变量名指向存数据对象的内存地址。
- 从内存方面来说
- 基本类型:变量在声明之后,Java 就会立刻分配给他内存空间。
- 引用类型:它以特殊的方式(类似 C 指针)向对象实体(具体的值),这类变量声明时不会分配内存,只是存储了一个内存地址。
- 从使用方面来说
- 基本类型:使用时需要赋具体值,判断时使用
==号。 - 引用类型:使用时可以赋 null,判断时使用
equals方法。
- 基本类型:使用时需要赋具体值,判断时使用
👉 扩展阅读:Java 基本数据类型和引用类型 (opens new window)
这篇文章对于基本数据类型和引用类型的内存存储讲述比较生动。
# #2. 数据转换
Java 中,数据类型转换有两种方式:
- 自动转换
- 强制转换
# #2.1. 自动转换
一般情况下,定义了某数据类型的变量,就不能再随意转换。但是 JAVA 允许用户对基本类型做有限度的类型转换。
如果符合以下条件,则 JAVA 将会自动做类型转换:
-
由小数据转换为大数据
显而易见的是,“小” 数据类型的数值表示范围小于 “大” 数据类型的数值表示范围,即精度小于 “大” 数据类型。
所以,如果 “大” 数据向 “小” 数据转换,会丢失数据精度。比如:long 转为 int,则超出 int 表示范围的数据将会丢失,导致结果的不确定性。
反之,“小” 数据向 “大” 数据转换,则不会存在数据丢失情况。由于这个原因,这种类型转换也称为扩大转换。
这些类型由 “小” 到 “大” 分别为:(byte,short,char) < int < long < float < double。
这里我们所说的 “大” 与 “小”,并不是指占用字节的多少,而是指表示值的范围的大小。
-
转换前后的数据类型要兼容
由于 boolean 类型只能存放 true 或 false,这与整数或字符是不兼容的,因此不可以做类型转换。
-
整型类型和浮点型进行计算后,结果会转为浮点类型
示例:
long x = 30;
float y = 14.3f;
System.out.println("x/y = " + x/y);输出:
x/y = 1.9607843可见 long 虽然精度大于 float 类型,但是结果为浮点数类型。
# #2.2. 强制转换
在不符合自动转换条件时或者根据用户的需要,可以对数据类型做强制的转换。
强制转换使用括号 () 。
引用类型也可以使用强制转换。
示例:
float f = 25.5f;
int x = (int)f;
System.out.println("x = " + x);# #3. 装箱和拆箱
# #3.1. 包装类、装箱、拆箱
Java 中为每一种基本数据类型提供了相应的包装类,如下:
Byte <-> byte
Short <-> short
Integer <-> int
Long <-> long
Float <-> float
Double <-> double
Character <-> char
Boolean <-> boolean引入包装类的目的就是:提供一种机制,使得基本数据类型可以与引用类型互相转换。
基本数据类型与包装类的转换被称为 装箱 和 拆箱 。
-
装箱(boxing)是将值类型转换为引用类型。例如:
int转Integer- 装箱过程是通过调用包装类的
valueOf方法实现的。
- 装箱过程是通过调用包装类的
-
拆箱(unboxing)是将引用类型转换为值类型。例如:
Integer转int- 拆箱过程是通过调用包装类的
xxxValue方法实现的。(xxx 代表对应的基本数据类型)。
- 拆箱过程是通过调用包装类的
# #3.2. 自动装箱、自动拆箱
基本数据(Primitive)型的自动装箱(boxing)拆箱(unboxing)自 JDK 5 开始提供的功能。
自动装箱与拆箱的机制可以让我们在 Java 的变量赋值或者是方法调用等情况下使用原始类型或者对象类型更加简单直接。 因为自动装箱会隐式地创建对象,如果在一个循环体中,会创建无用的中间对象,这样会增加 GC 压力,拉低程序的性能。所以在写循环时一定要注意代码,避免引入不必要的自动装箱操作。
JDK 5 之前的形式:
Integer i1 = new Integer(10); // 非自动装箱JDK 5 之后:
Integer i2 = 10; // 自动装箱Java 对于自动装箱和拆箱的设计,依赖于一种叫做享元模式的设计模式(有兴趣的朋友可以去了解一下源码,这里不对设计模式展开详述)。
👉 扩展阅读:深入剖析 Java 中的装箱和拆箱 (opens new window)
结合示例,一步步阐述装箱和拆箱原理。
# #3.3. 装箱、拆箱的应用和注意点
# #装箱、拆箱应用场景
- 一种最普通的场景是:调用一个含类型为
Object参数的方法,该Object可支持任意类型(因为Object是所有类的父类),以便通用。当你需要将一个值类型(如 int)传入时,需要使用Integer装箱。 - 另一种用法是:一个非泛型的容器,同样是为了保证通用,而将元素类型定义为
Object。于是,要将值类型数据加入容器时,需要装箱。 - 当
==运算符的两个操作,一个操作数是包装类,另一个操作数是表达式(即包含算术运算)则比较的是数值(即会触发自动拆箱的过程)。
【示例】装箱、拆箱示例
Integer i1 = 10; // 自动装箱
Integer i2 = new Integer(10); // 非自动装箱
Integer i3 = Integer.valueOf(10); // 非自动装箱
int i4 = new Integer(10); // 自动拆箱
int i5 = i2.intValue(); // 非自动拆箱
System.out.println("i1 = [" + i1 + "]");
System.out.println("i2 = [" + i2 + "]");
System.out.println("i3 = [" + i3 + "]");
System.out.println("i4 = [" + i4 + "]");
System.out.println("i5 = [" + i5 + "]");
System.out.println("i1 == i2 is [" + (i1 == i2) + "]");
System.out.println("i1 == i4 is [" + (i1 == i4) + "]"); // 自动拆箱
// Output:
// i1 = [10]
// i2 = [10]
// i3 = [10]
// i4 = [10]
// i5 = [10]
// i1 == i2 is [false]
// i1 == i4 is [true]【说明】
上面的例子,虽然简单,但却隐藏了自动装箱、拆箱和非自动装箱、拆箱的应用。从例子中可以看到,明明所有变量都初始化为数值 10 了,但为何会出现 i1 == i2 is [false 而 i1 == i4 is [true] ?
原因在于:
- i1、i2 都是包装类,使用
==时,Java 将它们当做两个对象,而非两个 int 值来比较,所以两个对象自然是不相等的。正确的比较操作应该使用equals方法。 - i1 是包装类,i4 是基础数据类型,使用
==时,Java 会将两个 i1 这个包装类对象自动拆箱为一个int值,再代入到==运算表达式中计算;最终,相当于两个int进行比较,由于值相同,所以结果相等。
【示例】包装类判等问题
Integer a = 127; //Integer.valueOf(127)
Integer b = 127; //Integer.valueOf(127)
log.info("\nInteger a = 127;\nInteger b = 127;\na == b ? {}", a == b); // true
Integer c = 128; //Integer.valueOf(128)
Integer d = 128; //Integer.valueOf(128)
log.info("\nInteger c = 128;\nInteger d = 128;\nc == d ? {}", c == d); //false
//设置-XX:AutoBoxCacheMax=1000再试试
Integer e = 127; //Integer.valueOf(127)
Integer f = new Integer(127); //new instance
log.info("\nInteger e = 127;\nInteger f = new Integer(127);\ne == f ? {}", e == f); //false
Integer g = new Integer(127); //new instance
Integer h = new Integer(127); //new instance
log.info("\nInteger g = new Integer(127);\nInteger h = new Integer(127);\ng == h ? {}", g == h); //false
Integer i = 128; //unbox
int j = 128;
log.info("\nInteger i = 128;\nint j = 128;\ni == j ? {}", i == j); //true通过运行结果可以看到,虽然看起来永远是在对 127 和 127、128 和 128 判等,但 == 却并非总是返回 true。
# #装箱、拆箱应用注意点
- 装箱操作会创建对象,频繁的装箱操作会造成不必要的内存消耗,影响性能。所以应该尽量避免装箱。
- 基础数据类型的比较操作使用
==,包装类的比较操作使用equals方法。
# #4. 判等问题
Java 中,通常使用 equals 或 == 进行判等操作。 equals 是方法而 == 是操作符。此外,二者使用也是有区别的:
- 对基本类型,比如
int、long,进行判等,只能使用==,比较的是字面值。因为基本类型的值就是其数值。 - 对引用类型,比如
Integer、Long和String,进行判等,需要使用equals进行内容判等。因为引用类型的直接值是指针,使用==的话,比较的是指针,也就是两个对象在内存中的地址,即比较它们是不是同一个对象,而不是比较对象的内容。
# #4.1. 包装类的判等
我们通过一个示例来深入研究一下判等问题。
【示例】包装类的判等
Integer a = 127; //Integer.valueOf(127)
Integer b = 127; //Integer.valueOf(127)
log.info("\nInteger a = 127;\nInteger b = 127;\na == b ? {}", a == b); // true
Integer c = 128; //Integer.valueOf(128)
Integer d = 128; //Integer.valueOf(128)
log.info("\nInteger c = 128;\nInteger d = 128;\nc == d ? {}", c == d); //false
//设置-XX:AutoBoxCacheMax=1000再试试
Integer e = 127; //Integer.valueOf(127)
Integer f = new Integer(127); //new instance
log.info("\nInteger e = 127;\nInteger f = new Integer(127);\ne == f ? {}", e == f); //false
Integer g = new Integer(127); //new instance
Integer h = new Integer(127); //new instance
log.info("\nInteger g = new Integer(127);\nInteger h = new Integer(127);\ng == h ? {}", g == h); //false
Integer i = 128; //unbox
int j = 128;
log.info("\nInteger i = 128;\nint j = 128;\ni == j ? {}", i == j); //true第一个案例中,编译器会把 Integer a = 127 转换为 Integer.valueOf (127)。查看源码可以发现,这个转换在内部其实做了缓存,使得两个 Integer 指向同一个对象,所以 == 返回 true。
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}第二个案例中,之所以同样的代码 128 就返回 false 的原因是,默认情况下会缓存 [-128,127] 的数值,而 128 处于这个区间之外。设置 JVM 参数加上 -XX:AutoBoxCacheMax=1000 再试试,是不是就返回 true 了呢?
private static class IntegerCache {
static final int low = -128;
static final int high;
static final Integer cache[];
static {
// high value may be configured by property
int h = 127;
String integerCacheHighPropValue =
sun.misc.VM.getSavedProperty("java.lang.Integer.IntegerCache.high");
if (integerCacheHighPropValue != null) {
try {
int i = parseInt(integerCacheHighPropValue);
i = Math.max(i, 127);
// Maximum array size is Integer.MAX_VALUE
h = Math.min(i, Integer.MAX_VALUE - (-low) -1);
} catch( NumberFormatException nfe) {
// If the property cannot be parsed into an int, ignore it.
}
}
high = h;
cache = new Integer[(high - low) + 1];
int j = low;
for(int k = 0; k < cache.length; k++)
cache[k] = new Integer(j++);
// range [-128, 127] must be interned (JLS7 5.1.7)
assert IntegerCache.high >= 127;
}
private IntegerCache() {}
}第三和第四个案例中,New 出来的 Integer 始终是不走缓存的新对象。比较两个新对象,或者比较一个新对象和一个来自缓存的对象,结果肯定不是相同的对象,因此返回 false。
第五个案例中,我们把装箱的 Integer 和基本类型 int 比较,前者会先拆箱再比较,比较的肯定是数值而不是引用,因此返回 true。
【总结】综上,我们可以得出结论:包装类需要使用
equals进行内容判等,而不能使用==。
# #4.2. String 的判等
String a = "1";
String b = "1";
log.info("\nString a = \"1\";\nString b = \"1\";\na == b ? {}", a == b); //true
String c = new String("2");
String d = new String("2");
log.info("\nString c = new String(\"2\");\nString d = new String(\"2\");\nc == d ? {}", c == d); //false
String e = new String("3").intern();
String f = new String("3").intern();
log.info("\nString e = new String(\"3\").intern();\nString f = new String(\"3\").intern();\ne == f ? {}", e == f); //true
String g = new String("4");
String h = new String("4");
log.info("\nString g = new String(\"4\");\nString h = new String(\"4\");\ng == h ? {}", g.equals(h)); //true在 JVM 中,当代码中出现双引号形式创建字符串对象时,JVM 会先对这个字符串进行检查,如果字符串常量池中存在相同内容的字符串对象的引用,则将这个引用返回;否则,创建新的字符串对象,然后将这个引用放入字符串常量池,并返回该引用。这种机制,就是字符串驻留或池化。
第一个案例返回 true,因为 Java 的字符串驻留机制,直接使用双引号声明出来的两个 String 对象指向常量池中的相同字符串。
第二个案例,new 出来的两个 String 是不同对象,引用当然不同,所以得到 false 的结果。
第三个案例,使用 String 提供的 intern 方法也会走常量池机制,所以同样能得到 true。
第四个案例,通过 equals 对值内容判等,是正确的处理方式,当然会得到 true。
虽然使用 new 声明的字符串调用 intern 方法,也可以让字符串进行驻留,但在业务代码中滥用 intern,可能会产生性能问题。
【示例】String#intern 性能测试
//-XX:+PrintStringTableStatistics
//-XX:StringTableSize=10000000
List<String> list = new ArrayList<>();
long begin = System.currentTimeMillis();
list = IntStream.rangeClosed(1, 10000000)
.mapToObj(i -> String.valueOf(i).intern())
.collect(Collectors.toList());
System.out.println("size:" + list.size());
System.out.println("time:" + (System.currentTimeMillis() - begin));上面的示例执行时间会比较长。原因在于:字符串常量池是一个固定容量的 Map。如果容量太小(Number of buckets=60013)、字符串太多(1000 万个字符串),那么每一个桶中的字符串数量会非常多,所以搜索起来就很慢。输出结果中的 Average bucket size=167,代表了 Map 中桶的平均长度是 167。
解决方法是:设置 JVM 参数 -XX:StringTableSize=10000000,指定更多的桶。
为了方便观察,可以在启动程序时设置 JVM 参数 -XX:+PrintStringTableStatistic,程序退出时可以打印出字符串常量表的统计信息。
执行结果比不设置 -XX:StringTableSize 要快很多。
【总结】没事别轻易用 intern,如果要用一定要注意控制驻留的字符串的数量,并留意常量表的各项指标。
# #4.3. 实现 equals
如果看过 Object 类源码,你可能就知道,equals 的实现其实是比较对象引用
public boolean equals(Object obj) {
return (this == obj);
}之所以 Integer 或 String 能通过 equals 实现内容判等,是因为它们都覆写了这个方法。
对于自定义类型,如果不覆写 equals 的话,默认就是使用 Object 基类的按引用的比较方式。
实现一个更好的 equals 应该注意的点:
- 考虑到性能,可以先进行指针判等,如果对象是同一个那么直接返回 true;
- 需要对另一方进行判空,空对象和自身进行比较,结果一定是 fasle;
- 需要判断两个对象的类型,如果类型都不同,那么直接返回 false;
- 确保类型相同的情况下再进行类型强制转换,然后逐一判断所有字段。
【示例】自定义 equals 示例
自定义类:
class Point {
private final int x;
private final int y;
private final String desc;
}自定义 equals:
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Point that = (Point) o;
return x == that.x && y == that.y;
}# #4.4. hashCode 和 equals 要配对实现
Point p1 = new Point(1, 2, "a");
Point p2 = new Point(1, 2, "b");
HashSet<PointWrong> points = new HashSet<>();
points.add(p1);
log.info("points.contains(p2) ? {}", points.contains(p2));按照改进后的 equals 方法,这 2 个对象可以认为是同一个,Set 中已经存在了 p1 就应该包含 p2,但结果却是 false。
出现这个 Bug 的原因是,散列表需要使用 hashCode 来定位元素放到哪个桶。如果自定义对象没有实现自定义的 hashCode 方法,就会使用 Object 超类的默认实现,得到的两个 hashCode 是不同的,导致无法满足需求。
要自定义 hashCode,我们可以直接使用 Objects.hash 方法来实现。
@Override
public int hashCode() {
return Objects.hash(x, y);
}# #4.5. compareTo 和 equals 的逻辑一致性
【示例】自定义 compareTo 出错示例
@Data
@AllArgsConstructor
static class Student implements Comparable<Student> {
private int id;
private String name;
@Override
public int compareTo(Student other) {
int result = Integer.compare(other.id, id);
if (result == 0) { log.info("this {} == other {}", this, other); }
return result;
}
}调用:
List<Student> list = new ArrayList<>();
list.add(new Student(1, "zhang"));
list.add(new Student(2, "wang"));
Student student = new Student(2, "li");
log.info("ArrayList.indexOf");
int index1 = list.indexOf(student);
Collections.sort(list);
log.info("Collections.binarySearch");
int index2 = Collections.binarySearch(list, student);
log.info("index1 = " + index1);
log.info("index2 = " + index2);binarySearch 方法内部调用了元素的 compareTo 方法进行比较;
- indexOf 的结果没问题,列表中搜索不到 id 为 2、name 是 li 的学生;
- binarySearch 返回了索引 1,代表搜索到的结果是 id 为 2,name 是 wang 的学生。
修复方式很简单,确保 compareTo 的比较逻辑和 equals 的实现一致即可。
@Data
@AllArgsConstructor
static class StudentRight implements Comparable<StudentRight> {
private int id;
private String name;
@Override
public int compareTo(StudentRight other) {
return Comparator.comparing(StudentRight::getName)
.thenComparingInt(StudentRight::getId)
.compare(this, other);
}
}# #4.6. 小心 Lombok 生成代码的 “坑”
Lombok 的 @Data 注解会帮我们实现 equals 和 hashcode 方法,但是有继承关系时, Lombok 自动生成的方法可能就不是我们期望的了。
@EqualsAndHashCode 默认实现没有使用父类属性。为解决这个问题,我们可以手动设置 callSuper 开关为 true,来覆盖这种默认行为。
# #5. 数值计算
# #5.1. 浮点数计算问题
计算机是把数值保存在了变量中,不同类型的数值变量能保存的数值范围不同,当数值超过类型能表达的数值上限则会发生溢出问题。
System.out.println(0.1 + 0.2); // 0.30000000000000004
System.out.println(1.0 - 0.8); // 0.19999999999999996
System.out.println(4.015 * 100); // 401.49999999999994
System.out.println(123.3 / 100); // 1.2329999999999999
double amount1 = 2.15;
double amount2 = 1.10;
System.out.println(amount1 - amount2); // 1.0499999999999998上面的几个示例,输出结果和我们预期的很不一样。为什么会是这样呢?
出现这种问题的主要原因是,计算机是以二进制存储数值的,浮点数也不例外。Java 采用了 IEEE 754 标准实现浮点数的表达和运算,你可以通过这里查看数值转化为二进制的结果。
比如,0.1 的二进制表示为 0.0 0011 0011 0011… (0011 无限循环),再转换为十进制就是 0.1000000000000000055511151231257827021181583404541015625。对于计算机而言,0.1 无法精确表达,这是浮点数计算造成精度损失的根源。
浮点数无法精确表达和运算的场景,一定要使用 BigDecimal 类型。
使用 BigDecimal 时,有个细节要格外注意。让我们来看一段代码:
System.out.println(new BigDecimal(0.1).add(new BigDecimal(0.2)));
// Output: 0.3000000000000000166533453693773481063544750213623046875
System.out.println(new BigDecimal(1.0).subtract(new BigDecimal(0.8)));
// Output: 0.1999999999999999555910790149937383830547332763671875
System.out.println(new BigDecimal(4.015).multiply(new BigDecimal(100)));
// Output: 401.49999999999996802557689079549163579940795898437500
System.out.println(new BigDecimal(123.3).divide(new BigDecimal(100)));
// Output: 1.232999999999999971578290569595992565155029296875为什么输出结果仍然不符合预期呢?
使用 BigDecimal 表示和计算浮点数,且务必使用字符串的构造方法来初始化 BigDecimal。
# #5.2. 浮点数精度和格式化
浮点数的字符串格式化也要通过 BigDecimal 进行。
private static void wrong1() {
double num1 = 3.35;
float num2 = 3.35f;
System.out.println(String.format("%.1f", num1)); // 3.4
System.out.println(String.format("%.1f", num2)); // 3.3
}
private static void wrong2() {
double num1 = 3.35;
float num2 = 3.35f;
DecimalFormat format = new DecimalFormat("#.##");
format.setRoundingMode(RoundingMode.DOWN);
System.out.println(format.format(num1)); // 3.35
format.setRoundingMode(RoundingMode.DOWN);
System.out.println(format.format(num2)); // 3.34
}
private static void right() {
BigDecimal num1 = new BigDecimal("3.35");
BigDecimal num2 = num1.setScale(1, BigDecimal.ROUND_DOWN);
System.out.println(num2); // 3.3
BigDecimal num3 = num1.setScale(1, BigDecimal.ROUND_HALF_UP);
System.out.println(num3); // 3.4
}# #5.3. BigDecimal 判等问题
private static void wrong() {
System.out.println(new BigDecimal("1.0").equals(new BigDecimal("1")));
}
private static void right() {
System.out.println(new BigDecimal("1.0").compareTo(new BigDecimal("1")) == 0);
}BigDecimal 的 equals 方法的注释中说明了原因,equals 比较的是 BigDecimal 的 value 和 scale,1.0 的 scale 是 1,1 的 scale 是 0,所以结果一定是 false。
如果我们希望只比较 BigDecimal 的 value,可以使用 compareTo 方法。
BigDecimal 的 equals 和 hashCode 方法会同时考虑 value 和 scale,如果结合 HashSet 或 HashMap 使用的话就可能会出现麻烦。比如,我们把值为 1.0 的 BigDecimal 加入 HashSet,然后判断其是否存在值为 1 的 BigDecimal,得到的结果是 false。
Set<BigDecimal> hashSet1 = new HashSet<>();
hashSet1.add(new BigDecimal("1.0"));
System.out.println(hashSet1.contains(new BigDecimal("1")));//返回false解决办法有两个:
第一个方法是,使用 TreeSet 替换 HashSet。TreeSet 不使用 hashCode 方法,也不使用 equals 比较元素,而是使用 compareTo 方法,所以不会有问题。
第二个方法是,把 BigDecimal 存入 HashSet 或 HashMap 前,先使用 stripTrailingZeros 方法去掉尾部的零,比较的时候也去掉尾部的 0,确保 value 相同的 BigDecimal,scale 也是一致的。
Set<BigDecimal> hashSet2 = new HashSet<>();
hashSet2.add(new BigDecimal("1.0").stripTrailingZeros());
System.out.println(hashSet2.contains(new BigDecimal("1.000").stripTrailingZeros()));//返回true
Set<BigDecimal> treeSet = new TreeSet<>();
treeSet.add(new BigDecimal("1.0"));
System.out.println(treeSet.contains(new BigDecimal("1")));//返回true# #5.4. 数值溢出
数值计算还有一个要小心的点是溢出,不管是 int 还是 long,所有的基本数值类型都有超出表达范围的可能性。
long l = Long.MAX_VALUE;
System.out.println(l + 1); // -9223372036854775808
System.out.println(l + 1 == Long.MIN_VALUE); // true显然这是发生了溢出,而且是默默的溢出,并没有任何异常。这类问题非常容易被忽略,改进方式有下面 2 种。
方法一是,考虑使用 Math 类的 addExact、subtractExact 等 xxExact 方法进行数值运算,这些方法可以在数值溢出时主动抛出异常。
try {
long l = Long.MAX_VALUE;
System.out.println(Math.addExact(l, 1));
} catch (Exception ex) {
ex.printStackTrace();
}方法二是,使用大数类 BigInteger。BigDecimal 是处理浮点数的专家,而 BigInteger 则是对大数进行科学计算的专家。
BigInteger i = new BigInteger(String.valueOf(Long.MAX_VALUE));
System.out.println(i.add(BigInteger.ONE).toString());
try {
long l = i.add(BigInteger.ONE).longValueExact();
} catch (Exception ex) {
ex.printStackTrace();
}# 深入理解 Java String 类型
📦 本文以及示例源码已归档在 javacore(opens new window)
String 类型可能是 Java 中应用最频繁的引用类型,但它的性能问题却常常被忽略。高效的使用字符串,可以提升系统的整体性能。当然,要做到高效使用字符串,需要深入了解其特性。
-
- String 的性能考量
# #1. String 的不可变性
我们先来看下 String 的定义:
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final char value[];String 类被 final 关键字修饰,表示不可继承 String 类。
String 类的数据存储于 char[] 数组,这个数组被 final 关键字修饰,表示 String 对象不可被更改。
为什么 Java 要这样设计?
(1)保证 String 对象安全性。避免 String 被篡改。
(2)保证 hash 值不会频繁变更。
(3)可以实现字符串常量池。通常有两种创建字符串对象的方式,一种是通过字符串常量的方式创建,如 String str="abc"; 另一种是字符串变量通过 new 形式的创建,如 String str = new String("abc") 。
使用第一种方式创建字符串对象时,JVM 首先会检查该对象是否在字符串常量池中,如果在,就返回该对象引用,否则新的字符串将在常量池中被创建。这种方式可以减少同一个值的字符串对象的重复创建,节约内存。
String str = new String("abc") 这种方式,首先在编译类文件时, "abc" 常量字符串将会放入到常量结构中,在类加载时, "abc" 将会在常量池中创建;其次,在调用 new 时,JVM 命令将会调用 String 的构造函数,同时引用常量池中的 "abc" 字符串,在堆内存中创建一个 String 对象;最后,str 将引用 String 对象。
# #2. String 的性能考量
# #2.1. 字符串拼接
字符串常量的拼接,编译器会将其优化为一个常量字符串。
【示例】字符串常量拼接
public static void main(String[] args) {
// 本行代码在 class 文件中,会被编译器直接优化为:
// String str = "abc";
String str = "a" + "b" + "c";
System.out.println("str = " + str);
}字符串变量的拼接,编译器会优化成 StringBuilder 的方式。
【示例】字符串变量的拼接
public static void main(String[] args) {
String str = "";
for(int i=0; i<1000; i++) {
// 本行代码会被编译器优化为:
// str = (new StringBuilder(String.valueOf(str))).append(i).toString();
str = str + i;
}
}但是,每次循环都会生成一个新的 StringBuilder 实例,同样也会降低系统的性能。
字符串拼接的正确方案:
- 如果需要使用字符串拼接,应该优先考虑
StringBuilder的append方法替代使用+号。 - 如果在并发编程中,
String对象的拼接涉及到线程安全,可以使用StringBuffer。但是要注意,由于StringBuffer是线程安全的,涉及到锁竞争,所以从性能上来说,要比StringBuilder差一些。
# #2.2. 字符串分割
String 的 split() 方法使用正则表达式实现其强大的分割功能。而正则表达式的性能是非常不稳定的,使用不恰当会引起回溯问题,很可能导致 CPU 居高不下。
所以,应该慎重使用 split() 方法,可以考虑用 String.indexOf() 方法代替 split() 方法完成字符串的分割。如果实在无法满足需求,你就在使用 Split () 方法时,对回溯问题加以重视就可以了。
# #2.3. String.intern
在每次赋值的时候使用 String 的 intern 方法,如果常量池中有相同值,就会重复使用该对象,返回对象引用,这样一开始的对象就可以被回收掉。
在字符串常量中,默认会将对象放入常量池;在字符串变量中,对象是会创建在堆内存中,同时也会在常量池中创建一个字符串对象,复制到堆内存对象中,并返回堆内存对象引用。
如果调用 intern 方法,会去查看字符串常量池中是否有等于该对象的字符串,如果没有,就在常量池中新增该对象,并返回该对象引用;如果有,就返回常量池中的字符串引用。堆内存中原有的对象由于没有引用指向它,将会通过垃圾回收器回收。
【示例】
public class SharedLocation {
private String city;
private String region;
private String countryCode;
}
SharedLocation sharedLocation = new SharedLocation();
sharedLocation.setCity(messageInfo.getCity().intern()); sharedLocation.setCountryCode(messageInfo.getRegion().intern());
sharedLocation.setRegion(messageInfo.getCountryCode().intern());使用
intern方法需要注意:一定要结合实际场景。因为常量池的实现是类似于一个 HashTable 的实现方式,HashTable 存储的数据越大,遍历的时间复杂度就会增加。如果数据过大,会增加整个字符串常量池的负担。
# #3. String、StringBuffer、StringBuilder 有什么区别
String 是 Java 语言非常基础和重要的类,提供了构造和管理字符串的各种基本逻辑。它是典型的 Immutable 类,被声明成为 final class ,所有属性也都是 final 的。也由于它的不可变性,类似拼接、裁剪字符串等动作,都会产生新的 String 对象。由于字符串操作的普遍性,所以相关操作的效率往往对应用性能有明显影响。
StringBuffer 是为解决上面提到拼接产生太多中间对象的问题而提供的一个类,我们可以用 append 或者 add 方法,把字符串添加到已有序列的末尾或者指定位置。 StringBuffer 是一个线程安全的可修改字符序列。 StringBuffer 的线程安全是通过在各种修改数据的方法上用 synchronized 关键字修饰实现的。
StringBuilder 是 Java 1.5 中新增的,在能力上和 StringBuffer 没有本质区别,但是它去掉了线程安全的部分,有效减小了开销,是绝大部分情况下进行字符串拼接的首选。
StringBuffer 和 StringBuilder 底层都是利用可修改的(char,JDK 9 以后是 byte)数组,二者都继承了 AbstractStringBuilder ,里面包含了基本操作,区别仅在于最终的方法是否加了 synchronized 。构建时初始字符串长度加 16(这意味着,如果没有构建对象时输入最初的字符串,那么初始值就是 16)。我们如果确定拼接会发生非常多次,而且大概是可预计的,那么就可以指定合适的大小,避免很多次扩容的开销。扩容会产生多重开销,因为要抛弃原有数组,创建新的(可以简单认为是倍数)数组,还要进行 arraycopy 。
除非有线程安全的需要,不然一般都使用 StringBuilder
# Java 面向对象
在深入理解 Java 基本数据类型 (opens new window) 中我们了解 Java 中支持的基本数据类型(值类型)。本文开始讲解 Java 中重要的引用类型 —— 类。
📦 本文以及示例源码已归档在 javacore(opens new window)
-
- 面向对象
-
- 方法
-
- 变量
-
- 访问权限控制
# #1. 面向对象
每种编程语言,都有自己的操纵内存中元素的方式。
Java 中提供了基本数据类型 (opens new window),但这还不能满足编写程序时,需要抽象更加复杂数据类型的需要。因此,Java 中,允许开发者通过类(类的机制下面会讲到)创建自定义类型。
有了自定义类型,那么数据类型自然会千变万化,所以,必须要有一定的机制,使得它们仍然保持一些必要的、通用的特性。
Java 世界有一句名言:一切皆为对象。这句话,你可能第一天学 Java 时,就听过了。这不仅仅是一句口号,也体现在 Java 的设计上。
- 首先,所有 Java 类都继承自
Object类(从这个名字,就可见一斑)。 - 几乎所有 Java 对象初始化时,都要使用
new创建对象(基本数据类型 (opens new window)、String、枚举特殊处理),对象存储在堆中。
// 下面两
String s = "abc";
String s = new String("abc");其中, String s 定义了一个名为 s 的引用,它指向一个 String 类型的对象,而实际的对象是 “abc” 字符串。这就像是,使用遥控器(引用)来操纵电视机(对象)。
与 C/C++ 这类语言不同,程序员只需要通过 new 创建一个对象,但不必负责销毁或结束一个对象。负责运行 Java 程序的 Java 虚拟机有一个垃圾回收器,它会监视 new 创建的对象,一旦发现对象不再被引用,则会释放对象的内存空间。
# #1.1. 封装
封装(Encapsulation)是指一种将抽象性函式接口的实现细节部份包装、隐藏起来的方法。
封装最主要的作用在于我们能修改自己的实现代码,而不用修改那些调用我们代码的程序片段。
适当的封装可以让程式码更容易理解与维护,也加强了程式码的安全性。
封装的优点:
- 良好的封装能够减少耦合。
- 类内部的结构可以自由修改。
- 可以对成员变量进行更精确的控制。
- 隐藏信息,实现细节。
实现封装的步骤:
- 修改属性的可见性来限制对属性的访问(一般限制为 private)。
- 对每个值属性提供对外的公共方法访问,也就是创建一对赋取值方法,用于对私有属性的访问。
# #1.2. 继承
继承是 java 面向对象编程技术的一块基石,因为它允许创建分等级层次的类。
继承就是子类继承父类的特征和行为,使得子类对象(实例)具有父类的实例域和方法,或子类从父类继承方法,使得子类具有父类相同的行为。
现实中的例子:
狗和鸟都是动物。如果将狗、鸟作为类,它们可以继承动物类。
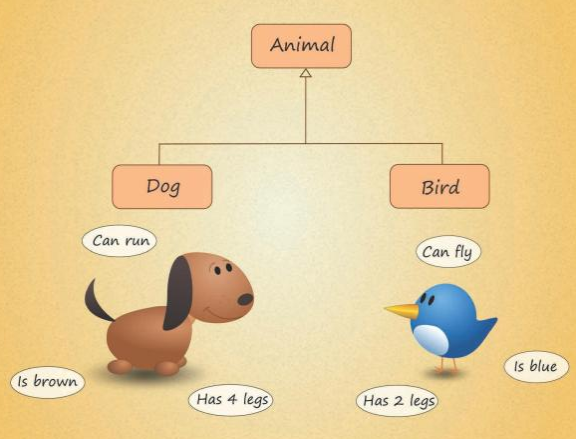
类的继承形式:
class 父类 {}
class 子类 extends 父类 {}# #继承类型
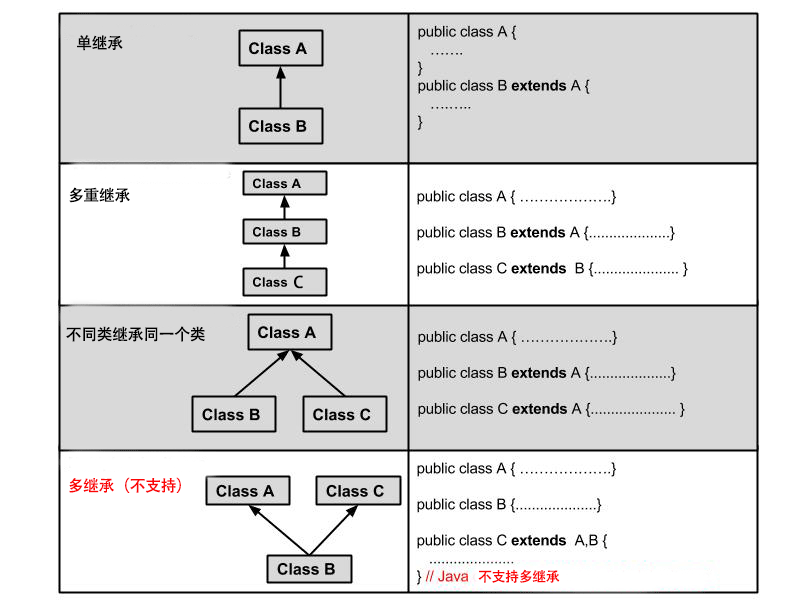
# #继承的特性
- 子类拥有父类非 private 的属性、方法。
- 子类可以拥有自己的属性和方法,即子类可以对父类进行扩展。
- 子类可以用自己的方式实现父类的方法。
- Java 的继承是单继承,但是可以多重继承,单继承就是一个子类只能继承一个父类,多重继承就是,例如 A 类继承 B 类,B 类继承 C 类,所以按照关系就是 C 类是 B 类的父类,B 类是 A 类的父类,这是 Java 继承区别于 C++ 继承的一个特性。
- 提高了类之间的耦合性(继承的缺点,耦合度高就会造成代码之间的联系越紧密,代码独立性越差)。
# #继承关键字
继承可以使用 extends 和 implements 这两个关键字来实现继承,而且所有的类都是继承于 java.lang.Object,当一个类没有继承的两个关键字,则默认继承 object(这个类在 java.lang 包中,所以不需要 import)祖先类。
# #1.3. 多态
刚开始学习面向对象编程时,容易被各种术语弄得云里雾里。所以,很多人会死记硬背书中对于术语的定义。
但是,随着应用和理解的深入,应该会渐渐有更进一步的认识,将其融汇贯通的理解。
学习类之前,先让我们思考一个问题:Java 中为什么要引入类机制,设计的初衷是什么?
Java 中提供的基本数据类型,只能表示单一的数值,这用于数值计算,还 OK。但是,如果要抽象模拟现实中更复杂的事物,则无法做到。
试想,如果要让你抽象狗的数据模型,怎么做?狗有眼耳口鼻等器官,有腿,狗有大小,毛色,这些都是它的状态,狗会跑、会叫、会吃东西,这些是它的行为。
类的引入,就是为了抽象这种相对复杂的事物。
对象是用于计算机语言对问题域中事物的描述。对象通过方法和属性来分别描述事物所具有的行为和状态。
类是用于描述同一类的对象的一个抽象的概念,类中定义了这一类对象所具有的行为和状态。
类可以看成是创建 Java 对象的模板。
什么是方法?扩展阅读:面向对象编程的弊端是什么? - invalid s 的回答 (opens new window)
# #2. 类
与大多数面向对象编程语言一样,Java 使用 class (类)关键字来表示自定义类型。自定义类型是为了更容易抽象现实事物。
在一个类中,可以设置一静一动两种元素:属性(静)和方法(动)。
- 属性(有的人喜欢称为成员、字段) - 属性抽象的是事物的状态。类属性可以是任何类型的对象。
- 方法(有的人喜欢称为函数) - 方法抽象的是事物的行为。
类的形式如下:
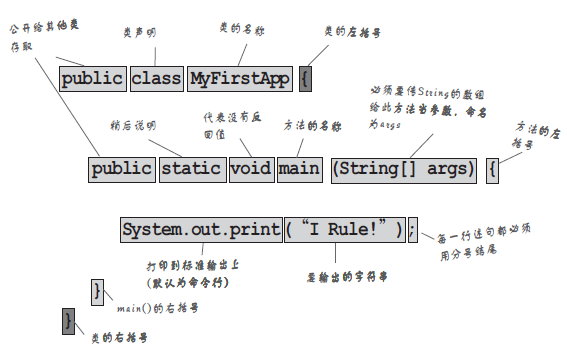
# #3. 方法
# #3.1. 方法定义
修饰符 返回值类型 方法名(参数类型 参数名){
...
方法体
...
return 返回值;
}方法包含一个方法头和一个方法体。下面是一个方法的所有部分:
- ** 修饰符:** 修饰符,这是可选的,告诉编译器如何调用该方法。定义了该方法的访问类型。
- ** 返回值类型 :** 方法可能有返回值。如果没有返回值,这种情况下,返回值类型应设为 void。
- ** 方法名:** 是方法的实际名称。方法名和参数表共同构成方法签名。
- ** 参数类型:** 参数像是一个占位符。当方法被调用时,传递值给参数。这个值被称为实参或变量。参数列表是指方法的参数类型、顺序和参数的个数。参数是可选的,方法可以不包含任何参数。
- ** 方法体:** 方法体包含具体的语句,定义该方法的功能。
示例:
public static int add(int x, int y) {
return x + y;
}# #3.2. 方法调用
Java 支持两种调用方法的方式,根据方法是否返回值来选择。
当程序调用一个方法时,程序的控制权交给了被调用的方法。当被调用方法的返回语句执行或者到达方法体闭括号时候交还控制权给程序。
当方法返回一个值的时候,方法调用通常被当做一个值。例如:
int larger = max(30, 40);如果方法返回值是 void,方法调用一定是一条语句。例如,方法 println 返回 void。下面的调用是个语句:
System.out.println("Hello World");# #3.3. 构造方法
每个类都有构造方法。如果没有显式地为类定义任何构造方法,Java 编译器将会为该类提供一个默认构造方法。
在创建一个对象的时候,至少要调用一个构造方法。构造方法的名称必须与类同名,一个类可以有多个构造方法。
public class Puppy{
public Puppy(){
}
public Puppy(String name){
// 这个构造器仅有一个参数:name
}
}# #4. 变量
Java 支持的变量类型有:
局部变量- 类方法中的变量。实例变量(也叫成员变量)- 类方法外的变量,不过没有static修饰。类变量(也叫静态变量)- 类方法外的变量,用static修饰。
特性对比:
| 局部变量 | 实例变量(也叫成员变量) | 类变量(也叫静态变量) |
|---|---|---|
| 局部变量声明在方法、构造方法或者语句块中。 | 实例变量声明在方法、构造方法和语句块之外。 | 类变量声明在方法、构造方法和语句块之外。并且以 static 修饰。 |
| 局部变量在方法、构造方法、或者语句块被执行的时候创建,当它们执行完成后,变量将会被销毁。 | 实例变量在对象创建的时候创建,在对象被销毁的时候销毁。 | 类变量在第一次被访问时创建,在程序结束时销毁。 |
| 局部变量没有默认值,所以必须经过初始化,才可以使用。 | 实例变量具有默认值。数值型变量的默认值是 0,布尔型变量的默认值是 false,引用类型变量的默认值是 null。变量的值可以在声明时指定,也可以在构造方法中指定。 | 类变量具有默认值。数值型变量的默认值是 0,布尔型变量的默认值是 false,引用类型变量的默认值是 null。变量的值可以在声明时指定,也可以在构造方法中指定。此外,静态变量还可以在静态语句块中初始化。 |
| 对于局部变量,如果是基本类型,会把值直接存储在栈;如果是引用类型,会把其对象存储在堆,而把这个对象的引用(指针)存储在栈。 | 实例变量存储在堆。 | 类变量存储在静态存储区。 |
| 访问修饰符不能用于局部变量。 | 访问修饰符可以用于实例变量。 | 访问修饰符可以用于类变量。 |
| 局部变量只在声明它的方法、构造方法或者语句块中可见。 | 实例变量对于类中的方法、构造方法或者语句块是可见的。一般情况下应该把实例变量设为私有。通过使用访问修饰符可以使实例变量对子类可见。 | 与实例变量具有相似的可见性。但为了对类的使用者可见,大多数静态变量声明为 public 类型。 |
| 实例变量可以直接通过变量名访问。但在静态方法以及其他类中,就应该使用完全限定名:ObejectReference.VariableName。 | 静态变量可以通过:ClassName.VariableName 的方式访问。 | |
| 无论一个类创建了多少个对象,类只拥有类变量的一份拷贝。 | ||
| 类变量除了被声明为常量外很少使用。 |
# #4.1. 变量修饰符
- 访问级别修饰符 - 如果变量是实例变量或类变量,可以添加访问级别修饰符(public/protected/private)
- 静态修饰符 - 如果变量是类变量,需要添加 static 修饰
- final - 如果变量使用 fianl 修饰符,就表示这是一个常量,不能被修改。
# #4.2. 创建对象
对象是根据类创建的。在 Java 中,使用关键字 new 来创建一个新的对象。创建对象需要以下三步:
- 声明:声明一个对象,包括对象名称和对象类型。
- 实例化:使用关键字 new 来创建一个对象。
- 初始化:使用 new 创建对象时,会调用构造方法初始化对象。
public class Puppy{
public Puppy(String name){
//这个构造器仅有一个参数:name
System.out.println("小狗的名字是 : " + name );
}
public static void main(String[] args){
// 下面的语句将创建一个Puppy对象
Puppy myPuppy = new Puppy( "tommy" );
}
}# #4.3. 访问实例变量和方法
/* 实例化对象 */
ObjectReference = new Constructor();
/* 访问类中的变量 */
ObjectReference.variableName;
/* 访问类中的方法 */
ObjectReference.methodName();# #5. 访问权限控制
# #5.1. 代码组织
当编译一个 .java 文件时,在 .java 文件中的每个类都会输出一个与类同名的 .class 文件。
MultiClassDemo.java 示例:
class MultiClass1 {}
class MultiClass2 {}
class MultiClass3 {}
public class MultiClassDemo {}执行 javac MultiClassDemo.java 命令,本地会生成 MultiClass1.class、MultiClass2.class、MultiClass3.class、MultiClassDemo.class 四个文件。
Java 可运行程序是由一组 .class 文件打包并压缩成的一个 .jar 文件。Java 解释器负责这些文件的查找、装载和解释。Java 类库实际上是一组类文件(.java 文件)。
- 其中每个文件允许有一个 public 类,以及任意数量的非 public 类。
- public 类名必须和 .java 文件名完全相同,包括大小写。
程序一般不止一个人编写,会调用系统提供的代码、第三方库中的代码、项目中其他人写的代码等,不同的人因为不同的目的可能定义同样的类名 / 接口名,这就是命名冲突。
Java 中为了解决命名冲突问题,提供了包( package )和导入( import )机制。
# #package
包( package )的原则:
- 包类似于文件夹,文件放在文件夹中,类和接口则放在包中。为了便于组织,文件夹一般是一个有层次的树形结构,包也类似。
- 包名以逗号
.分隔,表示层次结构。 - Java 中命名包名的一个惯例是使用域名作为前缀,因为域名是唯一的,一般按照域名的反序来定义包名,比如,域名是:apache.org,包名就以 org.apache 开头。
- ** 包名和文件目录结构必须完全匹配。**Java 解释器运行过程如下:
- 找出环境变量 CLASSPATH,作为 .class 文件的根目录。
- 从根目录开始,获取包名称,并将逗号
.替换为文件分隔符(反斜杠/),通过这个路径名称去查找 Java 类。
# #import
同一个包下的类之间互相引用是不需要包名的,可以直接使用。但如果类不在同一个包内,则必须要知道其所在的包,使用有两种方式:
- 通过类的完全限定名
- 通过 import 将用到的类引入到当前类
通过类的完全限定名示例:
public class PackageDemo {
public static void main (String[]args){
System.out.println(new java.util.Date());
System.out.println(new java.util.Date());
}
}通过 import 导入其它包的类到当前类:
import java.util.Date;
public class PackageDemo2 {
public static void main(String[] args) {
System.out.println(new Date());
System.out.println(new Date());
}
}说明:以上两个示例比较起来,显然是
import方式,代码更加整洁。
# #5.2. 访问权限修饰关键字
访问权限控制的等级,从最大权限到最小权限依次为:
public > protected > 包访问权限(没有任何关键字)> privatepublic- 表示任何类都可以访问;包访问权限- 包访问权限,没有任何关键字。它表示当前包中的所有其他类都可以访问,但是其它包的类无法访问。protected- 表示子类可以访问,此外,同一个包内的其他类也可以访问,即使这些类不是子类。private- 表示其它任何类都无法访问。
# #6. 接口
接口是对行为的抽象,它是抽象方法的集合,利用接口可以达到 API 定义和实现分离的目的。
接口,不能实例化;不能包含任何非常量成员,任何 field 都是隐含着 public static final 的意义;同时,没有非静态方法实现,也就是说要么是抽象方法,要么是静态方法。
Java 标准类库中,定义了非常多的接口,比如 java.util.List 。
public interface Comparable<T> {
public int compareTo(T o);
}# #7. 抽象类
抽象类是不能实例化的类,用 abstract 关键字修饰 class ,其目的主要是代码重用。除了不能实例化,形式上和一般的 Java 类并没有太大区别,可以有一个或者多个抽象方法,也可以没有抽象方法。抽象类大多用于抽取相关 Java 类的共用方法实现或者是共同成员变量,然后通过继承的方式达到代码复用的目的。
Java 标准库中,比如 collection 框架,很多通用部分就被抽取成为抽象类,例如 java.util.AbstractList 。
- 抽象类不能被实例化 (初学者很容易犯的错),如果被实例化,就会报错,编译无法通过。只有抽象类的非抽象子类可以创建对象。
- 抽象类中不一定包含抽象方法,但是有抽象方法的类必定是抽象类。
- 抽象类中的抽象方法只是声明,不包含方法体,就是不给出方法的具体实现也就是方法的具体功能。
- 构造方法,类方法(用 static 修饰的方法)不能声明为抽象方法。
- 抽象类的子类必须给出抽象类中的抽象方法的具体实现,除非该子类也是抽象类。
# 深入理解 Java 方法
方法(有的人喜欢叫函数)是一段可重用的代码段。
📦 本文以及示例源码已归档在 javacore(opens new window)
# #1. 方法的使用
# #1.1. 方法定义
方法定义语法格式:
[修饰符] 返回值类型 方法名([参数类型 参数名]){
...
方法体
...
return 返回值;
}示例:
public static void main(String[] args) {
System.out.println("Hello World");
}方法包含一个方法头和一个方法体。下面是一个方法的所有部分:
- 修饰符 - 修饰符是可选的,它告诉编译器如何调用该方法。定义了该方法的访问类型。
- 返回值类型 - 返回值类型表示方法执行结束后,返回结果的数据类型。如果没有返回值,应设为 void。
- 方法名 - 是方法的实际名称。方法名和参数表共同构成方法签名。
- 参数类型 - 参数像是一个占位符。当方法被调用时,传递值给参数。参数列表是指方法的参数类型、顺序和参数的个数。参数是可选的,方法可以不包含任何参数。
- 方法体 - 方法体包含具体的语句,定义该方法的功能。
- return - 必须返回声明方法时返回值类型相同的数据类型。在 void 方法中,return 语句可有可无,如果要写 return,则只能是
return;这种形式。
# #1.2. 方法的调用
当程序调用一个方法时,程序的控制权交给了被调用的方法。当被调用方法的返回语句执行或者到达方法体闭括号时候交还控制权给程序。
Java 支持两种调用方法的方式,根据方法是否有返回值来选择。
- 有返回值方法 - 有返回值方法通常被用来给一个变量赋值或代入到运算表达式中进行计算。
int larger = max(30, 40);- 无返回值方法 - 无返回值方法只能是一条语句。
System.out.println("Hello World");# #递归调用
Java 支持方法的递归调用(即方法调用自身)。
🔔 注意:
- 递归方法必须有明确的结束条件。
- 尽量避免使用递归调用。因为递归调用如果处理不当,可能导致栈溢出。
斐波那契数列(一个典型的递归算法)示例:
public class RecursionMethodDemo {
public static int fib(int num) {
if (num == 1 || num == 2) {
return 1;
} else {
return fib(num - 2) + fib(num - 1);
}
}
public static void main(String[] args) {
for (int i = 1; i < 10; i++) {
System.out.print(fib(i) + "\t");
}
}
}# #2. 方法参数
在 C/C++ 等编程语言中,方法的参数传递一般有两种形式:
- 值传递 - 值传递的参数被称为形参。值传递时,传入的参数,在方法中的修改,不会在方法外部生效。
- 引用传递 - 引用传递的参数被称为实参。引用传递时,传入的参数,在方法中的修改,会在方法外部生效。
那么,Java 中是怎样的呢?
Java 中只有值传递。
示例一:
public class MethodParamDemo {
public static void method(int value) {
value = value + 1;
}
public static void main(String[] args) {
int num = 0;
method(num);
System.out.println("num = [" + num + "]");
method(num);
System.out.println("num = [" + num + "]");
}
}
// Output:
// num = [0]
// num = [0]示例二:
public class MethodParamDemo2 {
public static void method(StringBuilder sb) {
sb = new StringBuilder("B");
}
public static void main(String[] args) {
StringBuilder sb = new StringBuilder("A");
System.out.println("sb = [" + sb.toString() + "]");
method(sb);
System.out.println("sb = [" + sb.toString() + "]");
sb = new StringBuilder("C");
System.out.println("sb = [" + sb.toString() + "]");
}
}
// Output:
// sb = [A]
// sb = [A]
// sb = [C]说明:
以上两个示例,无论向方法中传入的是基础数据类型,还是引用类型,在方法中修改的值,在外部都未生效。
Java 对于基本数据类型,会直接拷贝值传递到方法中;对于引用数据类型,拷贝当前对象的引用地址,然后把该地址传递过去,所以也是值传递。
扩展阅读:
# #3. 方法修饰符
前面提到了,Java 方法的修饰符是可选的,它告诉编译器如何调用该方法。定义了该方法的访问类型。
Java 方法有好几个修饰符,让我们一一来认识一下:
# #3.1. 访问控制修饰符
访问权限控制的等级,从最大权限到最小权限依次为:
public > protected > 包访问权限(没有任何关键字)> privatepublic- 表示任何类都可以访问;包访问权限- 包访问权限,没有任何关键字。它表示当前包中的所有其他类都可以访问,但是其它包的类无法访问。protected- 表示子类可以访问,此外,同一个包内的其他类也可以访问,即使这些类不是子类。private- 表示其它任何类都无法访问。
# #3.2. static
被 static 修饰的方法被称为静态方法。
静态方法相比于普通的实例方法,主要有以下区别:
- 在外部调用静态方法时,可以使用
类名.方法名的方式,也可以使用对象名.方法名的方式。而实例方法只有后面这种方式。也就是说,调用静态方法可以无需创建对象。 - 静态方法在访问本类的成员时,只允许访问静态成员(即静态成员变量和静态方法),而不允许访问实例成员变量和实例方法;实例方法则无此限制。
静态方法常被用于各种工具类、工厂方法类。
# #3.3. final
被 final 修饰的方法不能被子类覆写(Override)。
final 方法示例:
public class FinalMethodDemo {
static class Father {
protected final void print() {
System.out.println("call Father print()");
};
}
static class Son extends Father {
@Override
protected void print() {
System.out.println("call print()");
}
}
public static void main(String[] args) {
Father demo = new Son();
demo.print();
}
}
// 编译时会报错说明:
上面示例中,父类 Father 中定义了一个
final方法print(),则其子类不能 Override 这个 final 方法,否则会编译报错。
# #3.4. default
JDK8 开始,支持在接口 Interface 中定义 default 方法。 default 方法只能出现在接口 Interface 中。
接口中被 default 修饰的方法被称为默认方法,实现此接口的类如果没 Override 此方法,则直接继承这个方法,不再强制必须实现此方法。
default 方法语法的出现,是为了既有的成千上万的 Java 类库的类增加新的功能, 且不必对这些类重新进行设计。 举例来说,JDK8 中 Collection 类中有一个非常方便的 stream() 方法,就是被修饰为 default ,Collection 的一大堆 List、Set 子类就直接继承了这个方法 I,不必再为每个子类都注意添加这个方法。
default 方法示例:
public class DefaultMethodDemo {
interface MyInterface {
default void print() {
System.out.println("Hello World");
}
}
static class MyClass implements MyInterface {}
public static void main(String[] args) {
MyInterface obj = new MyClass();
obj.print();
}
}
// Output:
// Hello World# #3.5. abstract
被 abstract 修饰的方法被称为抽象方法,方法不能有实体。抽象方法只能出现抽象类中。
抽象方法示例:
public class AbstractMethodDemo {
static abstract class AbstractClass {
abstract void print();
}
static class ConcreteClass extends AbstractClass {
@Override
void print() {
System.out.println("call print()");
}
}
public static void main(String[] args) {
AbstractClass demo = new ConcreteClass();
demo.print();
}
}
// Outpu:
// call print()# #3.6. synchronized
synchronized 用于并发编程。被 synchronized 修饰的方法在一个时刻,只允许一个线程执行。
在 Java 的同步容器(Vector、Stack、HashTable)中,你会见到大量的 synchronized 方法。不过,请记住:在 Java 并发编程中,synchronized 方法并不是一个好的选择,大多数情况下,我们会选择更加轻量级的锁 。
# #4. 特殊方法
Java 中,有一些较为特殊的方法,分别使用于特殊的场景。
# #4.1. main 方法
Java 中的 main 方法是一种特殊的静态方法,因为所有的 Java 程序都是由 public static void main(String[] args) 方法开始执行。
有很多新手虽然一直用 main 方法,却不知道 main 方法中的 args 有什么用。实际上,这是用来接收接收命令行输入参数的。
示例:
public class MainMethodDemo {
public static void main(String[] args) {
for (String arg : args) {
System.out.println("arg = [" + arg + "]");
}
}
}依次执行
javac MainMethodDemo.java
java MainMethodDemo A B C控制台会打印输出参数:
arg = [A]
arg = [B]
arg = [C]# #4.2. 构造方法
任何类都有构造方法,构造方法的作用就是在初始化类实例时,设置实例的状态。
每个类都有构造方法。如果没有显式地为类定义任何构造方法,Java 编译器将会为该类提供一个默认构造方法。
在创建一个对象的时候,至少要调用一个构造方法。构造方法的名称必须与类同名,一个类可以有多个构造方法。
public class ConstructorMethodDemo {
static class Person {
private String name;
public Person(String name) {
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
public static void main(String[] args) {
Person person = new Person("jack");
System.out.println("person name is " + person.getName());
}
}注意,构造方法除了使用 public,也可以使用 private 修饰,这种情况下,类无法调用此构造方法去实例化对象,这常常用于设计模式中的单例模式。
# #4.3. 变参方法
JDK5 开始,Java 支持传递同类型的可变参数给一个方法。在方法声明中,在指定参数类型后加一个省略号 ... 。一个方法中只能指定一个可变参数,它必须是方法的最后一个参数。任何普通的参数必须在它之前声明。
变参方法示例:
public class VarargsDemo {
public static void method(String... params) {
System.out.println("params.length = " + params.length);
for (String param : params) {
System.out.println("params = [" + param + "]");
}
}
public static void main(String[] args) {
method("red");
method("red", "yellow");
method("red", "yellow", "blue");
}
}
// Output:
// params.length = 1
// params = [red]
// params.length = 2
// params = [red]
// params = [yellow]
// params.length = 3
// params = [red]
// params = [yellow]
// params = [blue]# #4.4. finalize () 方法
finalize 在对象被垃圾收集器析构 (回收) 之前调用,用来清除回收对象。
finalize 是在 java.lang.Object 里定义的,也就是说每一个对象都有这么个方法。这个方法在 GC 启动,该对象被回收的时候被调用。
finalizer () 通常是不可预测的,也是很危险的,一般情况下是不必要的。使用终结方法会导致行为不稳定、降低性能,以及可移植性问题。
请记住:应该尽量避免使用 finalizer() 。千万不要把它当成是 C/C++ 中的析构函数来用。原因是:Finalizer 线程会和我们的主线程进行竞争,不过由于它的优先级较低,获取到的 CPU 时间较少,因此它永远也赶不上主线程的步伐。所以最后可能会发生 OutOfMemoryError 异常。
扩展阅读:
下面两篇文章比较详细的讲述了 finalizer () 可能会造成的问题及原因。
# #5. 覆写和重载
覆写(Override)是指子类定义了与父类中同名的方法,但是在方法覆写时必须考虑到访问权限,子类覆写的方法不能拥有比父类更加严格的访问权限。
子类要覆写的方法如果要访问父类的方法,可以使用 super 关键字。
覆写示例:
public class MethodOverrideDemo {
static class Animal {
public void move() {
System.out.println("会动");
}
}
static class Dog extends Animal {
@Override
public void move() {
super.move();
System.out.println("会跑");
}
}
public static void main(String[] args) {
Animal dog = new Dog();
dog.move();
}
}
// Output:
// 会动
// 会跑方法的重载(Overload)是指方法名称相同,但参数的类型或参数的个数不同。通过传递参数的个数及类型的不同可以完成不同功能的方法调用。
🔔 注意:
重载一定是方法的参数不完全相同。如果方法的参数完全相同,仅仅是返回值不同,Java 是无法编译通过的。
重载示例:
public class MethodOverloadDemo {
public static void add(int x, int y) {
System.out.println("x + y = " + (x + y));
}
public static void add(double x, double y) {
System.out.println("x + y = " + (x + y));
}
public static void main(String[] args) {
add(10, 20);
add(1.0, 2.0);
}
}
// Output:
// x + y = 30
// x + y = 3.0# #6. 小结
# 深入理解 Java 数组
📦 本文以及示例源码已归档在 javacore(opens new window)
# #1. 简介
# #1.1. 数组的特性
数组对于每一门编程语言来说都是重要的数据结构之一,当然不同语言对数组的实现及处理也不尽相同。几乎所有程序设计语言都支持数组。
数组代表一系列对象或者基本数据类型,所有相同的类型都封装到一起,采用一个统一的标识符名称。
数组的定义和使用需要通过方括号 [] 。
Java 中,数组是一种引用类型。
Java 中,数组是用来存储固定大小的同类型元素。
# #1.2. 数组和容器
Java 中,既然有了强大的容器,是不是就不需要数组了?
答案是不。
诚然,大多数情况下,应该选择容器存储数据。
但是,数组也不是毫无是处:
- Java 中,数组是一种效率最高的存储和随机访问对象引用序列的方式。数组的效率要高于容器(如
ArrayList)。 - 数组可以持有值类型,而容器则不能(这时,就必须用到包装类)。
# #1.3. Java 数组的本质是对象
Java 数组的本质是对象。它具有 Java 中其他对象的一些基本特点:封装了一些数据,可以访问属性,也可以调用方法。所以,数组是对象。
如果有两个类 A 和 B,如果 B 继承(extends)了 A,那么 A [] 类型的引用就可以指向 B [] 类型的对象。
扩展阅读:Java 中数组的特性 (opens new window)
如果想要论证 Java 数组本质是对象,不妨一读这篇文章。
# #1.4. Java 数组和内存
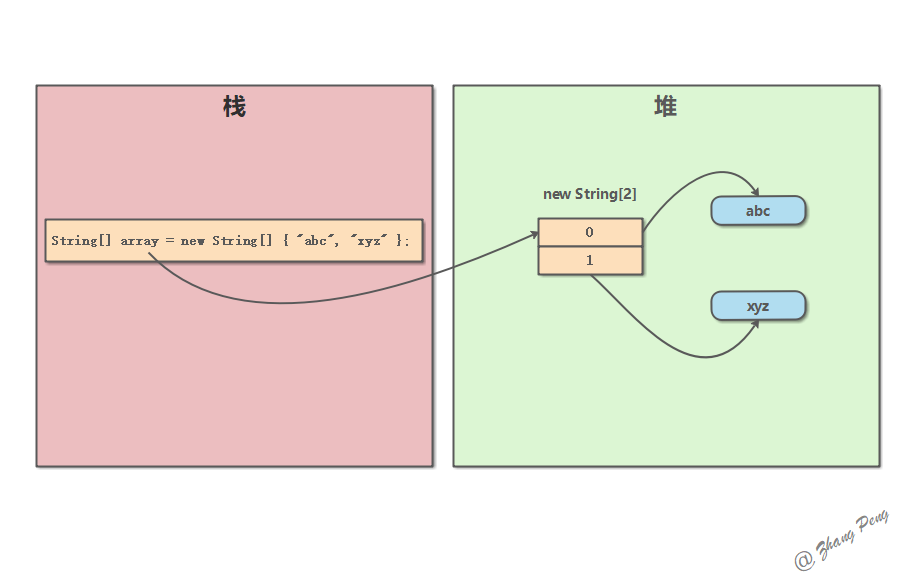
Java 数组在内存中的存储是这样的:
数组对象(这里可以看成一个指针)存储在栈中。
数组元素存储在堆中。
如下图所示:只有当 JVM 执行 new String[] 时,才会在堆中开辟相应的内存区域。数组对象 array 可以视为一个指针,指向这块内存的存储地址。
# #2. 声明数组
声明数组变量的语法如下:
int[] arr1; // 推荐风格
int arr2[]; // 效果相同# #3. 创建数组
Java 语言使用 new 操作符来创建数组。有两种创建数组方式:
- 指定数组维度
- 为数组开辟指定大小的数组维度。
- 如果数组元素是基础数据类型,会将每个元素设为默认值;如果是引用类型,元素值为
null。
- 不指定数组维度
- 用花括号中的实际元素初始化数组,数组大小与元素数相同。
示例 1:
public class ArrayDemo {
public static void main(String[] args) {
int[] array1 = new int[2]; // 指定数组维度
int[] array2 = new int[] { 1, 2 }; // 不指定数组维度
System.out.println("array1 size is " + array1.length);
for (int item : array1) {
System.out.println(item);
}
System.out.println("array2 size is " + array1.length);
for (int item : array2) {
System.out.println(item);
}
}
}
// Output:
// array1 size is 2
// 0
// 0
// array2 size is 2
// 1
// 2💡 说明 请注意数组 array1 中的元素虽然没有初始化,但是 length 和指定的数组维度是一样的。这表明指定数组维度后,无论后面是否初始化数组中的元素,数组都已经开辟了相应的内存。
数组 array1 中的元素都被设为默认值。
示例 2:
public class ArrayDemo2 {
static class User {}
public static void main(String[] args) {
User[] array1 = new User[2]; // 指定数组维度
User[] array2 = new User[] {new User(), new User()}; // 不指定数组维度
System.out.println("array1: ");
for (User item : array1) {
System.out.println(item);
}
System.out.println("array2: ");
for (User item : array2) {
System.out.println(item);
}
}
}
// Output:
// array1:
// null
// null
// array2:
// io.github.dunwu.javacore.array.ArrayDemo2$User@4141d797
// io.github.dunwu.javacore.array.ArrayDemo2$User@68f7aae2💡 说明
请将本例与示例 1 比较,可以发现:如果使用指定数组维度方式创建数组,且数组元素为引用类型,则数组中的元素元素值为
null。
# #3.1. 数组维度的形式
创建数组时,指定的数组维度可以有多种形式:
- 数组维度可以是整数、字符。
- 数组维度可以是整数型、字符型变量。
- 数组维度可以是计算结果为整数或字符的表达式。
示例:
public class ArrayDemo3 {
public static void main(String[] args) {
int length = 3;
// 放开被注掉的代码,编译器会报错
// int[] array = new int[4.0];
// int[] array2 = new int["test"];
int[] array3 = new int['a'];
int[] array4 = new int[length];
int[] array5 = new int[length + 2];
int[] array6 = new int['a' + 2];
// int[] array7 = new int[length + 2.1];
System.out.println("array3.length = [" + array3.length + "]");
System.out.println("array4.length = [" + array4.length + "]");
System.out.println("array5.length = [" + array5.length + "]");
System.out.println("array6.length = [" + array6.length + "]");
}
}
// Output:
// array3.length = [97]
// array4.length = [3]
// array5.length = [5]
// array6.length = [99]💡 说明
当指定的数组维度是字符时,Java 会将其转为整数。如字符
a的 ASCII 码是 97。综上,Java 数组的数组维度可以是常量、变量、表达式,只要转换为整数即可。
请留意,有些编程语言则不支持这点,如 C/C++ 语言,只允许数组维度是常量。
# #3.2. 数组维度的大小
数组维度并非没有上限的,如果数值过大,编译时会报错。
int[] array = new int[6553612431]; // 数组维度过大,编译报错此外,数组过大,可能会导致栈溢出。
# #4. 访问数组
Java 中,可以通过在 [] 中指定下标,访问数组元素,下标位置从 0 开始。
public class ArrayDemo4 {
public static void main(String[] args) {
int[] array = {1, 2, 3};
for (int i = 0; i < array.length; i++) {
array[i]++;
System.out.println(String.format("array[%d] = %d", i, array[i]));
}
}
}
// Output:
// array[0] = 2
// array[1] = 3
// array[2] = 4💡 说明
上面的示例中,从 0 开始,使用下标遍历数组 array 的所有元素,为每个元素值加 1 。
# #5. 数组的引用
Java 中,数组类型是一种引用类型。
因此,它可以作为引用,被 Java 函数作为函数入参或返回值。
数组作为函数入参的示例:
public class ArrayRefDemo {
private static void fun(int[] array) {
for (int i : array) {
System.out.print(i + "\t");
}
}
public static void main(String[] args) {
int[] array = new int[] {1, 3, 5};
fun(array);
}
}
// Output:
// 1 3 5数组作为函数返回值的示例:
public class ArrayRefDemo2 {
/**
* 返回一个数组
*/
private static int[] fun() {
return new int[] {1, 3, 5};
}
public static void main(String[] args) {
int[] array = fun();
System.out.println(Arrays.toString(array));
}
}
// Output:
// [1, 3, 5]# #6. 泛型和数组
通常,数组和泛型不能很好地结合。你不能实例化具有参数化类型的数组。
Peel<Banana>[] peels = new Pell<Banana>[10]; // 这行代码非法Java 中不允许直接创建泛型数组。但是,可以通过创建一个类型擦除的数组,然后转型的方式来创建泛型数组。
public class GenericArrayDemo<T> {
static class GenericArray<T> {
private T[] array;
public GenericArray(int num) {
array = (T[]) new Object[num];
}
public void put(int index, T item) {
array[index] = item;
}
public T get(int index) { return array[index]; }
public T[] array() { return array; }
}
public static void main(String[] args) {
GenericArray<Integer> genericArray = new GenericArray<Integer>(4);
genericArray.put(0, 0);
genericArray.put(1, 1);
Object[] array = genericArray.array();
System.out.println(Arrays.deepToString(array));
}
}
// Output:
// [0, 1, null, null]扩展阅读:https://www.cnblogs.com/jiangzhaowei/p/7399522.html
我认为,对于泛型数组的理解,点到为止即可。实际上,真的需要存储泛型,还是使用容器更合适。
# #7. 多维数组
多维数组可以看成是数组的数组,比如二维数组就是一个特殊的一维数组,其每一个元素都是一个一维数组。
Java 可以支持二维数组、三维数组、四维数组、五维数组。。。
但是,以正常人的理解能力,一般也就最多能理解三维数组。所以,请不要做反人类的事,去定义过多维度的数组。
多维数组使用示例:
public class MultiArrayDemo {
public static void main(String[] args) {
Integer[][] a1 = { // 自动装箱
{1, 2, 3,},
{4, 5, 6,},
};
Double[][][] a2 = { // 自动装箱
{ {1.1, 2.2}, {3.3, 4.4} },
{ {5.5, 6.6}, {7.7, 8.8} },
{ {9.9, 1.2}, {2.3, 3.4} },
};
String[][] a3 = {
{"The", "Quick", "Sly", "Fox"},
{"Jumped", "Over"},
{"The", "Lazy", "Brown", "Dog", "and", "friend"},
};
System.out.println("a1: " + Arrays.deepToString(a1));
System.out.println("a2: " + Arrays.deepToString(a2));
System.out.println("a3: " + Arrays.deepToString(a3));
}
}
// Output:
// a1: [[1, 2, 3], [4, 5, 6]]
// a2: [[[1.1, 2.2], [3.3, 4.4]], [[5.5, 6.6], [7.7, 8.8]], [[9.9, 1.2], [2.3, 3.4]]]
// a3: [[The, Quick, Sly, Fox], [Jumped, Over], [The, Lazy, Brown, Dog, and, friend]]# #8. Arrays 类
Java 中,提供了一个很有用的数组工具类:Arrays。
它提供的主要操作有:
sort- 排序binarySearch- 查找equals- 比较fill- 填充asList- 转列表hash- 哈希toString- 转字符串
# #9. 小结
# 深入理解 Java 枚举
📦 本文以及示例源码已归档在 javacore(opens new window)
# #1. 简介
enum 的全称为 enumeration, 是 JDK5 中引入的特性。
在 Java 中,被 enum 关键字修饰的类型就是枚举类型。形式如下:
enum ColorEn { RED, GREEN, BLUE }枚举的好处:可以将常量组织起来,统一进行管理。
枚举的典型应用场景:错误码、状态机等。
# #2. 枚举的本质
java.lang.Enum 类声明
public abstract class Enum<E extends Enum<E>>
implements Comparable<E>, Serializable { ... }新建一个 ColorEn.java 文件,内容如下:
package io.github.dunwu.javacore.enumeration;
public enum ColorEn {
RED,YELLOW,BLUE
}执行 javac ColorEn.java 命令,生成 ColorEn.class 文件。
然后执行 javap ColorEn.class 命令,输出如下内容:
Compiled from "ColorEn.java"
public final class io.github.dunwu.javacore.enumeration.ColorEn extends java.lang.Enum<io.github.dunwu.javacore.enumeration.ColorEn> {
public static final io.github.dunwu.javacore.enumeration.ColorEn RED;
public static final io.github.dunwu.javacore.enumeration.ColorEn YELLOW;
public static final io.github.dunwu.javacore.enumeration.ColorEn BLUE;
public static io.github.dunwu.javacore.enumeration.ColorEn[] values();
public static io.github.dunwu.javacore.enumeration.ColorEn valueOf(java.lang.String);
static {};
}💡 说明:
从上面的例子可以看出:
枚举的本质是
java.lang.Enum的子类。尽管
enum看起来像是一种新的数据类型,事实上,enum 是一种受限制的类,并且具有自己的方法。枚举这种特殊的类因为被修饰为final,所以不能继承其他类。定义的枚举值,会被默认修饰为
public static final,从修饰关键字,即可看出枚举值本质上是静态常量。
# #3. 枚举的方法
在 enum 中,提供了一些基本方法:
values():返回 enum 实例的数组,而且该数组中的元素严格保持在 enum 中声明时的顺序。name():返回实例名。ordinal():返回实例声明时的次序,从 0 开始。getDeclaringClass():返回实例所属的 enum 类型。equals():判断是否为同一个对象。
可以使用 == 来比较 enum 实例。
此外, java.lang.Enum 实现了 Comparable 和 Serializable 接口,所以也提供 compareTo() 方法。
例:展示 enum 的基本方法
public class EnumMethodDemo {
enum Color {RED, GREEN, BLUE;}
enum Size {BIG, MIDDLE, SMALL;}
public static void main(String args[]) {
System.out.println("=========== Print all Color ===========");
for (Color c : Color.values()) {
System.out.println(c + " ordinal: " + c.ordinal());
}
System.out.println("=========== Print all Size ===========");
for (Size s : Size.values()) {
System.out.println(s + " ordinal: " + s.ordinal());
}
Color green = Color.GREEN;
System.out.println("green name(): " + green.name());
System.out.println("green getDeclaringClass(): " + green.getDeclaringClass());
System.out.println("green hashCode(): " + green.hashCode());
System.out.println("green compareTo Color.GREEN: " + green.compareTo(Color.GREEN));
System.out.println("green equals Color.GREEN: " + green.equals(Color.GREEN));
System.out.println("green equals Size.MIDDLE: " + green.equals(Size.MIDDLE));
System.out.println("green equals 1: " + green.equals(1));
System.out.format("green == Color.BLUE: %b\n", green == Color.BLUE);
}
}输出
=========== Print all Color ===========
RED ordinal: 0
GREEN ordinal: 1
BLUE ordinal: 2
=========== Print all Size ===========
BIG ordinal: 0
MIDDLE ordinal: 1
SMALL ordinal: 2
green name(): GREEN
green getDeclaringClass(): class org.zp.javase.enumeration.EnumDemo$Color
green hashCode(): 460141958
green compareTo Color.GREEN: 0
green equals Color.GREEN: true
green equals Size.MIDDLE: false
green equals 1: false
green == Color.BLUE: false# #4. 枚举的特性
枚举的特性,归结起来就是一句话:
除了不能继承,基本上可以将
enum看做一个常规的类。
但是这句话需要拆分去理解,让我们细细道来。
# #4.1. 基本特性
如果枚举中没有定义方法,也可以在最后一个实例后面加逗号、分号或什么都不加。
如果枚举中没有定义方法,枚举值默认为从 0 开始的有序数值。以 Color 枚举类型举例,它的枚举常量依次为 RED:0,GREEN:1,BLUE:2 。
# #4.2. 枚举可以添加方法
在概念章节提到了,枚举值默认为从 0 开始的有序数值 。那么问题来了:如何为枚举显式的赋值。
(1)Java 不允许使用 = 为枚举常量赋值
如果你接触过 C/C++,你肯定会很自然的想到赋值符号 = 。在 C/C++ 语言中的 enum,可以用赋值符号 = 显式的为枚举常量赋值;但是 ,很遗憾,Java 语法中却不允许使用赋值符号 = 为枚举常量赋值。
例:C/C++ 语言中的枚举声明
typedef enum {
ONE = 1,
TWO,
THREE = 3,
TEN = 10
} Number;(2)枚举可以添加普通方法、静态方法、抽象方法、构造方法
Java 虽然不能直接为实例赋值,但是它有更优秀的解决方案:为 enum 添加方法来间接实现显式赋值。
创建 enum 时,可以为其添加多种方法,甚至可以为其添加构造方法。
注意一个细节:如果要为 enum 定义方法,那么必须在 enum 的最后一个实例尾部添加一个分号。此外,在 enum 中,必须先定义实例,不能将字段或方法定义在实例前面。否则,编译器会报错。
例:全面展示如何在枚举中定义普通方法、静态方法、抽象方法、构造方法
public enum ErrorCodeEn {
OK(0) {
@Override
public String getDescription() {
return "成功";
}
},
ERROR_A(100) {
@Override
public String getDescription() {
return "错误A";
}
},
ERROR_B(200) {
@Override
public String getDescription() {
return "错误B";
}
};
private int code;
// 构造方法:enum的构造方法只能被声明为private权限或不声明权限
private ErrorCodeEn(int number) { // 构造方法
this.code = number;
}
public int getCode() { // 普通方法
return code;
} // 普通方法
public abstract String getDescription(); // 抽象方法
public static void main(String args[]) { // 静态方法
for (ErrorCodeEn s : ErrorCodeEn.values()) {
System.out.println("code: " + s.getCode() + ", description: " + s.getDescription());
}
}
}
// Output:
// code: 0, description: 成功
// code: 100, description: 错误A
// code: 200, description: 错误B注:上面的例子并不可取,仅仅是为了展示枚举支持定义各种方法。正确的例子情况错误码示例
# #4.3. 枚举可以实现接口
enum 可以像一般类一样实现接口。
同样是实现上一节中的错误码枚举类,通过实现接口,可以约束它的方法。
public interface INumberEnum {
int getCode();
String getDescription();
}
public enum ErrorCodeEn2 implements INumberEnum {
OK(0, "成功"),
ERROR_A(100, "错误A"),
ERROR_B(200, "错误B");
ErrorCodeEn2(int number, String description) {
this.code = number;
this.description = description;
}
private int code;
private String description;
@Override
public int getCode() {
return code;
}
@Override
public String getDescription() {
return description;
}
}# #4.4. 枚举不可以继承
enum 不可以继承另外一个类,当然,也不能继承另一个 enum 。
因为 enum 实际上都继承自 java.lang.Enum 类,而 Java 不支持多重继承,所以 enum 不能再继承其他类,当然也不能继承另一个 enum 。
# #5. 枚举的应用
# #5.1. 组织常量
在 JDK5 之前,在 Java 中定义常量都是 public static final TYPE a; 这样的形式。有了枚举,你可以将有关联关系的常量组织起来,使代码更加易读、安全,并且还可以使用枚举提供的方法。
下面三种声明方式是等价的:
enum Color { RED, GREEN, BLUE }
enum Color { RED, GREEN, BLUE, }
enum Color { RED, GREEN, BLUE; }# #5.2. switch 状态机
我们经常使用 switch 语句来写状态机。JDK7 以后,switch 已经支持 int 、 char 、 String 、 enum 类型的参数。这几种类型的参数比较起来,使用枚举的 switch 代码更具有可读性。
public class StateMachineDemo {
public enum Signal {
GREEN, YELLOW, RED
}
public static String getTrafficInstruct(Signal signal) {
String instruct = "信号灯故障";
switch (signal) {
case RED:
instruct = "红灯停";
break;
case YELLOW:
instruct = "黄灯请注意";
break;
case GREEN:
instruct = "绿灯行";
break;
default:
break;
}
return instruct;
}
public static void main(String[] args) {
System.out.println(getTrafficInstruct(Signal.RED));
}
}
// Output:
// 红灯停# #5.3. 错误码
枚举常被用于定义程序错误码。下面是一个简单示例:
public class ErrorCodeEnumDemo {
enum ErrorCodeEn {
OK(0, "成功"),
ERROR_A(100, "错误A"),
ERROR_B(200, "错误B");
ErrorCodeEn(int number, String msg) {
this.code = number;
this.msg = msg;
}
private int code;
private String msg;
public int getCode() {
return code;
}
public String getMsg() {
return msg;
}
@Override
public String toString() {
return "ErrorCodeEn{" + "code=" + code + ", msg='" + msg + '\'' + '}';
}
public static String toStringAll() {
StringBuilder sb = new StringBuilder();
sb.append("ErrorCodeEn All Elements: [");
for (ErrorCodeEn code : ErrorCodeEn.values()) {
sb.append(code.getCode()).append(", ");
}
sb.append("]");
return sb.toString();
}
}
public static void main(String[] args) {
System.out.println(ErrorCodeEn.toStringAll());
for (ErrorCodeEn s : ErrorCodeEn.values()) {
System.out.println(s);
}
}
}
// Output:
// ErrorCodeEn All Elements: [0, 100, 200, ]
// ErrorCodeEn{code=0, msg='成功'}
// ErrorCodeEn{code=100, msg='错误A'}
// ErrorCodeEn{code=200, msg='错误B'}# #5.4. 组织枚举
可以将类型相近的枚举通过接口或类组织起来,但是一般用接口方式进行组织。
原因是:Java 接口在编译时会自动为 enum 类型加上 public static 修饰符;Java 类在编译时会自动为 enum 类型加上 static 修饰符。看出差异了吗?没错,就是说,在类中组织 enum ,如果你不给它修饰为 public ,那么只能在本包中进行访问。
例:在接口中组织 enum
public class EnumInInterfaceDemo {
public interface INumberEnum {
int getCode();
String getDescription();
}
public interface Plant {
enum Vegetable implements INumberEnum {
POTATO(0, "土豆"),
TOMATO(0, "西红柿");
Vegetable(int number, String description) {
this.code = number;
this.description = description;
}
private int code;
private String description;
@Override
public int getCode() {
return this.code;
}
@Override
public String getDescription() {
return this.description;
}
}
enum Fruit implements INumberEnum {
APPLE(0, "苹果"),
ORANGE(0, "桔子"),
BANANA(0, "香蕉");
Fruit(int number, String description) {
this.code = number;
this.description = description;
}
private int code;
private String description;
@Override
public int getCode() {
return this.code;
}
@Override
public String getDescription() {
return this.description;
}
}
}
public static void main(String[] args) {
for (Plant.Fruit f : Plant.Fruit.values()) {
System.out.println(f.getDescription());
}
}
}
// Output:
// 苹果
// 桔子
// 香蕉例:在类中组织 enum
本例和上例效果相同。
public class EnumInClassDemo {
public interface INumberEnum {
int getCode();
String getDescription();
}
public static class Plant2 {
enum Vegetable implements INumberEnum {
// 略,与上面完全相同
}
enum Fruit implements INumberEnum {
// 略,与上面完全相同
}
}
// 略
}
// Output:
// 土豆
// 西红柿# #5.5. 策略枚举
Effective Java 中展示了一种策略枚举。这种枚举通过枚举嵌套枚举的方式,将枚举常量分类处理。
这种做法虽然没有 switch 语句简洁,但是更加安全、灵活。
例:EffectvieJava 中的策略枚举范例
enum PayrollDay {
MONDAY(PayType.WEEKDAY), TUESDAY(PayType.WEEKDAY), WEDNESDAY(
PayType.WEEKDAY), THURSDAY(PayType.WEEKDAY), FRIDAY(PayType.WEEKDAY), SATURDAY(
PayType.WEEKEND), SUNDAY(PayType.WEEKEND);
private final PayType payType;
PayrollDay(PayType payType) {
this.payType = payType;
}
double pay(double hoursWorked, double payRate) {
return payType.pay(hoursWorked, payRate);
}
// 策略枚举
private enum PayType {
WEEKDAY {
double overtimePay(double hours, double payRate) {
return hours <= HOURS_PER_SHIFT ? 0 : (hours - HOURS_PER_SHIFT)
* payRate / 2;
}
},
WEEKEND {
double overtimePay(double hours, double payRate) {
return hours * payRate / 2;
}
};
private static final int HOURS_PER_SHIFT = 8;
abstract double overtimePay(double hrs, double payRate);
double pay(double hoursWorked, double payRate) {
double basePay = hoursWorked * payRate;
return basePay + overtimePay(hoursWorked, payRate);
}
}
}测试
System.out.println("时薪100的人在周五工作8小时的收入:" + PayrollDay.FRIDAY.pay(8.0, 100));
System.out.println("时薪100的人在周六工作8小时的收入:" + PayrollDay.SATURDAY.pay(8.0, 100));# #5.6. 枚举实现单例模式
单例模式是最常用的设计模式。
单例模式在并发环境下存在线程安全问题。
为了线程安全问题,传统做法有以下几种:
- 饿汉式加载
- 懒汉式 synchronize 和双重检查
- 利用 java 的静态加载机制
相比上述的方法,使用枚举也可以实现单例,而且还更加简单:
public class SingleEnumDemo {
public enum SingleEn {
INSTANCE;
private String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
public static void main(String[] args) {
SingleEn.INSTANCE.setName("zp");
System.out.println(SingleEn.INSTANCE.getName());
}
}扩展阅读:深入理解 Java 枚举类型 (enum)(opens new window)
这篇文章对于 Java 枚举的特性讲解很仔细,其中对于枚举实现单例和传统单例实现方式说的尤为细致。
# #6. 枚举工具类
Java 中提供了两个方便操作 enum 的工具类 —— EnumSet 和 EnumMap 。
# #6.1. EnumSet
EnumSet 是枚举类型的高性能 Set 实现。它要求放入它的枚举常量必须属于同一枚举类型。
主要接口:
noneOf- 创建一个具有指定元素类型的空 EnumSetallOf- 创建一个指定元素类型并包含所有枚举值的 EnumSetrange- 创建一个包括枚举值中指定范围元素的 EnumSetcomplementOf- 初始集合包括指定集合的补集of- 创建一个包括参数中所有元素的 EnumSetcopyOf- 创建一个包含参数容器中的所有元素的 EnumSet
示例:
public class EnumSetDemo {
public static void main(String[] args) {
System.out.println("EnumSet展示");
EnumSet<ErrorCodeEn> errSet = EnumSet.allOf(ErrorCodeEn.class);
for (ErrorCodeEn e : errSet) {
System.out.println(e.name() + " : " + e.ordinal());
}
}
}# #6.2. EnumMap
EnumMap 是专门为枚举类型量身定做的 Map 实现。虽然使用其它的 Map 实现(如 HashMap)也能完成枚举类型实例到值得映射,但是使用 EnumMap 会更加高效:它只能接收同一枚举类型的实例作为键值,并且由于枚举类型实例的数量相对固定并且有限,所以 EnumMap 使用数组来存放与枚举类型对应的值。这使得 EnumMap 的效率非常高。
主要接口:
size- 返回键值对数containsValue- 是否存在指定的 valuecontainsKey- 是否存在指定的 keyget- 根据指定 key 获取 valueput- 取出指定的键值对remove- 删除指定 keyputAll- 批量取出键值对clear- 清除数据keySet- 获取 key 集合values- 返回所有
示例:
public class EnumMapDemo {
public enum Signal {
GREEN, YELLOW, RED
}
public static void main(String[] args) {
System.out.println("EnumMap展示");
EnumMap<Signal, String> errMap = new EnumMap(Signal.class);
errMap.put(Signal.RED, "红灯");
errMap.put(Signal.YELLOW, "黄灯");
errMap.put(Signal.GREEN, "绿灯");
for (Iterator<Map.Entry<Signal, String>> iter = errMap.entrySet().iterator(); iter.hasNext();) {
Map.Entry<Signal, String> entry = iter.next();
System.out.println(entry.getKey().name() + " : " + entry.getValue());
}
}
}扩展阅读:深入理解 Java 枚举类型 (enum)(opens new window)
这篇文章中对 EnumSet 和 EnumMap 原理做了较为详细的介绍。
# #7. 小结

# Java 控制语句
📦 本文以及示例源码已归档在 javacore(opens new window)
Java 控制语句大致可分为三大类:
- 选择语句
- if, else-if, else
- switch
- 循环语句
- while
- do…while
- for
- foreach
- 终端语句
- break
- continue
- return
# #1. 选择语句
# #1.1. if 语句
if 语句会判断括号中的条件是否成立,如果成立则执行 if 语句中的代码块,否则跳过代码块继续执行。
语法
if(布尔表达式) {
//如果布尔表达式为true将执行的语句
}示例
public class IfDemo {
public static void main(String args[]) {
int x = 10;
if (x < 20) {
System.out.print("这是 if 语句");
}
}
}
// output:
// 这是 if 语句# #1.2. if…else 语句
if 语句后面可以跟 else 语句,当 if 语句的布尔表达式值为 false 时, else 语句块会被执行。
语法
if(布尔表达式) {
//如果布尔表达式的值为true
} else {
//如果布尔表达式的值为false
}示例
public class IfElseDemo {
public static void main(String args[]) {
int x = 30;
if (x < 20) {
System.out.print("这是 if 语句");
} else {
System.out.print("这是 else 语句");
}
}
}
// output:
// 这是 else 语句# #1.3. if…else if…else 语句
if语句至多有 1 个else语句,else语句在所有的else if语句之后。If语句可以有若干个else if语句,它们必须在else语句之前。- 一旦其中一个
else if语句检测为true,其他的else if以及else语句都将跳过执行。
语法
if (布尔表达式 1) {
//如果布尔表达式 1的值为true执行代码
} else if (布尔表达式 2) {
//如果布尔表达式 2的值为true执行代码
} else if (布尔表达式 3) {
//如果布尔表达式 3的值为true执行代码
} else {
//如果以上布尔表达式都不为true执行代码
}示例
public class IfElseifElseDemo {
public static void main(String args[]) {
int x = 3;
if (x == 1) {
System.out.print("Value of X is 1");
} else if (x == 2) {
System.out.print("Value of X is 2");
} else if (x == 3) {
System.out.print("Value of X is 3");
} else {
System.out.print("This is else statement");
}
}
}
// output:
// Value of X is 3# #1.4. 嵌套的 if…else 语句
使用嵌套的 if else 语句是合法的。也就是说你可以在另一个 if 或者 else if 语句中使用 if 或者 else if 语句。
语法
if (布尔表达式 1) {
////如果布尔表达式 1的值为true执行代码
if (布尔表达式 2) {
////如果布尔表达式 2的值为true执行代码
}
}示例
public class IfNestDemo {
public static void main(String args[]) {
int x = 30;
int y = 10;
if (x == 30) {
if (y == 10) {
System.out.print("X = 30 and Y = 10");
}
}
}
}
// output:
// X = 30 and Y = 10# #1.5. switch 语句
switch 语句判断一个变量与一系列值中某个值是否相等,每个值称为一个分支。
switch 语句有如下规则:
switch语句中的变量类型只能为byte、short、int、char或者String。switch语句可以拥有多个case语句。每个case后面跟一个要比较的值和冒号。case语句中的值的数据类型必须与变量的数据类型相同,而且只能是常量或者字面常量。- 当变量的值与
case语句的值相等时,那么case语句之后的语句开始执行,直到break语句出现才会跳出switch语句。 - 当遇到
break语句时,switch语句终止。程序跳转到switch语句后面的语句执行。case语句不必须要包含break语句。如果没有break语句出现,程序会继续执行下一条case语句,直到出现break语句。 switch语句可以包含一个default分支,该分支必须是switch语句的最后一个分支。default在没有case语句的值和变量值相等的时候执行。default分支不需要break语句。
语法
switch(expression){
case value :
//语句
break; //可选
case value :
//语句
break; //可选
//你可以有任意数量的case语句
default : //可选
//语句
break; //可选,但一般建议加上
}示例
public class SwitchDemo {
public static void main(String args[]) {
char grade = 'C';
switch (grade) {
case 'A':
System.out.println("Excellent!");
break;
case 'B':
case 'C':
System.out.println("Well done");
break;
case 'D':
System.out.println("You passed");
case 'F':
System.out.println("Better try again");
break;
default:
System.out.println("Invalid grade");
break;
}
System.out.println("Your grade is " + grade);
}
}
// output:
// Well done
// Your grade is C# #2. 循环语句
# #2.1. while 循环
只要布尔表达式为 true , while 循环体会一直执行下去。
语法
while( 布尔表达式 ) {
//循环内容
}示例
public class WhileDemo {
public static void main(String args[]) {
int x = 10;
while (x < 20) {
System.out.print("value of x : " + x);
x++;
System.out.print("\n");
}
}
}
// output:
// value of x : 10
// value of x : 11
// value of x : 12
// value of x : 13
// value of x : 14
// value of x : 15
// value of x : 16
// value of x : 17
// value of x : 18
// value of x : 19# #2.2. do while 循环
对于 while 语句而言,如果不满足条件,则不能进入循环。但有时候我们需要即使不满足条件,也至少执行一次。
do while 循环和 while 循环相似,不同的是, do while 循环至少会执行一次。
语法
do {
//代码语句
} while (布尔表达式);布尔表达式在循环体的后面,所以语句块在检测布尔表达式之前已经执行了。 如果布尔表达式的值为 true,则语句块一直执行,直到布尔表达式的值为 false。
示例
public class DoWhileDemo {
public static void main(String args[]) {
int x = 10;
do {
System.out.print("value of x : " + x);
x++;
System.out.print("\n");
} while (x < 20);
}
}
// output:
// value of x:10
// value of x:11
// value of x:12
// value of x:13
// value of x:14
// value of x:15
// value of x:16
// value of x:17
// value of x:18
// value of x:19# #2.3. for 循环
虽然所有循环结构都可以用 while 或者 do while 表示,但 Java 提供了另一种语句 —— for 循环,使一些循环结构变得更加简单。 for 循环执行的次数是在执行前就确定的。
语法
for (初始化; 布尔表达式; 更新) {
//代码语句
}- 最先执行初始化步骤。可以声明一种类型,但可初始化一个或多个循环控制变量,也可以是空语句。
- 然后,检测布尔表达式的值。如果为 true,循环体被执行。如果为 false,循环终止,开始执行循环体后面的语句。
- 执行一次循环后,更新循环控制变量。
- 再次检测布尔表达式。循环执行上面的过程。
示例
public class ForDemo {
public static void main(String args[]) {
for (int x = 10; x < 20; x = x + 1) {
System.out.print("value of x : " + x);
System.out.print("\n");
}
}
}
// output:
// value of x : 10
// value of x : 11
// value of x : 12
// value of x : 13
// value of x : 14
// value of x : 15
// value of x : 16
// value of x : 17
// value of x : 18
// value of x : 19# #2.4. foreach 循环
Java5 引入了一种主要用于数组的增强型 for 循环。
语法
for (声明语句 : 表达式) {
//代码句子
}声明语句:声明新的局部变量,该变量的类型必须和数组元素的类型匹配。其作用域限定在循环语句块,其值与此时数组元素的值相等。
表达式:表达式是要访问的数组名,或者是返回值为数组的方法。
示例
public class ForeachDemo {
public static void main(String args[]) {
int[] numbers = { 10, 20, 30, 40, 50 };
for (int x : numbers) {
System.out.print(x);
System.out.print(",");
}
System.out.print("\n");
String[] names = { "James", "Larry", "Tom", "Lacy" };
for (String name : names) {
System.out.print(name);
System.out.print(",");
}
}
}
// output:
// 10,20,30,40,50,
// James,Larry,Tom,Lacy,# #3. 中断语句
# #3.1. break 关键字
break 主要用在循环语句或者 switch 语句中,用来跳出整个语句块。
break 跳出最里层的循环,并且继续执行该循环下面的语句。
示例
public class BreakDemo {
public static void main(String args[]) {
int[] numbers = { 10, 20, 30, 40, 50 };
for (int x : numbers) {
if (x == 30) {
break;
}
System.out.print(x);
System.out.print("\n");
}
System.out.println("break 示例结束");
}
}
// output:
// 10
// 20
// break 示例结束# #3.2. continue 关键字
continue 适用于任何循环控制结构中。作用是让程序立刻跳转到下一次循环的迭代。在 for 循环中, continue 语句使程序立即跳转到更新语句。在 while 或者 do while 循环中,程序立即跳转到布尔表达式的判断语句。
示例
public class ContinueDemo {
public static void main(String args[]) {
int[] numbers = { 10, 20, 30, 40, 50 };
for (int x : numbers) {
if (x == 30) {
continue;
}
System.out.print(x);
System.out.print("\n");
}
}
}
// output:
// 10
// 20
// 40
// 50# #3.3. return 关键字
跳出整个函数体,函数体后面的部分不再执行。
示例
public class ReturnDemo {
public static void main(String args[]) {
int[] numbers = { 10, 20, 30, 40, 50 };
for (int x : numbers) {
if (x == 30) {
return;
}
System.out.print(x);
System.out.print("\n");
}
System.out.println("return 示例结束");
}
}
// output:
// 10
// 20🔔 注意:请仔细体会一下
return和break的区别。
# #4. 最佳实践
- 选择分支特别多的情况下,
switch语句优于if...else if...else语句。 switch语句不要吝啬使用default。switch语句中的default要放在最后。foreach循环优先于传统的for循环- 不要循环遍历容器元素,然后删除特定元素。正确姿势应该是遍历容器的迭代器(
Iterator),删除元素。
# 深入理解 Java 异常
📦 本文以及示例源码已归档在 javacore(opens new window)
# #1. 异常框架
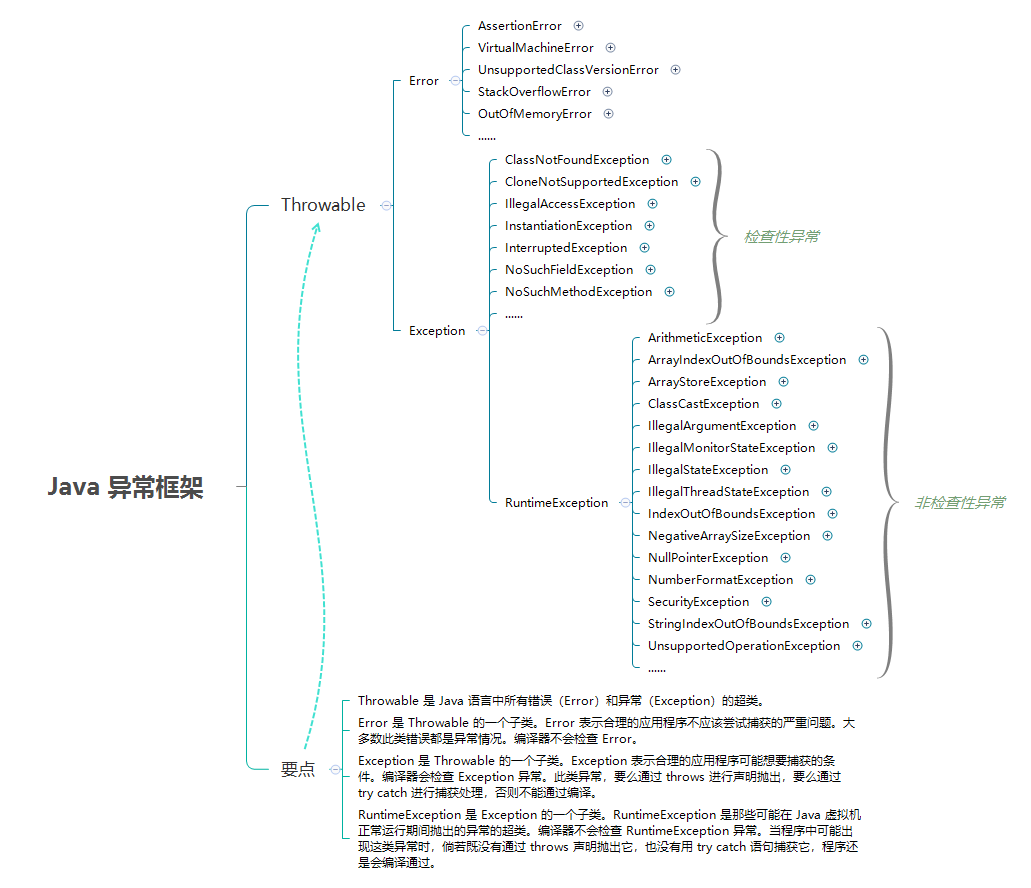
# #1.1. Throwable
** Throwable 是 Java 语言中所有错误( Error )和异常( Exception )的超类。** 在 Java 中只有 Throwable 类型的实例才可以被抛出( throw )或者捕获( catch ),它是异常处理机制的基本组成类型。
Throwable 包含了其线程创建时线程执行堆栈的快照,它提供了 printStackTrace() 等接口用于获取堆栈跟踪数据等信息。
主要方法:
fillInStackTrace- 用当前的调用栈层次填充Throwable对象栈层次,添加到栈层次任何先前信息中。getMessage- 返回关于发生的异常的详细信息。这个消息在Throwable类的构造函数中初始化了。getCause- 返回一个Throwable对象代表异常原因。getStackTrace- 返回一个包含堆栈层次的数组。下标为 0 的元素代表栈顶,最后一个元素代表方法调用堆栈的栈底。printStackTrace- 打印toString()结果和栈层次到System.err,即错误输出流。toString- 使用getMessage的结果返回代表Throwable对象的字符串。
# #1.2. Error
Error 是 Throwable 的一个子类。 Error 表示正常情况下,不大可能出现的严重问题。编译器不会检查 Error 。绝大部分的 Error 都会导致程序(比如 JVM 自身)处于非正常的、不可恢复状态。既然是非正常情况,所以不便于也不需要捕获,常见的比如 OutOfMemoryError 之类,都是 Error 的子类。
常见 Error :
AssertionError- 断言错误。VirtualMachineError- 虚拟机错误。UnsupportedClassVersionError- Java 类版本错误。StackOverflowError- 栈溢出错误。OutOfMemoryError- 内存溢出错误。
# #1.3. Exception
Exception 是 Throwable 的一个子类。** Exception 表示合理的应用程序可能想要捕获的条件。**Exception 是程序正常运行中,可以预料的意外情况,可能并且应该被捕获,进行相应处理。
Exception 又分为可检查(checked)异常和不检查(unchecked)异常,可检查异常在源代码里必须显式地进行捕获处理,这是编译期检查的一部分。
** 编译器会检查 Exception 异常。** 此类异常,要么通过 throws 进行声明抛出,要么通过 try catch 进行捕获处理,否则不能通过编译。
常见 Exception :
ClassNotFoundException- 应用程序试图加载类时,找不到相应的类,抛出该异常。CloneNotSupportedException- 当调用 Object 类中的 clone 方法克隆对象,但该对象的类无法实现 Cloneable 接口时,抛出该异常。IllegalAccessException- 拒绝访问一个类的时候,抛出该异常。InstantiationException- 当试图使用 Class 类中的 newInstance 方法创建一个类的实例,而指定的类对象因为是一个接口或是一个抽象类而无法实例化时,抛出该异常。InterruptedException- 一个线程被另一个线程中断,抛出该异常。NoSuchFieldException- 请求的变量不存在。NoSuchMethodException- 请求的方法不存在。
示例:
public class ExceptionDemo {
public static void main(String[] args) {
Method method = String.class.getMethod("toString", int.class);
}
};试图编译运行时会报错:
Error:(7, 47) java: 未报告的异常错误java.lang.NoSuchMethodException; 必须对其进行捕获或声明以便抛出# #1.4. RuntimeException
RuntimeException 是 Exception 的一个子类。 RuntimeException 是那些可能在 Java 虚拟机正常运行期间抛出的异常的超类。
** 编译器不会检查 RuntimeException 异常。** 当程序中可能出现这类异常时,倘若既没有通过 throws 声明抛出它,也没有用 try catch 语句捕获它,程序还是会编译通过。
示例:
public class RuntimeExceptionDemo {
public static void main(String[] args) {
// 此处产生了异常
int result = 10 / 0;
System.out.println("两个数字相除的结果:" + result);
System.out.println("----------------------------");
}
};运行时输出:
Exception in thread "main" java.lang.ArithmeticException: / by zero
at io.github.dunwu.javacore.exception.RumtimeExceptionDemo01.main(RumtimeExceptionDemo01.java:6)常见 RuntimeException :
ArrayIndexOutOfBoundsException- 用非法索引访问数组时抛出的异常。如果索引为负或大于等于数组大小,则该索引为非法索引。ArrayStoreException- 试图将错误类型的对象存储到一个对象数组时抛出的异常。ClassCastException- 当试图将对象强制转换为不是实例的子类时,抛出该异常。IllegalArgumentException- 抛出的异常表明向方法传递了一个不合法或不正确的参数。IllegalMonitorStateException- 抛出的异常表明某一线程已经试图等待对象的监视器,或者试图通知其他正在等待对象的监视器而本身没有指定监视器的线程。IllegalStateException- 在非法或不适当的时间调用方法时产生的信号。换句话说,即 Java 环境或 Java 应用程序没有处于请求操作所要求的适当状态下。IllegalThreadStateException- 线程没有处于请求操作所要求的适当状态时抛出的异常。IndexOutOfBoundsException- 指示某排序索引(例如对数组、字符串或向量的排序)超出范围时抛出。NegativeArraySizeException- 如果应用程序试图创建大小为负的数组,则抛出该异常。NullPointerException- 当应用程序试图在需要对象的地方使用 null 时,抛出该异常NumberFormatException- 当应用程序试图将字符串转换成一种数值类型,但该字符串不能转换为适当格式时,抛出该异常。SecurityException- 由安全管理器抛出的异常,指示存在安全侵犯。StringIndexOutOfBoundsException- 此异常由 String 方法抛出,指示索引或者为负,或者超出字符串的大小。UnsupportedOperationException- 当不支持请求的操作时,抛出该异常。
# #2. 自定义异常
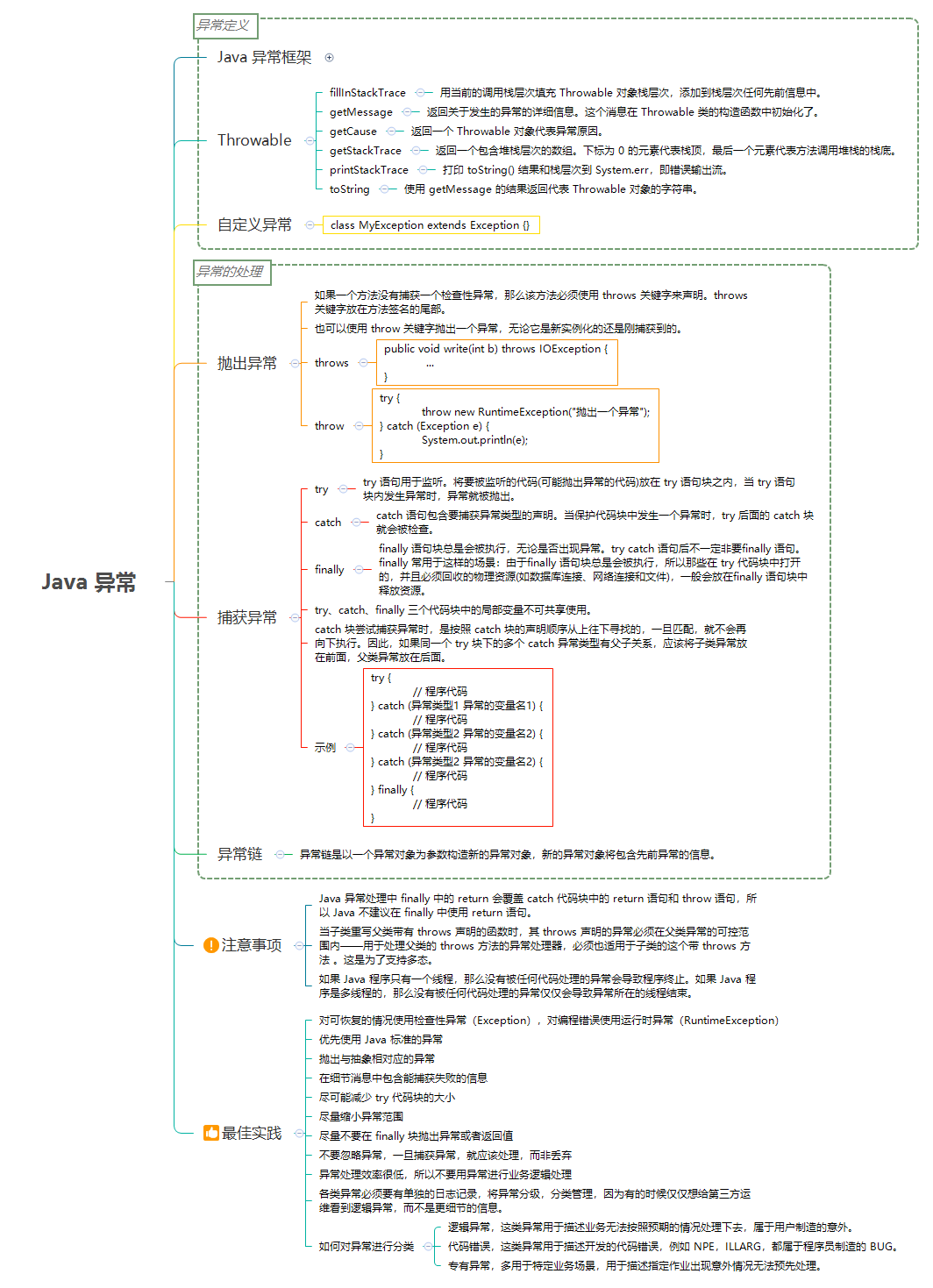
自定义一个异常类,只需要继承 Exception 或 RuntimeException 即可。
示例:
public class MyExceptionDemo {
public static void main(String[] args) {
throw new MyException("自定义异常");
}
static class MyException extends RuntimeException {
public MyException(String message) {
super(message);
}
}
}输出:
Exception in thread "main" io.github.dunwu.javacore.exception.MyExceptionDemo$MyException: 自定义异常
at io.github.dunwu.javacore.exception.MyExceptionDemo.main(MyExceptionDemo.java:9)# #3. 抛出异常
如果想在程序中明确地抛出异常,需要用到 throw 和 throws 。
如果一个方法没有捕获一个检查性异常,那么该方法必须使用 throws 关键字来声明。 throws 关键字放在方法签名的尾部。
throw 示例:
public class ThrowDemo {
public static void f() {
try {
throw new RuntimeException("抛出一个异常");
} catch (Exception e) {
System.out.println(e);
}
}
public static void main(String[] args) {
f();
}
};输出:
java.lang.RuntimeException: 抛出一个异常也可以使用 throw 关键字抛出一个异常,无论它是新实例化的还是刚捕获到的。
throws 示例:
public class ThrowsDemo {
public static void f1() throws NoSuchMethodException, NoSuchFieldException {
Field field = Integer.class.getDeclaredField("digits");
if (field != null) {
System.out.println("反射获取 digits 方法成功");
}
Method method = String.class.getMethod("toString", int.class);
if (method != null) {
System.out.println("反射获取 toString 方法成功");
}
}
public static void f2() {
try {
// 调用 f1 处,如果不用 try catch ,编译时会报错
f1();
} catch (NoSuchMethodException e) {
e.printStackTrace();
} catch (NoSuchFieldException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
f2();
}
};输出:
反射获取 digits 方法成功
java.lang.NoSuchMethodException: java.lang.String.toString(int)
at java.lang.Class.getMethod(Class.java:1786)
at io.github.dunwu.javacore.exception.ThrowsDemo.f1(ThrowsDemo.java:12)
at io.github.dunwu.javacore.exception.ThrowsDemo.f2(ThrowsDemo.java:21)
at io.github.dunwu.javacore.exception.ThrowsDemo.main(ThrowsDemo.java:30)throw 和 throws 的区别:
- throws 使用在函数上,throw 使用在函数内。
- throws 后面跟异常类,可以跟多个,用逗号区别;throw 后面跟的是异常对象。
# #4. 捕获异常
使用 try 和 catch 关键字可以捕获异常。try catch 代码块放在异常可能发生的地方。
它的语法形式如下:
try {
// 可能会发生异常的代码块
} catch (Exception e1) {
// 捕获并处理try抛出的异常类型Exception
} catch (Exception2 e2) {
// 捕获并处理try抛出的异常类型Exception2
} finally {
// 无论是否发生异常,都将执行的代码块
}此外,JDK7 以后, catch 多种异常时,也可以像下面这样简化代码:
try {
// 可能会发生异常的代码块
} catch (Exception | Exception2 e) {
// 捕获并处理try抛出的异常类型
} finally {
// 无论是否发生异常,都将执行的代码块
}try-try语句用于监听。将要被监听的代码 (可能抛出异常的代码) 放在try语句块之内,当try语句块内发生异常时,异常就被抛出。catch-catch语句包含要捕获异常类型的声明。当保护代码块中发生一个异常时,try后面的catch块就会被检查。finally-finally语句块总是会被执行,无论是否出现异常。try catch语句后不一定非要finally语句。finally常用于这样的场景:由于finally语句块总是会被执行,所以那些在try代码块中打开的,并且必须回收的物理资源 (如数据库连接、网络连接和文件),一般会放在finally语句块中释放资源。try、catch、finally三个代码块中的局部变量不可共享使用。catch块尝试捕获异常时,是按照catch块的声明顺序从上往下寻找的,一旦匹配,就不会再向下执行。因此,如果同一个try块下的多个catch异常类型有父子关系,应该将子类异常放在前面,父类异常放在后面。
示例:
public class TryCatchFinallyDemo {
public static void main(String[] args) {
try {
// 此处产生了异常
int temp = 10 / 0;
System.out.println("两个数字相除的结果:" + temp);
System.out.println("----------------------------");
} catch (ArithmeticException e) {
System.out.println("出现异常了:" + e);
} finally {
System.out.println("不管是否出现异常,都执行此代码");
}
}
};运行时输出:
出现异常了:java.lang.ArithmeticException: / by zero
不管是否出现异常,都执行此代码# #5. 异常链
异常链是以一个异常对象为参数构造新的异常对象,新的异常对象将包含先前异常的信息。
通过使用异常链,我们可以提高代码的可理解性、系统的可维护性和友好性。
我们有两种方式处理异常,一是 throws 抛出交给上级处理,二是 try…catch 做具体处理。 try…catch 的 catch 块我们可以不需要做任何处理,仅仅只用 throw 这个关键字将我们封装异常信息主动抛出来。然后在通过关键字 throws 继续抛出该方法异常。它的上层也可以做这样的处理,以此类推就会产生一条由异常构成的异常链。
【示例】
public class ExceptionChainDemo {
static class MyException1 extends Exception {
public MyException1(String message) {
super(message);
}
}
static class MyException2 extends Exception {
public MyException2(String message, Throwable cause) {
super(message, cause);
}
}
public static void f1() throws MyException1 {
throw new MyException1("出现 MyException1");
}
public static void f2() throws MyException2 {
try {
f1();
} catch (MyException1 e) {
throw new MyException2("出现 MyException2", e);
}
}
public static void main(String[] args) throws MyException2 {
f2();
}
}输出:
Exception in thread "main" io.github.dunwu.javacore.exception.ExceptionChainDemo$MyException2: 出现 MyException2
at io.github.dunwu.javacore.exception.ExceptionChainDemo.f2(ExceptionChainDemo.java:29)
at io.github.dunwu.javacore.exception.ExceptionChainDemo.main(ExceptionChainDemo.java:34)
Caused by: io.github.dunwu.javacore.exception.ExceptionChainDemo$MyException1: 出现 MyException1
at io.github.dunwu.javacore.exception.ExceptionChainDemo.f1(ExceptionChainDemo.java:22)
at io.github.dunwu.javacore.exception.ExceptionChainDemo.f2(ExceptionChainDemo.java:27)
... 1 more扩展阅读:https://juejin.im/post/5b6d61e55188251b38129f9a#heading-10
这篇文章中对于异常链讲解比较详细。
# #6. 异常注意事项
# #6.1. finally 覆盖异常
Java 异常处理中 finally 中的 return 会覆盖 catch 代码块中的 return 语句和 throw 语句,所以 Java 不建议在 finally 中使用 return 语句。
此外 finally 中的 throw 语句也会覆盖 catch 代码块中的 return 语句和 throw 语句。
示例:
public class FinallyOverrideExceptionDemo {
static void f() throws Exception {
try {
throw new Exception("A");
} catch (Exception e) {
throw new Exception("B");
} finally {
throw new Exception("C");
}
}
public static void main(String[] args) {
try {
f();
} catch (Exception e) {
System.out.println(e.getMessage());
}
}
}输出:C
# #6.2. 覆盖抛出异常的方法
当子类重写父类带有 throws 声明的函数时,其 throws 声明的异常必须在父类异常的可控范围内 —— 用于处理父类的 throws 方法的异常处理器,必须也适用于子类的这个带 throws 方法 。这是为了支持多态。
示例:
public class ExceptionOverrideDemo {
static class Father {
public void start() throws IOException {
throw new IOException();
}
}
static class Son extends Father {
@Override
public void start() throws SQLException {
throw new SQLException();
}
}
public static void main(String[] args) {
Father obj1 = new Father();
Father obj2 = new Son();
try {
obj1.start();
obj2.start();
} catch (IOException e) {
e.printStackTrace();
}
}
}上面的示例编译时会报错,原因在于:
因为 Son 类抛出异常的实质是
SQLException,而IOException无法处理它。那么这里的 try catch 就不能处理 Son 中的异常了。多态就不能实现了。
# #6.3. 异常和线程
如果 Java 程序只有一个线程,那么没有被任何代码处理的异常会导致程序终止。如果 Java 程序是多线程的,那么没有被任何代码处理的异常仅仅会导致异常所在的线程结束。
# #7. 最佳实践
- 对可恢复的情况使用检查性异常(Exception),对编程错误使用运行时异常(RuntimeException)。
- 优先使用 Java 标准的异常。
- 抛出与抽象相对应的异常。
- 在细节消息中包含能捕获失败的信息。
- 尽可能减少 try 代码块的大小。
- 尽量缩小异常范围。例如,如果明知尝试捕获的是一个
ArithmeticException,就应该catchArithmeticException,而不是catch范围较大的RuntimeException,甚至是Exception。 - 尽量不要在
finally块抛出异常或者返回值。 - 不要忽略异常,一旦捕获异常,就应该处理,而非丢弃。
- 异常处理效率很低,所以不要用异常进行业务逻辑处理。
- 各类异常必须要有单独的日志记录,将异常分级,分类管理,因为有的时候仅仅想给第三方运维看到逻辑异常,而不是更细节的信息。
- 如何对异常进行分类:
- 逻辑异常,这类异常用于描述业务无法按照预期的情况处理下去,属于用户制造的意外。
- 代码错误,这类异常用于描述开发的代码错误,例如 NPE,ILLARG,都属于程序员制造的 BUG。
- 专有异常,多用于特定业务场景,用于描述指定作业出现意外情况无法预先处理。
# 深入理解 Java 泛型
📦 本文以及示例源码已归档在 javacore(opens new window)
# #1. 为什么需要泛型
JDK5 引入了泛型机制。
为什么需要泛型呢?回答这个问题前,先让我们来看一个示例。
public class NoGenericsDemo {
public static void main(String[] args) {
List list = new ArrayList<>();
list.add("abc");
list.add(18);
list.add(new double[] {1.0, 2.0});
Object obj1 = list.get(0);
Object obj2 = list.get(1);
Object obj3 = list.get(2);
System.out.println("obj1 = [" + obj1 + "]");
System.out.println("obj2 = [" + obj2 + "]");
System.out.println("obj3 = [" + obj3 + "]");
int num1 = (int)list.get(0);
int num2 = (int)list.get(1);
int num3 = (int)list.get(2);
System.out.println("num1 = [" + num1 + "]");
System.out.println("num2 = [" + num2 + "]");
System.out.println("num3 = [" + num3 + "]");
}
}
// Output:
// obj1 = [abc]
// obj2 = [18]
// obj3 = [[D@47089e5f]
// Exception in thread "main" java.lang.ClassCastException: java.lang.String cannot be cast to java.lang.Integer
// at io.github.dunwu.javacore.generics.NoGenericsDemo.main(NoGenericsDemo.java:23)示例说明:
在上面的示例中,
List容器没有指定存储数据类型,这种情况下,可以向List添加任意类型数据,编译器不会做类型检查,而是默默的将所有数据都转为Object。假设,最初我们希望向
List存储的是整形数据,假设,某个家伙不小心存入了其他数据类型。当你试图从容器中取整形数据时,由于List当成Object类型来存储,你不得不使用类型强制转换。在运行时,才会发现List中数据不存储一致的问题,这就为程序运行带来了很大的风险(无形伤害最为致命)。
而泛型的出现,解决了类型安全问题。
泛型具有以下优点:
- 编译时的强类型检查
泛型要求在声明时指定实际数据类型,Java 编译器在编译时会对泛型代码做强类型检查,并在代码违反类型安全时发出告警。早发现,早治理,把隐患扼杀于摇篮,在编译时发现并修复错误所付出的代价远比在运行时小。
- 避免了类型转换
未使用泛型:
List list = new ArrayList();
list.add("hello");
String s = (String) list.get(0);使用泛型:
List<String> list = new ArrayList<String>();
list.add("hello");
String s = list.get(0); // no cast- 泛型编程可以实现通用算法
通过使用泛型,程序员可以实现通用算法,这些算法可以处理不同类型的集合,可以自定义,并且类型安全且易于阅读。
# #2. 泛型类型
泛型类型 是被参数化的类或接口。
# #2.1. 泛型类
泛型类的语法形式:
class name<T1, T2, ..., Tn> { /* ... */ }泛型类的声明和非泛型类的声明类似,除了在类名后面添加了类型参数声明部分。由尖括号( <> )分隔的类型参数部分跟在类名后面。它指定类型参数(也称为类型变量)T1,T2,… 和 Tn。
一般将泛型中的类名称为原型,而将 <> 指定的参数称为类型参数。
- 未应用泛型的类
在泛型出现之前,如果一个类想持有一个可以为任意类型的数据,只能使用 Object 做类型转换。示例如下:
public class Info {
private Object value;
public Object getValue() {
return value;
}
public void setValue(Object value) {
this.value = value;
}
}- 单类型参数的泛型类
public class Info<T> {
private T value;
public Info() { }
public Info(T value) {
this.value = value;
}
public T getValue() {
return value;
}
public void setValue(T value) {
this.value = value;
}
@Override
public String toString() {
return "Info{" + "value=" + value + '}';
}
}
public class GenericsClassDemo01 {
public static void main(String[] args) {
Info<Integer> info = new Info<>();
info.setValue(10);
System.out.println(info.getValue());
Info<String> info2 = new Info<>();
info2.setValue("xyz");
System.out.println(info2.getValue());
}
}
// Output:
// 10
// xyz在上面的例子中,在初始化一个泛型类时,使用 <> 指定了内部具体类型,在编译时就会根据这个类型做强类型检查。
实际上,不使用 <> 指定内部具体类型,语法上也是支持的(不推荐这么做),如下所示:
public static void main(String[] args) {
Info info = new Info();
info.setValue(10);
System.out.println(info.getValue());
info.setValue("abc");
System.out.println(info.getValue());
}示例说明:
上面的例子,不会产生编译错误,也能正常运行。但这样的调用就失去泛型类型的优势。
- 多个类型参数的泛型类
public class MyMap<K,V> {
private K key;
private V value;
public MyMap(K key, V value) {
this.key = key;
this.value = value;
}
@Override
public String toString() {
return "MyMap{" + "key=" + key + ", value=" + value + '}';
}
}
public class GenericsClassDemo02 {
public static void main(String[] args) {
MyMap<Integer, String> map = new MyMap<>(1, "one");
System.out.println(map);
}
}
// Output:
// MyMap{key=1, value=one}- 泛型类的类型嵌套
public class GenericsClassDemo03 {
public static void main(String[] args) {
Info<String> info = new Info("Hello");
MyMap<Integer, Info<String>> map = new MyMap<>(1, info);
System.out.println(map);
}
}
// Output:
// MyMap{key=1, value=Info{value=Hello}}# #2.2. 泛型接口
接口也可以声明泛型。
泛型接口语法形式:
public interface Content<T> {
T text();
}泛型接口有两种实现方式:
- 实现接口的子类明确声明泛型类型
public class GenericsInterfaceDemo01 implements Content<Integer> {
private int text;
public GenericsInterfaceDemo01(int text) {
this.text = text;
}
@Override
public Integer text() { return text; }
public static void main(String[] args) {
GenericsInterfaceDemo01 demo = new GenericsInterfaceDemo01(10);
System.out.print(demo.text());
}
}
// Output:
// 10- 实现接口的子类不明确声明泛型类型
public class GenericsInterfaceDemo02<T> implements Content<T> {
private T text;
public GenericsInterfaceDemo02(T text) {
this.text = text;
}
@Override
public T text() { return text; }
public static void main(String[] args) {
GenericsInterfaceDemo02<String> gen = new GenericsInterfaceDemo02<>("ABC");
System.out.print(gen.text());
}
}
// Output:
// ABC# #3. 泛型方法
泛型方法是引入其自己的类型参数的方法。泛型方法可以是普通方法、静态方法以及构造方法。
泛型方法语法形式如下:
public <T> T func(T obj) {}是否拥有泛型方法,与其所在的类是否是泛型没有关系。
泛型方法的语法包括一个类型参数列表,在尖括号内,它出现在方法的返回类型之前。对于静态泛型方法,类型参数部分必须出现在方法的返回类型之前。类型参数能被用来声明返回值类型,并且能作为泛型方法得到的实际类型参数的占位符。
使用泛型方法的时候,通常不必指明类型参数,因为编译器会为我们找出具体的类型。这称为类型参数推断(type argument inference)。类型推断只对赋值操作有效,其他时候并不起作用。如果将一个返回类型为 T 的泛型方法调用的结果作为参数,传递给另一个方法,这时编译器并不会执行推断。编译器会认为:调用泛型方法后,其返回值被赋给一个 Object 类型的变量。
public class GenericsMethodDemo01 {
public static <T> void printClass(T obj) {
System.out.println(obj.getClass().toString());
}
public static void main(String[] args) {
printClass("abc");
printClass(10);
}
}
// Output:
// class java.lang.String
// class java.lang.Integer泛型方法中也可以使用可变参数列表
public class GenericVarargsMethodDemo {
public static <T> List<T> makeList(T... args) {
List<T> result = new ArrayList<T>();
Collections.addAll(result, args);
return result;
}
public static void main(String[] args) {
List<String> ls = makeList("A");
System.out.println(ls);
ls = makeList("A", "B", "C");
System.out.println(ls);
}
}
// Output:
// [A]
// [A, B, C]# #4. 类型擦除
Java 语言引入泛型是为了在编译时提供更严格的类型检查,并支持泛型编程。不同于 C++ 的模板机制,Java 泛型是使用类型擦除来实现的,使用泛型时,任何具体的类型信息都被擦除了。
那么,类型擦除做了什么呢?它做了以下工作:
- 把泛型中的所有类型参数替换为 Object,如果指定类型边界,则使用类型边界来替换。因此,生成的字节码仅包含普通的类,接口和方法。
- 擦除出现的类型声明,即去掉
<>的内容。比如T get()方法声明就变成了Object get();List<String>就变成了List。如有必要,插入类型转换以保持类型安全。 - 生成桥接方法以保留扩展泛型类型中的多态性。类型擦除确保不为参数化类型创建新类;因此,泛型不会产生运行时开销。
让我们来看一个示例:
public class GenericsErasureTypeDemo {
public static void main(String[] args) {
List<Object> list1 = new ArrayList<Object>();
List<String> list2 = new ArrayList<String>();
System.out.println(list1.getClass());
System.out.println(list2.getClass());
}
}
// Output:
// class java.util.ArrayList
// class java.util.ArrayList示例说明:
上面的例子中,虽然指定了不同的类型参数,但是 list1 和 list2 的类信息却是一样的。
这是因为:使用泛型时,任何具体的类型信息都被擦除了。这意味着:
ArrayList<Object>和ArrayList<String>在运行时,JVM 将它们视为同一类型。
Java 泛型的实现方式不太优雅,但这是因为泛型是在 JDK5 时引入的,为了兼容老代码,必须在设计上做一定的折中。
# #5. 泛型和继承
泛型不能用于显式地引用运行时类型的操作之中,例如:转型、instanceof 操作和 new 表达式。因为所有关于参数的类型信息都丢失了。当你在编写泛型代码时,必须时刻提醒自己,你只是看起来好像拥有有关参数的类型信息而已。
正是由于泛型时基于类型擦除实现的,所以,泛型类型无法向上转型。
向上转型是指用子类实例去初始化父类,这是面向对象中多态的重要表现。
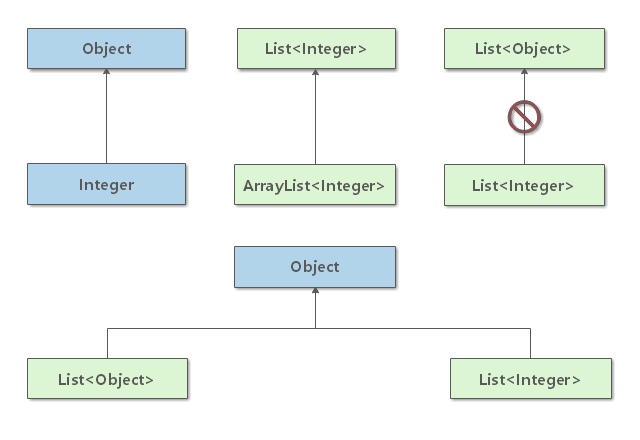
Integer 继承了 Object ; ArrayList 继承了 List ;但是 List<Interger> 却并非继承了 List<Object> 。
这是因为,泛型类并没有自己独有的 Class 类对象。比如:并不存在 List<Object>.class 或是 List<Interger>.class ,Java 编译器会将二者都视为 List.class 。
List<Integer> list = new ArrayList<>();
List<Object> list2 = list; // Erorr# #6. 类型边界
有时您可能希望限制可在参数化类型中用作类型参数的类型。 类型边界 可以对泛型的类型参数设置限制条件。例如,对数字进行操作的方法可能只想接受 Number 或其子类的实例。
要声明有界类型参数,请列出类型参数的名称,然后是 extends 关键字,后跟其限制类或接口。
类型边界的语法形式如下:
<T extends XXX>示例:
public class GenericsExtendsDemo01 {
static <T extends Comparable<T>> T max(T x, T y, T z) {
T max = x; // 假设x是初始最大值
if (y.compareTo(max) > 0) {
max = y; //y 更大
}
if (z.compareTo(max) > 0) {
max = z; // 现在 z 更大
}
return max; // 返回最大对象
}
public static void main(String[] args) {
System.out.println(max(3, 4, 5));
System.out.println(max(6.6, 8.8, 7.7));
System.out.println(max("pear", "apple", "orange"));
}
}
// Output:
// 5
// 8.8
// pear示例说明:
上面的示例声明了一个泛型方法,类型参数
T extends Comparable<T>表明传入方法中的类型必须实现了 Comparable 接口。
类型边界可以设置多个,语法形式如下:
<T extends B1 & B2 & B3>🔔 注意:extends 关键字后面的第一个类型参数可以是类或接口,其他类型参数只能是接口。
示例:
public class GenericsExtendsDemo02 {
static class A { /* ... */ }
interface B { /* ... */ }
interface C { /* ... */ }
static class D1 <T extends A & B & C> { /* ... */ }
static class D2 <T extends B & A & C> { /* ... */ } // 编译报错
static class E extends A implements B, C { /* ... */ }
public static void main(String[] args) {
D1<E> demo1 = new D1<>();
System.out.println(demo1.getClass().toString());
D1<String> demo2 = new D1<>(); // 编译报错
}
}# #7. 类型通配符
类型通配符 一般是使用 ? 代替具体的类型参数。例如 List<?> 在逻辑上是 List<String> , List<Integer> 等所有 List<具体类型实参> 的父类。
# #7.1. 上界通配符
可以使用 ** 上界通配符 ** 来缩小类型参数的类型范围。
它的语法形式为: <? extends Number>
public class GenericsUpperBoundedWildcardDemo {
public static double sumOfList(List<? extends Number> list) {
double s = 0.0;
for (Number n : list) {
s += n.doubleValue();
}
return s;
}
public static void main(String[] args) {
List<Integer> li = Arrays.asList(1, 2, 3);
System.out.println("sum = " + sumOfList(li));
}
}
// Output:
// sum = 6.0# #7.2. 下界通配符
** 下界通配符 ** 将未知类型限制为该类型的特定类型或超类类型。
🔔 注意:上界通配符和下界通配符不能同时使用。
它的语法形式为: <? super Number>
public class GenericsLowerBoundedWildcardDemo {
public static void addNumbers(List<? super Integer> list) {
for (int i = 1; i <= 5; i++) {
list.add(i);
}
}
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
addNumbers(list);
System.out.println(Arrays.deepToString(list.toArray()));
}
}
// Output:
// [1, 2, 3, 4, 5]# #7.3. 无界通配符
无界通配符有两种应用场景:
- 可以使用 Object 类中提供的功能来实现的方法。
- 使用不依赖于类型参数的泛型类中的方法。
语法形式: <?>
public class GenericsUnboundedWildcardDemo {
public static void printList(List<?> list) {
for (Object elem : list) {
System.out.print(elem + " ");
}
System.out.println();
}
public static void main(String[] args) {
List<Integer> li = Arrays.asList(1, 2, 3);
List<String> ls = Arrays.asList("one", "two", "three");
printList(li);
printList(ls);
}
}
// Output:
// 1 2 3
// one two three# #7.4. 通配符和向上转型
前面,我们提到:泛型不能向上转型。但是,我们可以通过使用通配符来向上转型。
public class GenericsWildcardDemo {
public static void main(String[] args) {
List<Integer> intList = new ArrayList<>();
List<Number> numList = intList; // Error
List<? extends Integer> intList2 = new ArrayList<>();
List<? extends Number> numList2 = intList2; // OK
}
}# #8. 泛型的约束
Pair<int, char> p = new Pair<>(8, 'a'); // 编译错误public static <E> void append(List<E> list) {
E elem = new E(); // 编译错误
list.add(elem);
}public class MobileDevice<T> {
private static T os; // error
// ...
}public static <E> void rtti(List<E> list) {
if (list instanceof ArrayList<Integer>) { // 编译错误
// ...
}
}
List<Integer> li = new ArrayList<>();
List<Number> ln = (List<Number>) li; // 编译错误List<Integer>[] arrayOfLists = new List<Integer>[2]; // 编译错误// Extends Throwable indirectly
class MathException<T> extends Exception { /* ... */ } // 编译错误
// Extends Throwable directly
class QueueFullException<T> extends Throwable { /* ... */ // 编译错误
public static <T extends Exception, J> void execute(List<J> jobs) {
try {
for (J job : jobs)
// ...
} catch (T e) { // compile-time error
// ...
}
}public class Example {
public void print(Set<String> strSet) { }
public void print(Set<Integer> intSet) { } // 编译错误
}# #9. 泛型最佳实践
# #9.1. 泛型命名
泛型一些约定俗成的命名:
- E - Element
- K - Key
- N - Number
- T - Type
- V - Value
- S,U,V etc. - 2nd, 3rd, 4th types
# #9.2. 使用泛型的建议
- 消除类型检查告警
- List 优先于数组
- 优先考虑使用泛型来提高代码通用性
- 优先考虑泛型方法来限定泛型的范围
- 利用有限制通配符来提升 API 的灵活性
- 优先考虑类型安全的异构容器
# #10. 小结
# 深入理解 Java 反射和动态代理
📦 本文以及示例源码已归档在 javacore(opens new window)
- \1. 反射简介
- \2. 反射机制
- \3. 使用反射
- \4. 动态代理
- 5. 参考资料
# #1. 反射简介
# #1.1. 什么是反射
反射 (Reflection) 是 Java 程序开发语言的特征之一,它允许运行中的 Java 程序获取自身的信息,并且可以操作类或对象的内部属性。
通过反射机制,可以在运行时访问 Java 对象的属性,方法,构造方法等。
# #1.2. 反射的应用场景
反射的主要应用场景有:
- 开发通用框架 - 反射最重要的用途就是开发各种通用框架。很多框架(比如 Spring)都是配置化的(比如通过 XML 文件配置 JavaBean、Filter 等),为了保证框架的通用性,它们可能需要根据配置文件加载不同的对象或类,调用不同的方法,这个时候就必须用到反射 —— 运行时动态加载需要加载的对象。
- 动态代理 - 在切面编程(AOP)中,需要拦截特定的方法,通常,会选择动态代理方式。这时,就需要反射技术来实现了。
- 注解 - 注解本身仅仅是起到标记作用,它需要利用反射机制,根据注解标记去调用注解解释器,执行行为。如果没有反射机制,注解并不比注释更有用。
- 可扩展性功能 - 应用程序可以通过使用完全限定名称创建可扩展性对象实例来使用外部的用户定义类。
# #1.3. 反射的缺点
- 性能开销 - 由于反射涉及动态解析的类型,因此无法执行某些 Java 虚拟机优化。因此,反射操作的性能要比非反射操作的性能要差,应该在性能敏感的应用程序中频繁调用的代码段中避免。
- 破坏封装性 - 反射调用方法时可以忽略权限检查,因此可能会破坏封装性而导致安全问题。
- 内部曝光 - 由于反射允许代码执行在非反射代码中非法的操作,例如访问私有字段和方法,所以反射的使用可能会导致意想不到的副作用,这可能会导致代码功能失常并可能破坏可移植性。反射代码打破了抽象,因此可能会随着平台的升级而改变行为。
# #2. 反射机制
# #2.1. 类加载过程
类加载的完整过程如下:
- 在编译时,Java 编译器编译好
.java文件之后,在磁盘中产生.class文件。.class文件是二进制文件,内容是只有 JVM 能够识别的机器码。 - JVM 中的类加载器读取字节码文件,取出二进制数据,加载到内存中,解析.class 文件内的信息。类加载器会根据类的全限定名来获取此类的二进制字节流;然后,将字节流所代表的静态存储结构转化为方法区的运行时数据结构;接着,在内存中生成代表这个类的
java.lang.Class对象。 - 加载结束后,JVM 开始进行连接阶段(包含验证、准备、初始化)。经过这一系列操作,类的变量会被初始化。
# #2.2. Class 对象
要想使用反射,首先需要获得待操作的类所对应的 Class 对象。Java 中,无论生成某个类的多少个对象,这些对象都会对应于同一个 Class 对象。这个 Class 对象是由 JVM 生成的,通过它能够获悉整个类的结构。所以, java.lang.Class 可以视为所有反射 API 的入口点。
反射的本质就是:在运行时,把 Java 类中的各种成分映射成一个个的 Java 对象。
举例来说,假如定义了以下代码:
User user = new User();步骤说明:
- JVM 加载方法的时候,遇到
new User(),JVM 会根据User的全限定名去加载User.class。 - JVM 会去本地磁盘查找
User.class文件并加载 JVM 内存中。 - JVM 通过调用类加载器自动创建这个类对应的
Class对象,并且存储在 JVM 的方法区。注意:一个类有且只有一个Class对象。
# #2.3. 方法的反射调用
方法的反射调用,也就是 Method.invoke 方法。
Method.invoke 方法源码:
public final class Method extends Executable {
...
public Object invoke(Object obj, Object... args) throws ... {
... // 权限检查
MethodAccessor ma = methodAccessor;
if (ma == null) {
ma = acquireMethodAccessor();
}
return ma.invoke(obj, args);
}
}Method.invoke 方法实际上委派给 MethodAccessor 接口来处理。它有两个已有的具体实现:
NativeMethodAccessorImpl:本地方法来实现反射调用DelegatingMethodAccessorImpl:委派模式来实现反射调用
每个 Method 实例的第一次反射调用都会生成一个委派实现( DelegatingMethodAccessorImpl ),它所委派的具体实现便是一个本地实现( NativeMethodAccessorImpl )。本地实现非常容易理解。当进入了 Java 虚拟机内部之后,我们便拥有了 Method 实例所指向方法的具体地址。这时候,反射调用无非就是将传入的参数准备好,然后调用进入目标方法。
【示例】通过抛出异常方式 打印 Method.invoke 调用轨迹
public class MethodDemo01 {
public static void target(int i) {
new Exception("#" + i).printStackTrace();
}
public static void main(String[] args) throws Exception {
Class<?> clazz = Class.forName("io.github.dunwu.javacore.reflect.MethodDemo01");
Method method = clazz.getMethod("target", int.class);
method.invoke(null, 0);
}
}
// Output:
// java.lang.Exception: #0
// at io.github.dunwu.javacore.reflect.MethodDemo01.target(MethodDemo01.java:12)
// at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
// at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)先调用 DelegatingMethodAccessorImpl ;然后调用 NativeMethodAccessorImpl ,最后调用实际方法。
为什么反射调用 DelegatingMethodAccessorImpl 作为中间层,而不是直接交给本地实现?
其实,Java 的反射调用机制还设立了另一种动态生成字节码的实现(下称动态实现),直接使用 invoke 指令来调用目标方法。之所以采用委派实现,便是为了能够在本地实现以及动态实现中切换。动态实现和本地实现相比,其运行效率要快上 20 倍。这是因为动态实现无需经过 Java 到 C++ 再到 Java 的切换,但由于生成字节码十分耗时,仅调用一次的话,反而是本地实现要快上 3 到 4 倍。
考虑到许多反射调用仅会执行一次,Java 虚拟机设置了一个阈值 15(可以通过 -Dsun.reflect.inflationThreshold 来调整),当某个反射调用的调用次数在 15 之下时,采用本地实现;当达到 15 时,便开始动态生成字节码,并将委派实现的委派对象切换至动态实现,这个过程我们称之为 Inflation。
【示例】执行 java -verbose:class MethodDemo02 启动
public class MethodDemo02 {
public static void target(int i) {
new Exception("#" + i).printStackTrace();
}
public static void main(String[] args) throws Exception {
Class<?> klass = Class.forName("io.github.dunwu.javacore.reflect.MethodDemo02");
Method method = klass.getMethod("target", int.class);
for (int i = 0; i < 20; i++) {
method.invoke(null, i);
}
}
}输出内容:
// ...省略
java.lang.Exception: #14
at io.github.dunwu.javacore.reflect.MethodDemo02.target(MethodDemo02.java:13)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at io.github.dunwu.javacore.reflect.MethodDemo02.main(MethodDemo02.java:20)
[Loaded sun.reflect.ClassFileConstants from D:\Tools\Java\jdk1.8.0_192\jre\lib\rt.jar]
[Loaded sun.reflect.AccessorGenerator from D:\Tools\Java\jdk1.8.0_192\jre\lib\rt.jar]
[Loaded sun.reflect.MethodAccessorGenerator from D:\Tools\Java\jdk1.8.0_192\jre\lib\rt.jar]
[Loaded sun.reflect.ByteVectorFactory from D:\Tools\Java\jdk1.8.0_192\jre\lib\rt.jar]
[Loaded sun.reflect.ByteVector from D:\Tools\Java\jdk1.8.0_192\jre\lib\rt.jar]
[Loaded sun.reflect.ByteVectorImpl from D:\Tools\Java\jdk1.8.0_192\jre\lib\rt.jar]
[Loaded sun.reflect.ClassFileAssembler from D:\Tools\Java\jdk1.8.0_192\jre\lib\rt.jar]
[Loaded sun.reflect.UTF8 from D:\Tools\Java\jdk1.8.0_192\jre\lib\rt.jar]
[Loaded sun.reflect.Label from D:\Tools\Java\jdk1.8.0_192\jre\lib\rt.jar]
[Loaded sun.reflect.Label$PatchInfo from D:\Tools\Java\jdk1.8.0_192\jre\lib\rt.jar]
[Loaded java.util.ArrayList$Itr from D:\Tools\Java\jdk1.8.0_192\jre\lib\rt.jar]
[Loaded sun.reflect.MethodAccessorGenerator$1 from D:\Tools\Java\jdk1.8.0_192\jre\lib\rt.jar]
[Loaded sun.reflect.ClassDefiner from D:\Tools\Java\jdk1.8.0_192\jre\lib\rt.jar]
[Loaded sun.reflect.ClassDefiner$1 from D:\Tools\Java\jdk1.8.0_192\jre\lib\rt.jar]
[Loaded sun.reflect.GeneratedMethodAccessor1 from __JVM_DefineClass__]
java.lang.Exception: #15
at io.github.dunwu.javacore.reflect.MethodDemo02.target(MethodDemo02.java:13)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at io.github.dunwu.javacore.reflect.MethodDemo02.main(MethodDemo02.java:20)
[Loaded java.util.concurrent.ConcurrentHashMap$ForwardingNode from D:\Tools\Java\jdk1.8.0_192\jre\lib\rt.jar]
java.lang.Exception: #16
at io.github.dunwu.javacore.reflect.MethodDemo02.target(MethodDemo02.java:13)
at sun.reflect.GeneratedMethodAccessor1.invoke(Unknown Source)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at io.github.dunwu.javacore.reflect.MethodDemo02.main(MethodDemo02.java:20)
// ...省略可以看到,从第 16 次开始后,都是使用 DelegatingMethodAccessorImpl ,不再使用本地实现 NativeMethodAccessorImpl 。
# #2.4. 反射调用的开销
方法的反射调用会带来不少性能开销,原因主要有三个:
- 变长参数方法导致的 Object 数组
- 基本类型的自动装箱、拆箱
- 还有最重要的方法内联
Class.forName 会调用本地方法, Class.getMethod 则会遍历该类的公有方法。如果没有匹配到,它还将遍历父类的公有方法。可想而知,这两个操作都非常费时。
注意,以
getMethod为代表的查找方法操作,会返回查找得到结果的一份拷贝。因此,我们应当避免在热点代码中使用返回Method数组的getMethods或者getDeclaredMethods方法,以减少不必要的堆空间消耗。在实践中,我们往往会在应用程序中缓存Class.forName和Class.getMethod的结果。
下面只关注反射调用本身的性能开销。
第一,由于 Method.invoke 是一个变长参数方法,在字节码层面它的最后一个参数会是 Object 数组(感兴趣的同学私下可以用 javap 查看)。Java 编译器会在方法调用处生成一个长度为传入参数数量的 Object 数组,并将传入参数一一存储进该数组中。
第二,由于 Object 数组不能存储基本类型,Java 编译器会对传入的基本类型参数进行自动装箱。
这两个操作除了带来性能开销外,还可能占用堆内存,使得 GC 更加频繁。(如果你感兴趣的话,可以用虚拟机参数 -XX:+PrintGC 试试。)那么,如何消除这部分开销呢?
# #3. 使用反射
# #3.1. java.lang.reflect 包
Java 中的 java.lang.reflect 包提供了反射功能。 java.lang.reflect 包中的类都没有 public 构造方法。
java.lang.reflect 包的核心接口和类如下:
Member接口:反映关于单个成员 (字段或方法) 或构造函数的标识信息。Field类:提供一个类的域的信息以及访问类的域的接口。Method类:提供一个类的方法的信息以及访问类的方法的接口。Constructor类:提供一个类的构造函数的信息以及访问类的构造函数的接口。Array类:该类提供动态地生成和访问 JAVA 数组的方法。Modifier类:提供了 static 方法和常量,对类和成员访问修饰符进行解码。Proxy类:提供动态地生成代理类和类实例的静态方法。
# #3.2. 获取 Class 对象
获取 Class 对象的三种方法:
(1) Class.forName 静态方法
【示例】使用 Class.forName 静态方法获取 Class 对象
package io.github.dunwu.javacore.reflect;
public class ReflectClassDemo01 {
public static void main(String[] args) throws ClassNotFoundException {
Class c1 = Class.forName("io.github.dunwu.javacore.reflect.ReflectClassDemo01");
System.out.println(c1.getCanonicalName());
Class c2 = Class.forName("[D");
System.out.println(c2.getCanonicalName());
Class c3 = Class.forName("[[Ljava.lang.String;");
System.out.println(c3.getCanonicalName());
}
}
//Output:
//io.github.dunwu.javacore.reflect.ReflectClassDemo01
//double[]
//java.lang.String[][]使用类的完全限定名来反射对象的类。常见的应用场景为:在 JDBC 开发中常用此方法加载数据库驱动。
(2)类名 + .class
【示例】直接用类名 + .class 获取 Class 对象
public class ReflectClassDemo02 {
public static void main(String[] args) {
boolean b;
// Class c = b.getClass(); // 编译错误
Class c1 = boolean.class;
System.out.println(c1.getCanonicalName());
Class c2 = java.io.PrintStream.class;
System.out.println(c2.getCanonicalName());
Class c3 = int[][][].class;
System.out.println(c3.getCanonicalName());
}
}
//Output:
//boolean
//java.io.PrintStream
//int[][][](3) Object 的 getClass 方法
Object 类中有 getClass 方法,因为所有类都继承 Object 类。从而调用 Object 类来获取 Class 对象。
【示例】 Object 的 getClass 方法获取 Class 对象
package io.github.dunwu.javacore.reflect;
import java.util.HashSet;
import java.util.Set;
public class ReflectClassDemo03 {
enum E {A, B}
public static void main(String[] args) {
Class c = "foo".getClass();
System.out.println(c.getCanonicalName());
Class c2 = ReflectClassDemo03.E.A.getClass();
System.out.println(c2.getCanonicalName());
byte[] bytes = new byte[1024];
Class c3 = bytes.getClass();
System.out.println(c3.getCanonicalName());
Set<String> set = new HashSet<>();
Class c4 = set.getClass();
System.out.println(c4.getCanonicalName());
}
}
//Output:
//java.lang.String
//io.github.dunwu.javacore.reflect.ReflectClassDemo.E
//byte[]
//java.util.HashSet# #3.3. 判断是否为某个类的实例
判断是否为某个类的实例有两种方式:
- 用
instanceof关键字 - 用
Class对象的isInstance方法(它是一个 Native 方法)
【示例】
public class InstanceofDemo {
public static void main(String[] args) {
ArrayList arrayList = new ArrayList();
if (arrayList instanceof List) {
System.out.println("ArrayList is List");
}
if (List.class.isInstance(arrayList)) {
System.out.println("ArrayList is List");
}
}
}
//Output:
//ArrayList is List
//ArrayList is List# #3.4. 创建实例
通过反射来创建实例对象主要有两种方式:
- 用
Class对象的newInstance方法。 - 用
Constructor对象的newInstance方法。
【示例】
public class NewInstanceDemo {
public static void main(String[] args)
throws IllegalAccessException, InstantiationException, NoSuchMethodException, InvocationTargetException {
Class<?> c1 = StringBuilder.class;
StringBuilder sb = (StringBuilder) c1.newInstance();
sb.append("aaa");
System.out.println(sb.toString());
//获取String所对应的Class对象
Class<?> c2 = String.class;
//获取String类带一个String参数的构造器
Constructor constructor = c2.getConstructor(String.class);
//根据构造器创建实例
String str2 = (String) constructor.newInstance("bbb");
System.out.println(str2);
}
}
//Output:
//aaa
//bbb# #3.5. 创建数组实例
数组在 Java 里是比较特殊的一种类型,它可以赋值给一个对象引用。Java 中,通过 Array.newInstance 创建数组的实例。
【示例】利用反射创建数组
public class ReflectArrayDemo {
public static void main(String[] args) throws ClassNotFoundException {
Class<?> cls = Class.forName("java.lang.String");
Object array = Array.newInstance(cls, 25);
//往数组里添加内容
Array.set(array, 0, "Scala");
Array.set(array, 1, "Java");
Array.set(array, 2, "Groovy");
Array.set(array, 3, "Scala");
Array.set(array, 4, "Clojure");
//获取某一项的内容
System.out.println(Array.get(array, 3));
}
}
//Output:
//Scala其中的 Array 类为 java.lang.reflect.Array 类。我们 Array.newInstance 的原型是:
public static Object newInstance(Class<?> componentType, int length)
throws NegativeArraySizeException {
return newArray(componentType, length);
}# #3.6. Field
Class 对象提供以下方法获取对象的成员( Field ):
getFiled- 根据名称获取公有的(public)类成员。getDeclaredField- 根据名称获取已声明的类成员。但不能得到其父类的类成员。getFields- 获取所有公有的(public)类成员。getDeclaredFields- 获取所有已声明的类成员。
示例如下:
public class ReflectFieldDemo {
class FieldSpy<T> {
public boolean[][] b = { {false, false}, {true, true} };
public String name = "Alice";
public List<Integer> list;
public T val;
}
public static void main(String[] args) throws NoSuchFieldException {
Field f1 = FieldSpy.class.getField("b");
System.out.format("Type: %s%n", f1.getType());
Field f2 = FieldSpy.class.getField("name");
System.out.format("Type: %s%n", f2.getType());
Field f3 = FieldSpy.class.getField("list");
System.out.format("Type: %s%n", f3.getType());
Field f4 = FieldSpy.class.getField("val");
System.out.format("Type: %s%n", f4.getType());
}
}
//Output:
//Type: class [[Z
//Type: class java.lang.String
//Type: interface java.util.List
//Type: class java.lang.Object# #3.7. Method
Class 对象提供以下方法获取对象的方法( Method ):
getMethod- 返回类或接口的特定方法。其中第一个参数为方法名称,后面的参数为方法参数对应 Class 的对象。getDeclaredMethod- 返回类或接口的特定声明方法。其中第一个参数为方法名称,后面的参数为方法参数对应 Class 的对象。getMethods- 返回类或接口的所有 public 方法,包括其父类的 public 方法。getDeclaredMethods- 返回类或接口声明的所有方法,包括 public、protected、默认(包)访问和 private 方法,但不包括继承的方法。
获取一个 Method 对象后,可以用 invoke 方法来调用这个方法。
invoke 方法的原型为:
public Object invoke(Object obj, Object... args)
throws IllegalAccessException, IllegalArgumentException,
InvocationTargetException【示例】
public class ReflectMethodDemo {
public static void main(String[] args)
throws NoSuchMethodException, InvocationTargetException, IllegalAccessException {
// 返回所有方法
Method[] methods1 = System.class.getDeclaredMethods();
System.out.println("System getDeclaredMethods 清单(数量 = " + methods1.length + "):");
for (Method m : methods1) {
System.out.println(m);
}
// 返回所有 public 方法
Method[] methods2 = System.class.getMethods();
System.out.println("System getMethods 清单(数量 = " + methods2.length + "):");
for (Method m : methods2) {
System.out.println(m);
}
// 利用 Method 的 invoke 方法调用 System.currentTimeMillis()
Method method = System.class.getMethod("currentTimeMillis");
System.out.println(method);
System.out.println(method.invoke(null));
}
}# #3.8. Constructor
Class 对象提供以下方法获取对象的构造方法( Constructor ):
getConstructor- 返回类的特定 public 构造方法。参数为方法参数对应 Class 的对象。getDeclaredConstructor- 返回类的特定构造方法。参数为方法参数对应 Class 的对象。getConstructors- 返回类的所有 public 构造方法。getDeclaredConstructors- 返回类的所有构造方法。
获取一个 Constructor 对象后,可以用 newInstance 方法来创建类实例。
【示例】
public class ReflectMethodConstructorDemo {
public static void main(String[] args)
throws NoSuchMethodException, IllegalAccessException, InvocationTargetException, InstantiationException {
Constructor<?>[] constructors1 = String.class.getDeclaredConstructors();
System.out.println("String getDeclaredConstructors 清单(数量 = " + constructors1.length + "):");
for (Constructor c : constructors1) {
System.out.println(c);
}
Constructor<?>[] constructors2 = String.class.getConstructors();
System.out.println("String getConstructors 清单(数量 = " + constructors2.length + "):");
for (Constructor c : constructors2) {
System.out.println(c);
}
System.out.println("====================");
Constructor constructor = String.class.getConstructor(String.class);
System.out.println(constructor);
String str = (String) constructor.newInstance("bbb");
System.out.println(str);
}
}# #3.9. 绕开访问限制
有时候,我们需要通过反射访问私有成员、方法。可以使用 Constructor/Field/Method.setAccessible(true) 来绕开 Java 语言的访问限制。
# #4. 动态代理
动态代理是一种方便运行时动态构建代理、动态处理代理方法调用的机制,很多场景都是利用类似机制做到的,比如用来包装 RPC 调用、面向切面的编程(AOP)。
实现动态代理的方式很多,比如 JDK 自身提供的动态代理,就是主要利用了上面提到的反射机制。还有其他的实现方式,比如利用传说中更高性能的字节码操作机制,类似 ASM、cglib(基于 ASM)、Javassist 等。
# #4.1. 静态代理
静态代理其实就是指设计模式中的代理模式。
代理模式为其他对象提供一种代理以控制对这个对象的访问。
Subject 定义了 RealSubject 和 Proxy 的公共接口,这样就在任何使用 RealSubject 的地方都可以使用 Proxy 。
abstract class Subject {
public abstract void Request();
}RealSubject 定义 Proxy 所代表的真实实体。
class RealSubject extends Subject {
@Override
public void Request() {
System.out.println("真实的请求");
}
}Proxy 保存一个引用使得代理可以访问实体,并提供一个与 Subject 的接口相同的接口,这样代理就可以用来替代实体。
class Proxy extends Subject {
private RealSubject real;
@Override
public void Request() {
if (null == real) {
real = new RealSubject();
}
real.Request();
}
}说明:
静态代理模式固然在访问无法访问的资源,增强现有的接口业务功能方面有很大的优点,但是大量使用这种静态代理,会使我们系统内的类的规模增大,并且不易维护;并且由于 Proxy 和 RealSubject 的功能本质上是相同的,Proxy 只是起到了中介的作用,这种代理在系统中的存在,导致系统结构比较臃肿和松散。
# #4.2. JDK 动态代理
为了解决静态代理的问题,就有了创建动态代理的想法:
在运行状态中,需要代理的地方,根据 Subject 和 RealSubject,动态地创建一个 Proxy,用完之后,就会销毁,这样就可以避免了 Proxy 角色的 class 在系统中冗杂的问题了。
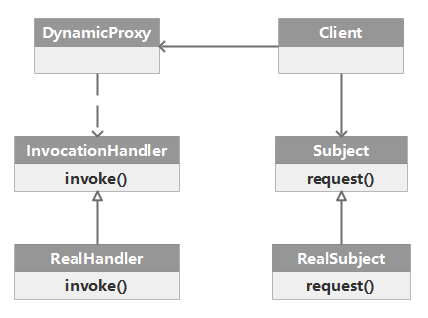
Java 动态代理基于经典代理模式,引入了一个 InvocationHandler , InvocationHandler 负责统一管理所有的方法调用。
动态代理步骤:
- 获取 RealSubject 上的所有接口列表;
- 确定要生成的代理类的类名,默认为:
com.sun.proxy.$ProxyXXXX; - 根据需要实现的接口信息,在代码中动态创建 该 Proxy 类的字节码;
- 将对应的字节码转换为对应的 class 对象;
- 创建
InvocationHandler实例 handler,用来处理Proxy所有方法调用; - Proxy 的 class 对象 以创建的 handler 对象为参数,实例化一个 proxy 对象。
从上面可以看出,JDK 动态代理的实现是基于实现接口的方式,使得 Proxy 和 RealSubject 具有相同的功能。
但其实还有一种思路:通过继承。即:让 Proxy 继承 RealSubject,这样二者同样具有相同的功能,Proxy 还可以通过重写 RealSubject 中的方法,来实现多态。CGLIB 就是基于这种思路设计的。
在 Java 的动态代理机制中,有两个重要的类(接口),一个是 InvocationHandler 接口、另一个则是 Proxy 类,这一个类和一个接口是实现我们动态代理所必须用到的。
# #InvocationHandler 接口
InvocationHandler 接口定义:
public interface InvocationHandler {
public Object invoke(Object proxy, Method method, Object[] args)
throws Throwable;
}每一个动态代理类都必须要实现 InvocationHandler 这个接口,并且每个代理类的实例都关联到了一个 Handler,当我们通过代理对象调用一个方法的时候,这个方法的调用就会被转发为由 InvocationHandler 这个接口的 invoke 方法来进行调用。
我们来看看 InvocationHandler 这个接口的唯一一个方法 invoke 方法:
Object invoke(Object proxy, Method method, Object[] args) throws Throwable参数说明:
- proxy - 代理的真实对象。
- method - 所要调用真实对象的某个方法的
Method对象 - args - 所要调用真实对象某个方法时接受的参数
如果不是很明白,等下通过一个实例会对这几个参数进行更深的讲解。
# #Proxy 类
Proxy 这个类的作用就是用来动态创建一个代理对象的类,它提供了许多的方法,但是我们用的最多的就是 newProxyInstance 这个方法:
public static Object newProxyInstance(ClassLoader loader, Class<?>[] interfaces, InvocationHandler h) throws IllegalArgumentException这个方法的作用就是得到一个动态的代理对象。
参数说明:
- loader - 一个
ClassLoader对象,定义了由哪个ClassLoader对象来对生成的代理对象进行加载。 - interfaces - 一个
Class<?>对象的数组,表示的是我将要给我需要代理的对象提供一组什么接口,如果我提供了一组接口给它,那么这个代理对象就宣称实现了该接口 (多态),这样我就能调用这组接口中的方法了 - h - 一个
InvocationHandler对象,表示的是当我这个动态代理对象在调用方法的时候,会关联到哪一个InvocationHandler对象上
# #JDK 动态代理实例
上面的内容介绍完这两个接口 (类) 以后,我们来通过一个实例来看看我们的动态代理模式是什么样的:
首先我们定义了一个 Subject 类型的接口,为其声明了两个方法:
public interface Subject {
void hello(String str);
String bye();
}接着,定义了一个类来实现这个接口,这个类就是我们的真实对象,RealSubject 类:
public class RealSubject implements Subject {
@Override
public void hello(String str) {
System.out.println("Hello " + str);
}
@Override
public String bye() {
System.out.println("Goodbye");
return "Over";
}
}下一步,我们就要定义一个动态代理类了,前面说个,每一个动态代理类都必须要实现 InvocationHandler 这个接口,因此我们这个动态代理类也不例外:
public class InvocationHandlerDemo implements InvocationHandler {
// 这个就是我们要代理的真实对象
private Object subject;
// 构造方法,给我们要代理的真实对象赋初值
public InvocationHandlerDemo(Object subject) {
this.subject = subject;
}
@Override
public Object invoke(Object object, Method method, Object[] args)
throws Throwable {
// 在代理真实对象前我们可以添加一些自己的操作
System.out.println("Before method");
System.out.println("Call Method: " + method);
// 当代理对象调用真实对象的方法时,其会自动的跳转到代理对象关联的handler对象的invoke方法来进行调用
Object obj = method.invoke(subject, args);
// 在代理真实对象后我们也可以添加一些自己的操作
System.out.println("After method");
System.out.println();
return obj;
}
}最后,来看看我们的 Client 类:
public class Client {
public static void main(String[] args) {
// 我们要代理的真实对象
Subject realSubject = new RealSubject();
// 我们要代理哪个真实对象,就将该对象传进去,最后是通过该真实对象来调用其方法的
InvocationHandler handler = new InvocationHandlerDemo(realSubject);
/*
* 通过Proxy的newProxyInstance方法来创建我们的代理对象,我们来看看其三个参数
* 第一个参数 handler.getClass().getClassLoader() ,我们这里使用handler这个类的ClassLoader对象来加载我们的代理对象
* 第二个参数realSubject.getClass().getInterfaces(),我们这里为代理对象提供的接口是真实对象所实行的接口,表示我要代理的是该真实对象,这样我就能调用这组接口中的方法了
* 第三个参数handler, 我们这里将这个代理对象关联到了上方的 InvocationHandler 这个对象上
*/
Subject subject = (Subject)Proxy.newProxyInstance(handler.getClass().getClassLoader(), realSubject
.getClass().getInterfaces(), handler);
System.out.println(subject.getClass().getName());
subject.hello("World");
String result = subject.bye();
System.out.println("Result is: " + result);
}
}我们先来看看控制台的输出:
com.sun.proxy.$Proxy0
Before method
Call Method: public abstract void io.github.dunwu.javacore.reflect.InvocationHandlerDemo$Subject.hello(java.lang.String)
Hello World
After method
Before method
Call Method: public abstract java.lang.String io.github.dunwu.javacore.reflect.InvocationHandlerDemo$Subject.bye()
Goodbye
After method
Result is: Over我们首先来看看 com.sun.proxy.$Proxy0 这东西,我们看到,这个东西是由 System.out.println(subject.getClass().getName()); 这条语句打印出来的,那么为什么我们返回的这个代理对象的类名是这样的呢?
Subject subject = (Subject)Proxy.newProxyInstance(handler.getClass().getClassLoader(), realSubject
.getClass().getInterfaces(), handler);可能我以为返回的这个代理对象会是 Subject 类型的对象,或者是 InvocationHandler 的对象,结果却不是,首先我们解释一下为什么我们这里可以将其转化为 Subject 类型的对象?
原因就是:在 newProxyInstance 这个方法的第二个参数上,我们给这个代理对象提供了一组什么接口,那么我这个代理对象就会实现了这组接口,这个时候我们当然可以将这个代理对象强制类型转化为这组接口中的任意一个,因为这里的接口是 Subject 类型,所以就可以将其转化为 Subject 类型了。
同时我们一定要记住,通过 Proxy.newProxyInstance 创建的代理对象是在 jvm 运行时动态生成的一个对象,它并不是我们的 InvocationHandler 类型,也不是我们定义的那组接口的类型,而是在运行是动态生成的一个对象,并且命名方式都是这样的形式,以 $ 开头,proxy 为中,最后一个数字表示对象的标号。
接着我们来看看这两句
subject.hello("World");
String result = subject.bye();这里是通过代理对象来调用实现的那种接口中的方法,这个时候程序就会跳转到由这个代理对象关联到的 handler 中的 invoke 方法去执行,而我们的这个 handler 对象又接受了一个 RealSubject 类型的参数,表示我要代理的就是这个真实对象,所以此时就会调用 handler 中的 invoke 方法去执行。
我们看到,在真正通过代理对象来调用真实对象的方法的时候,我们可以在该方法前后添加自己的一些操作,同时我们看到我们的这个 method 对象是这样的:
public abstract void io.github.dunwu.javacore.reflect.InvocationHandlerDemo$Subject.hello(java.lang.String)
public abstract java.lang.String io.github.dunwu.javacore.reflect.InvocationHandlerDemo$Subject.bye()正好就是我们的 Subject 接口中的两个方法,这也就证明了当我通过代理对象来调用方法的时候,起实际就是委托由其关联到的 handler 对象的 invoke 方法中来调用,并不是自己来真实调用,而是通过代理的方式来调用的。
# #JDK 动态代理小结
代理类与委托类实现同一接口,主要是通过代理类实现 InvocationHandler 并重写 invoke 方法来进行动态代理的,在 invoke 方法中将对方法进行处理。
JDK 动态代理特点:
- 优点:相对于静态代理模式,不需要硬编码接口,代码复用率高。
- 缺点:强制要求代理类实现
InvocationHandler接口。
# #4.3. CGLIB 动态代理
CGLIB 提供了与 JDK 动态代理不同的方案。很多框架,例如 Spring AOP 中,就使用了 CGLIB 动态代理。
CGLIB 底层,其实是借助了 ASM 这个强大的 Java 字节码框架去进行字节码增强操作。
CGLIB 动态代理的工作步骤:
- 生成代理类的二进制字节码文件;
- 加载二进制字节码,生成
Class对象 ( 例如使用Class.forName()方法 ); - 通过反射机制获得实例构造,并创建代理类对象。
CGLIB 动态代理特点:
优点:使用字节码增强,比 JDK 动态代理方式性能高。可以在运行时对类或者是接口进行增强操作,且委托类无需实现接口。
缺点:不能对 final 类以及 final 方法进行代理。
# 深入理解 Java 注解
本文内容基于 JDK8。注解是 JDK5 引入的,后续 JDK 版本扩展了一些内容,本文中没有明确指明版本的注解都是 JDK5 就已经支持的注解。
📦 本文以及示例源码已归档在 javacore(opens new window)
# #1. 简介
# #1.1. 注解的形式
Java 中,注解是以 @ 字符开始的修饰符。如下:
@Override
void mySuperMethod() { ... }注解可以包含命名或未命名的属性,并且这些属性有值。
@Author(
name = "Benjamin Franklin",
date = "3/27/2003"
)
class MyClass() { ... }如果只有一个名为 value 的属性,那么名称可以省略,如:
@SuppressWarnings("unchecked")
void myMethod() { ... }如果注解没有属性,则称为 标记注解 。如: @Override 。
# #1.2. 什么是注解
从本质上来说,注解是一种标签,其实质上可以视为一种特殊的注释,如果没有解析它的代码,它并不比普通注释强。
解析一个注解往往有两种形式:
- 编译期直接的扫描 - 编译器的扫描指的是编译器在对 java 代码编译字节码的过程中会检测到某个类或者方法被一些注解修饰,这时它就会对于这些注解进行某些处理。这种情况只适用于 JDK 内置的注解类。
- 运行期的反射 - 如果要自定义注解,Java 编译器无法识别并处理这个注解,它只能根据该注解的作用范围来选择是否编译进字节码文件。如果要处理注解,必须利用反射技术,识别该注解以及它所携带的信息,然后做相应的处理。
# #1.3. 注解的作用
注解有许多用途:
- 编译器信息 - 编译器可以使用注解来检测错误或抑制警告。
- 编译时和部署时的处理 - 程序可以处理注解信息以生成代码,XML 文件等。
- 运行时处理 - 可以在运行时检查某些注解并处理。
作为 Java 程序员,多多少少都曾经历过被各种配置文件(xml、properties)支配的恐惧。过多的配置文件会使得项目难以维护。个人认为,使用注解以减少配置文件或代码,是注解最大的用处。
# #1.4. 注解的代价
凡事有得必有失,注解技术同样如此。使用注解也有一定的代价:
- 显然,它是一种侵入式编程,那么,自然就存在着增加程序耦合度的问题。
- 自定义注解的处理需要在运行时,通过反射技术来获取属性。如果注解所修饰的元素是类的非 public 成员,也可以通过反射获取。这就违背了面向对象的封装性。
- 注解所产生的问题,相对而言,更难以 debug 或定位。
但是,正所谓瑕不掩瑜,注解所付出的代价,相较于它提供的功能而言,还是可以接受的。
# #1.5. 注解的应用范围
注解可以应用于类、字段、方法和其他程序元素的声明。
JDK8 开始,注解的应用范围进一步扩大,以下是新的应用范围:
类实例初始化表达式:
new @Interned MyObject();类型转换:
myString = (@NonNull String) str;实现接口的声明:
class UnmodifiableList<T> implements
@Readonly List<@Readonly T> {}抛出异常声明:
void monitorTemperature()
throws @Critical TemperatureException {}# #2. 内置注解
JDK 中内置了以下注解:
@Override@Deprecated@SuppressWarnnings@SafeVarargs(JDK7 引入)@FunctionalInterface(JDK8 引入)
# #2.1. @Override
@Override (opens new window) 用于表明被修饰方法覆写了父类的方法。
如果试图使用 @Override 标记一个实际上并没有覆写父类的方法时,java 编译器会告警。
@Override 示例:
public class OverrideAnnotationDemo {
static class Person {
public String getName() {
return "getName";
}
}
static class Man extends Person {
@Override
public String getName() {
return "override getName";
}
/**
* 放开下面的注释,编译时会告警
*/
/*
@Override
public String getName2() {
return "override getName2";
}
*/
}
public static void main(String[] args) {
Person per = new Man();
System.out.println(per.getName());
}
}# #2.2. @Deprecated
@Deprecated 用于标明被修饰的类或类成员、类方法已经废弃、过时,不建议使用。
@Deprecated 有一定的延续性:如果我们在代码中通过继承或者覆盖的方式使用了过时的类或类成员,即使子类或子方法没有标记为 @Deprecated ,但编译器仍然会告警。
🔔 注意:
@Deprecated这个注解类型和 javadoc 中的@deprecated这个 tag 是有区别的:前者是 java 编译器识别的;而后者是被 javadoc 工具所识别用来生成文档(包含程序成员为什么已经过时、它应当如何被禁止或者替代的描述)。
@Deprecated 示例:
public class DeprecatedAnnotationDemo {
static class DeprecatedField {
@Deprecated
public static final String DEPRECATED_FIELD = "DeprecatedField";
}
static class DeprecatedMethod {
@Deprecated
public String print() {
return "DeprecatedMethod";
}
}
@Deprecated
static class DeprecatedClass {
public String print() {
return "DeprecatedClass";
}
}
public static void main(String[] args) {
System.out.println(DeprecatedField.DEPRECATED_FIELD);
DeprecatedMethod dm = new DeprecatedMethod();
System.out.println(dm.print());
DeprecatedClass dc = new DeprecatedClass();
System.out.println(dc.print());
}
}
//Output:
//DeprecatedField
//DeprecatedMethod
//DeprecatedClass# #2.3. @SuppressWarnnings
@SuppressWarnings (opens new window) 用于关闭对类、方法、成员编译时产生的特定警告。
@SuppressWarning 不是一个标记注解。它有一个类型为 String[] 的数组成员,这个数组中存储的是要关闭的告警类型。对于 javac 编译器来讲,对 -Xlint 选项有效的警告名也同样对 @SuppressWarings 有效,同时编译器会忽略掉无法识别的警告名。
@SuppressWarning 示例:
@SuppressWarnings({"rawtypes", "unchecked"})
public class SuppressWarningsAnnotationDemo {
static class SuppressDemo<T> {
private T value;
public T getValue() {
return this.value;
}
public void setValue(T var) {
this.value = var;
}
}
@SuppressWarnings({"deprecation"})
public static void main(String[] args) {
SuppressDemo d = new SuppressDemo();
d.setValue("南京");
System.out.println("地名:" + d.getValue());
}
}@SuppressWarnings 注解的常见参数值的简单说明:
deprecation- 使用了不赞成使用的类或方法时的警告;unchecked- 执行了未检查的转换时的警告,例如当使用集合时没有用泛型 (Generics) 来指定集合保存的类型;fallthrough- 当 Switch 程序块直接通往下一种情况而没有 Break 时的警告;path- 在类路径、源文件路径等中有不存在的路径时的警告;serial- 当在可序列化的类上缺少 serialVersionUID 定义时的警告;finally- 任何 finally 子句不能正常完成时的警告;all- 所有的警告。
@SuppressWarnings({"uncheck", "deprecation"})
public class InternalAnnotationDemo {
/**
* @SuppressWarnings 标记消除当前类的告警信息
*/
@SuppressWarnings({"deprecation"})
static class A {
public void method1() {
System.out.println("call method1");
}
/**
* @Deprecated 标记当前方法为废弃方法,不建议使用
*/
@Deprecated
public void method2() {
System.out.println("call method2");
}
}
/**
* @Deprecated 标记当前类为废弃类,不建议使用
*/
@Deprecated
static class B extends A {
/**
* @Override 标记显示指明当前方法覆写了父类或接口的方法
*/
@Override
public void method1() { }
}
public static void main(String[] args) {
A obj = new B();
obj.method1();
obj.method2();
}
}# #2.4. @SafeVarargs
@SafeVarargs 在 JDK7 中引入。
@SafeVarargs (opens new window) 的作用是:告诉编译器,在可变长参数中的泛型是类型安全的。可变长参数是使用数组存储的,而数组和泛型不能很好的混合使用。
简单的说,数组元素的数据类型在编译和运行时都是确定的,而泛型的数据类型只有在运行时才能确定下来。因此,当把一个泛型存储到数组中时,编译器在编译阶段无法确认数据类型是否匹配,因此会给出警告信息;即如果泛型的真实数据类型无法和参数数组的类型匹配,会导致 ClassCastException 异常。
@SafeVarargs 注解使用范围:
@SafeVarargs注解可以用于构造方法。@SafeVarargs注解可以用于static或final方法。
@SafeVarargs 示例:
public class SafeVarargsAnnotationDemo {
/**
* 此方法实际上并不安全,不使用此注解,编译时会告警
*/
@SafeVarargs
static void wrongMethod(List<String>... stringLists) {
Object[] array = stringLists;
List<Integer> tmpList = Arrays.asList(42);
array[0] = tmpList; // 语法错误,但是编译不告警
String s = stringLists[0].get(0); // 运行时报 ClassCastException
}
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("A");
list.add("B");
List<String> list2 = new ArrayList<>();
list.add("1");
list.add("2");
wrongMethod(list, list2);
}
}以上代码,如果不使用 @SafeVarargs ,编译时会告警
[WARNING] /D:/Codes/ZP/Java/javacore/codes/basics/src/main/java/io/github/dunwu/javacore/annotation/SafeVarargsAnnotationDemo.java: 某些输入文件使用了未经检查或不安全的操作。
[WARNING] /D:/Codes/ZP/Java/javacore/codes/basics/src/main/java/io/github/dunwu/javacore/annotation/SafeVarargsAnnotationDemo.java: 有关详细信息, 请使用 -Xlint:unchecked 重新编译。# #2.5. @FunctionalInterface
@FunctionalInterface 在 JDK8 引入。
@FunctionalInterface (opens new window) 用于指示被修饰的接口是函数式接口。
需要注意的是,如果一个接口符合 "函数式接口" 定义,不加 @FunctionalInterface 也没关系;但如果编写的不是函数式接口,却使用 @FunctionInterface ,那么编译器会报错。
什么是函数式接口?
函数式接口 (Functional Interface) 就是一个有且仅有一个抽象方法,但是可以有多个非抽象方法的接口。函数式接口可以被隐式转换为 lambda 表达式。
函数式接口的特点:
- 接口有且只能有个一个抽象方法(抽象方法只有方法定义,没有方法体)。
- 不能在接口中覆写 Object 类中的 public 方法(写了编译器也会报错)。
- 允许有 default 实现方法。
示例:
public class FunctionalInterfaceAnnotationDemo {
@FunctionalInterface
public interface Func1<T> {
void printMessage(T message);
}
/**
* @FunctionalInterface 修饰的接口中定义两个抽象方法,编译时会报错
* @param <T>
*/
/*@FunctionalInterface
public interface Func2<T> {
void printMessage(T message);
void printMessage2(T message);
}*/
public static void main(String[] args) {
Func1 func1 = message -> System.out.println(message);
func1.printMessage("Hello");
func1.printMessage(100);
}
}# #3. 元注解
JDK 中虽然内置了几个注解,但这远远不能满足开发过程中遇到的千变万化的需求。所以我们需要自定义注解,而这就需要用到元注解。
元注解的作用就是用于定义其它的注解。
Java 中提供了以下元注解类型:
@Retention@Target@Documented@Inherited(JDK8 引入)@Repeatable(JDK8 引入)
这些类型和它们所支持的类在 java.lang.annotation 包中可以找到。下面我们看一下每个元注解的作用和相应分参数的使用说明。
# #3.1. @Retention
@Retention (opens new window) 指明了注解的保留级别。
@Retention 源码:
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.ANNOTATION_TYPE)
public @interface Retention {
RetentionPolicy value();
}RetentionPolicy 是一个枚举类型,它定义了被 @Retention 修饰的注解所支持的保留级别:
RetentionPolicy.SOURCE- 标记的注解仅在源文件中有效,编译器会忽略。RetentionPolicy.CLASS- 标记的注解在 class 文件中有效,JVM 会忽略。RetentionPolicy.RUNTIME- 标记的注解在运行时有效。
@Retention 示例:
@Target(ElementType.FIELD)
@Retention(RetentionPolicy.RUNTIME)
public @interface Column {
public String name() default "fieldName";
public String setFuncName() default "setField";
public String getFuncName() default "getField";
public boolean defaultDBValue() default false;
}# #3.2. @Documented
@Documented (opens new window) 表示无论何时使用指定的注解,都应使用 Javadoc(默认情况下,注释不包含在 Javadoc 中)。更多内容可以参考:Javadoc tools page (opens new window)。
@Documented 示例:
@Target(ElementType.FIELD)
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface Column {
public String name() default "fieldName";
public String setFuncName() default "setField";
public String getFuncName() default "getField";
public boolean defaultDBValue() default false;
}# #3.3. @Target
@Target (opens new window) 指定注解可以修饰的元素类型。
@Target 源码:
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.ANNOTATION_TYPE)
public @interface Target {
ElementType[] value();
}ElementType 是一个枚举类型,它定义了被 @Target 修饰的注解可以应用的范围:
ElementType.ANNOTATION_TYPE- 标记的注解可以应用于注解类型。ElementType.CONSTRUCTOR- 标记的注解可以应用于构造函数。ElementType.FIELD- 标记的注解可以应用于字段或属性。ElementType.LOCAL_VARIABLE- 标记的注解可以应用于局部变量。ElementType.METHOD- 标记的注解可以应用于方法。ElementType.PACKAGE- 标记的注解可以应用于包声明。ElementType.PARAMETER- 标记的注解可以应用于方法的参数。ElementType.TYPE- 标记的注解可以应用于类的任何元素。
@Target 示例:
@Target(ElementType.TYPE)
public @interface Table {
/**
* 数据表名称注解,默认值为类名称
* @return
*/
public String tableName() default "className";
}
@Target(ElementType.FIELD)
public @interface NoDBColumn {}# #3.4. @Inherited
@Inherited (opens new window) 表示注解类型可以被继承(默认情况下不是这样)。
表示自动继承注解类型。 如果注解类型声明中存在 @Inherited 元注解,则注解所修饰类的所有子类都将会继承此注解。
🔔 注意:
@Inherited注解类型是被标注过的类的子类所继承。类并不从它所实现的接口继承注解,方法并不从它所覆写的方法继承注解。此外,当
@Inherited类型标注的注解的@Retention是RetentionPolicy.RUNTIME,则反射 API 增强了这种继承性。如果我们使用java.lang.reflect去查询一个@Inherited类型的注解时,反射代码检查将展开工作:检查类和其父类,直到发现指定的注解类型被发现,或者到达类继承结构的顶层。
@Inherited
public @interface Greeting {
public enum FontColor{ BULE,RED,GREEN};
String name();
FontColor fontColor() default FontColor.GREEN;
}# #3.5. @Repeatable
@Repeatable (opens new window) 表示注解可以重复使用。
以 Spring @Scheduled 为例:
@Target({ElementType.METHOD, ElementType.ANNOTATION_TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface Schedules {
Scheduled[] value();
}
@Target({ElementType.METHOD, ElementType.ANNOTATION_TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Repeatable(Schedules.class)
public @interface Scheduled {
// ...
}应用示例:
public class TaskRunner {
@Scheduled("0 0/15 * * * ?")
@Scheduled("0 0 12 * ?")
public void task1() {}
}# #4. 自定义注解
使用 @interface 自定义注解时,自动继承了 java.lang.annotation.Annotation 接口,由编译程序自动完成其他细节。在定义注解时,不能继承其他的注解或接口。 @interface 用来声明一个注解,其中的每一个方法实际上是声明了一个配置参数。方法的名称就是参数的名称,返回值类型就是参数的类型(返回值类型只能是基本类型、Class、String、enum)。可以通过 default 来声明参数的默认值。
这里,我会通过实现一个名为 RegexValid 的正则校验注解工具来展示自定义注解的全步骤。
# #4.1. 注解的定义
注解的语法格式如下:
public @interface 注解名 {定义体}我们来定义一个注解:
@Documented
@Target({ElementType.FIELD, ElementType.PARAMETER})
@Retention(RetentionPolicy.RUNTIME)
public @interface RegexValid {}说明:
通过上一节对于元注解
@Target、@Retention、@Documented的说明,这里就很容易理解了。
- 上面的代码中定义了一个名为
@RegexValid的注解。@Documented表示@RegexValid应该使用 javadoc。@Target({ElementType.FIELD, ElementType.PARAMETER})表示@RegexValid可以在类成员或方法参数上修饰。- @Retention (RetentionPolicy.RUNTIME) 表示
@RegexValid在运行时有效。
此时,我们已经定义了一个没有任何属性的注解,如果到此为止,它仅仅是一个标记注解。作为正则工具,没有属性可什么也做不了。接下来,我们将为它添加注解属性。
# #4.2. 注解属性
注解属性的语法形式如下:
[访问级别修饰符] [数据类型] 名称() default 默认值;例如,我们要定义在注解中定义一个名为 value 的字符串属性,其默认值为空字符串,访问级别为默认级别,那么应该定义如下:
String value() default "";🔔 注意:在注解中,我们定义属性时,属性名后面需要加
()。
定义注解属性有以下要点:
- 注解属性只能使用
public或默认访问级别(即不指定访问级别修饰符)修饰。 - 注解属性的数据类型有限制要求。支持的数据类型如下:
- 所有基本数据类型(byte、char、short、int、long、float、double、boolean)
- String 类型
- Class 类
- enum 类型
- Annotation 类型
- 以上所有类型的数组
- 注解属性必须有确定的值,建议指定默认值。注解属性只能通过指定默认值或使用注解时指定属性值,相较之下,指定默认值的方式更为可靠。注解属性如果是引用类型,不可以为 null。这个约束使得注解处理器很难判断注解属性是默认值,或是使用注解时所指定的属性值。为此,我们设置默认值时,一般会定义一些特殊的值,例如空字符串或者负数。
- 如果注解中只有一个属性值,最好将其命名为 value。因为,指定属性名为 value,在使用注解时,指定 value 的值可以不指定属性名称。
// 这两种方式效果相同
@RegexValid("^((\\+)?86\\s*)?((13[0-9])|(15([0-3]|[5-9]))|(18[0,2,5-9]))\\d{8}$")
@RegexValid(value = "^((\\+)?86\\s*)?((13[0-9])|(15([0-3]|[5-9]))|(18[0,2,5-9]))\\d{8}$")示例:
了解了注解属性的定义要点,让我们来为 @RegexValid 注解定义几个属性。
@Documented
@Target({ElementType.FIELD, ElementType.PARAMETER})
@Retention(RetentionPolicy.RUNTIME)
public @interface RegexValid {
enum Policy {
// @formatter:off
EMPTY(null),
DATE("^(?:(?!0000)[0-9]{4}([-/.]?)(?:(?:0?[1-9]|1[0-2])\\1(?:0?[1-9]|1[0-9]|2[0-8])|(?:0?[13-9]|1[0-2])\\1"
+ "(?:29|30)|(?:0?[13578]|1[02])\\1(?:31))|(?:[0-9]{2}(?:0[48]|[2468][048]|[13579][26])|"
+ "(?:0[48]|[2468][048]|[13579][26])00)([-/.]?)0?2\\2(?:29))$"),
MAIL("^[A-Za-z0-9](([_\\.\\-]?[a-zA-Z0-9]+)*)@([A-Za-z0-9]+)(([\\.\\-]?[a-zA-Z0-9]+)*)\\.([A-Za-z]{2,})$");
// @formatter:on
private String policy;
Policy(String policy) {
this.policy = policy;
}
public String getPolicy() {
return policy;
}
}
String value() default "";
Policy policy() default Policy.EMPTY;
}说明:
在上面的示例代码中,我们定义了两个注解属性:
String类型的 value 属性和Policy枚举类型的 policy 属性。Policy枚举中定义了几个默认的正则表达式,这是为了直接使用这几个常用表达式去正则校验。考虑到,我们可能需要自己传入一些自定义正则表达式去校验其他场景,所以定义了 value 属性,允许使用者传入正则表达式。
至此, @RegexValid 的声明已经结束。但是,程序仍不知道如何处理 @RegexValid 这个注解。我们还需要定义注解处理器。
# #4.3. 注解处理器
如果没有用来读取注解的方法和工作,那么注解也就不会比注释更有用处了。使用注解的过程中,很重要的一部分就是创建于使用注解处理器。JDK5 扩展了反射机制的 API,以帮助程序员快速的构造自定义注解处理器。
java.lang.annotation.Annotation 是一个接口,程序可以通过反射来获取指定程序元素的注解对象,然后通过注解对象来获取注解里面的元数据。
Annotation 接口源码如下:
public interface Annotation {
boolean equals(Object obj);
int hashCode();
String toString();
Class<? extends Annotation> annotationType();
}除此之外,Java 中支持注解处理器接口 java.lang.reflect.AnnotatedElement ,该接口代表程序中可以接受注解的程序元素,该接口主要有如下几个实现类:
Class- 类定义Constructor- 构造器定义Field- 累的成员变量定义Method- 类的方法定义Package- 类的包定义
java.lang.reflect 包下主要包含一些实现反射功能的工具类。实际上, java.lang.reflect 包所有提供的反射 API 扩充了读取运行时注解信息的能力。当一个注解类型被定义为运行时的注解后,该注解才能是运行时可见,当 class 文件被装载时被保存在 class 文件中的注解才会被虚拟机读取。 AnnotatedElement 接口是所有程序元素(Class、Method 和 Constructor)的父接口,所以程序通过反射获取了某个类的 AnnotatedElement 对象之后,程序就可以调用该对象的如下四个个方法来访问注解信息:
getAnnotation- 返回该程序元素上存在的、指定类型的注解,如果该类型注解不存在,则返回 null。getAnnotations- 返回该程序元素上存在的所有注解。isAnnotationPresent- 判断该程序元素上是否包含指定类型的注解,存在则返回 true,否则返回 false。getDeclaredAnnotations- 返回直接存在于此元素上的所有注释。与此接口中的其他方法不同,该方法将忽略继承的注释。(如果没有注释直接存在于此元素上,则返回长度为零的一个数组。)该方法的调用者可以随意修改返回的数组;这不会对其他调用者返回的数组产生任何影响。
了解了以上内容,让我们来实现 @RegexValid 的注解处理器:
import java.lang.reflect.Field;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegexValidUtil {
public static boolean check(Object obj) throws Exception {
boolean result = true;
StringBuilder sb = new StringBuilder();
Field[] fields = obj.getClass().getDeclaredFields();
for (Field field : fields) {
// 判断成员是否被 @RegexValid 注解所修饰
if (field.isAnnotationPresent(RegexValid.class)) {
RegexValid valid = field.getAnnotation(RegexValid.class);
// 如果 value 为空字符串,说明没有注入自定义正则表达式,改用 policy 属性
String value = valid.value();
if ("".equals(value)) {
RegexValid.Policy policy = valid.policy();
value = policy.getPolicy();
}
// 通过设置 setAccessible(true) 来访问私有成员
field.setAccessible(true);
Object fieldObj = null;
try {
fieldObj = field.get(obj);
} catch (IllegalAccessException e) {
e.printStackTrace();
}
if (fieldObj == null) {
sb.append("\n")
.append(String.format("%s 类中的 %s 字段不能为空!", obj.getClass().getName(), field.getName()));
result = false;
} else {
if (fieldObj instanceof String) {
String text = (String) fieldObj;
Pattern p = Pattern.compile(value);
Matcher m = p.matcher(text);
result = m.matches();
if (!result) {
sb.append("\n").append(String.format("%s 不是合法的 %s !", text, field.getName()));
}
} else {
sb.append("\n").append(
String.format("%s 类中的 %s 字段不是字符串类型,不能使用此注解校验!", obj.getClass().getName(), field.getName()));
result = false;
}
}
}
}
if (sb.length() > 0) {
throw new Exception(sb.toString());
}
return result;
}
}说明:
以上示例中的注解处理器,执行步骤如下:
- 通过 getDeclaredFields 反射方法获取传入对象的所有成员。
- 遍历成员,使用 isAnnotationPresent 判断成员是否被指定注解所修饰,如果不是,直接跳过。
- 如果成员被注解所修饰,通过
RegexValid valid = field.getAnnotation(RegexValid.class);这样的形式获取,注解实例化对象,然后,就可以使用valid.value()或valid.policy()这样的形式获取注解中设定的属性值。- 根据属性值,进行逻辑处理。
# #4.4. 使用注解
完成了以上工作,我们就可以使用自定义注解了,示例如下:
public class RegexValidDemo {
static class User {
private String name;
@RegexValid(policy = RegexValid.Policy.DATE)
private String date;
@RegexValid(policy = RegexValid.Policy.MAIL)
private String mail;
@RegexValid("^((\\+)?86\\s*)?((13[0-9])|(15([0-3]|[5-9]))|(18[0,2,5-9]))\\d{8}$")
private String phone;
public User(String name, String date, String mail, String phone) {
this.name = name;
this.date = date;
this.mail = mail;
this.phone = phone;
}
@Override
public String toString() {
return "User{" + "name='" + name + '\'' + ", date='" + date + '\'' + ", mail='" + mail + '\'' + ", phone='"
+ phone + '\'' + '}';
}
}
static void printDate(@RegexValid(policy = RegexValid.Policy.DATE) String date){
System.out.println(date);
}
public static void main(String[] args) throws Exception {
User user = new User("Tom", "1990-01-31", "xxx@163.com", "18612341234");
User user2 = new User("Jack", "2019-02-29", "sadhgs", "183xxxxxxxx");
if (RegexValidUtil.check(user)) {
System.out.println(user + "正则校验通过");
}
if (RegexValidUtil.check(user2)) {
System.out.println(user2 + "正则校验通过");
}
}
}# #5. 小结
# Java 正则从入门到精通
📦 本文以及示例源码已归档在 javacore(opens new window)
关键词:Pattern、Matcher、捕获与非捕获、反向引用、零宽断言、贪婪与懒惰、元字符、DFA、NFA
# #1. 正则简介
# #1.1. 正则表达式是什么
正则表达式(Regular Expression)是一个用正则符号写出的公式,程序对这个公式进行语法分析,建立一个语法分析树,再根据这个分析树结合正则表达式的引擎生成执行程序(这个执行程序我们把它称作状态机,也叫状态自动机),用于字符匹配。
# #1.2. 如何学习正则
正则表达式是一个强大的文本匹配工具,但是它的规则很复杂,理解起来较为困难,容易让人望而生畏。
刚接触正则时,我看了一堆正则的语义说明,但是仍然不明所以。后来,我多接触一些正则的应用实例,渐渐有了感觉,再结合语义说明,终有领悟。我觉得正则表达式和武侠修练武功差不多,应该先练招式,再练心法。如果一开始就直接看正则的规则,保证你会懵逼。当你熟悉基本招式(正则基本使用案例)后,也该修炼修炼心法(正则语法)了。真正的高手不能只靠死记硬背那么几招把式。就像张三丰教张无忌太极拳一样,领悟心法,融会贯通,少侠你就可以无招胜有招,成为传说中的绝世高手。
以上闲话可归纳为一句:学习正则应该从实例去理解规则。
# #2. 正则工具类
JDK 中的 java.util.regex 包提供了对正则表达式的支持。
java.util.regex 有三个核心类:
- Pattern 类:
Pattern是一个正则表达式的编译表示。 - Matcher 类:
Matcher是对输入字符串进行解释和匹配操作的引擎。 - PatternSyntaxException:
PatternSyntaxException是一个非强制异常类,它表示一个正则表达式模式中的语法错误。
** 注:** 需要格外注意一点,在 Java 中使用反斜杠 "" 时必须写成 "\\" 。所以本文的代码出现形如 String regex = "\\$\\{.*?\\}" 其实就是 \$\{.\*?\} 。
# #2.1. Pattern 类
Pattern 类没有公共构造方法。要创建一个 Pattern 对象,你必须首先调用其静态方法 compile ,加载正则规则字符串,然后返回一个 Pattern 对象。
与 Pattern 类一样, Matcher 类也没有公共构造方法。你需要调用 Pattern 对象的 matcher 方法来获得一个 Matcher 对象。
【示例】Pattern 和 Matcher 的初始化
Pattern p = Pattern.compile(regex);
Matcher m = p.matcher(content);# #2.2. Matcher 类
Matcher 类可以说是 java.util.regex 中的核心类,它有三类功能:校验、查找、替换。
# #校验
为了校验文本是否与正则规则匹配,Matcher 提供了以下几个返回值为 boolean 的方法。
| 序号 | 方法及说明 |
|---|---|
| 1 | **public boolean lookingAt () ** 尝试将从区域开头开始的输入序列与该模式匹配。 |
| 2 | **public boolean find () ** 尝试查找与该模式匹配的输入序列的下一个子序列。 |
| 3 | **public boolean find (int start)** 重置此匹配器,然后尝试查找匹配该模式、从指定索引开始的输入序列的下一个子序列。 |
| 4 | **public boolean matches () ** 尝试将整个区域与模式匹配。 |
如果你傻傻分不清上面的查找方法有什么区别,那么下面一个例子就可以让你秒懂。
【示例】lookingAt、find、matches
public static void main(String[] args) {
checkLookingAt("hello", "helloworld");
checkLookingAt("world", "helloworld");
checkFind("hello", "helloworld");
checkFind("world", "helloworld");
checkMatches("hello", "helloworld");
checkMatches("world", "helloworld");
checkMatches("helloworld", "helloworld");
}
private static void checkLookingAt(String regex, String content) {
Pattern p = Pattern.compile(regex);
Matcher m = p.matcher(content);
if (m.lookingAt()) {
System.out.println(content + "\tlookingAt: " + regex);
} else {
System.out.println(content + "\tnot lookingAt: " + regex);
}
}
private static void checkFind(String regex, String content) {
Pattern p = Pattern.compile(regex);
Matcher m = p.matcher(content);
if (m.find()) {
System.out.println(content + "\tfind: " + regex);
} else {
System.out.println(content + "\tnot find: " + regex);
}
}
private static void checkMatches(String regex, String content) {
Pattern p = Pattern.compile(regex);
Matcher m = p.matcher(content);
if (m.matches()) {
System.out.println(content + "\tmatches: " + regex);
} else {
System.out.println(content + "\tnot matches: " + regex);
}
}输出:
helloworld lookingAt: hello
helloworld not lookingAt: world
helloworld find: hello
helloworld find: world
helloworld not matches: hello
helloworld not matches: world
helloworld matches: helloworld说明
regex = "world" 表示的正则规则是以 world 开头的字符串, regex = "hello" 和 regex = "helloworld" 也是同理。
lookingAt方法从头部开始,检查 content 字符串是否有子字符串于正则规则匹配。find方法检查 content 字符串是否有子字符串于正则规则匹配,不管字符串所在位置。matches方法检查 content 字符串整体是否与正则规则匹配。
# #查找
为了查找文本匹配正则规则的位置, Matcher 提供了以下方法:
| 序号 | 方法及说明 |
|---|---|
| 1 | **public int start () ** 返回以前匹配的初始索引。 |
| 2 | public int start(int group) 返回在以前的匹配操作期间,由给定组所捕获的子序列的初始索引 |
| 3 | **public int end ()** 返回最后匹配字符之后的偏移量。 |
| 4 | **public int end (int group)** 返回在以前的匹配操作期间,由给定组所捕获子序列的最后字符之后的偏移量。 |
| 5 | **public String group ()** 返回前一个符合匹配条件的子序列。 |
| 6 | **public String group (int group)** 返回指定的符合匹配条件的子序列。 |
【示例】使用 start ()、end ()、group () 查找所有匹配正则条件的子序列
public static void main(String[] args) {
final String regex = "world";
final String content = "helloworld helloworld";
Pattern p = Pattern.compile(regex);
Matcher m = p.matcher(content);
System.out.println("content: " + content);
int i = 0;
while (m.find()) {
i++;
System.out.println("[" + i + "th] found");
System.out.print("start: " + m.start() + ", ");
System.out.print("end: " + m.end() + ", ");
System.out.print("group: " + m.group() + "\n");
}
}输出
content: helloworld helloworld
[1th] found
start: 5, end: 10, group: world
[2th] found
start: 16, end: 21, group: world说明
例子很直白,不言自明了吧。
# #替换
替换方法是替换输入字符串里文本的方法:
| 序号 | 方法及说明 |
|---|---|
| 1 | **public Matcher appendReplacement (StringBuffer sb, String replacement)** 实现非终端添加和替换步骤。 |
| 2 | **public StringBuffer appendTail (StringBuffer sb)** 实现终端添加和替换步骤。 |
| 3 | **public String replaceAll (String replacement) ** 替换模式与给定替换字符串相匹配的输入序列的每个子序列。 |
| 4 | public String replaceFirst(String replacement) 替换模式与给定替换字符串匹配的输入序列的第一个子序列。 |
| 5 | **public static String quoteReplacement (String s)** 返回指定字符串的字面替换字符串。这个方法返回一个字符串,就像传递给 Matcher 类的 appendReplacement 方法一个字面字符串一样工作。 |
【示例】replaceFirst 和 replaceAll
public static void main(String[] args) {
String regex = "can";
String replace = "can not";
String content = "I can because I think I can.";
Pattern p = Pattern.compile(regex);
Matcher m = p.matcher(content);
System.out.println("content: " + content);
System.out.println("replaceFirst: " + m.replaceFirst(replace));
System.out.println("replaceAll: " + m.replaceAll(replace));
}输出
content: I can because I think I can.
replaceFirst: I can not because I think I can.
replaceAll: I can not because I think I can not.说明
replaceFirst:替换第一个匹配正则规则的子序列。
replaceAll:替换所有匹配正则规则的子序列。
【示例】appendReplacement、appendTail 和 replaceAll
public static void main(String[] args) {
String regex = "can";
String replace = "can not";
String content = "I can because I think I can.";
StringBuffer sb = new StringBuffer();
StringBuffer sb2 = new StringBuffer();
System.out.println("content: " + content);
Pattern p = Pattern.compile(regex);
Matcher m = p.matcher(content);
while (m.find()) {
m.appendReplacement(sb, replace);
}
System.out.println("appendReplacement: " + sb);
m.appendTail(sb);
System.out.println("appendTail: " + sb);
}输出
content: I can because I think I can.
appendReplacement: I can not because I think I can not
appendTail: I can not because I think I can not.说明
从输出结果可以看出, appendReplacement 和 appendTail 方法组合起来用,功能和 replaceAll 是一样的。
如果你查看 replaceAll 的源码,会发现其内部就是使用 appendReplacement 和 appendTail 方法组合来实现的。
【示例】quoteReplacement 和 replaceAll,解决特殊字符替换问题
public static void main(String[] args) {
String regex = "\\$\\{.*?\\}";
String replace = "${product}";
String content = "product is ${productName}.";
Pattern p = Pattern.compile(regex);
Matcher m = p.matcher(content);
String replaceAll = m.replaceAll(replace);
System.out.println("content: " + content);
System.out.println("replaceAll: " + replaceAll);
}输出
Exception in thread "main" java.lang.IllegalArgumentException: No group with name {product}
at java.util.regex.Matcher.appendReplacement(Matcher.java:849)
at java.util.regex.Matcher.replaceAll(Matcher.java:955)
at org.zp.notes.javase.regex.RegexDemo.wrongMethod(RegexDemo.java:42)
at org.zp.notes.javase.regex.RegexDemo.main(RegexDemo.java:18)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at com.intellij.rt.execution.application.AppMain.main(AppMain.java:147)说明
String regex = "\\$\\{.*?\\}"; 表示匹配类似 ${name} 这样的字符串。由于 $ 、 { 、 } 都是特殊字符,需要用反义字符 \ 来修饰才能被当做一个字符串字符来处理。
上面的例子是想将 ${productName} 替换为 ${product} ,然而 replaceAll 方法却将传入的字符串中的 $ 当做特殊字符来处理了。结果产生异常。
如何解决这个问题?
JDK1.5 引入了 quoteReplacement 方法。它可以用来转换特殊字符。其实源码非常简单,就是判断字符串中如果有 \ 或 $ ,就为它加一个转义字符 \
我们对上面的代码略作调整:
m.replaceAll(replace) 改为 m.replaceAll(Matcher.quoteReplacement(replace)) ,新代码如下:
public static void main(String[] args) {
String regex = "\\$\\{.*?\\}";
String replace = "${product}";
String content = "product is ${productName}.";
Pattern p = Pattern.compile(regex);
Matcher m = p.matcher(content);
String replaceAll = m.replaceAll(Matcher.quoteReplacement(replace));
System.out.println("content: " + content);
System.out.println("replaceAll: " + replaceAll);
}输出
content: product is ${productName}.
replaceAll: product is ${product}.说明
字符串中如果有 \ 或 $ ,不能被正常解析的问题解决。
# #3. 元字符
元字符 (metacharacters) 就是正则表达式中具有特殊意义的专用字符。
# #3.1. 基本元字符
正则表达式的元字符难以记忆,很大程度上是因为有很多为了简化表达而出现的等价字符。而实际上最基本的元字符,并没有那么多。对于大部分的场景,基本元字符都可以搞定。让我们从一个个实例出发,由浅入深的去体会正则的奥妙。
# #多选( | )
【示例】匹配一个确定的字符串
checkMatches("abc", "abc");如果要匹配一个确定的字符串,非常简单,如例 1 所示。但是,如果你不确定要匹配的字符串,希望有多个选择,怎么办?答案是:使用元字符 | ,它的含义是或。
【示例】匹配多个可选的字符串
// 测试正则表达式字符:|
Assert.assertTrue(checkMatches("yes|no", "yes"));
Assert.assertTrue(checkMatches("yes|no", "no"));
Assert.assertFalse(checkMatches("yes|no", "right"));
// 输出
// yes matches: yes|no
// no matches: yes|no
// right not matches: yes|no# #分组( () )
如果你希望表达式由多个子表达式组成,你可以使用 () 。
【示例】匹配组合字符串
Assert.assertTrue(checkMatches("(play|end)(ing|ed)", "ended"));
Assert.assertTrue(checkMatches("(play|end)(ing|ed)", "ending"));
Assert.assertTrue(checkMatches("(play|end)(ing|ed)", "playing"));
Assert.assertTrue(checkMatches("(play|end)(ing|ed)", "played"));
// 输出
// ended matches: (play|end)(ing|ed)
// ending matches: (play|end)(ing|ed)
// playing matches: (play|end)(ing|ed)
// played matches: (play|end)(ing|ed)# #指定单字符有效范围( [] )
前面展示了如何匹配字符串,但是很多时候你需要精确的匹配一个字符,这时可以使用 [] 。
【示例】字符在指定范围
// 测试正则表达式字符:[]
Assert.assertTrue(checkMatches("[abc]", "b")); // 字符只能是a、b、c
Assert.assertTrue(checkMatches("[a-z]", "m")); // 字符只能是a - z
Assert.assertTrue(checkMatches("[A-Z]", "O")); // 字符只能是A - Z
Assert.assertTrue(checkMatches("[a-zA-Z]", "K")); // 字符只能是a - z和A - Z
Assert.assertTrue(checkMatches("[a-zA-Z]", "k"));
Assert.assertTrue(checkMatches("[0-9]", "5")); // 字符只能是0 - 9
// 输出
// b matches: [abc]
// m matches: [a-z]
// O matches: [A-Z]
// K matches: [a-zA-Z]
// k matches: [a-zA-Z]
// 5 matches: [0-9]# #指定单字符无效范围( [^] )
【示例】字符不能在指定范围
如果需要匹配一个字符的逆操作,即字符不能在指定范围,可以使用 [^] 。
// 测试正则表达式字符:[^]
Assert.assertFalse(checkMatches("[^abc]", "b")); // 字符不能是a、b、c
Assert.assertFalse(checkMatches("[^a-z]", "m")); // 字符不能是a - z
Assert.assertFalse(checkMatches("[^A-Z]", "O")); // 字符不能是A - Z
Assert.assertFalse(checkMatches("[^a-zA-Z]", "K")); // 字符不能是a - z和A - Z
Assert.assertFalse(checkMatches("[^a-zA-Z]", "k"));
Assert.assertFalse(checkMatches("[^0-9]", "5")); // 字符不能是0 - 9
// 输出
// b not matches: [^abc]
// m not matches: [^a-z]
// O not matches: [^A-Z]
// K not matches: [^a-zA-Z]
// k not matches: [^a-zA-Z]
// 5 not matches: [^0-9]# #限制字符数量( {} )
如果想要控制字符出现的次数,可以使用 {} 。
| 字符 | 描述 |
|---|---|
{n} |
n 是一个非负整数。匹配确定的 n 次。 |
{n,} |
n 是一个非负整数。至少匹配 n 次。 |
{n,m} |
m 和 n 均为非负整数,其中 n <= m。最少匹配 n 次且最多匹配 m 次。 |
【示例】限制字符出现次数
// {n}: n 是一个非负整数。匹配确定的 n 次。
checkMatches("ap{1}", "a");
checkMatches("ap{1}", "ap");
checkMatches("ap{1}", "app");
checkMatches("ap{1}", "apppppppppp");
// {n,}: n 是一个非负整数。至少匹配 n 次。
checkMatches("ap{1,}", "a");
checkMatches("ap{1,}", "ap");
checkMatches("ap{1,}", "app");
checkMatches("ap{1,}", "apppppppppp");
// {n,m}: m 和 n 均为非负整数,其中 n <= m。最少匹配 n 次且最多匹配 m 次。
checkMatches("ap{2,5}", "a");
checkMatches("ap{2,5}", "ap");
checkMatches("ap{2,5}", "app");
checkMatches("ap{2,5}", "apppppppppp");
// 输出
// a not matches: ap{1}
// ap matches: ap{1}
// app not matches: ap{1}
// apppppppppp not matches: ap{1}
// a not matches: ap{1,}
// ap matches: ap{1,}
// app matches: ap{1,}
// apppppppppp matches: ap{1,}
// a not matches: ap{2,5}
// ap not matches: ap{2,5}
// app matches: ap{2,5}
// apppppppppp not matches: ap{2,5}# #转义字符( / )
如果想要查找元字符本身,你需要使用转义符,使得正则引擎将其视作一个普通字符,而不是一个元字符去处理。
* 的转义字符:\*
+ 的转义字符:\+
? 的转义字符:\?
^ 的转义字符:\^
$ 的转义字符:\$
. 的转义字符:\.如果是转义符 \ 本身,你需要使用 \\ 。
# #指定表达式字符串的开始( ^ )和结尾( $ )
如果希望匹配的字符串必须以特定字符串开头,可以使用 ^ 。
注意:请特别留意,这里的
^一定要和[^]中的^区分。
【示例】限制字符串头部
Assert.assertTrue(checkMatches("^app[a-z]{0,}", "apple")); // 字符串必须以app开头
Assert.assertFalse(checkMatches("^app[a-z]{0,}", "aplause"));
// 输出
// apple matches: ^app[a-z]{0,}
// aplause not matches: ^app[a-z]{0,}如果希望匹配的字符串必须以特定字符串结尾,可以使用 $ 。
【示例】限制字符串尾部
Assert.assertTrue(checkMatches("[a-z]{0,}ing$", "playing")); // 字符串必须以ing结尾
Assert.assertFalse(checkMatches("[a-z]{0,}ing$", "long"));
// 输出
// playing matches: [a-z]{0,}ing$
// long not matches: [a-z]{0,}ing$# #3.2. 等价字符
等价字符,顾名思义,就是对于基本元字符表达的一种简化(等价字符的功能都可以通过基本元字符来实现)。
在没有掌握基本元字符之前,可以先不用理会,因为很容易把人绕晕。
等价字符的好处在于简化了基本元字符的写法。
# #表示某一类型字符的等价字符
下表中的等价字符都表示某一类型的字符。
| 字符 | 描述 |
|---|---|
. |
匹配除 “\n” 之外的任何单个字符。 |
\d |
匹配一个数字字符。等价于 [0-9]。 |
\D |
匹配一个非数字字符。等价于 [^0-9]。 |
\w |
匹配包括下划线的任何单词字符。类似但不等价于 “[A-Za-z0-9_]”,这里的单词字符指的是 Unicode 字符集。 |
\W |
匹配任何非单词字符。 |
\s |
匹配任何不可见字符,包括空格、制表符、换页符等等。等价于 [\f\n\r\t\v]。 |
\S |
匹配任何可见字符。等价于 [\f\n\r\t\v]。 |
【示例】基本等价字符的用法
// 匹配除“\n”之外的任何单个字符
Assert.assertTrue(checkMatches(".{1,}", "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789_"));
Assert.assertTrue(checkMatches(".{1,}", "~!@#$%^&*()+`-=[]{};:<>,./?|\\"));
Assert.assertFalse(checkMatches(".", "\n"));
Assert.assertFalse(checkMatches("[^\n]", "\n"));
// 匹配一个数字字符。等价于[0-9]
Assert.assertTrue(checkMatches("\\d{1,}", "0123456789"));
// 匹配一个非数字字符。等价于[^0-9]
Assert.assertFalse(checkMatches("\\D{1,}", "0123456789"));
// 匹配包括下划线的任何单词字符。类似但不等价于“[A-Za-z0-9_]”,这里的单词字符指的是Unicode字符集
Assert.assertTrue(checkMatches("\\w{1,}", "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789_"));
Assert.assertFalse(checkMatches("\\w{1,}", "~!@#$%^&*()+`-=[]{};:<>,./?|\\"));
// 匹配任何非单词字符
Assert.assertFalse(checkMatches("\\W{1,}", "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789_"));
Assert.assertTrue(checkMatches("\\W{1,}", "~!@#$%^&*()+`-=[]{};:<>,./?|\\"));
// 匹配任何不可见字符,包括空格、制表符、换页符等等。等价于[ \f\n\r\t\v]
Assert.assertTrue(checkMatches("\\s{1,}", " \f\r\n\t"));
// 匹配任何可见字符。等价于[^ \f\n\r\t\v]
Assert.assertFalse(checkMatches("\\S{1,}", " \f\r\n\t"));
// 输出
// ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789_ matches: .{1,}
// ~!@#$%^&*()+`-=[]{};:<>,./?|\\ matches: .{1,}
// \n not matches: .
// \n not matches: [^\n]
// 0123456789 matches: \\d{1,}
// 0123456789 not matches: \\D{1,}
// ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789_ matches: \\w{1,}
// ~!@#$%^&*()+`-=[]{};:<>,./?|\\ not matches: \\w{1,}
// ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789_ not matches: \\W{1,}
// ~!@#$%^&*()+`-=[]{};:<>,./?|\\ matches: \\W{1,}
// \f\r\n\t matches: \\s{1,}
// \f\r\n\t not matches: \\S{1,}# #限制字符数量的等价字符
在基本元字符章节中,已经介绍了限制字符数量的基本元字符 - {} 。
此外,还有 * 、 + 、 ? 这个三个为了简化写法而出现的等价字符,我们来认识一下。
| 字符 | 描述 |
|---|---|
* |
匹配前面的子表达式零次或多次。等价于 {0,}。 |
+ |
匹配前面的子表达式一次或多次。等价于 {1,}。 |
? |
匹配前面的子表达式零次或一次。等价于 {0,1}。 |
案例 限制字符数量的等价字符
// *: 匹配前面的子表达式零次或多次。* 等价于{0,}。
checkMatches("ap*", "a");
checkMatches("ap*", "ap");
checkMatches("ap*", "app");
checkMatches("ap*", "apppppppppp");
// +: 匹配前面的子表达式一次或多次。+ 等价于 {1,}。
checkMatches("ap+", "a");
checkMatches("ap+", "ap");
checkMatches("ap+", "app");
checkMatches("ap+", "apppppppppp");
// ?: 匹配前面的子表达式零次或一次。? 等价于 {0,1}。
checkMatches("ap?", "a");
checkMatches("ap?", "ap");
checkMatches("ap?", "app");
checkMatches("ap?", "apppppppppp");
// 输出
// a matches: ap*
// ap matches: ap*
// app matches: ap*
// apppppppppp matches: ap*
// a not matches: ap+
// ap matches: ap+
// app matches: ap+
// apppppppppp matches: ap+
// a matches: ap?
// ap matches: ap?
// app not matches: ap?
// apppppppppp not matches: ap?# #元字符优先级顺序
正则表达式从左到右进行计算,并遵循优先级顺序,这与算术表达式非常类似。
下表从最高到最低说明了各种正则表达式运算符的优先级顺序:
| 运算符 | 说明 |
|---|---|
\ |
转义符 |
() 、 (?:) 、 (?=) 、 [] |
括号和中括号 |
* 、 + 、 ? 、 {n} 、 {n,} 、 {n,m} |
限定符 |
^ 、 $ 、 *任何字符 、 任何字符* |
定位点和序列 |
| |
替换 |
字符具有高于替换运算符的优先级,使得 m|food 匹配 m 或 food 。若要匹配 mood 或 food ,请使用括号创建子表达式,从而产生 (m|f)ood 。
# #4. 分组构造
在基本元字符章节,提到了 () 字符可以用来对表达式分组。实际上分组还有更多复杂的用法。
所谓分组构造,是用来描述正则表达式的子表达式,用于捕获字符串中的子字符串。
# #4.1. 捕获与非捕获
下表为分组构造中的捕获和非捕获分类。
| 表达式 | 描述 | 捕获或非捕获 |
|---|---|---|
(exp) |
匹配的子表达式 | 捕获 |
(?<name>exp) |
命名的反向引用 | 捕获 |
(?:exp) |
非捕获组 | 非捕获 |
(?=exp) |
零宽度正预测先行断言 | 非捕获 |
(?!exp) |
零宽度负预测先行断言 | 非捕获 |
(?<=exp) |
零宽度正回顾后发断言 | 非捕获 |
(?<!exp) |
零宽度负回顾后发断言 | 非捕获 |
注:Java 正则引擎不支持平衡组。
# #4.2. 反向引用
# #带编号的反向引用
带编号的反向引用使用以下语法: \number
其中 number 是正则表达式中捕获组的序号位置。 例如,\4 匹配第四个捕获组的内容。 如果正则表达式模式中未定义 number,则将发生分析错误
【示例】匹配重复的单词和紧随每个重复的单词的单词 (不命名子表达式)
// (\w+)\s\1\W(\w+) 匹配重复的单词和紧随每个重复的单词的单词
Assert.assertTrue(findAll("(\\w+)\\s\\1\\W(\\w+)",
"He said that that was the the correct answer.") > 0);
// 输出
// regex = (\w+)\s\1\W(\w+), content: He said that that was the the correct answer.
// [1th] start: 8, end: 21, group: that that was
// [2th] start: 22, end: 37, group: the the correct说明:
(\w+):匹配一个或多个单词字符。\s:与空白字符匹配。\1:匹配第一个组,即 (\w+)。\W:匹配包括空格和标点符号的一个非单词字符。 这样可以防止正则表达式模式匹配从第一个捕获组的单词开头的单词。
# #命名的反向引用
命名后向引用通过使用下面的语法进行定义: \k<name >
【示例】匹配重复的单词和紧随每个重复的单词的单词 (命名子表达式)
// (?<duplicateWord>\w+)\s\k<duplicateWord>\W(?<nextWord>\w+) 匹配重复的单词和紧随每个重复的单词的单词
Assert.assertTrue(findAll("(?<duplicateWord>\\w+)\\s\\k<duplicateWord>\\W(?<nextWord>\\w+)",
"He said that that was the the correct answer.") > 0);
// 输出
// regex = (?<duplicateWord>\w+)\s\k<duplicateWord>\W(?<nextWord>\w+), content: He said that that was the the correct answer.
// [1th] start: 8, end: 21, group: that that was
// [2th] start: 22, end: 37, group: the the correct说明:
(?<duplicateWord>\w+):匹配一个或多个单词字符。 命名此捕获组 duplicateWord。\s: 与空白字符匹配。\k<duplicateWord>:匹配名为 duplicateWord 的捕获的组。\W:匹配包括空格和标点符号的一个非单词字符。 这样可以防止正则表达式模式匹配从第一个捕获组的单词开头的单词。(?<nextWord>\w+):匹配一个或多个单词字符。 命名此捕获组 nextWord。
# #4.3. 非捕获组
(?:exp) 表示当一个限定符应用到一个组,但组捕获的子字符串并非所需时,通常会使用非捕获组构造。
【示例】匹配以。结束的语句。
// 匹配由句号终止的语句。
Assert.assertTrue(findAll("(?:\\b(?:\\w+)\\W*)+\\.", "This is a short sentence. Never end") > 0);
// 输出
// regex = (?:\b(?:\w+)\W*)+\., content: This is a short sentence. Never end
// [1th] start: 0, end: 25, group: This is a short sentence.# #4.4. 零宽断言
用于查找在某些内容 (但并不包括这些内容) 之前或之后的东西,也就是说它们像 \b,^,$ 那样用于指定一个位置,这个位置应该满足一定的条件 (即断言),因此它们也被称为零宽断言。
| 表达式 | 描述 |
|---|---|
(?=exp) |
匹配 exp 前面的位置 |
(?<=exp) |
匹配 exp 后面的位置 |
(?!exp) |
匹配后面跟的不是 exp 的位置 |
(?<!exp) |
匹配前面不是 exp 的位置 |
# #匹配 exp 前面的位置
(?=exp) 表示输入字符串必须匹配子表达式中的正则表达式模式,尽管匹配的子字符串未包含在匹配结果中。
// \b\w+(?=\sis\b) 表示要捕获is之前的单词
Assert.assertTrue(findAll("\\b\\w+(?=\\sis\\b)", "The dog is a Malamute.") > 0);
Assert.assertFalse(findAll("\\b\\w+(?=\\sis\\b)", "The island has beautiful birds.") > 0);
Assert.assertFalse(findAll("\\b\\w+(?=\\sis\\b)", "The pitch missed home plate.") > 0);
Assert.assertTrue(findAll("\\b\\w+(?=\\sis\\b)", "Sunday is a weekend day.") > 0);
// 输出
// regex = \b\w+(?=\sis\b), content: The dog is a Malamute.
// [1th] start: 4, end: 7, group: dog
// regex = \b\w+(?=\sis\b), content: The island has beautiful birds.
// not found
// regex = \b\w+(?=\sis\b), content: The pitch missed home plate.
// not found
// regex = \b\w+(?=\sis\b), content: Sunday is a weekend day.
// [1th] start: 0, end: 6, group: Sunday说明:
\b:在单词边界处开始匹配。\w+:匹配一个或多个单词字符。(?=\sis\b):确定单词字符是否后接空白字符和字符串 “is”,其在单词边界处结束。 如果如此,则匹配成功。
# #匹配 exp 后面的位置
(?<=exp) 表示子表达式不得在输入字符串当前位置左侧出现,尽管子表达式未包含在匹配结果中。零宽度正回顾后发断言不会回溯。
// (?<=\b20)\d{2}\b 表示要捕获以20开头的数字的后面部分
Assert.assertTrue(findAll("(?<=\\b20)\\d{2}\\b", "2010 1999 1861 2140 2009") > 0);
// 输出
// regex = (?<=\b20)\d{2}\b, content: 2010 1999 1861 2140 2009
// [1th] start: 2, end: 4, group: 10
// [2th] start: 22, end: 24, group: 09说明:
\d{2}:匹配两个十进制数字。{?<=\b20):如果两个十进制数字的字边界以小数位数 “20” 开头,则继续匹配。\b:在单词边界处结束匹配。
# #匹配后面跟的不是 exp 的位置
(?!exp) 表示输入字符串不得匹配子表达式中的正则表达式模式,尽管匹配的子字符串未包含在匹配结果中。
【示例】捕获未以 “un” 开头的单词
// \b(?!un)\w+\b 表示要捕获未以“un”开头的单词
Assert.assertTrue(findAll("\\b(?!un)\\w+\\b", "unite one unethical ethics use untie ultimate") > 0);
// 输出
// regex = \b(?!un)\w+\b, content: unite one unethical ethics use untie ultimate
// [1th] start: 6, end: 9, group: one
// [2th] start: 20, end: 26, group: ethics
// [3th] start: 27, end: 30, group: use
// [4th] start: 37, end: 45, group: ultimate说明:
\b:在单词边界处开始匹配。(?!un):确定接下来的两个的字符是否为 “un”。 如果没有,则可能匹配。\w+:匹配一个或多个单词字符。\b:在单词边界处结束匹配。
# #匹配前面不是 exp 的位置
(?<!exp) 表示子表达式不得在输入字符串当前位置的左侧出现。 但是,任何不匹配子表达式 的子字符串不包含在匹配结果中。
【示例】捕获任意工作日
// (?<!(Saturday|Sunday) )\b\w+ \d{1,2}, \d{4}\b 表示要捕获任意工作日(即周一到周五)
Assert.assertTrue(findAll("(?<!(Saturday|Sunday) )\\b\\w+ \\d{1,2}, \\d{4}\\b", "Monday February 1, 2010") > 0);
Assert.assertTrue(findAll("(?<!(Saturday|Sunday) )\\b\\w+ \\d{1,2}, \\d{4}\\b", "Wednesday February 3, 2010") > 0);
Assert.assertFalse(findAll("(?<!(Saturday|Sunday) )\\b\\w+ \\d{1,2}, \\d{4}\\b", "Saturday February 6, 2010") > 0);
Assert.assertFalse(findAll("(?<!(Saturday|Sunday) )\\b\\w+ \\d{1,2}, \\d{4}\\b", "Sunday February 7, 2010") > 0);
Assert.assertTrue(findAll("(?<!(Saturday|Sunday) )\\b\\w+ \\d{1,2}, \\d{4}\\b", "Monday, February 8, 2010") > 0);
// 输出
// regex = (?<!(Saturday|Sunday) )\b\w+ \d{1,2}, \d{4}\b, content: Monday February 1, 2010
// [1th] start: 7, end: 23, group: February 1, 2010
// regex = (?<!(Saturday|Sunday) )\b\w+ \d{1,2}, \d{4}\b, content: Wednesday February 3, 2010
// [1th] start: 10, end: 26, group: February 3, 2010
// regex = (?<!(Saturday|Sunday) )\b\w+ \d{1,2}, \d{4}\b, content: Saturday February 6, 2010
// not found
// regex = (?<!(Saturday|Sunday) )\b\w+ \d{1,2}, \d{4}\b, content: Sunday February 7, 2010
// not found
// regex = (?<!(Saturday|Sunday) )\b\w+ \d{1,2}, \d{4}\b, content: Monday, February 8, 2010
// [1th] start: 8, end: 24, group: February 8, 2010# #5. 贪婪与懒惰
当正则表达式中包含能接受重复的限定符时,通常的行为是(在使整个表达式能得到匹配的前提下)匹配尽可能多的字符。以这个表达式为例:a.*b,它将会匹配最长的以 a 开始,以 b 结束的字符串。如果用它来搜索 aabab 的话,它会匹配整个字符串 aabab。这被称为贪婪匹配。
有时,我们更需要懒惰匹配,也就是匹配尽可能少的字符。前面给出的限定符都可以被转化为懒惰匹配模式,只要在它后面加上一个问号?。这样.*? 就意味着匹配任意数量的重复,但是在能使整个匹配成功的前提下使用最少的重复。
| 表达式 | 描述 |
|---|---|
*? |
重复任意次,但尽可能少重复 |
+? |
重复 1 次或更多次,但尽可能少重复 |
?? |
重复 0 次或 1 次,但尽可能少重复 |
{n,m}? |
重复 n 到 m 次,但尽可能少重复 |
{n,}? |
重复 n 次以上,但尽可能少重复 |
【示例】Java 正则中贪婪与懒惰的示例
// 贪婪匹配
Assert.assertTrue(findAll("a\\w*b", "abaabaaabaaaab") > 0);
// 懒惰匹配
Assert.assertTrue(findAll("a\\w*?b", "abaabaaabaaaab") > 0);
Assert.assertTrue(findAll("a\\w+?b", "abaabaaabaaaab") > 0);
Assert.assertTrue(findAll("a\\w??b", "abaabaaabaaaab") > 0);
Assert.assertTrue(findAll("a\\w{0,4}?b", "abaabaaabaaaab") > 0);
Assert.assertTrue(findAll("a\\w{3,}?b", "abaabaaabaaaab") > 0);
// 输出
// regex = a\w*b, content: abaabaaabaaaab
// [1th] start: 0, end: 14, group: abaabaaabaaaab
// regex = a\w*?b, content: abaabaaabaaaab
// [1th] start: 0, end: 2, group: ab
// [2th] start: 2, end: 5, group: aab
// [3th] start: 5, end: 9, group: aaab
// [4th] start: 9, end: 14, group: aaaab
// regex = a\w+?b, content: abaabaaabaaaab
// [1th] start: 0, end: 5, group: abaab
// [2th] start: 5, end: 9, group: aaab
// [3th] start: 9, end: 14, group: aaaab
// regex = a\w??b, content: abaabaaabaaaab
// [1th] start: 0, end: 2, group: ab
// [2th] start: 2, end: 5, group: aab
// [3th] start: 6, end: 9, group: aab
// [4th] start: 11, end: 14, group: aab
// regex = a\w{0,4}?b, content: abaabaaabaaaab
// [1th] start: 0, end: 2, group: ab
// [2th] start: 2, end: 5, group: aab
// [3th] start: 5, end: 9, group: aaab
// [4th] start: 9, end: 14, group: aaaab
// regex = a\w{3,}?b, content: abaabaaabaaaab
// [1th] start: 0, end: 5, group: abaab
// [2th] start: 5, end: 14, group: aaabaaaab说明:
本例中代码展示的是使用不同贪婪或懒惰策略去查找字符串 abaabaaabaaaab 中匹配以 a 开头,以 b 结尾的所有子字符串。请从输出结果中,细细体味使用不同的贪婪或懒惰策略,对于匹配子字符串有什么影响。
# #6. 正则附录
# #6.1. 匹配正则字符串的方法
由于正则表达式中很多元字符本身就是转义字符,在 Java 字符串的规则中不会被显示出来。
为此,可以使用一个工具类 org.apache.commons.lang3.StringEscapeUtils 来做特殊处理,使得转义字符可以打印。这个工具类提供的都是静态方法,从方法命名大致也可以猜出用法,这里不多做说明。
如果你了解 maven,可以直接引入依赖
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>${commons-lang3.version}</version>
</dependency>【示例】本文为了展示正则匹配规则用到的方法
private boolean checkMatches(String regex, String content) {
Pattern p = Pattern.compile(regex);
Matcher m = p.matcher(content);
boolean flag = m.matches();
if (m.matches()) {
System.out.println(StringEscapeUtils.escapeJava(content) + "\tmatches: " + StringEscapeUtils.escapeJava(regex));
} else {
System.out.println(StringEscapeUtils.escapeJava(content) + "\tnot matches: " + StringEscapeUtils.escapeJava(regex));
}
return flag;
}
public int findAll(String regex, String content) {
Pattern p = Pattern.compile(regex);
Matcher m = p.matcher(content);
System.out.println("regex = " + regex + ", content: " + content);
int count = 0;
while (m.find()) {
count++;
System.out.println("[" + count + "th] " + "start: " + m.start() + ", end: " + m.end()
+ ", group: " + m.group());
}
if (0 == count) {
System.out.println("not found");
}
return count;
}# #6.2. 速查元字符字典
为了方便快查正则的元字符含义,在本节根据元字符的功能集中罗列正则的各种元字符。
# #限定符
| 字符 | 描述 |
|---|---|
* |
匹配前面的子表达式零次或多次。例如,zo* 能匹配 “z” 以及 “zoo”。* 等价于 {0,}。 |
+ |
匹配前面的子表达式一次或多次。例如,‘zo+’ 能匹配 “zo” 以及 “zoo”,但不能匹配 “z”。+ 等价于 {1,}。 |
? |
匹配前面的子表达式零次或一次。例如,“do (es)?” 可以匹配 “do” 或 “does” 中的 "do" 。? 等价于 {0,1}。 |
{n} |
n 是一个非负整数。匹配确定的 n 次。例如,‘o {2}’ 不能匹配 “Bob” 中的 ‘o’,但是能匹配 “food” 中的两个 o。 |
{n,} |
n 是一个非负整数。至少匹配 n 次。例如,‘o {2,}’ 不能匹配 “Bob” 中的 ‘o’,但能匹配 “foooood” 中的所有 o。‘o {1,}’ 等价于 ‘o+’。‘o {0,}’ 则等价于 ‘o*’。 |
{n,m} |
m 和 n 均为非负整数,其中 n <= m。最少匹配 n 次且最多匹配 m 次。例如,“o {1,3}” 将匹配 “fooooood” 中的前三个 o。‘o {0,1}’ 等价于 ‘o?’。请注意在逗号和两个数之间不能有空格。 |
# #定位符
| 字符 | 描述 |
|---|---|
^ |
匹配输入字符串开始的位置。如果设置了 RegExp 对象的 Multiline 属性,^ 还会与 \n 或 \r 之后的位置匹配。 |
$ |
匹配输入字符串结尾的位置。如果设置了 RegExp 对象的 Multiline 属性,$ 还会与 \n 或 \r 之前的位置匹配。 |
\b |
匹配一个字边界,即字与空格间的位置。 |
\B |
非字边界匹配。 |
# #非打印字符
| 字符 | 描述 |
|---|---|
\cx |
匹配由 x 指明的控制字符。例如, \cM 匹配一个 Control-M 或回车符。x 的值必须为 A-Z 或 a-z 之一。否则,将 c 视为一个原义的 ‘c’ 字符。 |
\f |
匹配一个换页符。等价于 \x0c 和 \cL。 |
\n |
匹配一个换行符。等价于 \x0a 和 \cJ。 |
\r |
匹配一个回车符。等价于 \x0d 和 \cM。 |
\s |
匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [\f\n\r\t\v]。 |
\S |
匹配任何非空白字符。等价于 [\f\n\r\t\v]。 |
\t |
匹配一个制表符。等价于 \x09 和 \cI。 |
\v |
匹配一个垂直制表符。等价于 \x0b 和 \cK。 |
# #分组
| 表达式 | 描述 |
|---|---|
(exp) |
匹配的子表达式。() 中的内容就是子表达式。 |
(?<name>exp) |
命名的子表达式(反向引用)。 |
(?:exp) |
非捕获组,表示当一个限定符应用到一个组,但组捕获的子字符串并非所需时,通常会使用非捕获组构造。 |
(?=exp) |
匹配 exp 前面的位置。 |
(?<=exp) |
匹配 exp 后面的位置。 |
(?!exp) |
匹配后面跟的不是 exp 的位置。 |
(?<!exp) |
匹配前面不是 exp 的位置。 |
# #特殊符号
| 字符 | 描述 |
|---|---|
\ |
将下一个字符标记为或特殊字符、或原义字符、或向后引用、或八进制转义符。例如, ‘n’ 匹配字符 ‘n’。’\n’ 匹配换行符。序列 ‘’ 匹配 “”,而 ‘(’ 则匹配 “(”。 |
\| |
指明两项之间的一个选择。 |
[] |
匹配方括号范围内的任意一个字符。形式如:[xyz]、[xyz]、[a-z]、[a-z]、[x,y,z] |
# #7. 正则实战
虽然本系列洋洋洒洒的大谈特谈正则表达式。但是我还是要在这里建议,如果一个正则表达式没有经过充分测试,还是要谨慎使用。
正则是把双刃剑,它可以为你节省大量的代码行。但是由于它不易阅读,维护起来可是头疼的哦(你需要一个字符一个字符的去理解)。
# #7.1. 最实用的正则
# #校验中文
校验字符串中只能有中文字符(不包括中文标点符号)。中文字符的 Unicode 编码范围是 \u4e00 到 \u9fa5 。
如有兴趣,可以参考百度百科 - Unicode (opens new window)。
^[\u4e00-\u9fa5]+$- 匹配: 春眠不觉晓
- ** 不匹配:** 春眠不觉晓,
# #校验身份证号码
身份证为 15 位或 18 位。15 位是第一代身份证。从 1999 年 10 月 1 日起,全国实行公民身份证号码制度,居民身份证编号由原 15 位升至 18 位。
- 15 位身份证:由 15 位数字组成。排列顺序从左至右依次为:六位数字地区码;六位数字出生日期;三位顺序号,其中 15 位男为单数,女为双数。
- 18 位身份证:由十七位数字本体码和一位数字校验码组成。排列顺序从左至右依次为:六位数字地区码;八位数字出生日期;三位数字顺序码和一位数字校验码(也可能是 X)。
身份证号含义详情请见:百度百科 - 居民身份证号码 (opens new window)
地区码(6 位)
(1[1-5]|2[1-3]|3[1-7]|4[1-3]|5[0-4]|6[1-5])\d{4}出生日期(8 位)
注:下面的是 18 位身份证的有效出生日期,如果是 15 位身份证,只要将第一个 \d {4} 改为 \d {2} 即可。
((\d{4}((0[13578]|1[02])(0[1-9]|[12]\d|3[01])|(0[13456789]|1[012])(0[1-9]|[12]\d|30)|02(0[1-9]|1\d|2[0-8])))|([02468][048]|[13579][26])0229)15 位有效身份证
^((1[1-5]|2[1-3]|3[1-7]|4[1-3]|5[0-4]|6[1-5])\d{4})((\d{2}((0[13578]|1[02])(0[1-9]|[12]\d|3[01])|(0[13456789]|1[012])(0[1-9]|[12]\d|30)|02(0[1-9]|1\d|2[0-8])))|([02468][048]|[13579][26])0229)(\d{3})$- ** 匹配:**110001700101031
- ** 不匹配:**110001701501031
18 位有效身份证
^((1[1-5]|2[1-3]|3[1-7]|4[1-3]|5[0-4]|6[1-5])\d{4})((\d{4}((0[13578]|1[02])(0[1-9]|[12]\d|3[01])|(0[13456789]|1[012])(0[1-9]|[12]\d|30)|02(0[1-9]|1\d|2[0-8])))|([02468][048]|[13579][26])0229)(\d{3}(\d|X))$- ** 匹配:**110001199001010310 | 11000019900101015X
- ** 不匹配:**990000199001010310 | 110001199013010310
# #校验有效用户名、密码
** 描述:** 长度为 6-18 个字符,允许输入字母、数字、下划线,首字符必须为字母。
^[a-zA-Z]\w{5,17}$- ** 匹配:**he_llo@worl.d.com | hel.l-o@wor-ld.museum | h1ello@123.com
- ** 不匹配:**hello@worl_d.com | he&llo@world.co1 | .hello@wor#.co.uk
# #校验邮箱
** 描述:** 不允许使用 IP 作为域名,如 : hello@154.145.68.12
@ 符号前的邮箱用户和 . 符号前的域名 (domain) 必须满足以下条件:
- 字符只能是英文字母、数字、下划线
_、.、-; - 首字符必须为字母或数字;
_、.、-不能连续出现。
域名的根域只能为字母,且至少为两个字符。
^[A-Za-z0-9](([_\.\-]?[a-zA-Z0-9]+)*)@([A-Za-z0-9]+)(([\.\-]?[a-zA-Z0-9]+)*)\.([A-Za-z]{2,})$- ** 匹配:**he_llo@worl.d.com | hel.l-o@wor-ld.museum | h1ello@123.com
- ** 不匹配:**hello@worl_d.com | he&llo@world.co1 | .hello@wor#.co.uk
# #校验 URL
** 描述:** 校验 URL。支持 http、https、ftp、ftps。
^(ht|f)(tp|tps)\://[a-zA-Z0-9\-\.]+\.([a-zA-Z]{2,3})?(/\S*)?$- ** 匹配:**http://google.com/help/me | http://www.google.com/help/me/ | https://www.google.com/help.asp | ftp://www.google.com | ftps://google.org
- ** 不匹配:**http://un/www.google.com/index.asp
# #校验时间
** 描述:** 校验时间。时、分、秒必须是有效数字,如果数值不是两位数,十位需要补零。
^([0-1][0-9]|[2][0-3]):([0-5][0-9])$- ** 匹配:**00:00:00 | 23:59:59 | 17:06:30
- ** 不匹配:**17:6:30 | 24:16:30
# #校验日期
** 描述:** 校验日期。日期满足以下条件:
- 格式 yyyy-MM-dd 或 yyyy-M-d
- 连字符可以没有或是 “-”、“/”、“.” 之一
- 闰年的二月可以有 29 日;而平年不可以。
- 一、三、五、七、八、十、十二月为 31 日。四、六、九、十一月为 30 日。
^(?:(?!0000)[0-9]{4}([-/.]?)(?:(?:0?[1-9]|1[0-2])\1(?:0?[1-9]|1[0-9]|2[0-8])|(?:0?[13-9]|1[0-2])\1(?:29|30)|(?:0?[13578]|1[02])\1(?:31))|(?:[0-9]{2}(?:0[48]|[2468][048]|[13579][26])|(?:0[48]|[2468][048]|[13579][26])00)([-/.]?)0?2\2(?:29))$- ** 匹配:**2016/1/1 | 2016/01/01 | 20160101 | 2016-01-01 | 2016.01.01 | 2000-02-29
- ** 不匹配:**2001-02-29 | 2016/12/32 | 2016/6/31 | 2016/13/1 | 2016/0/1
# #校验中国手机号码
** 描述:** 中国手机号码正确格式:11 位数字。
移动有 16 个号段:134、135、136、137、138、139、147、150、151、152、157、158、159、182、187、188。其中 147、157、188 是 3G 号段,其他都是 2G 号段。联通有 7 种号段:130、131、132、155、156、185、186。其中 186 是 3G(WCDMA)号段,其余为 2G 号段。电信有 4 个号段:133、153、180、189。其中 189 是 3G 号段(CDMA2000),133 号段主要用作无线网卡号。总结:13 开头手机号 0-9;15 开头手机号 0-3、5-9;18 开头手机号 0、2、5-9。
此外,中国在国际上的区号为 86,所以手机号开头有 + 86、86 也是合法的。
以上信息来源于 百度百科 - 手机号 (opens new window)
^((\+)?86\s*)?((13[0-9])|(15([0-3]|[5-9]))|(18[0,2,5-9]))\d{8}$- 匹配:+86 18012345678 | 86 18012345678 | 15812345678
- ** 不匹配:**15412345678 | 12912345678 | 180123456789
# #校验中国固话号码
** 描述:** 固话号码,必须加区号(以 0 开头)。 3 位有效区号:010、020~029,固话位数为 8 位。 4 位有效区号:03xx 开头到 09xx,固话位数为 7。
如果想了解更详细的信息,请参考 百度百科 - 电话区号 (opens new window)。
^(010|02[0-9])(\s|-)\d{8}|(0[3-9]\d{2})(\s|-)\d{7}$- ** 匹配:**010-12345678 | 010 12345678 | 0512-1234567 | 0512 1234567
- ** 不匹配:**1234567 | 12345678
# #校验 IPv4 地址
** 描述:**IP 地址是一个 32 位的二进制数,通常被分割为 4 个 “8 位二进制数”(也就是 4 个字节)。IP 地址通常用 “点分十进制” 表示成(a.b.c.d)的形式,其中,a,b,c,d 都是 0~255 之间的十进制整数。
^([01]?\d\d?|2[0-4]\d|25[0-5])\.([01]?\d\d?|2[0-4]\d|25[0-5])\.([01]?\d\d?|2[0-4]\d|25[0-5])\.([01]?\d\d?|2[0-4]\d|25[0-5])$- ** 匹配:**0.0.0.0 | 255.255.255.255 | 127.0.0.1
- ** 不匹配:**10.10.10 | 10.10.10.256
# #校验 IPv6 地址
** 描述:**IPv6 的 128 位地址通常写成 8 组,每组为四个十六进制数的形式。
IPv6 地址可以表示为以下形式:
- IPv6 地址
- 零压缩 IPv6 地址 (section 2.2 of rfc5952 (opens new window))
- 带有本地链接区域索引的 IPv6 地址 (section 11 of rfc4007 (opens new window))
- 嵌入 IPv4 的 IPv6 地址 (section 2 of rfc6052(opens new window)
- 映射 IPv4 的 IPv6 地址 (section 2.1 of rfc2765 (opens new window))
- 翻译 IPv4 的 IPv6 地址 (section 2.1 of rfc2765 (opens new window))
显然,IPv6 地址的表示方式很复杂。你也可以参考:
(([0-9a-fA-F]{1,4}:){7,7}[0-9a-fA-F]{1,4}|([0-9a-fA-F]{1,4}:){1,7}:|([0-9a-fA-F]{1,4}:){1,6}:[0-9a-fA-F]{1,4}|([0-9a-fA-F]{1,4}:){1,5}(:[0-9a-fA-F]{1,4}){1,2}|([0-9a-fA-F]{1,4}:){1,4}(:[0-9a-fA-F]{1,4}){1,3}|([0-9a-fA-F]{1,4}:){1,3}(:[0-9a-fA-F]{1,4}){1,4}|([0-9a-fA-F]{1,4}:){1,2}(:[0-9a-fA-F]{1,4}){1,5}|[0-9a-fA-F]{1,4}:((:[0-9a-fA-F]{1,4}){1,6})|:((:[0-9a-fA-F]{1,4}){1,7}|:)|fe80:(:[0-9a-fA-F]{0,4}){0,4}%[0-9a-zA-Z]{1,}|::(ffff(:0{1,4}){0,1}:){0,1}((25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])\.){3,3}(25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])|([0-9a-fA-F]{1,4}:){1,4}:((25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])\.){3,3}(25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9]))- ** 匹配:**1:2:3:4:5:6:7:8 | 1:: | 1::8 | 1::6:7:8 | 1::5:6:7:8 | 1::4:5:6:7:8 | 1::3:4:5:6:7:8 | ::2:3:4:5:6:7:8 | 1:2:3:4:5:6:7:: | 1:2:3:4:5:6::8 | 1:2:3:4:5::8 | 1:2:3:4::8 | 1:2:3::8 | 1:2::8 | 1::8 | ::8 | fe80::7:8%1 | ::255.255.255.255 | 2001:db8:3:4::192.0.2.33 | 64:ff9b::192.0.2.33
- ** 不匹配:**1.2.3.4.5.6.7.8 | 1::2::3
# #7.2. 特定字符
- 匹配长度为 3 的字符串:
^.{3}$。 - 匹配由 26 个英文字母组成的字符串:
^[A-Za-z]+$。 - 匹配由 26 个大写英文字母组成的字符串:
^[A-Z]+$。 - 匹配由 26 个小写英文字母组成的字符串:
^[a-z]+$。 - 匹配由数字和 26 个英文字母组成的字符串:
^[A-Za-z0-9]+$。 - 匹配由数字、26 个英文字母或者下划线组成的字符串:
^\w+$。
# #7.3. 特定数字
- 匹配正整数:
^[1-9]\d*$ - 匹配负整数:
^-[1-9]\d*$ - 匹配整数:
^(-?[1-9]\d*)|0$ - 匹配正浮点数:
^[1-9]\d*\.\d+|0\.\d+$ - 匹配负浮点数:
^-([1-9]\d*\.\d*|0\.\d*[1-9]\d*)$ - 匹配浮点数:
^-?([1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0)$
# #8. 正则表达式的性能
目前实现正则表达式引擎的方式有两种:DFA 自动机(Deterministic Final Automata 确定有限状态自动机)和 NFA 自动机(Non deterministic Finite Automaton 非确定有限状态自动机)。对比来看,构造 DFA 自动机的代价远大于 NFA 自动机,但 DFA 自动机的执行效率高于 NFA 自动机。
假设一个字符串的长度是 n,如果用 DFA 自动机作为正则表达式引擎,则匹配的时间复杂度为 O (n);如果用 NFA 自动机作为正则表达式引擎,由于 NFA 自动机在匹配过程中存在大量的分支和回溯,假设 NFA 的状态数为 s,则该匹配算法的时间复杂度为 O(ns)。
NFA 自动机的优势是支持更多功能。例如,捕获 group、环视、占有优先量词等高级功能。这些功能都是基于子表达式独立进行匹配,因此在编程语言里,使用的正则表达式库都是基于 NFA 实现的。
# #8.1. NFA 自动机的回溯
用 NFA 自动机实现的比较复杂的正则表达式,在匹配过程中经常会引起回溯问题。大量的回溯会长时间地占用 CPU,从而带来系统性能开销。
text=“abbc”
regex=“ab{1,3}c”这个例子匹配目的是:匹配以 a 开头,以 c 结尾,中间有 1-3 个 b 字符的字符串。NFA 自动机对其解析的过程是这样的:
- 读取正则表达式第一个匹配符 a 和字符串第一个字符 a 进行比较,a 对 a,匹配。
- 然后,读取正则表达式第二个匹配符
b{1,3}和字符串的第二个字符 b 进行比较,匹配。但因为b{1,3}表示 1-3 个 b 字符串,NFA 自动机又具有贪婪特性,所以此时不会继续读取正则表达式的下一个匹配符,而是依旧使用b{1,3}和字符串的第三个字符 b 进行比较,结果还是匹配。 - 接着继续使用
b{1,3}和字符串的第四个字符 c 进行比较,发现不匹配了,此时就会发生回溯,已经读取的字符串第四个字符 c 将被吐出去,指针回到第三个字符 b 的位置。 - 那么发生回溯以后,匹配过程怎么继续呢?程序会读取正则表达式的下一个匹配符 c,和字符串中的第四个字符 c 进行比较,结果匹配,结束。
# #8.2. 如何避免回溯
# #贪婪模式(Greedy)
顾名思义,就是在数量匹配中,如果单独使用 +、 ? 、* 或 {min,max} 等量词,正则表达式会匹配尽可能多的内容。
例如,上边那个例子:
text=“abbc”
regex=“ab{1,3}c”就是在贪婪模式下,NFA 自动机读取了最大的匹配范围,即匹配 3 个 b 字符。匹配发生了一次失败,就引起了一次回溯。如果匹配结果是 “abbbc”,就会匹配成功。
text=“abbbc”
regex=“ab{1,3}c”# #懒惰模式(Reluctant)
在该模式下,正则表达式会尽可能少地重复匹配字符。如果匹配成功,它会继续匹配剩余的字符串。
例如,在上面例子的字符后面加一个 “?”,就可以开启懒惰模式。
text=“abc”
regex=“ab{1,3}?c”匹配结果是 “abc”,该模式下 NFA 自动机首先选择最小的匹配范围,即匹配 1 个 b 字符,因此就避免了回溯问题。
# #独占模式(Possessive)
同贪婪模式一样,独占模式一样会最大限度地匹配更多内容;不同的是,在独占模式下,匹配失败就会结束匹配,不会发生回溯问题。
还是上边的例子,在字符后面加一个 “+”,就可以开启独占模式。
text=“abbc”
regex=“ab{1,3}+bc”结果是不匹配,结束匹配,不会发生回溯问题。
讲到这里,你应该非常清楚了,避免回溯的方法就是:使用懒惰模式和独占模式。
# #8.3. 正则表达式的优化
# #少用贪婪模式,多用独占模式
贪婪模式会引起回溯问题,可以使用独占模式来避免回溯。
# #减少分支选择
分支选择类型 (X|Y|Z) 的正则表达式会降低性能,我们在开发的时候要尽量减少使用。如果一定要用,我们可以通过以下几种方式来优化:
- 首先,我们需要考虑选择的顺序,将比较常用的选择项放在前面,使它们可以较快地被匹配;
- 其次,我们可以尝试提取共用模式,例如,将
(abcd|abef)替换为ab(cd|ef),后者匹配速度较快,因为 NFA 自动机会尝试匹配 ab,如果没有找到,就不会再尝试任何选项; - 最后,如果是简单的分支选择类型,我们可以用三次 index 代替
(X|Y|Z),如果测试的话,你就会发现三次 index 的效率要比(X|Y|Z)高出一些。
# #减少捕获嵌套
- 捕获组是指把正则表达式中,子表达式匹配的内容保存到以数字编号或显式命名的数组中,方便后面引用。一般一个 () 就是一个捕获组,捕获组可以进行嵌套。
- 非捕获组则是指参与匹配却不进行分组编号的捕获组,其表达式一般由
(?:exp)组成。
在正则表达式中,每个捕获组都有一个编号,编号 0 代表整个匹配到的内容。我们可以看下面的例子:
public static void main(String[] args) {
String text = "<input high=\"20\" weight=\"70\">test</input>";
String reg="(<input.*?>)(.*?)(</input>)";
Pattern p = Pattern.compile(reg);
Matcher m = p.matcher(text);
while(m.find()) {
System.out.println(m.group(0));// 整个匹配到的内容
System.out.println(m.group(1));//(<input.*?>)
System.out.println(m.group(2));//(.*?)
System.out.println(m.group(3));//(</input>)
}
}运行结果:
<input high=\"20\" weight=\"70\">test</input>
<input high=\"20\" weight=\"70\">
test
</input>如果你并不需要获取某一个分组内的文本,那么就使用非捕获分组。例如,使用 “(?:X)” 代替 “(X)”,我们再看下面的例子:
public static void main(String[] args) {
String text = "<input high=\"20\" weight=\"70\">test</input>";
String reg="(?:<input.*?>)(.*?)(?:</input>)";
Pattern p = Pattern.compile(reg);
Matcher m = p.matcher(text);
while(m.find()) {
System.out.println(m.group(0));// 整个匹配到的内容
System.out.println(m.group(1));//(.*?)
}
}运行结果:
<input high=\"20\" weight=\"70\">test</input>
test综上可知:减少不需要获取的分组,可以提高正则表达式的性能。
# Java 编码和加密
📦 本文以及示例源码已归档在 javacore(opens new window)
关键词:
Base64、消息摘要、数字签名、对称加密、非对称加密、MD5、SHA、HMAC、AES、DES、DESede、RSA
# #一、Base64 编码
# #Base64 原理
Base64 内容传送编码是一种以任意 8 位字节序列组合的描述形式,这种形式不易被人直接识别。
Base64 是一种很常见的编码规范,其作用是将二进制序列转换为人类可读的 ASCII 字符序列,常用在需用通过文本协议(比如 HTTP 和 SMTP)来传输二进制数据的情况下。Base64 并不是加密解密算法,尽管我们有时也听到使用 Base64 来加密解密的说法,但这里所说的加密与解密实际是指 ** 编码(encode)和解码(decode)** 的过程,其变换是非常简单的,仅仅能够避免信息被直接识别。
Base64 算法主要是将给定的字符以字符编码 (如 ASCII 码,UTF-8 码) 对应的十进制数为基准,做编码操作:
- 将给定的字符串以字符为单位,转换为对应的字符编码。
- 将获得字符编码转换为二进制
- 对二进制码做分组转换,每 3 个字节为一组,转换为每 4 个 6 位二进制位一组(不足 6 位时低位补 0)。这是一个分组变化的过程,3 个 8 位二进制码和 4 个 6 位二进制码的长度都是 24 位(38 = 46 = 24)。
- 对获得的 4-6 二进制码补位,向 6 位二进制码添加 2 位高位 0,组成 4 个 8 位二进制码。
- 对获得的 4-8 二进制码转换为十进制码。
- 将获得的十进制码转换为 Base64 字符表中对应的字符。
*Base64 编码表 *
| 索引 | 对应字符 | 索引 | 对应字符 | 索引 | 对应字符 | 索引 | 对应字符 |
|---|---|---|---|---|---|---|---|
| 0 | A | 17 | R | 34 | i | 51 | z |
| 1 | B | 18 | S | 35 | j | 52 | 0 |
| 2 | C | 19 | T | 36 | k | 53 | 1 |
| 3 | D | 20 | U | 37 | l | 54 | 2 |
| 4 | E | 21 | V | 38 | m | 55 | 3 |
| 5 | F | 22 | W | 39 | n | 56 | 4 |
| 6 | G | 23 | X | 40 | o | 57 | 5 |
| 7 | H | 24 | Y | 41 | p | 58 | 6 |
| 8 | I | 25 | Z | 42 | q | 59 | 7 |
| 9 | J | 26 | a | 43 | r | 60 | 8 |
| 10 | K | 27 | b | 44 | s | 61 | 9 |
| 11 | L | 28 | c | 45 | t | 62 | + |
| 12 | M | 29 | d | 46 | u | 63 | / |
| 13 | N | 30 | e | 47 | v | ||
| 14 | O | 31 | f | 48 | w | ||
| 15 | P | 32 | g | 49 | x | ||
| 16 | Q | 33 | h | 50 | y |
# #Base64 应用
Base64 编码可用于在 HTTP 环境下传递较长的标识信息。在其他应用程序中,也常常需要把二进制数据编码为适合放在 URL (包括隐藏表单域) 中的形式。此时,采用 Base64 编码具有不可读性,即所编码的数据不会被人用肉眼所直接看到,算是起到一个加密的作用。
然而,标准的 Base64 并不适合直接放在 URL 里传输,因为 URL 编码器会把标准 Base64 中的 / 和 + 字符变为形如 %XX 的形式,而这些 % 号在存入数据库时还需要再进行转换,因为 ANSI SQL 中已将 % 号用作通配符。
为解决此问题,可采用一种用于 URL 的改进 Base64 编码,它不仅在末尾填充 = 号,并将标准 Base64 中的 “+” 和 “/” 分别改成了 - 和 _ ,这样就免去了在 URL 编解码和数据库存储时所要作的转换,避免了编码信息长度在此过程中的增加,并统一了数据库、表单等处对象标识符的格式。
另有一种用于正则表达式的改进 Base64 变种,它将 + 和 / 改成了 ! 和 - ,因为 + , * 以及前面在 IRCu 中用到的 [ 和 ] 在正则表达式中都可能具有特殊含义。
【示例】 java.util.Base64 编码、解码示例
Base64.getEncoder() 和 Base64.getDecoder() 提供了的是标准的 Base64 编码、解码方式;
Base64.getUrlEncoder() 和 Base64.getUrlDecoder() 提供了 URL 安全的 Base64 编码、解码方式(将 + 和 / 替换为 - 和 _ )。
import java.nio.charset.StandardCharsets;
import java.util.Base64;
public class Base64Demo {
public static void main(String[] args) {
String url = "https://www.baidu.com";
System.out.println("url:" + url);
// 标准的 Base64 编码、解码
byte[] encoded = Base64.getEncoder().encode(url.getBytes(StandardCharsets.UTF_8));
byte[] decoded = Base64.getDecoder().decode(encoded);
System.out.println("Url Safe Base64 encoded:" + new String(encoded));
System.out.println("Url Safe Base64 decoded:" + new String(decoded));
// URL 安全的 Base64 编码、解码
byte[] encoded2 = Base64.getUrlEncoder().encode(url.getBytes(StandardCharsets.UTF_8));
byte[] decoded2 = Base64.getUrlDecoder().decode(encoded2);
System.out.println("Base64 encoded:" + new String(encoded2));
System.out.println("Base64 decoded:" + new String(decoded2));
}
}输出:
url:https://www.baidu.com
Url Safe Base64 encoded:aHR0cHM6Ly93d3cuYmFpZHUuY29t
Url Safe Base64 decoded:https://www.baidu.com
Base64 encoded:aHR0cHM6Ly93d3cuYmFpZHUuY29t
Base64 decoded:https://www.baidu.com# #二、消息摘要
# #消息摘要概述
消息摘要,其实就是将需要摘要的数据作为参数,经过哈希函数 (Hash) 的计算,得到的散列值。
消息摘要是一个唯一对应一个消息或文本的固定长度的值,它由一个单向 Hash 加密函数对消息进行作用而产生。如果消息在途中改变了,则接收者通过对收到消息的新产生的摘要与原摘要比较,就可知道消息是否被改变了。因此消息摘要保证了消息的完整性。消息摘要采用单向 Hash 函数将需加密的明文 "摘要" 成一串密文,这一串密文亦称为数字指纹 (Finger Print)。它有固定的长度,且不同的明文摘要成密文,其结果总是不同的,而同样的明文其摘要必定一致。这样这串摘要便可成为验证明文是否是 "真身" 的 "指纹" 了。
# #消息摘要特点
- 唯一性:数据只要有一点改变,那么再通过消息摘要算法得到的摘要也会发生变化。虽然理论上有可能会发生碰撞,但是概率极其低。
- 不可逆:消息摘要算法的密文无法被解密。
- 不需要密钥,可使用于分布式网络。
- 无论输入的明文有多长,计算出来的消息摘要的长度总是固定的。
# #消息摘要常用算法
消息摘要算法包括 MD (Message Digest,消息摘要算法)、SHA (Secure Hash Algorithm,安全散列算法)、**MAC (Message AuthenticationCode,消息认证码算法)** 共 3 大系列,常用于验证数据的完整性,是数字签名算法的核心算法。
MD5 和 SHA1 分别是 MD、SHA 算法系列中最有代表性的算法。
如今,MD5 已被发现有许多漏洞,从而不再安全。SHA 算法比 MD 算法的摘要长度更长,也更加安全。
# #消息摘要应用
# #MD5、SHA 的范例
JDK 中使用 MD5 和 SHA 这两种消息摘要的方式基本一致,步骤如下:
- 初始化 MessageDigest 对象
- 更新要计算的内容
- 生成摘要
import java.security.MessageDigest;
import java.util.Base64;
public class MessageDigestDemo {
public static byte[] encode(byte[] input, Type type) throws Exception {
// 根据类型,初始化消息摘要对象
MessageDigest md5Digest = MessageDigest.getInstance(type.getName());
// 更新要计算的内容
md5Digest.update(input);
// 完成哈希计算,返回摘要
return md5Digest.digest();
}
public static byte[] encodeWithBase64(byte[] input, Type type) throws Exception {
return Base64.getUrlEncoder().encode(encode(input, type));
}
public static String encodeWithBase64String(byte[] input, Type type) throws Exception {
return Base64.getUrlEncoder().encodeToString(encode(input, type));
}
public enum Type {
MD2("MD2"),
MD5("MD5"),
SHA1("SHA1"),
SHA256("SHA-256"),
SHA384("SHA-384"),
SHA512("SHA-512");
private String name;
Type(String name) {
this.name = name;
}
public String getName() {
return this.name;
}
}
public static void main(String[] args) throws Exception {
String msg = "Hello World!";
System.out.println("MD2: " + encodeWithBase64String(msg.getBytes(), Type.MD2));
System.out.println("MD5: " + encodeWithBase64String(msg.getBytes(), Type.MD5));
System.out.println("SHA1: " + encodeWithBase64String(msg.getBytes(), Type.SHA1));
System.out.println("SHA256: " + encodeWithBase64String(msg.getBytes(), Type.SHA256));
System.out.println("SHA384: " + encodeWithBase64String(msg.getBytes(), Type.SHA384));
System.out.println("SHA512: " + encodeWithBase64String(msg.getBytes(), Type.SHA512));
}
}【输出】
MD2: MV98ZyI_Aft8q0uVEA6HLg==
MD5: 7Qdih1MuhjZehB6Sv8UNjA==
SHA1: Lve95gjOVATpfV8EL5X4nxwjKHE=
SHA256: f4OxZX_x_FO5LcGBSKHWXfwtSx-j1ncoSt3SABJtkGk=
SHA384: v9dsDrvQBv7lg0EFR8GIewKSvnbVgtlsJC0qeScj4_1v0GH51c_RO4-WE1jmrbpK
SHA512: hhhE1nBOhXP-w02WfiC8_vPUJM9IvgTm3AjyvVjHKXQzcQFerYkcw88cnTS0kmS1EHUbH_nlN5N7xGtdb_TsyA==# #HMAC 的范例
import java.nio.charset.StandardCharsets;
import java.util.Base64;
import javax.crypto.Mac;
import javax.crypto.spec.SecretKeySpec;
public class HmacMessageDigest {
public static void main(String[] args) throws Exception {
String msg = "Hello World!";
byte[] salt = "My Salt".getBytes(StandardCharsets.UTF_8);
System.out.println("原文: " + msg);
System.out.println("HmacMD5: " + encodeWithBase64String(msg.getBytes(), salt, HmacTypeEn.HmacMD5));
System.out.println("HmacSHA1: " + encodeWithBase64String(msg.getBytes(), salt, HmacTypeEn.HmacSHA1));
System.out.println("HmacSHA256: " + encodeWithBase64String(msg.getBytes(), salt, HmacTypeEn.HmacSHA256));
System.out.println("HmacSHA384: " + encodeWithBase64String(msg.getBytes(), salt, HmacTypeEn.HmacSHA384));
System.out.println("HmacSHA512: " + encodeWithBase64String(msg.getBytes(), salt, HmacTypeEn.HmacSHA512));
}
public static byte[] encode(byte[] plaintext, byte[] salt, HmacTypeEn type) throws Exception {
SecretKeySpec keySpec = new SecretKeySpec(salt, type.name());
Mac mac = Mac.getInstance(keySpec.getAlgorithm());
mac.init(keySpec);
return mac.doFinal(plaintext);
}
public static byte[] encodeWithBase64(byte[] plaintext, byte[] salt, HmacTypeEn type) throws Exception {
return Base64.getUrlEncoder().encode(encode(plaintext, salt, type));
}
public static String encodeWithBase64String(byte[] plaintext, byte[] salt, HmacTypeEn type) throws Exception {
return Base64.getUrlEncoder().encodeToString(encode(plaintext, salt, type));
}
/**
* JDK支持 HmacMD5, HmacSHA1, HmacSHA256, HmacSHA384, HmacSHA512
*/
public enum HmacTypeEn {
HmacMD5, HmacSHA1, HmacSHA256, HmacSHA384, HmacSHA512;
}
}输出
原文: Hello World!
HmacMD5: re6BLRsB1Q26SfJTwXZUSQ==
HmacSHA1: CFu8a9H6CbY9C5fo0OmJ2bnuILM=
HmacSHA256: Z1czUqDWWfYYl7qEDJ2sUH6iieHVI7o83dXMl0JYER0=
HmacSHA384: 34mKtRQBOYnwwznmQubjrDk_MsLDGqM2PmgcplZUpLsKNrG_cwfz4bLPJCbBW88b
HmacSHA512: 6n77htTZ_atc04-SsmxhSK3wzh1sAmdudCl0Cb_RZp4DpienG4LZkhXMbq8lcK7XSnz6my_wIpnStDp6PC_-5w==# #三、数字签名
# #数字签名概述
数字签名算法可以看做是一种带有密钥的消息摘要算法,并且这种密钥包含了公钥和私钥。也就是说,数字签名算法是非对称加密算法和消息摘要算法的结合体。
数字签名算法要求能够验证数据完整性、认证数据来源,并起到抗否认的作用。
数字签名算法包含签名和验证两项操作,遵循私钥签名,公钥验证的方式。
签名时要使用私钥和待签名数据,验证时则需要公钥、签名值和待签名数据,其核心算法主要是消息摘要算法。
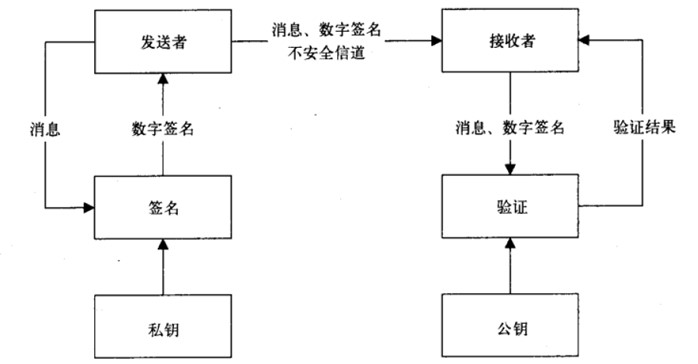
数字签名常用算法:RSA、DSA、ECDSA
# #数字签名算法应用
# #DSA 的范例
数字签名有两个流程:签名和验证。
它们的前提都是要有一个公钥、密钥对。
数字签名用私钥为消息计算签名。
【示例】用公钥验证摘要
public class DsaCoder {
public static final String KEY_ALGORITHM = "DSA";
public static final String SIGN_ALGORITHM = "SHA1withDSA";
/**
* DSA密钥长度默认1024位。 密钥长度必须是64的整数倍,范围在512~1024之间
*/
private static final int KEY_SIZE = 1024;
private KeyPair keyPair;
public DsaCoder() throws Exception {
this.keyPair = initKey();
}
private KeyPair initKey() throws Exception {
// 初始化密钥对生成器
KeyPairGenerator keyPairGen = KeyPairGenerator.getInstance(DsaCoder.KEY_ALGORITHM);
// 实例化密钥对生成器
keyPairGen.initialize(KEY_SIZE);
// 实例化密钥对
return keyPairGen.genKeyPair();
}
public byte[] signature(byte[] data, byte[] privateKey) throws Exception {
PKCS8EncodedKeySpec keySpec = new PKCS8EncodedKeySpec(privateKey);
KeyFactory keyFactory = KeyFactory.getInstance(KEY_ALGORITHM);
PrivateKey key = keyFactory.generatePrivate(keySpec);
Signature signature = Signature.getInstance(SIGN_ALGORITHM);
signature.initSign(key);
signature.update(data);
return signature.sign();
}
public byte[] getPrivateKey() {
return keyPair.getPrivate().getEncoded();
}
public boolean verify(byte[] data, byte[] publicKey, byte[] sign) throws Exception {
X509EncodedKeySpec keySpec = new X509EncodedKeySpec(publicKey);
KeyFactory keyFactory = KeyFactory.getInstance(KEY_ALGORITHM);
PublicKey key = keyFactory.generatePublic(keySpec);
Signature signature = Signature.getInstance(SIGN_ALGORITHM);
signature.initVerify(key);
signature.update(data);
return signature.verify(sign);
}
public byte[] getPublicKey() {
return keyPair.getPublic().getEncoded();
}
public static void main(String[] args) throws Exception {
String msg = "Hello World";
DsaCoder dsa = new DsaCoder();
byte[] sign = dsa.signature(msg.getBytes(), dsa.getPrivateKey());
boolean flag = dsa.verify(msg.getBytes(), dsa.getPublicKey(), sign);
String result = flag ? "数字签名匹配" : "数字签名不匹配";
System.out.println("数字签名:" + Base64.getUrlEncoder().encodeToString(sign));
System.out.println("验证结果:" + result);
}
}【输出】
数字签名:MCwCFDPUO_VrONl5ST0AWary-MLXJuSCAhRMeMnUVhpizfa2H2M37tne0pUtoA==
验证结果:数字签名匹配# #四、对称加密
# #对称加密概述
对称加密算法主要有 DES、3DES(TripleDES)、AES、IDEA、RC2、RC4、RC5 和 Blowfish 等。
对称加密算法是应用较早的加密算法,技术成熟。在对称加密算法中,数据发信方将明文(原始数据)和加密密钥(mi yao)一起经过特殊加密算法处理后,使其变成复杂的加密密文发送出去。收信方收到密文后,若想解读原文,则需要使用加密用过的密钥及相同算法的逆算法对密文进行解密,才能使其恢复成可读明文。在对称加密算法中,使用的密钥只有一个,发收信双方都使用这个密钥对数据进行加密和解密,这就要求解密方事先必须知道加密密钥。
对称加密特点:
- 优点:计算量小、加密速度快、加密效率高。
- 缺点:算法是公开的,安全性得不到保证。
通信双方每次使用对称加密算法时,都需要使用其他人不知道的惟一密钥,这会使得通信双方所拥有的密钥数量呈几何级数增长,密钥管理成为用户的负担。对称加密算法在分布式网络系统上使用较为困难,主要是因为密钥管理困难,使用成本较高。
而与公钥、密钥加密算法比起来,对称加密算法能够提供加密和认证却缺乏了签名功能,使得使用范围有所缩小。
# #对称加密原理
对称加密要求加密与解密使用同一个密钥,解密是加密的逆运算。由于加密、解密使用同一个密钥,这要求通信双方必须在通信前商定该密钥,并妥善保存该密钥。
对称加密体制分为两种:
一种是对明文的单个位(或字节)进行运算,称为流密码,也称为序列密码;
一种是把明文信息划分为不同的组(或块)结构,分别对每个组(或块)进行加密、解密,称为分组密码。
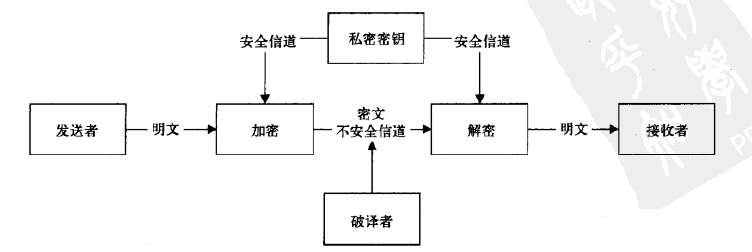
假设甲乙方作为通信双方。假定甲乙双方在消息传递前已商定加密算法,欲完成一次消息传递需要经过如下步骤。
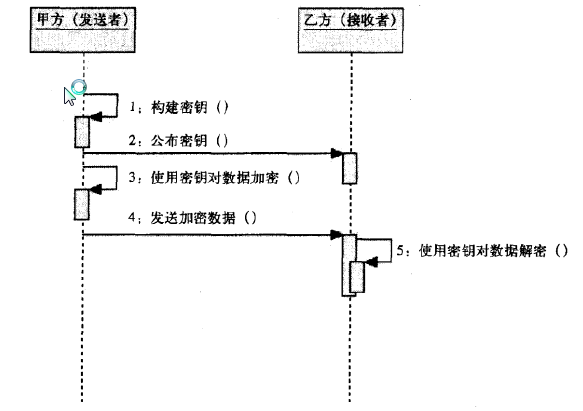
# #对称加密工作模式
以 DES 算法的工作模式为例,DES 算法根据其加密算法所定义的明文分组的大小(56 位),将数据分割成若干 56 位的加密区块,再以加密区块为单位,分别进行加密处理。如果最后剩下不足一个区块的大小,称之为短块。短块的处理方法有填充法、流密码加密法、密文挪用技术。
根据数据加密时每个加密区块见得关联方式来区分,可以分为以下种工作模式:
(1) 电子密码本模式 (Electronic Code Book, ECB)
用途:适合加密密钥,随机数等短数据。例如,安全地传递 DES 密钥,ECB 是最合适的模式。
(2) 密文链接模式 (Cipher Booki Chaining, CBC)
用途:可加密任意长度的数据,适用于计算产生检测数据完整性的消息认证 MAC。
(3) 密文反馈模式 (Cipher Feed Back, CFB)
用途:因错误传播无界,可以用于检查发现明文密文的篡改。
(4) 输出反馈模式 (Output Feed Back, OFB)
用途:使用于加密冗余性较大的数据,比如语音和图像数据。
AES 算法除了以上 4 中模式外,还有一种新的工作模式:
(5) 计数器模式 (Counter, CTR)
用途:适用于各种加密应用。
本文对于各种工作模式的原理展开描述。个人认为,作为工程应用,了解其用途即可。
# #对称加密填充方法
Java 中对称加密对于短块的处理,一般是采用填充方式。
常采用的是:NoPadding(不填充)、Zeros 填充(0 填充)、PKCS5Padding 填充。
ZerosPadding
方式:全部填充为 0 的字节
结果如下:
F1 F2 F3 F4 F5 F6 F7 F8 // 第一块
F9 00 00 00 00 00 00 00 // 第二块
PKCS5Padding
方式:每个填充的字节都记录了填充的总字节数
结果如下:
F1 F2 F3 F4 F5 F6 F7 F8 // 第一块
F9 07 07 07 07 07 07 07 // 第二块
# #对称加密应用
# #基于密钥加密的流程(DES、DESede、AES 和 IDEA)
DES、DESede、AES 和 IDEA 等算法都是基于密钥加密的对称加密算法,它们的实现流程也基本一致。步骤如下:
(1)生成密钥
KeyGenerator kg = KeyGenerator.getInstance("DES");
SecureRandom random = new SecureRandom();
kg.init(random);
SecretKey secretKey = kg.generateKey();建议使用随机数来初始化密钥的生成。
(2)初始化密码对象
Cipher cipher = Cipher.getInstance("DES/ECB/PKCS5Padding");
cipher.init(Cipher.ENCRYPT_MODE, secretKey);ENCRYPT_MODE :加密模式
DECRYPT_MODE :解密模式
(3)执行
String plaintext = "Hello World";
byte[] ciphertext = cipher.doFinal(plaintext.getBytes());一个完整的 DES 加密解密范例
import java.nio.charset.StandardCharsets;
import java.security.*;
import java.util.Base64;
import javax.crypto.*;
import javax.crypto.spec.IvParameterSpec;
/**
* DES安全编码:是经典的对称加密算法。密钥仅56位,且迭代次数偏少。已被视为并不安全的加密算法。
*
* @author Zhang Peng
* @since 2016年7月14日
*/
public class DESCoder {
public static final String KEY_ALGORITHM_DES = "DES";
public static final String CIPHER_DES_DEFAULT = "DES";
public static final String CIPHER_DES_ECB_PKCS5PADDING = "DES/ECB/PKCS5Padding"; // 算法/模式/补码方式
public static final String CIPHER_DES_CBC_PKCS5PADDING = "DES/CBC/PKCS5Padding";
public static final String CIPHER_DES_CBC_NOPADDING = "DES/CBC/NoPadding";
private static final String SEED = "%%%today is nice***"; // 用于生成随机数的种子
private Key key;
private Cipher cipher;
private String transformation;
public DESCoder() throws NoSuchAlgorithmException, NoSuchPaddingException, NoSuchProviderException {
this.key = initKey();
this.cipher = Cipher.getInstance(CIPHER_DES_DEFAULT);
this.transformation = CIPHER_DES_DEFAULT;
}
/**
* 根据随机数种子生成一个密钥
*
* @return Key
* @throws NoSuchAlgorithmException
* @throws NoSuchProviderException
* @author Zhang Peng
* @since 2016年7月14日
*/
private Key initKey() throws NoSuchAlgorithmException, NoSuchProviderException {
// 根据种子生成一个安全的随机数
SecureRandom secureRandom = null;
secureRandom = new SecureRandom(SEED.getBytes());
KeyGenerator keyGen = KeyGenerator.getInstance(KEY_ALGORITHM_DES);
keyGen.init(secureRandom);
return keyGen.generateKey();
}
public DESCoder(String transformation)
throws NoSuchAlgorithmException, NoSuchPaddingException, NoSuchProviderException {
this.key = initKey();
this.cipher = Cipher.getInstance(transformation);
this.transformation = transformation;
}
/**
* 加密
*
* @param input 明文
* @return byte[] 密文
* @throws InvalidKeyException
* @throws IllegalBlockSizeException
* @throws BadPaddingException
* @throws InvalidAlgorithmParameterException
* @author Zhang Peng
* @since 2016年7月20日
*/
public byte[] encrypt(byte[] input) throws InvalidKeyException, IllegalBlockSizeException, BadPaddingException,
InvalidAlgorithmParameterException {
if (transformation.equals(CIPHER_DES_CBC_PKCS5PADDING) || transformation.equals(CIPHER_DES_CBC_NOPADDING)) {
cipher.init(Cipher.ENCRYPT_MODE, key, new IvParameterSpec(getIV()));
} else {
cipher.init(Cipher.ENCRYPT_MODE, key);
}
return cipher.doFinal(input);
}
/**
* 解密
*
* @param input 密文
* @return byte[] 明文
* @throws InvalidKeyException
* @throws IllegalBlockSizeException
* @throws BadPaddingException
* @throws InvalidAlgorithmParameterException
* @author Zhang Peng
* @since 2016年7月20日
*/
public byte[] decrypt(byte[] input) throws InvalidKeyException, IllegalBlockSizeException, BadPaddingException,
InvalidAlgorithmParameterException {
if (transformation.equals(CIPHER_DES_CBC_PKCS5PADDING) || transformation.equals(CIPHER_DES_CBC_NOPADDING)) {
cipher.init(Cipher.DECRYPT_MODE, key, new IvParameterSpec(getIV()));
} else {
cipher.init(Cipher.DECRYPT_MODE, key);
}
return cipher.doFinal(input);
}
private byte[] getIV() {
String iv = "01234567"; // IV length: must be 8 bytes long
return iv.getBytes();
}
public static void main(String[] args) throws Exception {
DESCoder aes = new DESCoder(CIPHER_DES_CBC_PKCS5PADDING);
String msg = "Hello World!";
System.out.println("原文: " + msg);
byte[] encoded = aes.encrypt(msg.getBytes(StandardCharsets.UTF_8));
String encodedBase64 = Base64.getUrlEncoder().encodeToString(encoded);
System.out.println("密文: " + encodedBase64);
byte[] decodedBase64 = Base64.getUrlDecoder().decode(encodedBase64);
byte[] decoded = aes.decrypt(decodedBase64);
System.out.println("明文: " + new String(decoded));
}
}输出
原文: Hello World!
密文: TtnEu9ezNQtxFKpmq_37Qw==
明文: Hello World!# #基于口令加密的流程(PBE)
DES、DESede、AES、IDEA 这几种算法的应用模型几乎如出一辙。
但是,并非所有对称加密算法都是如此。
基于口令加密 (Password Based Encryption, PBE) 是一种基于口令加密的算法。其特点是:口令由用户自己掌管,采用随机数(这里叫做盐)杂凑多重加密等方法保证数据的安全性。
PBE 没有密钥概念,密钥在其他对称加密算法中是经过计算得出的,PBE 则使用口令替代了密钥。
流程:
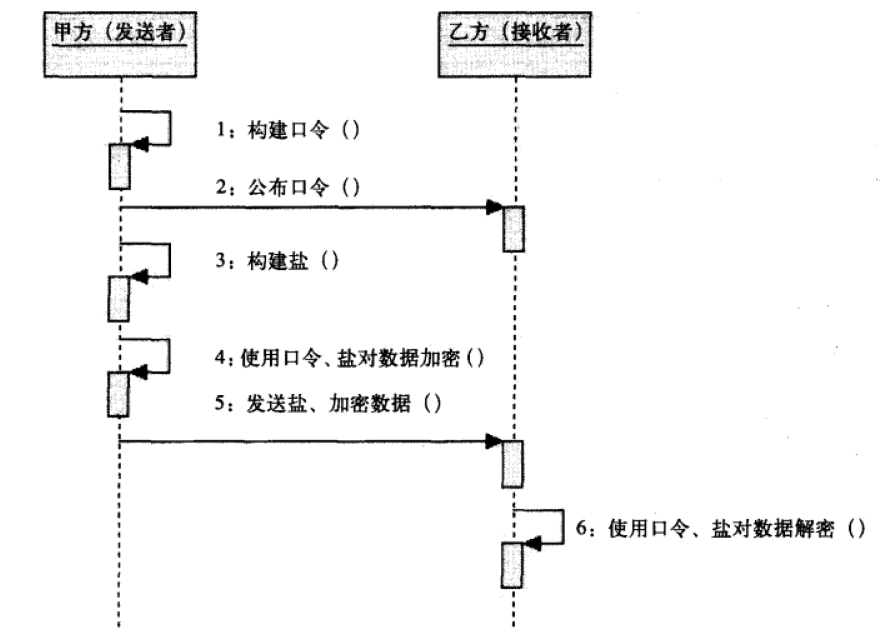
步骤如下:
(1)产生盐
SecureRandom secureRandom = new SecureRandom();
byte[] salt = secureRandom.generateSeed(8); // 盐长度必须为8字节(2)根据密码产生 Key
String password = "123456";
PBEKeySpec keySpec = new PBEKeySpec(password.toCharArray());
SecretKeyFactory keyFactory = SecretKeyFactory.getInstance(KEY_ALGORITHM);
SecretKey secretKey = keyFactory.generateSecret(keySpec);(3)初始化加密或解密对象
PBEParameterSpec paramSpec = new PBEParameterSpec(salt, ITERATION_COUNT);
Cipher cipher = Cipher.getInstance(KEY_ALGORITHM);
cipher.init(Cipher.ENCRYPT_MODE, secretKey, paramSpec);(4)执行
byte[] plaintext = "Hello World".getBytes();
byte[] ciphertext = cipher.doFinal(plaintext);(5)完整 PBE 示例
import java.security.Key;
import java.security.SecureRandom;
import java.util.Base64;
import javax.crypto.Cipher;
import javax.crypto.SecretKey;
import javax.crypto.SecretKeyFactory;
import javax.crypto.spec.PBEKeySpec;
import javax.crypto.spec.PBEParameterSpec;
/**
* 基于口令加密(Password Based Encryption, PBE),是一种对称加密算法。 其特点是:口令由用户自己掌管,采用随机数(这里叫做盐)杂凑多重加密等方法保证数据的安全性。
* PBE没有密钥概念,密钥在其他对称加密算法中是经过计算得出的,PBE则使用口令替代了密钥。
*
* @author Zhang Peng
* @since 2016年7月20日
*/
public class PBECoder {
public static final String KEY_ALGORITHM = "PBEWITHMD5andDES";
public static final int ITERATION_COUNT = 100;
private Key key;
private byte[] salt;
public PBECoder(String password) throws Exception {
this.salt = initSalt();
this.key = initKey(password);
}
private byte[] initSalt() {
SecureRandom secureRandom = new SecureRandom();
return secureRandom.generateSeed(8); // 盐长度必须为8字节
}
private Key initKey(String password) throws Exception {
PBEKeySpec keySpec = new PBEKeySpec(password.toCharArray());
SecretKeyFactory keyFactory = SecretKeyFactory.getInstance(KEY_ALGORITHM);
return keyFactory.generateSecret(keySpec);
}
public byte[] encrypt(byte[] plaintext) throws Exception {
PBEParameterSpec paramSpec = new PBEParameterSpec(salt, ITERATION_COUNT);
Cipher cipher = Cipher.getInstance(KEY_ALGORITHM);
cipher.init(Cipher.ENCRYPT_MODE, key, paramSpec);
return cipher.doFinal(plaintext);
}
public byte[] decrypt(byte[] ciphertext) throws Exception {
PBEParameterSpec paramSpec = new PBEParameterSpec(salt, ITERATION_COUNT);
Cipher cipher = Cipher.getInstance(KEY_ALGORITHM);
cipher.init(Cipher.DECRYPT_MODE, key, paramSpec);
return cipher.doFinal(ciphertext);
}
public static void test1() throws Exception {
// 产生盐
SecureRandom secureRandom = new SecureRandom();
byte[] salt = secureRandom.generateSeed(8); // 盐长度必须为8字节
// 产生Key
String password = "123456";
PBEKeySpec keySpec = new PBEKeySpec(password.toCharArray());
SecretKeyFactory keyFactory = SecretKeyFactory.getInstance(KEY_ALGORITHM);
SecretKey secretKey = keyFactory.generateSecret(keySpec);
PBEParameterSpec paramSpec = new PBEParameterSpec(salt, ITERATION_COUNT);
Cipher cipher = Cipher.getInstance(KEY_ALGORITHM);
cipher.init(Cipher.ENCRYPT_MODE, secretKey, paramSpec);
byte[] plaintext = "Hello World".getBytes();
byte[] ciphertext = cipher.doFinal(plaintext);
new String(ciphertext);
}
public static void main(String[] args) throws Exception {
PBECoder encode = new PBECoder("123456");
String message = "Hello World!";
byte[] ciphertext = encode.encrypt(message.getBytes());
byte[] plaintext = encode.decrypt(ciphertext);
System.out.println("原文:" + message);
System.out.println("密文:" + Base64.getUrlEncoder().encodeToString(ciphertext));
System.out.println("明文:" + new String(plaintext));
}
}# #五、非对称加密
# #非对称加密概述
非对称加密常用算法:DH (Diffie-Hellman,密钥交换算法)、RSA
非对称加密算法和对称加密算法的主要差别在于非对称加密算法用于加密和解密的密钥是不同的。一个公开,称为公钥(public key);一个保密,称为私钥(private key)。因此,非对称加密算法也称为双钥加密算法或公钥加密算法。
非对称加密特点:
- 优点:非对称加密算法解决了对称加密算法的密钥分配问题,并极大地提高了算法安全性。
- 缺点:算法比对称算法更复杂,因此加密、解密速度都比对称算法慢很多。
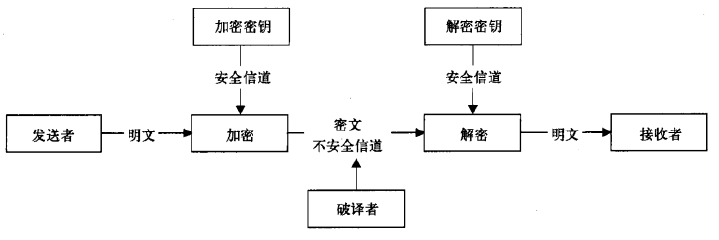
非对称加密算法实现机密信息交换的基本过程是:甲方生成一对密钥并将其中的一把作为公用密钥向其它方公开;得到该公用密钥的乙方使用该密钥对机密信息进行加密后再发送给甲方;甲方再用自己保存的另一把专用密钥对加密后的信息进行解密。
另一方面,甲方可以使用乙方的公钥对机密信息进行签名后再发送给乙方;乙方再用自己的私匙对数据进行验证。
甲方只能用其私钥解密,由其公钥加密后的任何信息。 非对称加密算法的保密性比较好,它消除了最终用户交换密钥的需要。
# #非对称加密算法应用
import java.nio.charset.StandardCharsets;
import java.security.*;
import java.security.spec.PKCS8EncodedKeySpec;
import java.security.spec.X509EncodedKeySpec;
import java.util.Base64;
import javax.crypto.Cipher;
/**
* RSA安全编码:非对称加密算法。它既可以用来加密、解密,也可以用来做数字签名
*
* @author Zhang Peng
* @since 2016年7月20日
*/
public class RSACoder {
public final static String KEY_ALGORITHM = "RSA";
public final static String SIGN_ALGORITHM = "MD5WithRSA";
private KeyPair keyPair;
public RSACoder() throws Exception {
this.keyPair = initKeyPair();
}
private KeyPair initKeyPair() throws Exception {
// KeyPairGenerator类用于生成公钥和私钥对,基于RSA算法生成对象
KeyPairGenerator keyPairGen = KeyPairGenerator.getInstance(KEY_ALGORITHM);
// 初始化密钥对生成器,密钥大小为1024位
keyPairGen.initialize(1024);
// 生成一个密钥对
return keyPairGen.genKeyPair();
}
public byte[] encryptByPrivateKey(byte[] plaintext, byte[] key) throws Exception {
PKCS8EncodedKeySpec keySpec = new PKCS8EncodedKeySpec(key);
KeyFactory keyFactory = KeyFactory.getInstance(KEY_ALGORITHM);
PrivateKey privateKey = keyFactory.generatePrivate(keySpec);
Cipher cipher = Cipher.getInstance(keyFactory.getAlgorithm());
cipher.init(Cipher.ENCRYPT_MODE, privateKey);
return cipher.doFinal(plaintext);
}
public byte[] decryptByPublicKey(byte[] ciphertext, byte[] key) throws Exception {
X509EncodedKeySpec keySpec = new X509EncodedKeySpec(key);
KeyFactory keyFactory = KeyFactory.getInstance(KEY_ALGORITHM);
PublicKey publicKey = keyFactory.generatePublic(keySpec);
Cipher cipher = Cipher.getInstance(keyFactory.getAlgorithm());
cipher.init(Cipher.DECRYPT_MODE, publicKey);
return cipher.doFinal(ciphertext);
}
public byte[] encryptByPublicKey(byte[] plaintext, byte[] key) throws Exception {
X509EncodedKeySpec keySpec = new X509EncodedKeySpec(key);
KeyFactory keyFactory = KeyFactory.getInstance(KEY_ALGORITHM);
PublicKey publicKey = keyFactory.generatePublic(keySpec);
Cipher cipher = Cipher.getInstance(keyFactory.getAlgorithm());
cipher.init(Cipher.ENCRYPT_MODE, publicKey);
return cipher.doFinal(plaintext);
}
public byte[] decryptByPrivateKey(byte[] ciphertext, byte[] key) throws Exception {
PKCS8EncodedKeySpec keySpec = new PKCS8EncodedKeySpec(key);
KeyFactory keyFactory = KeyFactory.getInstance(KEY_ALGORITHM);
PrivateKey privateKey = keyFactory.generatePrivate(keySpec);
Cipher cipher = Cipher.getInstance(keyFactory.getAlgorithm());
cipher.init(Cipher.DECRYPT_MODE, privateKey);
return cipher.doFinal(ciphertext);
}
public byte[] signature(byte[] data, byte[] privateKey, RsaSignTypeEn type) throws Exception {
PKCS8EncodedKeySpec keySpec = new PKCS8EncodedKeySpec(privateKey);
KeyFactory keyFactory = KeyFactory.getInstance(KEY_ALGORITHM);
PrivateKey key = keyFactory.generatePrivate(keySpec);
Signature signature = Signature.getInstance(type.name());
signature.initSign(key);
signature.update(data);
return signature.sign();
}
public byte[] getPrivateKey() {
return keyPair.getPrivate().getEncoded();
}
public boolean verify(byte[] data, byte[] publicKey, byte[] sign, RsaSignTypeEn type) throws Exception {
X509EncodedKeySpec keySpec = new X509EncodedKeySpec(publicKey);
KeyFactory keyFactory = KeyFactory.getInstance(KEY_ALGORITHM);
PublicKey key = keyFactory.generatePublic(keySpec);
Signature signature = Signature.getInstance(type.name());
signature.initVerify(key);
signature.update(data);
return signature.verify(sign);
}
public byte[] getPublicKey() {
return keyPair.getPublic().getEncoded();
}
public enum RsaSignTypeEn {
MD2WithRSA,
MD5WithRSA,
SHA1WithRSA
}
public static void main(String[] args) throws Exception {
String msg = "Hello World!";
RSACoder coder = new RSACoder();
// 私钥加密,公钥解密
byte[] ciphertext = coder.encryptByPrivateKey(msg.getBytes(StandardCharsets.UTF_8), coder.keyPair.getPrivate().getEncoded());
byte[] plaintext = coder.decryptByPublicKey(ciphertext, coder.keyPair.getPublic().getEncoded());
// 公钥加密,私钥解密
byte[] ciphertext2 = coder.encryptByPublicKey(msg.getBytes(), coder.keyPair.getPublic().getEncoded());
byte[] plaintext2 = coder.decryptByPrivateKey(ciphertext2, coder.keyPair.getPrivate().getEncoded());
byte[] sign = coder.signature(msg.getBytes(), coder.getPrivateKey(), RsaSignTypeEn.SHA1WithRSA);
boolean flag = coder.verify(msg.getBytes(), coder.getPublicKey(), sign, RsaSignTypeEn.SHA1WithRSA);
String result = flag ? "数字签名匹配" : "数字签名不匹配";
System.out.println("原文:" + msg);
System.out.println("公钥:" + Base64.getUrlEncoder().encodeToString(coder.keyPair.getPublic().getEncoded()));
System.out.println("私钥:" + Base64.getUrlEncoder().encodeToString(coder.keyPair.getPrivate().getEncoded()));
System.out.println("============== 私钥加密,公钥解密 ==============");
System.out.println("密文:" + Base64.getUrlEncoder().encodeToString(ciphertext));
System.out.println("明文:" + new String(plaintext));
System.out.println("============== 公钥加密,私钥解密 ==============");
System.out.println("密文:" + Base64.getUrlEncoder().encodeToString(ciphertext2));
System.out.println("明文:" + new String(plaintext2));
System.out.println("============== 数字签名 ==============");
System.out.println("数字签名:" + Base64.getUrlEncoder().encodeToString(sign));
System.out.println("验证结果:" + result);
}
}输出
原文:Hello World!
公钥:MIGfMA0GCSqGSIb3DQEBAQUAA4GNADCBiQKBgQCzPtRLErTUcYtr8GmIpvbso7FN18thuEq02U21mh7TA4FH4TjvNgOZrZEORYu94dxrPdnrPjh0p62P5pDIjx_dtGlZr0aGWgtTvBbPwAKE4keXyPqv4VV6iXRzyQ2HdOvFOovim5eu0Tu_TxGeNpFfp0pYj2LXCzpsgSrdUPuPmwIDAQAB
私钥:MIICdwIBADANBgkqhkiG9w0BAQEFAASCAmEwggJdAgEAAoGBALM-1EsStNRxi2vwaYim9uyjsU3Xy2G4SrTZTbWaHtMDgUfhOO82A5mtkQ5Fi73h3Gs92es-OHSnrY_mkMiPH920aVmvRoZaC1O8Fs_AAoTiR5fI-q_hVXqJdHPJDYd068U6i-Kbl67RO79PEZ42kV-nSliPYtcLOmyBKt1Q-4-bAgMBAAECgYBJxOXiL8S0WjajKcKFNxIQuh3Sh6lwgkRcwcI1p0RgW-TtDEg-SuCYctJsKTsl3rq0eDQjmOvrNsc7ngygPidCiTdbD1H6m3tLrebBB-wZdXMSWPsHtQJsq4dE0e93mmfysciOP6QExOs0JqVjTyyBSK37LpUcLdalj2IJDtC0gQJBAPfMngZAuIPmXued7PUuWNBuwxnkmdMcs308eC_9vnLLXWhDB9xKMuXCMwqk16MJ6j1FQWtJu62T21yniWWQHIsCQQC5LWqKfRxVukgnBg0Pa95NVWWY01Yttnb125JsLxeKbR97KU4VgBaBcB9TyUdPr9lxAzGFg6Y3A1wfsfukaGsxAkEA1l719oLXHYSWZdmBvTozK14m-qeBS9lwjc9aSmpB8B1u2Vvj2Pd3wLyYW4Tv5-QT-J2JUr-e1TMseqOVgX-CsQJAETRoBq_zFv_0vjNwuTMTd2nsw5M3GY4vZU5eP1Dsxf63gxDmYVcCQEpzjqxPxNaYxEhArJ_7rHbSc1ts_ux4sQJBAIlbGQC4-92foXGzWT80rsqZlMQ8J8Nbjpoo7RUN9tgx60Vkr3xv26Vos77oqdufWlt5IiBZBS9acTA2suav6Qg=
============== 私钥加密,公钥解密 ==============
密文:qn6iGjSJV45EnH21RYRx2UZfMueqplbm1g3VIpBBQBuF63RdHdSgMJsVPAuB__V0rxpPlU3gR6qLyWu1mpaJ-ix_6KogAH64wqTWqPRh7E6aj767rybNpt9JyVlCmmpy9DiqHAUFWtBJDo34q-a7Fhq9c8bWrJ6jnn47IdmzHfU=
明文:Hello World!
============== 公钥加密,私钥解密 ==============
密文:fsz2IFs69d7JDrH-yoe5pi5WKQU1Zml7SDSpPqTZUn6muSCjNp6x312deQCXKMGSeAdMpVeb01yZBfa0MT_6eYJYVseU7Rd6bDf6YIg3AZFC41yh5ITiTvQ-XzxugnppS12sLpXSWg0faa5qjcVZnoTX9p7nHr8n20y4CNMI6Rw=
明文:Hello World!
============== 数字签名 ==============
数字签名:dTtUUlWX1wRQbW1PcA8O6WJcWcrHinEZRXwgLKEwBOm2DpvHnynvV_HYKS-qFE5_4vJQcPGJ2hZqWbfv1VKLHMUWuiXM7VJk70g3g7BF8i8RWbrCDOxgTR77jrEwidpr1PYJzWJVGq_HP36MxInGFLcVh2sN0fu8MppzsXUENZQ=
验证结果:数字签名匹配# #六、术语
- 明文 (Plaintext):指待加密信息。明文可以是文本文件、图片文件、二进制数据等。
- 密文 (Ciphertext):指经过加密后的明文。密文通常以文本、二进制等形式存在。
- 加密 (Encryption):指将明文转换为密文的过程。
- 解密 (Decryption):指将密文转换为明文的过程。
- 加密密钥 (Encryption Key):指通过加密算法进行加密操作用的密钥。
- 解密密钥 (Decryption Key):指通过解密算法进行解密操作用的密钥。
- 信道 (Channel):通信的通道,是信号传输的媒介。
# Java 本地化
📦 本文以及示例源码已归档在 javacore(opens new window)
# #背景知识
通讯的发达,使得世界各地交流越来越紧密。许多的软件产品也要面向世界上不同国家的用户。其中,语言障碍显然是产品在不同语种用户中进行推广的一个重要问题。
本文围绕本地化这一主题,先介绍国际标准的语言编码,然后讲解在 Java 应用中如何去实现本地化。
# #语言编码、国家 / 地区编码
做 web 开发的朋友可能多多少少接触过类似 zh-cn, en-us 这样的编码字样。
这些编码是用来表示指定的国家地区的语言类型的。那么,这些含有特殊含义的编码是如何产生的呢?
ISO-639 (opens new window) 标准使用编码定义了国际上常见的语言,每一种语言由两个小写字母表示。
ISO-3166 (opens new window) 标准使用编码定义了国家 / 地区,每个国家 / 地区由两个大写字母表示。
下表列举了一些常见国家、地区的语言编码:
| 国家 / 地区 | 语言编码 | 国家 / 地区 | 语言编码 |
|---|---|---|---|
| 简体中文 (中国) | zh-cn | 繁体中文 (台湾地区) | zh-tw |
| 繁体中文 (香港) | zh-hk | 英语 (香港) | en-hk |
| 英语 (美国) | en-us | 英语 (英国) | en-gb |
| 英语 (全球) | en-ww | 英语 (加拿大) | en-ca |
| 英语 (澳大利亚) | en-au | 英语 (爱尔兰) | en-ie |
| 英语 (芬兰) | en-fi | 芬兰语 (芬兰) | fi-fi |
| 英语 (丹麦) | en-dk | 丹麦语 (丹麦) | da-dk |
| 英语 (以色列) | en-il | 希伯来语 (以色列) | he-il |
| 英语 (南非) | en-za | 英语 (印度) | en-in |
| 英语 (挪威) | en-no | 英语 (新加坡) | en-sg |
| 英语 (新西兰) | en-nz | 英语 (印度尼西亚) | en-id |
| 英语 (菲律宾) | en-ph | 英语 (泰国) | en-th |
| 英语 (马来西亚) | en-my | 英语 (阿拉伯) | en-xa |
| 韩文 (韩国) | ko-kr | 日语 (日本) | ja-jp |
| 荷兰语 (荷兰) | nl-nl | 荷兰语 (比利时) | nl-be |
| 葡萄牙语 (葡萄牙) | pt-pt | 葡萄牙语 (巴西) | pt-br |
| 法语 (法国) | fr-fr | 法语 (卢森堡) | fr-lu |
| 法语 (瑞士) | fr-ch | 法语 (比利时) | fr-be |
| 法语 (加拿大) | fr-ca | 西班牙语 (拉丁美洲) | es-la |
| 西班牙语 (西班牙) | es-es | 西班牙语 (阿根廷) | es-ar |
| 西班牙语 (美国) | es-us | 西班牙语 (墨西哥) | es-mx |
| 西班牙语 (哥伦比亚) | es-co | 西班牙语 (波多黎各) | es-pr |
| 德语 (德国) | de-de | 德语 (奥地利) | de-at |
| 德语 (瑞士) | de-ch | 俄语 (俄罗斯) | ru-ru |
| 意大利语 (意大利) | it-it | 希腊语 (希腊) | el-gr |
| 挪威语 (挪威) | no-no | 匈牙利语 (匈牙利) | hu-hu |
| 土耳其语 (土耳其) | tr-tr | 捷克语 (捷克共和国) | cs-cz |
| 斯洛文尼亚语 | sl-sl | 波兰语 (波兰) | pl-pl |
| 瑞典语 (瑞典) | sv-se |
注:由表中可以看出语言、国家 / 地区编码一般都是英文单词的缩写。
# #字符编码
在此处,引申一下字符编码的概念。
是不是有了语言、国家 / 地区编码,计算机就可以识别各种语言了?
答案是否。作为程序员,相信每个人都会遇到过这样的情况:期望打印中文,结果输出的却是乱码。
这种情况,往往是因为字符编码的问题。
计算机在设计之初,并没有考虑多个国家,多种不同语言的应用场景。当时定义一种 ASCII 码,将字母、数字和其他符号编号用 7 比特的二进制数来表示。后来,计算机在世界开始普及,为了适应多种文字,出现了多种编码格式,例如中文汉字一般使用的编码格式为 GB2312 、 GBK 。
由此,又产生了一个问题,不同字符编码之间互相无法识别。于是,为了一统江湖,出现了 unicode 编码。它为每种语言的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台的文本转换需求。
有人不禁要问,既然 Unicode 可以支持所有语言的字符,那还要其他字符编码做什么?
Unicode 有一个缺点:为了支持所有语言的字符,所以它需要用更多位数去表示,比如 ASCII 表示一个英文字符只需要一个字节,而 Unicode 则需要两个字节。很明显,如果字符数多,这样的效率会很低。
为了解决这个问题,有出现了一些中间格式的字符编码:如 UTF-8 、 UTF-16 、 UTF-32 等(中国的程序员一般使用 UTF-8 编码)。
# #Java 中实现本地化
本地化的实现原理很简单:
- 先定义好不同语种的模板;
- 选择语种;
- 加载指定语种的模板。
接下来,本文会按照步骤逐一讲解实现本地化的具体步骤
# #定义不同语种的模板
Java 中将多语言文本存储在格式为 properties 的资源文件中。
它必须遵照以下的命名规范:
<资源名>_<语言代码>_<国家/地区编码>.properties其中,语言编码和国家 / 地区编码都是可选的。
注: <资源名>.properties 命名的本地化资源文件是默认的资源文件,即某个本地化类型在系统中找不到对应的资源文件,就采用这个默认的资源文件。
# #定义 properties 文件
在 src/main/resources/locales 路径下定义名为 content 的不同语种资源文件:
content_en_US.properties
helloWorld = HelloWorld!
time = The current time is %s.content_zh_CN.properties
helloWorld = \u4e16\u754c\uff0c\u4f60\u597d\uff01
time = \u5f53\u524d\u65f6\u95f4\u662f\u0025\u0073\u3002可以看到:几个资源文件中,定义的 Key 完全一致,只是 Value 是对应语言的字符串。
虽然属性值各不相同,但属性名却是相同的,这样应用程序就可以通过 Locale 对象和属性名精确调用到某个具体的属性值了。
# #Unicode 转换工具
上一节中,我们定义的中文资源文件中的属性值都是以 \u 开头的四位 16 进制数。其实,这表示的是一个 Unicode 编码。
helloWorld = \u4e16\u754c\uff0c\u4f60\u597d\uff01
time = \u5f53\u524d\u65f6\u95f4\u662f\u0025\u0073\u3002本文的字符编码中提到了,为了达到跨编码也正常显示的目的,有必要将非 ASCII 字符转为 Unicode 编码。上面的中文资源文件就是中文转为 Unicode 的结果。
怎么将非 ASCII 字符转为 Unicode 编码呢?
JDK 在 bin 目录下为我们提供了一个转换工具:native2ascii。
它可以将中文字符的资源文件转换为 Unicode 代码格式的文件,命令格式如下:
native2ascii [-reverse] [-encoding 编码] [输入文件 [输出文件]]假设 content_zh_CN.properties 在 d:\ 目录。执行以下命令可以新建一个名为 content_zh_CN_new.properties 的文件,其中的内容就中文字符转为 UTF-8 编码格式的结果。
native2ascii -encoding utf-8 d:\content_zh_CN.properties d:\content_zh_CN_new.properties# #选择语种
定义了多语言资源文件,第二步就是根据本地语种选择模板文件了。
# #Locale
在 Java 中,一个 java.util.Locale 对象表示了特定的地理、政治和文化地区。需要 Locale 来执行其任务的操作称为语言环境敏感的操作,它使用 Locale 为用户量身定制本地信息。
它有三个构造方法
Locale(String language) :根据语言编码初始化 Locale(String language, String country) :根据语言编码、国家编码初始化 Locale(String language, String country, String variant) :根据语言编码、国家编码、变体初始化
此外,Locale 定义了一些常用的 Locale 常量: Locale.ENGLISH 、 Locale.CHINESE 等。
// 初始化一个通用英语的locale.
Locale locale1 = new Locale("en");
// 初始化一个加拿大英语的locale.
Locale locale2 = new Locale("en", "CA");
// 初始化一个美式英语变种硅谷英语的locale
Locale locale3 = new Locale("en", "US", "SiliconValley");
// 根据Locale常量初始化一个简体中文
Locale locale4 = Locale.SIMPLIFIED_CHINESE;# #加载指定语种的模板
# #ResourceBoundle
Java 为我们提供了用于加载本地化资源文件的工具类: java.util.ResourceBoundle 。
ResourceBoundle 提供了多个名为 getBundle 的静态重载方法,这些方法的作用是用来根据资源名、Locale 选择指定语种的资源文件。需要说明的是: getBundle 方法的第一个参数一般都是 baseName ,这个参数表示资源文件名。
ResourceBoundle 还提供了名为 getString 的方法,用来获取资源文件中 key 对应的 value。
public static void main(String[] args) {
// 根据语言+地区编码初始化
ResourceBundle rbUS = ResourceBundle.getBundle("locales.content", new Locale("en", "US"));
// 根据Locale常量初始化
ResourceBundle rbZhCN = ResourceBundle.getBundle("locales.content", Locale.SIMPLIFIED_CHINESE);
// 获取本地系统默认的Locale初始化
ResourceBundle rbDefault = ResourceBundle.getBundle("locales.content");
// ResourceBundle rbDefault =ResourceBundle.getBundle("locales.content", Locale.getDefault()); // 与上行代码等价
System.out.println("us-US:" + rbUS.getString("helloWorld"));
System.out.println("us-US:" + String.format(rbUS.getString("time"), "08:00"));
System.out.println("zh-CN:" + rbZhCN.getString("helloWorld"));
System.out.println("zh-CN:" + String.format(rbZhCN.getString("time"), "08:00"));
System.out.println("default:" + rbDefault.getString("helloWorld"));
System.out.println("default:" + String.format(rbDefault.getString("time"), "08:00"));
}输出
us-US:HelloWorld!
us-US:The current time is 08:00.
zh-CN:世界,你好!
zh-CN:当前时间是08:00。
default:世界,你好!
default:当前时间是08:00。注:在加载资源时,如果指定的本地化资源文件不存在,它会尝试按下面的顺序加载其他的资源:本地系统默认本地化对象对应的资源 -> 默认的资源。如果指定错误,Java 会提示找不到资源文件。
# #支持本地化的工具类
Java 中也提供了几个支持本地化的格式化工具类。例如: NumberFormat 、 DateFormat 、 MessageFormat
# #NumberFormat
NumberFormat 是所有数字格式类的基类。它提供格式化和解析数字的接口。它也提供了决定数字所属语言类型的方法。
public static void main(String[] args) {
double num = 123456.78;
NumberFormat format = NumberFormat.getCurrencyInstance(Locale.SIMPLIFIED_CHINESE);
System.out.format("%f 的本地化(%s)结果: %s", num, Locale.SIMPLIFIED_CHINESE, format.format(num));
}# #DateFormat
DateFormat 是日期、时间格式化类的抽象类。它支持基于语言习惯的日期、时间格式。
public static void main(String[] args) {
Date date = new Date();
DateFormat df = DateFormat.getDateInstance(DateFormat.MEDIUM, Locale.ENGLISH);
DateFormat df2 = DateFormat.getDateInstance(DateFormat.MEDIUM, Locale.SIMPLIFIED_CHINESE);
System.out.format("%s 的本地化(%s)结果: %s\n", date, Locale.SIMPLIFIED_CHINESE, df.format(date));
System.out.format("%s 的本地化(%s)结果: %s\n", date, Locale.SIMPLIFIED_CHINESE, df2.format(date));
}# #MessageFormat
Messageformat 提供一种与语言无关的拼接消息的方式。通过这种拼接方式,将最终呈现返回给使用者。
public static void main(String[] args) {
String pattern1 = "{0},你好!你于 {1} 消费 {2} 元。";
String pattern2 = "At {1,time,short} On {1,date,long},{0} paid {2,number, currency}.";
Object[] params = {"Jack", new GregorianCalendar().getTime(), 8888};
String msg1 = MessageFormat.format(pattern1, params);
MessageFormat mf = new MessageFormat(pattern2, Locale.US);
String msg2 = mf.format(params);
System.out.println(msg1);
System.out.println(msg2);
}# JDK8 入门指南
JDK8 升级常见问题章节是我个人的经验整理。其他内容基本翻译自 java8-tutorial(opens new window)
📦 本文以及示例源码已归档在 javacore(opens new window)
关键词:
Stream、lambda、Optional、@FunctionalInterface
# #Default Methods for Interfaces (接口的默认方法)
Java 8 使我们能够通过使用 default 关键字将非抽象方法实现添加到接口。这个功能也被称为虚拟扩展方法。
这是我们的第一个例子:
interface Formula {
double calculate(int a);
default double sqrt(int a) {
return Math.sqrt(a);
}
}除了抽象方法 calculate ,接口 Formula 还定义了默认方法 sqrt 。具体类只需要执行抽象方法计算。默认的方法 sqrt 可以用于开箱即用。
Formula formula = new Formula() {
@Override
public double calculate(int a) {
return sqrt(a * 100);
}
};
formula.calculate(100); // 100.0
formula.sqrt(16); // 4.0Formula 被实现为一个匿名对象。代码非常冗长:用于 sqrt(a * 100) 这样简单的计算的 6 行代码。正如我们将在下一节中看到的,在 Java 8 中实现单个方法对象有更好的方法。
# #Lambda expressions (Lambda 表达式)
让我们从一个简单的例子来说明如何在以前版本的 Java 中对字符串列表进行排序:
List<String> names = Arrays.asList("peter", "anna", "mike", "xenia");
Collections.sort(names, new Comparator<String>() {
@Override
public int compare(String a, String b) {
return b.compareTo(a);
}
});静态工具方法 Collections.sort 为了对指定的列表进行排序,接受一个列表和一个比较器。您会发现自己经常需要创建匿名比较器并将其传递给排序方法。
Java 8 使用更简短的 lambda 表达式来避免常常创建匿名对象的问题:
Collections.sort(names, (String a, String b) -> {
return b.compareTo(a);
});如您所见,这段代码比上段代码简洁很多。但是,还可以更加简洁:
Collections.sort(names, (String a, String b) -> b.compareTo(a));这行代码中,你省去了花括号 {} 和 return 关键字。但是,这还不算完,它还可以再进一步简洁:
names.sort((a, b) -> b.compareTo(a));列表现在有一个 sort 方法。此外,java 编译器知道参数类型,所以你可以不指定入参的数据类型。让我们深入探讨如何使用 lambda 表达式。
# #Functional Interfaces (函数接口)
lambda 表达式如何适应 Java 的类型系统?每个 lambda 对应一个由接口指定的类型。一个所谓的函数接口必须包含一个抽象方法声明。该类型的每个 lambda 表达式都将与此抽象方法匹配。由于默认方法不是抽象的,所以你可以自由地添加默认方法到你的函数接口。
只要保证接口仅包含一个抽象方法,就可以使用任意的接口作为 lambda 表达式。为确保您的接口符合要求,您应该添加 @FunctionalInterface 注解。编译器注意到这个注解后,一旦您尝试在接口中添加第二个抽象方法声明,编译器就会抛出编译器错误。
示例:
@FunctionalInterface
interface Converter<F, T> {
T convert(F from);
}
Converter<String, Integer> converter = (from) -> Integer.valueOf(from);
Integer converted = converter.convert("123");
System.out.println(converted); // 123请记住,如果 @FunctionalInterface 注解被省略,代码也是有效的。
# #Method and Constructor References (方法和构造器引用)
上面的示例代码可以通过使用静态方法引用进一步简化:
Converter<String, Integer> converter = Integer::valueOf;
Integer converted = converter.convert("123");
System.out.println(converted); // 123Java 8 允许您通过 :: 关键字传递方法或构造函数的引用。上面的例子展示了如何引用一个静态方法。但是我们也可以引用对象方法:
class Something {
String startsWith(String s) {
return String.valueOf(s.charAt(0));
}
}
Something something = new Something();
Converter<String, String> converter = something::startsWith;
String converted = converter.convert("Java");
System.out.println(converted); // "J"我们来观察一下 :: 关键字是如何作用于构造器的。首先,我们定义一个有多个构造器的示例类。
class Person {
String firstName;
String lastName;
Person() {}
Person(String firstName, String lastName) {
this.firstName = firstName;
this.lastName = lastName;
}
}接着,我们指定一个用于创建 Person 对象的 PersonFactory 接口。
interface PersonFactory<P extends Person> {
P create(String firstName, String lastName);
}我们不是手动实现工厂,而是通过构造引用将所有东西粘合在一起:
PersonFactory<Person> personFactory = Person::new;
Person person = personFactory.create("Peter", "Parker");我们通过 Person::new 来创建一个 Person 构造器的引用。Java 编译器会根据 PersonFactory.create 的签名自动匹配正确的构造器。
# #Lambda Scopes (Lambda 作用域)
从 lambda 表达式访问外部作用域变量与匿名对象非常相似。您可以访问本地外部作用域的常量以及实例的成员变量和静态变量。
# #Accessing local variables (访问本地变量)
我们可以访问 lambda 表达式作用域外部的常量:
final int num = 1;
Converter<Integer, String> stringConverter =
(from) -> String.valueOf(from + num);
stringConverter.convert(2); // 3不同于匿名对象的是:这个变量 num 不是一定要被 final 修饰。下面的代码一样合法:
int num = 1;
Converter<Integer, String> stringConverter =
(from) -> String.valueOf(from + num);
stringConverter.convert(2); // 3但是, num 必须是隐式常量的。下面的代码不能编译通过:
int num = 1;
Converter<Integer, String> stringConverter =
(from) -> String.valueOf(from + num);
num = 3;此外,在 lambda 表达式中对 num 做写操作也是被禁止的。
# #Accessing fields and static variables (访问成员变量和静态变量)
与局部变量相比,我们既可以在 lambda 表达式中读写实例的成员变量,也可以读写实例的静态变量。这种行为在匿名对象中是众所周知的。
class Lambda4 {
static int outerStaticNum;
int outerNum;
void testScopes() {
Converter<Integer, String> stringConverter1 = (from) -> {
outerNum = 23;
return String.valueOf(from);
};
Converter<Integer, String> stringConverter2 = (from) -> {
outerStaticNum = 72;
return String.valueOf(from);
};
}
}# #Accessing Default Interface Methods(访问默认的接口方法)
还记得第一节的 formula 例子吗? Formula 接口定义了一个默认方法 sqrt ,它可以被每个 formula 实例(包括匿名对象)访问。这个特性不适用于 lambda 表达式。
默认方法不能被 lambda 表达式访问。下面的代码不能编译通过:
Formula formula = (a) -> sqrt(a * 100);# #Built-in Functional Interfaces (内置函数接口)
JDK 1.8 API 包含许多内置的功能接口。它们中的一些在较早的 Java 版本(比如 Comparator 或 Runnable )中是众所周知的。这些现有的接口通过 @FunctionalInterfaceannotation 注解被扩展为支持 Lambda。
但是,Java 8 API 也提供了不少新的函数接口。其中一些新接口在 Google Guava (opens new window) 库中是众所周知的。即使您熟悉这个库,也应该密切关注如何通过一些有用的方法扩展来扩展这些接口。
# #Predicates
Predicate 是只有一个参数的布尔值函数。该接口包含各种默认方法,用于将谓词组合成复杂的逻辑术语(与、或、非)
Predicate<String> predicate = (s) -> s.length() > 0;
predicate.test("foo"); // true
predicate.negate().test("foo"); // false
Predicate<Boolean> nonNull = Objects::nonNull;
Predicate<Boolean> isNull = Objects::isNull;
Predicate<String> isEmpty = String::isEmpty;
Predicate<String> isNotEmpty = isEmpty.negate();# #Functions
Function 接受一个参数并产生一个结果。可以使用默认方法将多个函数链接在一起(compose、andThen)。
Function<String, Integer> toInteger = Integer::valueOf;
Function<String, String> backToString = toInteger.andThen(String::valueOf);
backToString.apply("123"); // "123"# #Suppliers
Supplier 产生一个泛型结果。与 Function 不同, Supplier 不接受参数。
Supplier<Person> personSupplier = Person::new;
personSupplier.get(); // new Person# #Consumers
Consumer 表示要在一个输入参数上执行的操作。
Consumer<Person> greeter = (p) -> System.out.println("Hello, " + p.firstName);
greeter.accept(new Person("Luke", "Skywalker"));# #Comparators
比较器在老版本的 Java 中是众所周知的。 Java 8 为接口添加了各种默认方法。
Comparator<Person> comparator = (p1, p2) -> p1.firstName.compareTo(p2.firstName);
Person p1 = new Person("John", "Doe");
Person p2 = new Person("Alice", "Wonderland");
comparator.compare(p1, p2); // > 0
comparator.reversed().compare(p1, p2); // < 0# #Optionals
Optional 不是功能性接口,而是防止 NullPointerException 的好工具。这是下一节的一个重要概念,所以让我们快速看看 Optional 是如何工作的。
Optional 是一个简单的容器,其值可以是 null 或非 null。想想一个可能返回一个非空结果的方法,但有时候什么都不返回。不是返回 null,而是返回 Java 8 中的 Optional 。
Optional<String> optional = Optional.of("bam");
optional.isPresent(); // true
optional.get(); // "bam"
optional.orElse("fallback"); // "bam"
optional.ifPresent((s) -> System.out.println(s.charAt(0))); // "b"# #Streams
java.util.Stream 表示可以在其上执行一个或多个操作的元素序列。流操作是中间或终端。当终端操作返回一个特定类型的结果时,中间操作返回流本身,所以你可以链接多个方法调用。流在源上创建,例如一个 java.util.Collection 像列表或集合(不支持映射)。流操作既可以按顺序执行,也可以并行执行。
流是非常强大的,所以,我写了一个独立的 Java8 Streams 教程 (opens new window)。您还应该查看 Sequent,将其作为 Web 的类似库。
我们先来看看顺序流如何工作。首先,我们以字符串列表的形式创建一个示例源代码:
List<String> stringCollection = new ArrayList<>();
stringCollection.add("ddd2");
stringCollection.add("aaa2");
stringCollection.add("bbb1");
stringCollection.add("aaa1");
stringCollection.add("bbb3");
stringCollection.add("ccc");
stringCollection.add("bbb2");
stringCollection.add("ddd1");Java 8 中的集合已被扩展,因此您可以通过调用 Collection.stream() 或 Collection.parallelStream() 来简单地创建流。以下各节介绍最常见的流操作。
# #Filter
过滤器接受一个谓词来过滤流的所有元素。这个操作是中间的,使我们能够调用另一个流操作( forEach )的结果。 ForEach 接受一个消费者被执行的过滤流中的每个元素。 ForEach 是一个终端操作。它是无效的,所以我们不能调用另一个流操作。
stringCollection
.stream()
.filter((s) -> s.startsWith("a"))
.forEach(System.out::println);
// "aaa2", "aaa1"# #Sorted
排序是一个中间操作,返回流的排序视图。元素按自然顺序排序,除非您传递自定义比较器。
stringCollection
.stream()
.sorted()
.filter((s) -> s.startsWith("a"))
.forEach(System.out::println);
// "aaa1", "aaa2"请记住,排序只会创建流的排序视图,而不会操纵支持的集合的排序。 stringCollection 的排序是不变的:
System.out.println(stringCollection);
// ddd2, aaa2, bbb1, aaa1, bbb3, ccc, bbb2, ddd1# #Map
中间操作映射通过给定函数将每个元素转换为另一个对象。以下示例将每个字符串转换为大写字母字符串。但是您也可以使用 map 将每个对象转换为另一种类型。结果流的泛型类型取决于您传递给 map 的函数的泛型类型。
stringCollection
.stream()
.map(String::toUpperCase)
.sorted((a, b) -> b.compareTo(a))
.forEach(System.out::println);
// "DDD2", "DDD1", "CCC", "BBB3", "BBB2", "AAA2", "AAA1"# #Match
可以使用各种匹配操作来检查某个谓词是否与流匹配。所有这些操作都是终端并返回布尔结果。
boolean anyStartsWithA =
stringCollection
.stream()
.anyMatch((s) -> s.startsWith("a"));
System.out.println(anyStartsWithA); // true
boolean allStartsWithA =
stringCollection
.stream()
.allMatch((s) -> s.startsWith("a"));
System.out.println(allStartsWithA); // false
boolean noneStartsWithZ =
stringCollection
.stream()
.noneMatch((s) -> s.startsWith("z"));
System.out.println(noneStartsWithZ); // true# #Count
Count 是一个终端操作,返回流中元素的个数。
long startsWithB =
stringCollection
.stream()
.filter((s) -> s.startsWith("b"))
.count();
System.out.println(startsWithB); // 3# #Reduce
该终端操作使用给定的功能对流的元素进行缩减。结果是一个 Optional 持有缩小后的值。
Optional<String> reduced =
stringCollection
.stream()
.sorted()
.reduce((s1, s2) -> s1 + "#" + s2);
reduced.ifPresent(System.out::println);
// "aaa1##aaa2##bbb1##bbb2##bbb3##ccc##ddd1##ddd2"# #Parallel Streams
如上所述,流可以是顺序的也可以是并行的。顺序流上的操作在单个线程上执行,而并行流上的操作在多个线程上同时执行。
以下示例演示了通过使用并行流提高性能是多么容易。
首先,我们创建一个较大的独特元素的列表:
int max = 1000000;
List<String> values = new ArrayList<>(max);
for (int i = 0; i < max; i++) {
UUID uuid = UUID.randomUUID();
values.add(uuid.toString());
}现在我们测量对这个集合进行排序所花费的时间。
# #Sequential Sort
long t0 = System.nanoTime();
long count = values.stream().sorted().count();
System.out.println(count);
long t1 = System.nanoTime();
long millis = TimeUnit.NANOSECONDS.toMillis(t1 - t0);
System.out.println(String.format("sequential sort took: %d ms", millis));
// sequential sort took: 899 ms# #Parallel Sort
long t0 = System.nanoTime();
long count = values.parallelStream().sorted().count();
System.out.println(count);
long t1 = System.nanoTime();
long millis = TimeUnit.NANOSECONDS.toMillis(t1 - t0);
System.out.println(String.format("parallel sort took: %d ms", millis));
// parallel sort took: 472 ms如你所见,两个代码段差不多,但是并行排序快了近 50%。你所需做的仅仅是将 stream() 改为 parallelStream() 。
# #Maps
如前所述,map 不直接支持流。Map 接口本身没有可用的 stream() 方法,但是你可以通过 map.keySet().stream() 、 map.values().stream() 和 map.entrySet().stream() 创建指定的流。
此外,map 支持各种新的、有用的方法来处理常见任务。
Map<Integer, String> map = new HashMap<>();
for (int i = 0; i < 10; i++) {
map.putIfAbsent(i, "val" + i);
}
map.forEach((id, val) -> System.out.println(val));上面的代码应该是自我解释的: putIfAbsent 阻止我们写入额外的空值检查; forEach 接受消费者为 map 的每个值实现操作。
这个例子展示了如何利用函数来计算 map 上的代码:
map.computeIfPresent(3, (num, val) -> val + num);
map.get(3); // val33
map.computeIfPresent(9, (num, val) -> null);
map.containsKey(9); // false
map.computeIfAbsent(23, num -> "val" + num);
map.containsKey(23); // true
map.computeIfAbsent(3, num -> "bam");
map.get(3); // val33接下来,我们学习如何删除给定键的条目,只有当前键映射到给定值时:
map.remove(3, "val3");
map.get(3); // val33
map.remove(3, "val33");
map.get(3); // null另一个有用方法:
map.getOrDefault(42, "not found"); // not found合并一个 map 的 entry 很简单:
map.merge(9, "val9", (value, newValue) -> value.concat(newValue));
map.get(9); // val9
map.merge(9, "concat", (value, newValue) -> value.concat(newValue));
map.get(9); // val9concat如果不存在该键的条目,合并或者将键 / 值放入 map 中;否则将调用合并函数来更改现有值。
# #Date API
Java 8 在 java.time 包下新增了一个全新的日期和时间 API。新的日期 API 与 Joda-Time (opens new window) 库相似,但不一样。以下示例涵盖了此新 API 的最重要部分。
# #Clock
Clock 提供对当前日期和时间的访问。 Clock 知道一个时区,可以使用它来代替 System.currentTimeMillis() ,获取从 Unix EPOCH 开始的以毫秒为单位的当前时间。时间线上的某一时刻也由类 Instant 表示。 Instants 可以用来创建遗留的 java.util.Date 对象。
Clock clock = Clock.systemDefaultZone();
long millis = clock.millis();
Instant instant = clock.instant();
Date legacyDate = Date.from(instant); // legacy java.util.Date# #Timezones
时区由 ZoneId 表示。他们可以很容易地通过静态工厂方法访问。时区定义了某一时刻和当地日期、时间之间转换的重要偏移量。
System.out.println(ZoneId.getAvailableZoneIds());
// prints all available timezone ids
ZoneId zone1 = ZoneId.of("Europe/Berlin");
ZoneId zone2 = ZoneId.of("Brazil/East");
System.out.println(zone1.getRules());
System.out.println(zone2.getRules());
// ZoneRules[currentStandardOffset=+01:00]
// ZoneRules[currentStandardOffset=-03:00]# #LocalTime
LocalTime 代表没有时区的时间,例如晚上 10 点或 17:30:15。以下示例为上面定义的时区创建两个本地时间。然后我们比较两次,并计算两次之间的小时和分钟的差异。
LocalTime now1 = LocalTime.now(zone1);
LocalTime now2 = LocalTime.now(zone2);
System.out.println(now1.isBefore(now2)); // false
long hoursBetween = ChronoUnit.HOURS.between(now1, now2);
long minutesBetween = ChronoUnit.MINUTES.between(now1, now2);
System.out.println(hoursBetween); // -3
System.out.println(minutesBetween); // -239LocalTime 带有各种工厂方法,以简化新实例的创建,包括解析时间字符串。
LocalTime late = LocalTime.of(23, 59, 59);
System.out.println(late); // 23:59:59
DateTimeFormatter germanFormatter =
DateTimeFormatter
.ofLocalizedTime(FormatStyle.SHORT)
.withLocale(Locale.GERMAN);
LocalTime leetTime = LocalTime.parse("13:37", germanFormatter);
System.out.println(leetTime); // 13:37# #LocalDate
LocalDate 表示不同的日期,例如:2014 年 3 月 11 日。它是不可变的,并且与 LocalTime 完全类似。该示例演示如何通过加减日、月或年来计算新日期。请记住,每个操作都会返回一个新的实例。
LocalDate today = LocalDate.now();
LocalDate tomorrow = today.plus(1, ChronoUnit.DAYS);
LocalDate yesterday = tomorrow.minusDays(2);
LocalDate independenceDay = LocalDate.of(2014, Month.JULY, 4);
DayOfWeek dayOfWeek = independenceDay.getDayOfWeek();
System.out.println(dayOfWeek); // FRIDAY从一个字符串中解析出 LocalDate 对象,和解析 LocalTime 一样的简单:
DateTimeFormatter germanFormatter =
DateTimeFormatter
.ofLocalizedDate(FormatStyle.MEDIUM)
.withLocale(Locale.GERMAN);
LocalDate xmas = LocalDate.parse("24.12.2014", germanFormatter);
System.out.println(xmas); // 2014-12-24# #LocalDateTime
LocalDateTime 表示日期时间。它将日期和时间组合成一个实例。 LocalDateTime 是不可变的,其作用类似于 LocalTime 和 LocalDate 。我们可以利用方法去获取日期时间中某个单位的值。
LocalDateTime sylvester = LocalDateTime.of(2014, Month.DECEMBER, 31, 23, 59, 59);
DayOfWeek dayOfWeek = sylvester.getDayOfWeek();
System.out.println(dayOfWeek); // WEDNESDAY
Month month = sylvester.getMonth();
System.out.println(month); // DECEMBER
long minuteOfDay = sylvester.getLong(ChronoField.MINUTE_OF_DAY);
System.out.println(minuteOfDay); // 1439通过一个时区的附加信息可以转为一个实例。这个实例很容易转为 java.util.Date 类型。
Instant instant = sylvester
.atZone(ZoneId.systemDefault())
.toInstant();
Date legacyDate = Date.from(instant);
System.out.println(legacyDate); // Wed Dec 31 23:59:59 CET 2014日期时间的格式化类似于 Date 或 Time。我们可以使用自定义模式创建格式化程序,而不是使用预定义的格式。
DateTimeFormatter formatter =
DateTimeFormatter
.ofPattern("MMM dd, yyyy - HH:mm");
LocalDateTime parsed = LocalDateTime.parse("Nov 03, 2014 - 07:13", formatter);
String string = formatter.format(parsed);
System.out.println(string); // Nov 03, 2014 - 07:13不同于 java.text.NumberFormat , DateTimeFormatter 是不可变且线程安全的 。
更多关于日期格式化的内容可以参考这里 (opens new window).
# #Annotations
Java 8 中的注释是可重复的。让我们直接看一个例子来解决这个问题。
首先,我们定义一个包含实际注释数组的外层注释:
@interface Hints {
Hint[] value();
}
@Repeatable(Hints.class)
@interface Hint {
String value();
}Java8 允许我们通过使用 @Repeatable 注解来引入多个同类型的注解。
# #Variant 1: 使用容器注解 (老套路)
@Hints({@Hint("hint1"), @Hint("hint2")})
class Person {}# #Variant 2: 使用 repeatable 注解 (新套路)
@Hint("hint1")
@Hint("hint2")
class Person {}使用场景 2,Java 编译器隐式地设置了 @Hints 注解。
这对于通过反射来读取注解信息很重要。
Hint hint = Person.class.getAnnotation(Hint.class);
System.out.println(hint); // null
Hints hints1 = Person.class.getAnnotation(Hints.class);
System.out.println(hints1.value().length); // 2
Hint[] hints2 = Person.class.getAnnotationsByType(Hint.class);
System.out.println(hints2.length); // 2尽管,我们从没有在 Person 类上声明 @Hints 注解,但是仍可以通过 getAnnotation(Hints.class) 读取它。然而,更便利的方式是 getAnnotationsByType ,它可以直接访问所有 @Hint 注解。
此外,Java 8 中的注释使用扩展了两个新的目标:
@Target({ElementType.TYPE_PARAMETER, ElementType.TYPE_USE})
@interface MyAnnotation {}水平线以上为 java8-tutorial (opens new window) 翻译内容。
# #JDK8 升级常见问题
JDK8 发布很久了,它提供了许多吸引人的新特性,能够提高编程效率。
如果是新的项目,使用 JDK8 当然是最好的选择。但是,对于一些老的项目,升级到 JDK8 则存在一些兼容性问题,是否升级需要酌情考虑。
近期,我在工作中遇到一个任务,将部门所有项目的 JDK 版本升级到 1.8 (老版本大多是 1.6)。在这个过程中,遇到一些问题点,并结合在网上看到的坑,在这里总结一下。
# #Intellij 中的 JDK 环境设置
# #Settings
点击 File > Settings > Java Compiler
Project bytecode version 选择 1.8
点击 File > Settings > Build Tools > Maven > Importing
选择 JDK for importer 为 1.8
# #Projcet Settings
Project SDK 选择 1.8
# #Application
如果 web 应用的启动方式为 Application ,需要修改 JRE
点击 Run/Debug Configurations > Configuration
选择 JRE 为 1.8
# #Linux 环境修改
# #修改环境变量
修改 /etc/profile 中的 JAVA_HOME,设置 为 jdk8 所在路径。
修改后,执行 source /etc/profile 生效。
编译、发布脚本中如果有 export JAVA_HOME ,需要注意,需要使用 jdk8 的路径。
# #修改 maven
settings.xml 中 profile 的激活条件如果是 jdk,需要修改一下 jdk 版本
<activation>
<jdk>1.8</jdk> <!-- 修改为 1.8 -->
</activation># #修改 server
修改 server 中的 javac 版本,以 resin 为例:
修改 resin 配置文件中的 javac 参数。
<javac compiler="internal" args="-source 1.8"/># #sun.* 包缺失问题
JDK8 不再提供 sun.* 包供开发者使用,因为这些接口不是公共接口,不能保证在所有 Java 兼容的平台上工作。
使用了这些 API 的程序如果要升级到 JDK 1.8 需要寻求替代方案。
虽然,也可以自己导入包含 sun.* 接口 jar 包到 classpath 目录,但这不是一个好的做法。
需要详细了解为什么不要使用 sun.* ,可以参考官方文档:Why Developers Should Not Write Programs That Call ‘sun’ Packages(opens new window)
# #默认安全策略修改
升级后估计有些小伙伴在使用不安全算法时可能会发生错误,so,支持不安全算法还是有必要的
找到 $JAVA_HOME 下 jre/lib/security/java.security ,将禁用的算法设置为空: jdk.certpath.disabledAlgorithms= 。
# #JVM 参数调整
在 jdk8 中,PermSize 相关的参数已经不被使用:
-XX:MaxPermSize=size
Sets the maximum permanent generation space size (in bytes). This option was deprecated in JDK 8, and superseded by the -XX:MaxMetaspaceSize option.
-XX:PermSize=size
Sets the space (in bytes) allocated to the permanent generation that triggers a garbage collection if it is exceeded. This option was deprecated un JDK 8, and superseded by the -XX:MetaspaceSize option.JDK8 中再也没有 PermGen 了。其中的某些部分,如被 intern 的字符串,在 JDK7 中已经移到了普通堆里。其余结构在 JDK8 中会被移到称作 “Metaspace” 的本机内存区中,该区域在默认情况下会自动生长,也会被垃圾回收。它有两个标记:MetaspaceSize 和 MaxMetaspaceSize。
-XX:MetaspaceSize=size
Sets the size of the allocated class metadata space that will trigger a garbage collection the first time it is exceeded. This threshold for a garbage collection is increased or decreased depending on the amount of metadata used. The default size depends on the platform.
-XX:MaxMetaspaceSize=size
Sets the maximum amount of native memory that can be allocated for class metadata. By default, the size is not limited. The amount of metadata for an application depends on the application itself, other running applications, and the amount of memory available on the system.
以下示例显示如何将类类元数据的上限设置为 256 MB:
XX:MaxMetaspaceSize=256m
# #字节码问题
ASM 5.0 beta 开始支持 JDK8
字节码错误
Caused by: java.io.IOException: invalid constant type: 15
at javassist.bytecode.ConstPool.readOne(ConstPool.java:1113)- 查找组件用到了 mvel,mvel 为了提高效率进行了字节码优化,正好碰上 JDK8 死穴,所以需要升级。
<dependency>
<groupId>org.mvel</groupId>
<artifactId>mvel2</artifactId>
<version>2.2.7.Final</version>
</dependency>- javassist
<dependency>
<groupId>org.javassist</groupId>
<artifactId>javassist</artifactId>
<version>3.18.1-GA</version>
</dependency>注意
有些部署工具不会删除旧版本 jar 包,所以可以尝试手动删除老版本 jar 包。
http://asm.ow2.org/history.html
# #Java 连接 redis 启动报错 Error redis clients jedis HostAndPort cant resolve localhost address
错误环境:本地 window 开发环境没有问题。上到 Linux 环境,启动出现问题。 错误信息: Error redis clients jedis HostAndPort cant resolve localhost address
解决办法:
(1)查看 Linux 系统的主机名
# hostname
template(2)查看 /etc/hosts 文件中是否有 127.0.0.1 对应主机名,如果没有则添加
# #Resin 容器指定 JDK 1.8
如果 resin 容器原来版本低于 JDK1.8,运行 JDK 1.8 编译的 web app 时,可能会提示错误:
java.lang.UnsupportedClassVersionError: PR/Sort : Unsupported major.minor version 52.0解决方法就是,使用 JDK 1.8 要重新编译一下。然后,我在部署时出现过编译后仍报错的情况,重启一下服务器后,问题解决,不知是什么原因。
./configure --prefix=/usr/local/resin --with-java=/usr/local/jdk1.8.0_121
make & make install# Java 容器简介
📦 本文以及示例源码已归档在 javacore(opens new window)
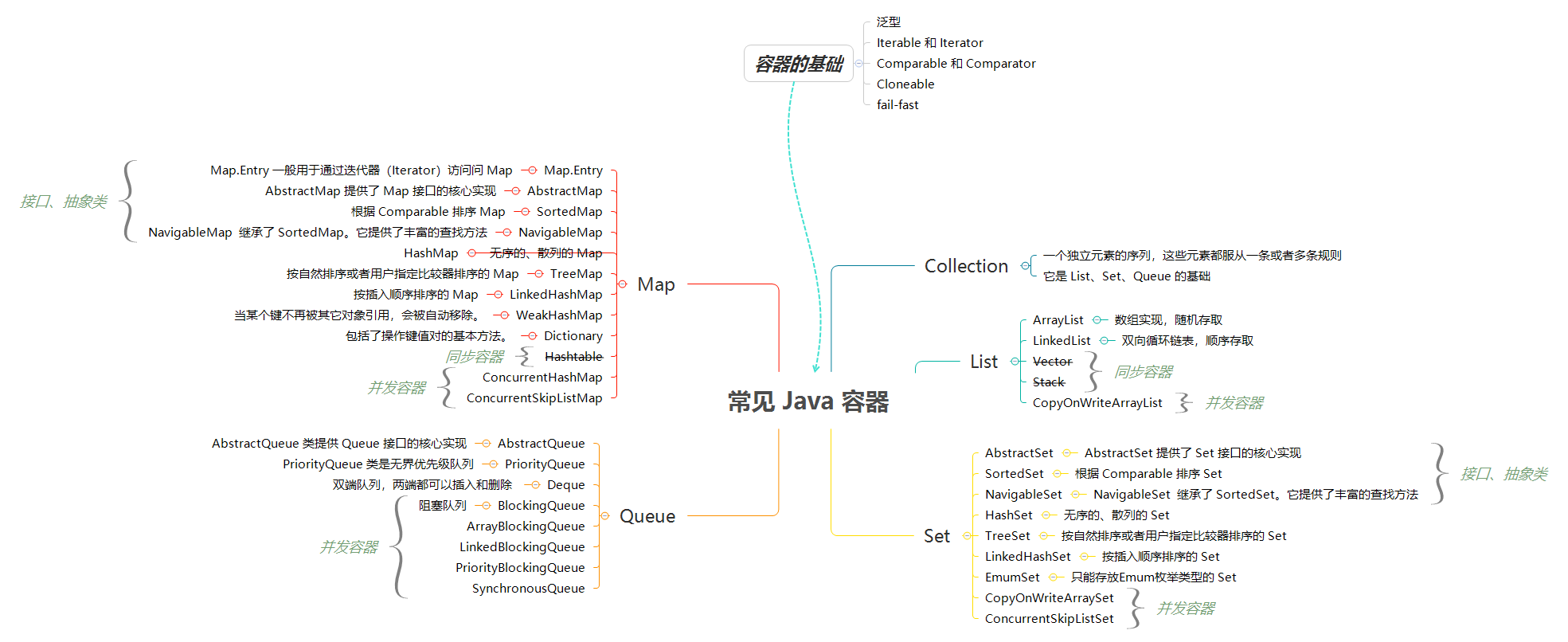
- \1. 容器简介
- \2. 容器的基本机制
- 3. 容器和线程安全
- 4. 参考资料
# #1. 容器简介
# #1.1. 数组与容器
Java 中常用的存储容器就是数组和容器,二者有以下区别:
- 存储大小是否固定
- 数组的长度固定;
- 容器的长度可变。
- 数据类型
- 数组可以存储基本数据类型,也可以存储引用数据类型;
- 容器只能存储引用数据类型,基本数据类型的变量要转换成对应的包装类才能放入容器类中。
💡 不了解什么是基本数据类型、引用数据类型、包装类这些概念,可以参考:Java 基本数据类型 (opens new window)
# #1.2. 容器框架
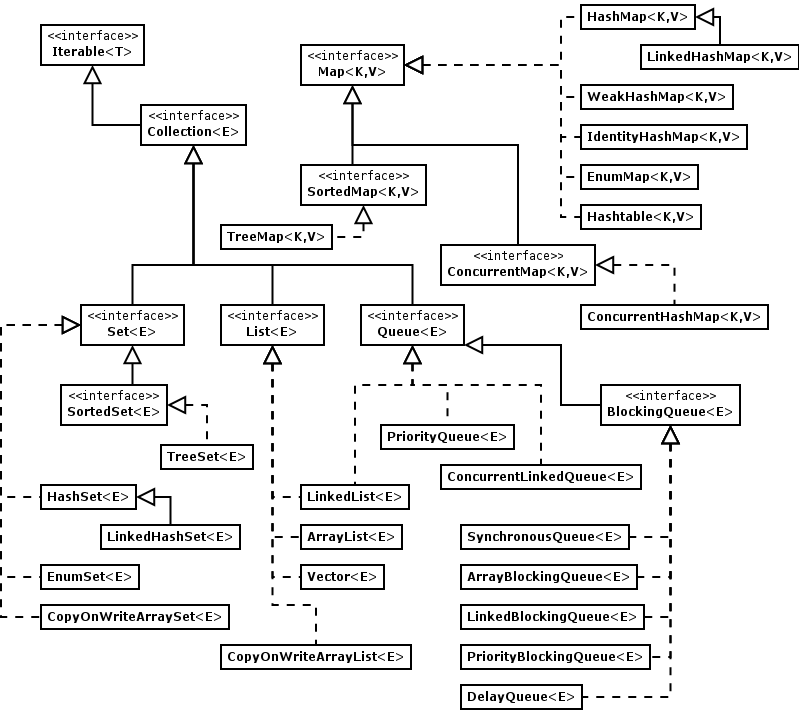
Java 容器框架主要分为 Collection 和 Map 两种。其中, Collection 又分为 List 、 Set 以及 Queue 。
-
Collection \- 一个独立元素的序列,这些元素都服从一条或者多条规则。 - `List` - 必须按照插入的顺序保存元素。 - `Set` - 不能有重复的元素。 - `Queue` - 按照排队规则来确定对象产生的顺序(通常与它们被插入的顺序相同)。 - `Map` - 一组成对的“键值对”对象,允许你使用键来查找值。 ## [#](https://dunwu.github.io/javacore/container/java-container.html#_2-容器的基本机制)2. 容器的基本机制 > Java 的容器具有一定的共性,它们或全部或部分依赖以下技术。所以,学习以下技术点,对于理解 Java 容器的特性和原理有很大的帮助。 ### [#](https://dunwu.github.io/javacore/container/java-container.html#_2-1-泛型)2.1. 泛型 Java 1.5 引入了泛型技术。 Java **容器通过泛型技术来保证其数据的类型安全**。什么是类型安全呢? 举例来说:如果有一个 `List<Object>` 容器,Java **编译器在编译时不会对原始类型进行类型安全检查**,却会对带参数的类型进行检查,通过使用 Object 作为类型,可以告知编译器该方法可以接受任何类型的对象,比如 String 或 Integer。 ```java List<Object> list = new ArrayList<Object>(); list.add("123"); list.add(123);
如果没有泛型技术,如示例中的代码那样,容器中就可能存储任意数据类型,这是很危险的行为。
List<String> list = new ArrayList<String>();
list.add("123");
list.add(123);💡 想深入了解 Java 泛型技术的用法和原理可以参考:深入理解 Java 泛型 (opens new window)
# #2.2. Iterable 和 Iterator
Iterable 和 Iterator 目的在于遍历访问容器中的元素。
Iterator 接口定义:
public interface Iterator<E> {
boolean hasNext();
E next();
default void remove() {
throw new UnsupportedOperationException("remove");
}
default void forEachRemaining(Consumer<? super E> action) {
Objects.requireNonNull(action);
while (hasNext())
action.accept(next());
}
}Iterable 接口定义:
public interface Iterable<T> {
Iterator<T> iterator();
default void forEach(Consumer<? super T> action) {
Objects.requireNonNull(action);
for (T t : this) {
action.accept(t);
}
}
default Spliterator<T> spliterator() {
return Spliterators.spliteratorUnknownSize(iterator(), 0);
}
}Collection 接口扩展了 Iterable 接口。
迭代其实我们可以简单地理解为遍历,是一个标准化遍历各类容器里面的所有对象的接口。它是一个经典的设计模式 —— 迭代器模式(Iterator)。
迭代器模式 - 提供一种方法顺序访问一个聚合对象中各个元素,而又无须暴露该对象的内部表示。
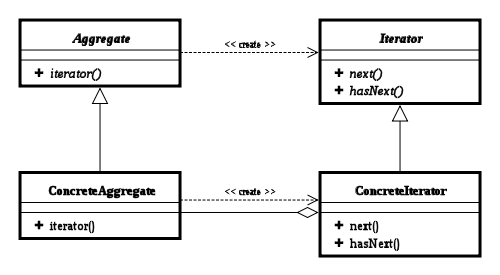
示例:迭代器遍历
public class IteratorDemo {
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
Iterator it = list.iterator();
while (it.hasNext()) {
System.out.println(it.next());
}
}
}# #2.3. Comparable 和 Comparator
Comparable 是排序接口。若一个类实现了 Comparable 接口,表示该类的实例可以比较,也就意味着支持排序。实现了 Comparable 接口的类的对象的列表或数组可以通过 Collections.sort 或 Arrays.sort 进行自动排序。
Comparable 接口定义:
public interface Comparable<T> {
public int compareTo(T o);
}Comparator 是比较接口,我们如果需要控制某个类的次序,而该类本身不支持排序 (即没有实现 Comparable 接口),那么我们就可以建立一个 “该类的比较器” 来进行排序,这个 “比较器” 只需要实现 Comparator 接口即可。也就是说,我们可以通过实现 Comparator 来新建一个比较器,然后通过这个比较器对类进行排序。
Comparator 接口定义:
@FunctionalInterface
public interface Comparator<T> {
int compare(T o1, T o2);
boolean equals(Object obj);
// 反转
default Comparator<T> reversed() {
return Collections.reverseOrder(this);
}
default Comparator<T> thenComparing(Comparator<? super T> other) {
Objects.requireNonNull(other);
return (Comparator<T> & Serializable) (c1, c2) -> {
int res = compare(c1, c2);
return (res != 0) ? res : other.compare(c1, c2);
};
}
// thenComparingXXX 方法略
// 静态方法略
}在 Java 容器中,一些可以排序的容器,如 TreeMap 、 TreeSet ,都可以通过传入 Comparator ,来定义内部元素的排序规则。
# #2.4. Cloneable
Java 中 一个类要实现 clone 功能 必须实现 Cloneable 接口,否则在调用 clone() 时会报 CloneNotSupportedException 异常。
Java 中所有类都默认继承 java.lang.Object 类,在 java.lang.Object 类中有一个方法 clone() ,这个方法将返回 Object 对象的一个拷贝。 Object 类里的 clone() 方法仅仅用于浅拷贝(拷贝基本成员属性,对于引用类型仅返回指向改地址的引用)。
如果 Java 类需要深拷贝,需要覆写 clone() 方法。
# #2.5. fail-fast
# #fail-fast 的要点
Java 容器(如:ArrayList、HashMap、TreeSet 等待)的 javadoc 中常常提到类似的描述:
注意,迭代器的快速失败行为无法得到保证,因为一般来说,不可能对是否出现不同步并发修改做出任何硬性保证。快速失败(fail-fast)迭代器会尽最大努力抛出
ConcurrentModificationException。因此,为提高这类迭代器的正确性而编写一个依赖于此异常的程序是错误的做法:迭代器的快速失败行为应该仅用于检测 bug。
那么,我们不禁要问,什么是 fail-fast,为什么要有 fail-fast 机制?
fail-fast 是 Java 容器的一种错误检测机制。当多个线程对容器进行结构上的改变的操作时,就可能触发 fail-fast 机制。记住是有可能,而不是一定。
例如:假设存在两个线程(线程 1、线程 2),线程 1 通过 Iterator 在遍历容器 A 中的元素,在某个时候线程 2 修改了容器 A 的结构(是结构上面的修改,而不是简单的修改容器元素的内容),那么这个时候程序就会抛出 ConcurrentModificationException 异常,从而产生 fail-fast 机制。
容器在迭代操作中改变元素个数(添加、删除元素)都可能会导致 fail-fast。
示例:fail-fast 示例
public class FailFastDemo {
private static int MAX = 100;
private static List<Integer> list = new ArrayList<>();
public static void main(String[] args) {
for (int i = 0; i < MAX; i++) {
list.add(i);
}
new Thread(new MyThreadA()).start();
new Thread(new MyThreadB()).start();
}
/** 迭代遍历容器所有元素 */
static class MyThreadA implements Runnable {
@Override
public void run() {
Iterator<Integer> iterator = list.iterator();
while (iterator.hasNext()) {
int i = iterator.next();
System.out.println("MyThreadA 访问元素:" + i);
try {
TimeUnit.MILLISECONDS.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
/** 遍历删除指定范围内的所有偶数 */
static class MyThreadB implements Runnable {
@Override
public void run() {
int i = 0;
while (i < MAX) {
if (i % 2 == 0) {
System.out.println("MyThreadB 删除元素" + i);
list.remove(i);
}
i++;
}
}
}
}执行后,会抛出 java.util.ConcurrentModificationException 异常。
# #解决 fail-fast
fail-fast 有两种解决方案:
- 在遍历过程中所有涉及到改变容器个数的地方全部加上
synchronized或者直接使用Collections.synchronizedXXX容器,这样就可以解决。但是不推荐,因为增删造成的同步锁可能会阻塞遍历操作,影响吞吐。 - 使用并发容器,如:
CopyOnWriterArrayList。
# #3. 容器和线程安全
为了在并发环境下安全地使用容器,Java 提供了同步容器和并发容器。
同步容器和并发容器详情请参考:同步容器和并发容器
# Java 容器之 List
📦 本文以及示例源码已归档在 javacore(opens new window)
List是Collection的子接口,其中可以保存各个重复的内容。
- \1. List 简介
- \2. ArrayList
- \3. LinkedList
- \4. List 常见问题
- 5. 参考资料
# #1. List 简介
List 是一个接口,它继承于 Collection 的接口。它代表着有序的队列。
AbstractList 是一个抽象类,它继承于 AbstractCollection 。 AbstractList 实现了 List 接口中除 size() 、 get(int location) 之外的函数。
AbstractSequentialList 是一个抽象类,它继承于 AbstractList 。 AbstractSequentialList 实现了 “链表中,根据 index 索引值操作链表的全部函数”。
# #1.1. ArrayList 和 LinkedList
ArrayList 、 LinkedList 是 List 最常用的实现。
ArrayList基于动态数组实现,存在容量限制,当元素数超过最大容量时,会自动扩容;LinkedList基于双向链表实现,不存在容量限制。ArrayList随机访问速度较快,随机插入、删除速度较慢;LinkedList随机插入、删除速度较快,随机访问速度较慢。ArrayList和LinkedList都不是线程安全的。
# #1.2. Vector 和 Stack
Vector 和 Stack 的设计目标是作为线程安全的 List 实现,替代 ArrayList 。
Vector-Vector和ArrayList类似,也实现了List接口。但是,Vector中的主要方法都是synchronized方法,即通过互斥同步方式保证操作的线程安全。Stack-Stack也是一个同步容器,它的方法也用synchronized进行了同步,它实际上是继承于Vector类。
# #2. ArrayList
ArrayList 从数据结构角度来看,可以视为支持动态扩容的线性表。

# #2.1. ArrayList 要点
ArrayList 是一个数组队列,相当于动态数组。 ArrayList 默认初始容量大小为 10 ,添加元素时,如果发现容量已满,会自动扩容为原始大小的 1.5 倍。因此,应该尽量在初始化 ArrayList 时,为其指定合适的初始化容量大小,减少扩容操作产生的性能开销。
ArrayList 定义:
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable从 ArrayList 的定义,不难看出 ArrayList 的一些基本特性:
ArrayList实现了List接口,并继承了AbstractList,它支持所有List的操作。ArrayList实现了RandomAccess接口,支持随机访问。RandomAccess是一个标志接口,它意味着 “只要实现该接口的List类,都支持快速随机访问”。在ArrayList中,我们即可以通过元素的序号快速获取元素对象;这就是快速随机访问。ArrayList实现了Cloneable接口,默认为浅拷贝。ArrayList实现了Serializable接口,支持序列化,能通过序列化方式传输。ArrayList是非线程安全的。
# #2.2. ArrayList 原理
# #ArrayList 的数据结构
ArrayList 包含了两个重要的元素: elementData 和 size 。
// 默认初始化容量
private static final int DEFAULT_CAPACITY = 10;
// 对象数组
transient Object[] elementData;
// 数组长度
private int size;size- 是动态数组的实际大小。elementData- 是一个Object数组,用于保存添加到ArrayList中的元素。
# #ArrayList 的序列化
ArrayList 具有动态扩容特性,因此保存元素的数组不一定都会被使用,那么就没必要全部进行序列化。为此, ArrayList 定制了其序列化方式。具体做法是:
- 存储元素的
Object数组(即elementData)使用transient修饰,使得它可以被 Java 序列化所忽略。 ArrayList重写了writeObject()和readObject()来控制序列化数组中有元素填充那部分内容。
💡 不了解 Java 序列化方式,可以参考:Java 序列化 (opens new window)
# #ArrayList 构造方法
ArrayList 类实现了三个构造函数:
- 第一个是默认构造方法,ArrayList 会创建一个空数组;
- 第二个是创建 ArrayList 对象时,传入一个初始化值;
- 第三个是传入一个集合类型进行初始化。
当 ArrayList 新增元素时,如果所存储的元素已经超过其当前容量,它会计算容量后再进行动态扩容。数组的动态扩容会导致整个数组进行一次内存复制。因此,初始化 ArrayList 时,指定数组初始大小,有助于减少数组的扩容次数,从而提高系统性能。
public ArrayList() {
// 创建一个空数组
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
// 根据初始化值创建数组大小
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
// 初始化值为 0 时,创建一个空数组
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}# #ArrayList 访问元素
ArrayList 访问元素的实现主要基于以下关键性源码:
// 获取第 index 个元素
public E get(int index) {
rangeCheck(index);
return elementData(index);
}
E elementData(int index) {
return (E) elementData[index];
}实现非常简单,其实就是通过数组下标访问数组元素,其时间复杂度为 O (1),所以很快。
# #ArrayList 添加元素
ArrayList 添加元素有两种方法:一种是添加元素到数组末尾,另外一种是添加元素到任意位置。
// 添加元素到数组末尾
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
// 添加元素到任意位置
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}两种添加元素方法的不同点是:
- 添加元素到任意位置,会导致在该位置后的所有元素都需要重新排列;
- 而添加元素到数组末尾,在没有发生扩容的前提下,是不会有元素复制排序过程的。
两种添加元素方法的共同点是:添加元素时,会先检查容量大小,如果发现容量不足,会自动扩容为原始大小的 1.5 倍。
ArrayList 添加元素的实现主要基于以下关键性源码:
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}ArrayList 执行添加元素动作( add 方法)时,调用 ensureCapacityInternal 方法来保证容量足够。
- 如果容量足够时,将数据作为数组中
size+1位置上的元素写入,并将size自增 1。 - 如果容量不够时,需要使用
grow方法进行扩容数组,新容量的大小为oldCapacity + (oldCapacity >> 1),也就是旧容量的 1.5 倍。扩容操作实际上是调用Arrays.copyOf()把原数组拷贝为一个新数组,因此最好在创建ArrayList对象时就指定大概的容量大小,减少扩容操作的次数。
# #ArrayList 删除元素
ArrayList 的删除方法和添加元素到任意位置方法有些相似。
ArrayList 在每一次有效的删除操作后,都要进行数组的重组,并且删除的元素位置越靠前,数组重组的开销就越大。具体来说, ArrayList 会 ** 调用 System.arraycopy() 将 index+1 后面的元素都复制到 index 位置上。
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index, numMoved);
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}# #ArrayList 的 Fail-Fast
ArrayList 使用 modCount 来记录结构发生变化的次数。结构发生变化是指添加或者删除至少一个元素的所有操作,或者是调整内部数组的大小,仅仅只是设置元素的值不算结构发生变化。
在进行序列化或者迭代等操作时,需要比较操作前后 modCount 是否改变,如果发生改变, ArrayList 会抛出 ConcurrentModificationException 。
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException{
// Write out element count, and any hidden stuff
int expectedModCount = modCount;
s.defaultWriteObject();
// Write out size as capacity for behavioural compatibility with clone()
s.writeInt(size);
// Write out all elements in the proper order.
for (int i=0; i<size; i++) {
s.writeObject(elementData[i]);
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}# #3. LinkedList
LinkedList 从数据结构角度来看,可以视为双链表。
# #3.1. LinkedList 要点
LinkedList 基于双链表结构实现。由于是双链表,所以顺序访问会非常高效,而随机访问效率比较低。
LinkedList 定义:
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable从 LinkedList 的定义,可以得出 LinkedList 的一些基本特性:
LinkedList实现了List接口,并继承了AbstractSequentialList,它支持所有List的操作。LinkedList实现了Deque接口,也可以被当作队列(Queue)或双端队列(Deque)进行操作,此外,也可以用来实现栈。LinkedList实现了Cloneable接口,默认为浅拷贝。LinkedList实现了Serializable接口,支持序列化。LinkedList是非线程安全的。
# #3.2. LinkedList 原理
# #LinkedList 的数据结构
LinkedList 内部维护了一个双链表。
LinkedList 通过 Node 类型的头尾指针( first 和 last )来访问数据。
// 链表长度
transient int size = 0;
// 链表头节点
transient Node<E> first;
// 链表尾节点
transient Node<E> last;size- 表示双链表中节点的个数,初始为 0。first和last- 分别是双链表的头节点和尾节点。
Node 是 LinkedList 的内部类,它表示链表中的元素实例。Node 中包含三个元素:
prev是该节点的上一个节点;next是该节点的下一个节点;item是该节点所包含的值。
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
...
}# #LinkedList 的序列化
LinkedList 与 ArrayList 一样也定制了自身的序列化方式。具体做法是:
- 将
size(双链表容量大小)、first和last(双链表的头尾节点)修饰为transient,使得它们可以被 Java 序列化所忽略。 - 重写了
writeObject()和readObject()来控制序列化时,只处理双链表中能被头节点链式引用的节点元素。
# #LinkedList 访问元素
LinkedList 访问元素的实现主要基于以下关键性源码:
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}获取 LinkedList 第 index 个元素的算法是:
- 判断 index 在链表前半部分,还是后半部分。
- 如果是前半部分,从头节点开始查找;如果是后半部分,从尾结点开始查找。
LinkedList 这种访问元素的性能是 O(N) 级别的(极端情况下,扫描 N/2 个元素);相比于 ArrayList 的 O(1) ,显然要慢不少。
推荐使用迭代器遍历 LinkedList ,不要使用传统的 for 循环。注:foreach 语法会被编译器转换成迭代器遍历,但是它的遍历过程中不允许修改 List 长度,即不能进行增删操作。
# #LinkedList 添加元素
LinkedList 有多种添加元素方法:
add(E e):默认添加元素方法(插入尾部)add(int index, E element):添加元素到任意位置addFirst(E e):在头部添加元素addLast(E e):在尾部添加元素
public boolean add(E e) {
linkLast(e);
return true;
}
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
public void addFirst(E e) {
linkFirst(e);
}
public void addLast(E e) {
linkLast(e);
}LinkedList 添加元素的实现主要基于以下关键性源码:
private void linkFirst(E e) {
final Node<E> f = first;
final Node<E> newNode = new Node<>(null, e, f);
first = newNode;
if (f == null)
last = newNode;
else
f.prev = newNode;
size++;
modCount++;
}
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}算法如下:
- 将新添加的数据包装为
Node; - 如果往头部添加元素,将头指针
first指向新的Node,之前的first对象的prev指向新的Node。 - 如果是向尾部添加元素,则将尾指针
last指向新的Node,之前的last对象的next指向新的Node。
# #LinkedList 删除元素
LinkedList 删除元素的实现主要基于以下关键性源码:
public boolean remove(Object o) {
if (o == null) {
// 遍历找到要删除的元素节点
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
// 遍历找到要删除的元素节点
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}算法说明:
-
遍历找到要删除的元素节点,然后调用
unlink方法删除节点; -
unlink 删除节点的方法: - 如果当前节点有前驱节点,则让前驱节点指向当前节点的下一个节点;否则,让双链表头指针指向下一个节点。 - 如果当前节点有后继节点,则让后继节点指向当前节点的前一个节点;否则,让双链表尾指针指向上一个节点。 ## [#](https://dunwu.github.io/javacore/container/java-container-list.html#_4-list-常见问题)4. List 常见问题 ### [#](https://dunwu.github.io/javacore/container/java-container-list.html#_4-1-arrays-aslist-问题点)4.1. Arrays.asList 问题点 在业务开发中,我们常常会把原始的数组转换为 `List` 类数据结构,来继续展开各种 `Stream` 操作。通常,我们会使用 `Arrays.asList` 方法可以把数组一键转换为 `List`。 【示例】Arrays.asList 转换基本类型数组 ```java int[] arr = { 1, 2, 3 }; List list = Arrays.asList(arr); log.info("list:{} size:{} class:{}", list, list.size(), list.get(0).getClass());
【输出】
11:26:33.214 [main] INFO io.github.dunwu.javacore.container.list.AsList示例 - list:[[I@ae45eb6] size:1 class:class [I数组元素个数为 3,但转换后的列表个数为 1。
由此可知, Arrays.asList 第一个问题点:不能直接使用 Arrays.asList 来转换基本类型数组。
其原因是: Arrays.asList 方法传入的是一个泛型 T 类型可变参数,最终 int 数组整体作为了一个对象成为了泛型类型 T:
public static <T> List<T> asList(T... a) {
return new ArrayList<>(a);
}直接遍历这样的 List 必然会出现 Bug,修复方式有两种,如果使用 Java8 以上版本可以使用 Arrays.stream 方法来转换,否则可以把 int 数组声明为包装类型 Integer 数组:
【示例】转换整型数组为 List 的正确方式
int[] arr1 = { 1, 2, 3 };
List list1 = Arrays.stream(arr1).boxed().collect(Collectors.toList());
log.info("list:{} size:{} class:{}", list1, list1.size(), list1.get(0).getClass());
Integer[] arr2 = { 1, 2, 3 };
List list2 = Arrays.asList(arr2);
log.info("list:{} size:{} class:{}", list2, list2.size(), list2.get(0).getClass());【示例】Arrays.asList 转换引用类型数组
String[] arr = { "1", "2", "3" };
List list = Arrays.asList(arr);
arr[1] = "4";
try {
list.add("5");
} catch (Exception ex) {
ex.printStackTrace();
}
log.info("arr:{} list:{}", Arrays.toString(arr), list);抛出 java.lang.UnsupportedOperationException 。
抛出异常的原因在于 Arrays.asList 第二个问题点: Arrays.asList 返回的 List 不支持增删操作。 Arrays.asList 返回的 List 并不是我们期望的 java.util.ArrayList ,而是 Arrays 的内部类 ArrayList 。
查看源码,我们可以发现 Arrays.asList 返回的 ArrayList 继承了 AbstractList ,但是并没有覆写 add 和 remove 方法。
private static class ArrayList<E> extends AbstractList<E>
implements RandomAccess, java.io.Serializable
{
private static final long serialVersionUID = -2764017481108945198L;
private final E[] a;
ArrayList(E[] array) {
a = Objects.requireNonNull(array);
}
// ...
@Override
public E set(int index, E element) {
E oldValue = a[index];
a[index] = element;
return oldValue;
}
}
public abstract class AbstractList<E> extends AbstractCollection<E> implements List<E> {
public void add(int index, E element) {
throw new UnsupportedOperationException();
}
public E remove(int index) {
throw new UnsupportedOperationException();
}
}Arrays.asList 第三个问题点:对原始数组的修改会影响到我们获得的那个 List 。 ArrayList 其实是直接使用了原始的数组。
解决方法很简单,重新 new 一个 ArrayList 初始化 Arrays.asList 返回的 List 即可:
String[] arr = { "1", "2", "3" };
List list = new ArrayList(Arrays.asList(arr));
arr[1] = "4";
try {
list.add("5");
} catch (Exception ex) {
ex.printStackTrace();
}
log.info("arr:{} list:{}", Arrays.toString(arr), list);# #4.2. List.subList 问题点
List.subList 直接引用了原始的 List,也可以认为是共享 “存储”,而且对原始 List 直接进行结构性修改会导致 SubList 出现异常。
private static List<List<Integer>> data = new ArrayList<>();
private static void oom() {
for (int i = 0; i < 1000; i++) {
List<Integer> rawList = IntStream.rangeClosed(1, 100000).boxed().collect(Collectors.toList());
data.add(rawList.subList(0, 1));
}
}出现 OOM 的原因是,循环中的 1000 个具有 10 万个元素的 List 始终得不到回收,因为它始终被 subList 方法返回的 List 强引用。
解决方法是:
private static void oomfix() {
for (int i = 0; i < 1000; i++) {
List<Integer> rawList = IntStream.rangeClosed(1, 100000).boxed().collect(Collectors.toList());
data.add(new ArrayList<>(rawList.subList(0, 1)));
}
}【示例】子 List 强引用原始的 List
private static void wrong() {
List<Integer> list = IntStream.rangeClosed(1, 10).boxed().collect(Collectors.toList());
List<Integer> subList = list.subList(1, 4);
System.out.println(subList);
subList.remove(1);
System.out.println(list);
list.add(0);
try {
subList.forEach(System.out::println);
} catch (Exception ex) {
ex.printStackTrace();
}
}抛出 java.util.ConcurrentModificationException 。
解决方法:
一种是,不直接使用 subList 方法返回的 SubList,而是重新使用 new ArrayList,在构造方法传入 SubList,来构建一个独立的 ArrayList;
另一种是,对于 Java 8 使用 Stream 的 skip 和 limit API 来跳过流中的元素,以及限制流中元素的个数,同样可以达到 SubList 切片的目的。
//方式一:
List<Integer> subList = new ArrayList<>(list.subList(1, 4));
//方式二:
List<Integer> subList = list.stream().skip(1).limit(3).collect(Collectors.toList());# Java 容器之 Map
📦 本文以及示例源码已归档在 javacore(opens new window)
- \1. Map 简介
- \2. HashMap 类
- \3. LinkedHashMap 类
- \4. TreeMap 类
- 5. WeakHashMap
- \6. 总结
- 7. 参考资料
# #1. Map 简介
# #1.1. Map 架构
Map 家族主要成员功能如下:
Map是 Map 容器家族的祖先,Map 是一个用于保存键值对 (key-value) 的接口。Map 中不能包含重复的键;每个键最多只能映射到一个值。AbstractMap继承了Map的抽象类,它实现了Map中的核心 API。其它Map的实现类可以通过继承AbstractMap来减少重复编码。SortedMap继承了Map的接口。SortedMap中的内容是排序的键值对,排序的方法是通过实现比较器 (Comparator) 完成的。NavigableMap继承了SortedMap的接口。相比于SortedMap,NavigableMap有一系列的 “导航” 方法;如 "获取大于 / 等于某对象的键值对"、“获取小于 / 等于某对象的键值对” 等等。HashMap继承了AbstractMap,但没实现NavigableMap接口。HashMap的主要作用是储存无序的键值对,而Hash也体现了它的查找效率很高。HashMap是使用最广泛的Map。Hashtable虽然没有继承AbstractMap,但它继承了Dictionary(Dictionary也是键值对的接口),而且也实现Map接口。因此,Hashtable的主要作用是储存无序的键值对。和 HashMap 相比,Hashtable在它的主要方法中使用synchronized关键字修饰,来保证线程安全。但是,由于它的锁粒度太大,非常影响读写速度,所以,现代 Java 程序几乎不会使用Hashtable,如果需要保证线程安全,一般会用ConcurrentHashMap来替代。TreeMap继承了AbstractMap,且实现了NavigableMap接口。TreeMap的主要作用是储存有序的键值对,排序依据根据元素类型的Comparator而定。WeakHashMap继承了AbstractMap。WeakHashMap的键是弱引用 (即WeakReference),它的主要作用是当 GC 内存不足时,会自动将WeakHashMap中的 key 回收,这避免了WeakHashMap的内存空间无限膨胀。很明显,WeakHashMap适用于作为缓存。
# #1.2. Map 接口
Map 的定义如下:
public interface Map<K,V> { }Map 是一个用于保存键值对 (key-value) 的接口。Map 中不能包含重复的键;每个键最多只能映射到一个值。
Map 接口提供三种 Collection 视图,允许以键集、值集或键 - 值映射关系集的形式访问数据。
Map 有些实现类,可以有序的保存元素,如 TreeMap ;另一些实现类则不保证顺序,如 HashMap 类。
Map 的实现类应该提供 2 个 “标准的” 构造方法:
- void(无参数)构造方法,用于创建空 Map;
- 带有单个 Map 类型参数的构造方法,用于创建一个与其参数具有相同键 - 值映射关系的新 Map。
实际上,后一个构造方法允许用户复制任意 Map,生成所需类的一个等价 Map。尽管无法强制执行此建议(因为接口不能包含构造方法),但是 JDK 中所有通用的 Map 实现都遵从它。
# #1.3. Map.Entry 接口
Map.Entry 一般用于通过迭代器( Iterator )访问问 Map 。
Map.Entry 是 Map 中内部的一个接口, Map.Entry 代表了 键值对 实体,Map 通过 entrySet() 获取 Map.Entry 集合,从而通过该集合实现对键值对的操作。
# #1.4. AbstractMap 抽象类
AbstractMap 的定义如下:
public abstract class AbstractMap<K,V> implements Map<K,V> {}AbstractMap 抽象类提供了 Map 接口的核心实现,以最大限度地减少实现 Map 接口所需的工作。
要实现不可修改的 Map,编程人员只需扩展此类并提供 entrySet() 方法的实现即可,该方法将返回 Map 的映射关系 Set 视图。通常,返回的 set 将依次在 AbstractSet 上实现。此 Set 不支持 add() 或 remove() 方法,其迭代器也不支持 remove() 方法。
要实现可修改的 Map ,编程人员必须另外重写此类的 put 方法(否则将抛出 UnsupportedOperationException ), entrySet().iterator() 返回的迭代器也必须另外实现其 remove() 方法。
# #1.5. SortedMap 接口
SortedMap 的定义如下:
public interface SortedMap<K,V> extends Map<K,V> { }SortedMap 继承了 Map ,它是一个有序的 Map 。
SortedMap 的排序方式有两种:自然排序或者用户指定比较器。插入有序 SortedMap 的所有元素都必须实现 Comparable 接口(或者被指定的比较器所接受)。
另外,所有 SortedMap 实现类都应该提供 4 个 “标准” 构造方法:
void(无参数)构造方法,它创建一个空的有序Map,按照键的自然顺序进行排序。- 带有一个
Comparator类型参数的构造方法,它创建一个空的有序Map,根据指定的比较器进行排序。 - 带有一个
Map类型参数的构造方法,它创建一个新的有序Map,其键 - 值映射关系与参数相同,按照键的自然顺序进行排序。 - 带有一个
SortedMap类型参数的构造方法,它创建一个新的有序Map,其键 - 值映射关系和排序方法与输入的有序 Map 相同。无法保证强制实施此建议,因为接口不能包含构造方法。
# #1.6. NavigableMap 接口
NavigableMap 的定义如下:
public interface NavigableMap<K,V> extends SortedMap<K,V> { }NavigableMap 继承了 SortedMap ,它提供了丰富的查找方法。
NavigableMap 分别提供了获取 “键”、“键 - 值对”、“键集”、“键 - 值对集” 的相关方法。
NavigableMap 提供的功能可以分为 4 类:
-
获取键 - 值对
lowerEntry、floorEntry、ceilingEntry和higherEntry方法,它们分别返回与小于、小于等于、大于等于、大于给定键的键关联的 Map.Entry 对象。firstEntry、pollFirstEntry、lastEntry和pollLastEntry方法,它们返回和 / 或移除最小和最大的映射关系(如果存在),否则返回 null。
-
获取键
。这个和第 1 类比较类似。
lowerKey、floorKey、ceilingKey和higherKey方法,它们分别返回与小于、小于等于、大于等于、大于给定键的键。
-
获取键的集合
navigableKeySet、descendingKeySet分别获取正序 / 反序的键集。
-
获取键 - 值对的子集
# #1.7. Dictionary 抽象类
Dictionary 的定义如下:
public abstract class Dictionary<K,V> {}Dictionary 是 JDK 1.0 定义的操作键值对的抽象类,它包括了操作键值对的基本方法。
# #2. HashMap 类
HashMap 类是最常用的 Map 。
# #2.1. HashMap 要点
从 HashMap 的命名,也可以看出: HashMap 以散列方式存储键值对。
HashMap 允许使用空值和空键。( HashMap 类大致等同于 Hashtable ,除了它是不同步的并且允许为空值。)这个类不保序;特别是,它的元素顺序可能会随着时间的推移变化。
HashMap 有两个影响其性能的参数:初始容量和负载因子。
- 容量是哈希表中桶的数量,初始容量就是哈希表创建时的容量。
- 加载因子是散列表在其容量自动扩容之前被允许的最大饱和量。当哈希表中的 entry 数量超过负载因子和当前容量的乘积时,散列表就会被重新映射(即重建内部数据结构),一般散列表大约是存储桶数量的两倍。
通常,默认加载因子(0.75)在时间和空间成本之间提供了良好的平衡。较高的值会减少空间开销,但会增加查找成本(反映在大部分 HashMap 类的操作中,包括 get 和 put )。在设置初始容量时,应考虑映射中的条目数量及其负载因子,以尽量减少重新运行操作的次数。如果初始容量大于最大入口数除以负载因子,则不会发生重新刷新操作。
如果许多映射要存储在 HashMap 实例中,使用足够大的容量创建映射将允许映射存储的效率高于根据需要执行自动重新散列以增长表。请注意,使用多个具有相同 hashCode() 的密钥是降低任何散列表性能的一个可靠方法。为了改善影响,当键是 Comparable 时,该类可以使用键之间的比较顺序来帮助断开关系。
HashMap 不是线程安全的。
# #2.2. HashMap 原理
# #HashMap 数据结构
HashMap 的核心字段:
table-HashMap使用一个Node<K,V>[]类型的数组table来储存元素。size- 初始容量。 初始为 16,每次容量不够自动扩容loadFactor- 负载因子。自动扩容之前被允许的最大饱和量,默认 0.75。
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
// 该表在初次使用时初始化,并根据需要调整大小。分配时,长度总是2的幂。
transient Node<K,V>[] table;
// 保存缓存的 entrySet()。请注意,AbstractMap 字段用于 keySet() 和 values()。
transient Set<Map.Entry<K,V>> entrySet;
// map 中的键值对数
transient int size;
// 这个HashMap被结构修改的次数结构修改是那些改变HashMap中的映射数量或者修改其内部结构(例如,重新散列)的修改。
transient int modCount;
// 下一个调整大小的值(容量*加载因子)。
int threshold;
// 散列表的加载因子
final float loadFactor;
}# #HashMap 构造方法
public HashMap(); // 默认加载因子0.75
public HashMap(int initialCapacity); // 默认加载因子0.75;以 initialCapacity 初始化容量
public HashMap(int initialCapacity, float loadFactor); // 以 initialCapacity 初始化容量;以 loadFactor 初始化加载因子
public HashMap(Map<? extends K, ? extends V> m) // 默认加载因子0.75# #put 方法的实现
put 方法大致的思路为:
- 对 key 的
hashCode()做 hash 计算,然后根据 hash 值再计算 Node 的存储位置; - 如果没有哈希碰撞,直接放到桶里;如果有哈希碰撞,以链表的形式存在桶后。
- 如果哈希碰撞导致链表过长 (大于等于
TREEIFY_THRESHOLD,数值为 8),就把链表转换成红黑树; - 如果节点已经存在就替换旧值
- 桶数量超过容量 * 负载因子(即 load factor * current capacity),HashMap 调用
resize自动扩容一倍
具体代码的实现如下:
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
// hashcode 无符号位移 16 位
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// tab 为空则创建
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 计算 index,并对 null 做处理
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
// 节点存在
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// 该链为树
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
// 该链为链表
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
// 写入
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}为什么计算 hash 使用 hashcode 无符号位移 16 位。
假设要添加两个对象 a 和 b,如果数组长度是 16,这时对象 a 和 b 通过公式 (n - 1) & hash 运算,也就是 (16-1)&a.hashCode 和 (16-1)&b.hashCode,15 的二进制为 0000000000000000000000000001111,假设对象 A 的 hashCode 为 1000010001110001000001111000000,对象 B 的 hashCode 为 0111011100111000101000010100000,你会发现上述与运算结果都是 0。这样的哈希结果就太让人失望了,很明显不是一个好的哈希算法。
但如果我们将 hashCode 值右移 16 位(h >>> 16 代表无符号右移 16 位),也就是取 int 类型的一半,刚好可以将该二进制数对半切开,并且使用位异或运算(如果两个数对应的位置相反,则结果为 1,反之为 0),这样的话,就能避免上面的情况发生。这就是 hash () 方法的具体实现方式。简而言之,就是尽量打乱 hashCode 真正参与运算的低 16 位。
# #get 方法的实现
在理解了 put 之后,get 就很简单了。大致思路如下:
- 对 key 的 hashCode () 做 hash 计算,然后根据 hash 值再计算桶的 index
- 如果桶中的第一个节点命中,直接返回;
- 如果有冲突,则通过
key.equals(k)去查找对应的 entry- 若为树,则在红黑树中通过 key.equals (k) 查找,O (logn);
- 若为链表,则在链表中通过 key.equals (k) 查找,O (n)。
具体代码的实现如下:
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
// 直接命中
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
// 未命中
if ((e = first.next) != null) {
// 在树中 get
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
// 在链表中 get
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}# #hash 方法的实现
HashMap 计算桶下标(index)公式: key.hashCode() ^ (h >>> 16) 。
下面针对这个公式来详细讲解。
在 get 和 put 的过程中,计算下标时,先对 hashCode 进行 hash 操作,然后再通过 hash 值进一步计算下标,如下图所示:
在对 hashCode() 计算 hash 时具体实现是这样的:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}可以看到这个方法大概的作用就是:高 16bit 不变,低 16bit 和高 16bit 做了一个异或。
在设计 hash 方法时,因为目前的 table 长度 n 为 2 的幂,而计算下标的时候,是这样实现的 (使用 & 位操作,而非 % 求余):
(n - 1) & hash设计者认为这方法很容易发生碰撞。为什么这么说呢?不妨思考一下,在 n - 1 为 15 (0x1111) 时,其实散列真正生效的只是低 4bit 的有效位,当然容易碰撞了。
因此,设计者想了一个顾全大局的方法 (综合考虑了速度、作用、质量),就是把高 16bit 和低 16bit 异或了一下。设计者还解释到因为现在大多数的 hashCode 的分布已经很不错了,就算是发生了碰撞也用 O (logn) 的 tree 去做了。仅仅异或一下,既减少了系统的开销,也不会造成的因为高位没有参与下标的计算 (table 长度比较小时),从而引起的碰撞。
如果还是产生了频繁的碰撞,会发生什么问题呢?作者注释说,他们使用树来处理频繁的碰撞 (we use trees to handle large sets of collisions in bins),在 JEP-180 (opens new window) 中,描述了这个问题:
Improve the performance of java.util.HashMap under high hash-collision conditions by using balanced trees rather than linked lists to store map entries. Implement the same improvement in the LinkedHashMap class.
之前已经提过,在获取 HashMap 的元素时,基本分两步:
- 首先根据 hashCode () 做 hash,然后确定 bucket 的 index;
- 如果 bucket 的节点的 key 不是我们需要的,则通过 keys.equals () 在链中找。
在 JDK8 之前的实现中是用链表解决冲突的,在产生碰撞的情况下,进行 get 时,两步的时间复杂度是 O (1)+O (n)。因此,当碰撞很厉害的时候 n 很大,O (n) 的速度显然是影响速度的。
因此在 JDK8 中,利用红黑树替换链表,这样复杂度就变成了 O (1)+O (logn) 了,这样在 n 很大的时候,能够比较理想的解决这个问题,在 JDK8:HashMap 的性能提升一文中有性能测试的结果。
# #resize 的实现
当 put 时,如果发现目前的 bucket 占用程度已经超过了 Load Factor 所希望的比例,那么就会发生 resize。在 resize 的过程,简单的说就是把 bucket 扩充为 2 倍,之后重新计算 index,把节点再放到新的 bucket 中。
当超过限制的时候会 resize,然而又因为我们使用的是 2 次幂的扩展 (指长度扩为原来 2 倍),所以,元素的位置要么是在原位置,要么是在原位置再移动 2 次幂的位置。
怎么理解呢?例如我们从 16 扩展为 32 时,具体的变化如下所示:
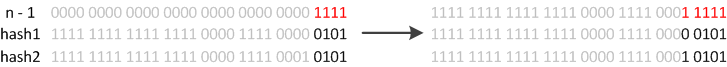
因此元素在重新计算 hash 之后,因为 n 变为 2 倍,那么 n-1 的 mask 范围在高位多 1bit (红色),因此新的 index 就会发生这样的变化:
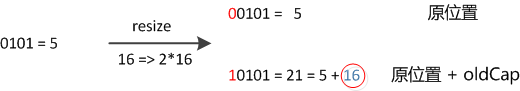
因此,我们在扩充 HashMap 的时候,不需要重新计算 hash,只需要看看原来的 hash 值新增的那个 bit 是 1 还是 0 就好了,是 0 的话索引没变,是 1 的话索引变成 “原索引 + oldCap”。可以看看下图为 16 扩充为 32 的 resize 示意图:
这个设计确实非常的巧妙,既省去了重新计算 hash 值的时间,而且同时,由于新增的 1bit 是 0 还是 1 可以认为是随机的,因此 resize 的过程,均匀的把之前的冲突的节点分散到新的 bucket 了。
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
// 超过最大值就不再扩充了,就只好随你碰撞去吧
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 没超过最大值,就扩充为原来的 2 倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
// 计算新的 resize 上限
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
// 把每个 bucket 都移动到新的 buckets 中
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
// 原索引
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
// 原索引+oldCap
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
// 原索引放到bucket里
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
// 原索引+oldCap放到bucket里
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}# #3. LinkedHashMap 类
# #3.1. LinkedHashMap 要点
LinkedHashMap 通过维护一个保存所有条目(Entry)的双向链表,保证了元素迭代的顺序(即插入顺序)。
| 关注点 | 结论 |
|---|---|
| 是否允许键值对为 null | Key 和 Value 都允许 null |
| 是否允许重复数据 | Key 重复会覆盖、Value 允许重复 |
| 是否有序 | 按照元素插入顺序存储 |
| 是否线程安全 | 非线程安全 |
# #3.2. LinkedHashMap 要点
# #LinkedHashMap 数据结构
LinkedHashMap 通过维护一对 LinkedHashMap.Entry<K,V> 类型的头尾指针,以双链表形式,保存所有数据。
学习过数据结构的双链表,就能理解其元素存储以及访问必然是有序的。
public class LinkedHashMap<K,V>
extends HashMap<K,V>
implements Map<K,V> {
// 双链表的头指针
transient LinkedHashMap.Entry<K,V> head;
// 双链表的尾指针
transient LinkedHashMap.Entry<K,V> tail;
// 迭代排序方法:true 表示访问顺序;false 表示插入顺序
final boolean accessOrder;
}LinkedHashMap 继承了 HashMap 的 put 方法,本身没有实现 put 方法。
# #4. TreeMap 类
# #4.1. TreeMap 要点
TreeMap 基于红黑树实现。
TreeMap 是有序的。它的排序规则是:根据 map 中的 key 的自然语义顺序或提供的比较器( Comparator )的自定义比较顺序。
TreeMap 不是线程安全的。
# #4.2. TreeMap 原理
# #put 方法
public V put(K key, V value) {
Entry<K,V> t = root;
// 如果根节点为 null,插入第一个节点
if (t == null) {
compare(key, key); // type (and possibly null) check
root = new Entry<>(key, value, null);
size = 1;
modCount++;
return null;
}
int cmp;
Entry<K,V> parent;
// split comparator and comparable paths
Comparator<? super K> cpr = comparator;
// 每个节点的左孩子节点的值小于它;右孩子节点的值大于它
// 如果有比较器,使用比较器进行比较
if (cpr != null) {
do {
parent = t;
cmp = cpr.compare(key, t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
// 没有比较器,使用 key 的自然顺序进行比较
else {
if (key == null)
throw new NullPointerException();
@SuppressWarnings("unchecked")
Comparable<? super K> k = (Comparable<? super K>) key;
do {
parent = t;
cmp = k.compareTo(t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
// 通过上面的遍历未找到 key 值,则新插入节点
Entry<K,V> e = new Entry<>(key, value, parent);
if (cmp < 0)
parent.left = e;
else
parent.right = e;
// 插入后,为了维持红黑树的平衡需要调整
fixAfterInsertion(e);
size++;
modCount++;
return null;
}# #get 方法
public V get(Object key) {
Entry<K,V> p = getEntry(key);
return (p==null ? null : p.value);
}
final Entry<K,V> getEntry(Object key) {
// Offload comparator-based version for sake of performance
if (comparator != null)
return getEntryUsingComparator(key);
if (key == null)
throw new NullPointerException();
@SuppressWarnings("unchecked")
Comparable<? super K> k = (Comparable<? super K>) key;
Entry<K,V> p = root;
// 按照二叉树搜索的方式进行搜索,搜到返回
while (p != null) {
int cmp = k.compareTo(p.key);
if (cmp < 0)
p = p.left;
else if (cmp > 0)
p = p.right;
else
return p;
}
return null;
}# #4.3. remove 方法
public V remove(Object key) {
Entry<K,V> p = getEntry(key);
if (p == null)
return null;
V oldValue = p.value;
deleteEntry(p);
return oldValue;
}
private void deleteEntry(Entry<K,V> p) {
modCount++;
size--;
// 如果当前节点有左右孩子节点,使用后继节点替换要删除的节点
// If strictly internal, copy successor's element to p and then make p
// point to successor.
if (p.left != null && p.right != null) {
Entry<K,V> s = successor(p);
p.key = s.key;
p.value = s.value;
p = s;
} // p has 2 children
// Start fixup at replacement node, if it exists.
Entry<K,V> replacement = (p.left != null ? p.left : p.right);
if (replacement != null) { // 要删除的节点有一个孩子节点
// Link replacement to parent
replacement.parent = p.parent;
if (p.parent == null)
root = replacement;
else if (p == p.parent.left)
p.parent.left = replacement;
else
D:\codes\zp\java\database\docs\redis\分布式锁.md p.parent.right = replacement;
// Null out links so they are OK to use by fixAfterDeletion.
p.left = p.right = p.parent = null;
// Fix replacement
if (p.color == BLACK)
fixAfterDeletion(replacement);
} else if (p.parent == null) { // return if we are the only node.
root = null;
} else { // No children. Use self as phantom replacement and unlink.
if (p.color == BLACK)
fixAfterDeletion(p);
if (p.parent != null) {
if (p == p.parent.left)
p.parent.left = null;
else if (p == p.parent.right)
p.parent.right = null;
p.parent = null;
}
}
}# #4.4. TreeMap 示例
public class TreeMapDemo {
private static final String[] chars = "A B C D E F G H I J K L M N O P Q R S T U V W X Y Z".split(" ");
public static void main(String[] args) {
TreeMap<Integer, String> treeMap = new TreeMap<>();
for (int i = 0; i < chars.length; i++) {
treeMap.put(i, chars[i]);
}
System.out.println(treeMap);
Integer low = treeMap.firstKey();
Integer high = treeMap.lastKey();
System.out.println(low);
System.out.println(high);
Iterator<Integer> it = treeMap.keySet().iterator();
for (int i = 0; i <= 6; i++) {
if (i == 3) { low = it.next(); }
if (i == 6) { high = it.next(); } else { it.next(); }
}
System.out.println(low);
System.out.println(high);
System.out.println(treeMap.subMap(low, high));
System.out.println(treeMap.headMap(high));
System.out.println(treeMap.tailMap(low));
}
}# #5. WeakHashMap
WeakHashMap 的定义如下:
public class WeakHashMap<K,V>
extends AbstractMap<K,V>
implements Map<K,V> {}WeakHashMap 继承了 AbstractMap,实现了 Map 接口。
和 HashMap 一样,WeakHashMap 也是一个散列表,它存储的内容也是键值对 (key-value) 映射,而且键和值都可以是 null。
不过 WeakHashMap 的键是弱键。在 WeakHashMap 中,当某个键不再被其它对象引用,会被从 WeakHashMap 中被自动移除。更精确地说,对于一个给定的键,其映射的存在并不阻止垃圾回收器对该键的丢弃,这就使该键成为可终止的,被终止,然后被回收。某个键被终止时,它对应的键值对也就从映射中有效地移除了。
这个弱键的原理呢?大致上就是,通过 WeakReference 和 ReferenceQueue 实现的。
WeakHashMap 的 key 是弱键,即是 WeakReference 类型的;ReferenceQueue 是一个队列,它会保存被 GC 回收的弱键。实现步骤是:
- 新建 WeakHashMap,将键值对添加到 WeakHashMap 中。实际上,WeakHashMap 是通过数组 table 保存 Entry (键值对);每一个 Entry 实际上是一个单向链表,即 Entry 是键值对链表。
- 当某弱键不再被其它对象引用,并被 GC 回收时。在 GC 回收该弱键时,这个弱键也同时会被添加到 ReferenceQueue (queue) 队列中。
- 当下一次我们需要操作 WeakHashMap 时,会先同步 table 和 queue。table 中保存了全部的键值对,而 queue 中保存被 GC 回收的键值对;同步它们,就是删除 table 中被 GC 回收的键值对。
这就是弱键如何被自动从 WeakHashMap 中删除的步骤了。
和 HashMap 一样,WeakHashMap 是不同步的。可以使用 Collections.synchronizedMap 方法来构造同步的 WeakHashMap。
# Java 容器之 Set
📦 本文以及示例源码已归档在 javacore(opens new window)
# #1. Set 简介
Set 家族成员简介:
Set继承了Collection的接口。实际上Set就是Collection,只是行为略有不同:Set集合不允许有重复元素。SortedSet继承了Set的接口。SortedSet中的内容是排序的唯一值,排序的方法是通过比较器 (Comparator)。NavigableSet继承了SortedSet的接口。它提供了丰富的查找方法:如 "获取大于 / 等于某值的元素"、“获取小于 / 等于某值的元素” 等等。AbstractSet是一个抽象类,它继承于AbstractCollection,AbstractCollection实现了 Set 中的绝大部分方法,为实现Set的实例类提供了便利。HashSet类依赖于HashMap,它实际上是通过HashMap实现的。HashSet中的元素是无序的、散列的。TreeSet类依赖于TreeMap,它实际上是通过TreeMap实现的。TreeSet中的元素是有序的,它是按自然排序或者用户指定比较器排序的 Set。LinkedHashSet是按插入顺序排序的 Set。EnumSet是只能存放 Emum 枚举类型的 Set。
# #1.1. Set 接口
Set 继承了 Collection 的接口。实际上, Set 就是 Collection ,二者提供的方法完全相同。
Set 接口定义如下:
public interface Set<E> extends Collection<E> {}# #1.2. SortedSet 接口
继承了 Set 的接口。 SortedSet 中的内容是排序的唯一值,排序的方法是通过比较器 (Comparator)。
SortedSet 接口定义如下:
public interface SortedSet<E> extends Set<E> {}SortedSet 接口新扩展的方法:
comparator- 返回 ComparatorsubSet- 返回指定区间的子集headSet- 返回小于指定元素的子集tailSet- 返回大于指定元素的子集first- 返回第一个元素last- 返回最后一个元素- spliterator
# #1.3. NavigableSet 接口
NavigableSet 继承了 SortedSet 。它提供了丰富的查找方法。
NavigableSet 接口定义如下:
public interface NavigableSet<E> extends SortedSet<E> {}NavigableSet 接口新扩展的方法:
- lower - 返回小于指定值的元素中最接近的元素
- higher - 返回大于指定值的元素中最接近的元素
- floor - 返回小于或等于指定值的元素中最接近的元素
- ceiling - 返回大于或等于指定值的元素中最接近的元素
- pollFirst - 检索并移除第一个(最小的)元素
- pollLast - 检索并移除最后一个(最大的)元素
- descendingSet - 返回反序排列的 Set
- descendingIterator - 返回反序排列的 Set 的迭代器
- subSet - 返回指定区间的子集
- headSet - 返回小于指定元素的子集
- tailSet - 返回大于指定元素的子集
# #1.4. AbstractSet 抽象类
AbstractSet 类提供 Set 接口的核心实现,以最大限度地减少实现 Set 接口所需的工作。
AbstractSet 抽象类定义如下:
public abstract class AbstractSet<E> extends AbstractCollection<E> implements Set<E> {}事实上,主要的实现已经在 AbstractCollection 中完成。
# #2. HashSet 类
HashSet 类依赖于 HashMap ,它实际上是通过 HashMap 实现的。 HashSet 中的元素是无序的、散列的。
HashSet 类定义如下:
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable {}# #2.1. HashSet 要点
HashSet通过继承AbstractSet实现了Set接口中的骨干方法。HashSet实现了Cloneable,所以支持克隆。HashSet实现了Serializable,所以支持序列化。HashSet中存储的元素是无序的。HashSet允许 null 值的元素。HashSet不是线程安全的。
# #2.2. HashSet 原理
HashSet 是基于 HashMap 实现的。
// HashSet 的核心,通过维护一个 HashMap 实体来实现 HashSet 方法
private transient HashMap<E,Object> map;
// PRESENT 是用于关联 map 中当前操作元素的一个虚拟值
private static final Object PRESENT = new Object();
}-
HashSet
HashMap 中维护了一个
HashSet 对象 map,
add 的重要方法,如
remove、
iterator、
clear、
size、 等都是围绕 map 实现的。 - `HashSet` 类中通过定义 `writeObject()` 和 `readObject()` 方法确定了其序列化和反序列化的机制。 - PRESENT 是用于关联 map 中当前操作元素的一个虚拟值。 ## [#](https://dunwu.github.io/javacore/container/java-container-set.html#_3-treeset-类)3. TreeSet 类 `TreeSet` 类依赖于 `TreeMap`,它实际上是通过 `TreeMap` 实现的。`TreeSet` 中的元素是有序的,它是按自然排序或者用户指定比较器排序的 Set。 `TreeSet` 类定义如下: ```java public class TreeSet<E> extends AbstractSet<E> implements NavigableSet<E>, Cloneable, java.io.Serializable {}
# #3.1. TreeSet 要点
TreeSet通过继承AbstractSet实现了NavigableSet接口中的骨干方法。TreeSet实现了Cloneable,所以支持克隆。TreeSet实现了Serializable,所以支持序列化。TreeSet中存储的元素是有序的。排序规则是自然顺序或比较器(Comparator)中提供的顺序规则。TreeSet不是线程安全的。
# #3.2. TreeSet 源码
TreeSet 是基于 TreeMap 实现的。
// TreeSet 的核心,通过维护一个 NavigableMap 实体来实现 TreeSet 方法
private transient NavigableMap<E,Object> m;
// PRESENT 是用于关联 map 中当前操作元素的一个虚拟值
private static final Object PRESENT = new Object();TreeSet中维护了一个NavigableMap对象 map(实际上是一个 TreeMap 实例),TreeSet的重要方法,如add、remove、iterator、clear、size等都是围绕 map 实现的。PRESENT是用于关联map中当前操作元素的一个虚拟值。TreeSet中的元素都被当成TreeMap的 key 存储,而 value 都填的是PRESENT。
# #4. LinkedHashSet 类
LinkedHashSet 是按插入顺序排序的 Set。
LinkedHashSet 类定义如下:
public class LinkedHashSet<E>
extends HashSet<E>
implements Set<E>, Cloneable, java.io.Serializable {}# #4.1. LinkedHashSet 要点
LinkedHashSet通过继承HashSet实现了Set接口中的骨干方法。LinkedHashSet实现了Cloneable,所以支持克隆。LinkedHashSet实现了Serializable,所以支持序列化。LinkedHashSet中存储的元素是按照插入顺序保存的。LinkedHashSet不是线程安全的。
# #4.2. LinkedHashSet 原理
LinkedHashSet 有三个构造方法,无一例外,都是调用父类 HashSet 的构造方法。
public LinkedHashSet(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor, true);
}
public LinkedHashSet(int initialCapacity) {
super(initialCapacity, .75f, true);
}
public LinkedHashSet() {
super(16, .75f, true);
}需要强调的是:LinkedHashSet 构造方法实际上调用的是父类 HashSet 的非 public 构造方法。
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}不同于 HashSet public 构造方法中初始化的 HashMap 实例,这个构造方法中,初始化了 LinkedHashMap 实例。
也就是说,实际上, LinkedHashSet 维护了一个双链表。由双链表的特性可以知道,它是按照元素的插入顺序保存的。所以,这就是 LinkedHashSet 中存储的元素是按照插入顺序保存的原理。
# #5. EnumSet 类
EnumSet 类定义如下:
public abstract class EnumSet<E extends Enum<E>> extends AbstractSet<E>
implements Cloneable, java.io.Serializable {}# #5.1. EnumSet 要点
EnumSet继承了AbstractSet,所以有Set接口中的骨干方法。EnumSet实现了Cloneable,所以支持克隆。EnumSet实现了Serializable,所以支持序列化。EnumSet通过<E extends Enum<E>>限定了存储元素必须是枚举值。EnumSet没有构造方法,只能通过类中的static方法来创建EnumSet对象。EnumSet是有序的。以枚举值在EnumSet类中的定义顺序来决定集合元素的顺序。EnumSet不是线程安全的。
# #6. 要点总结
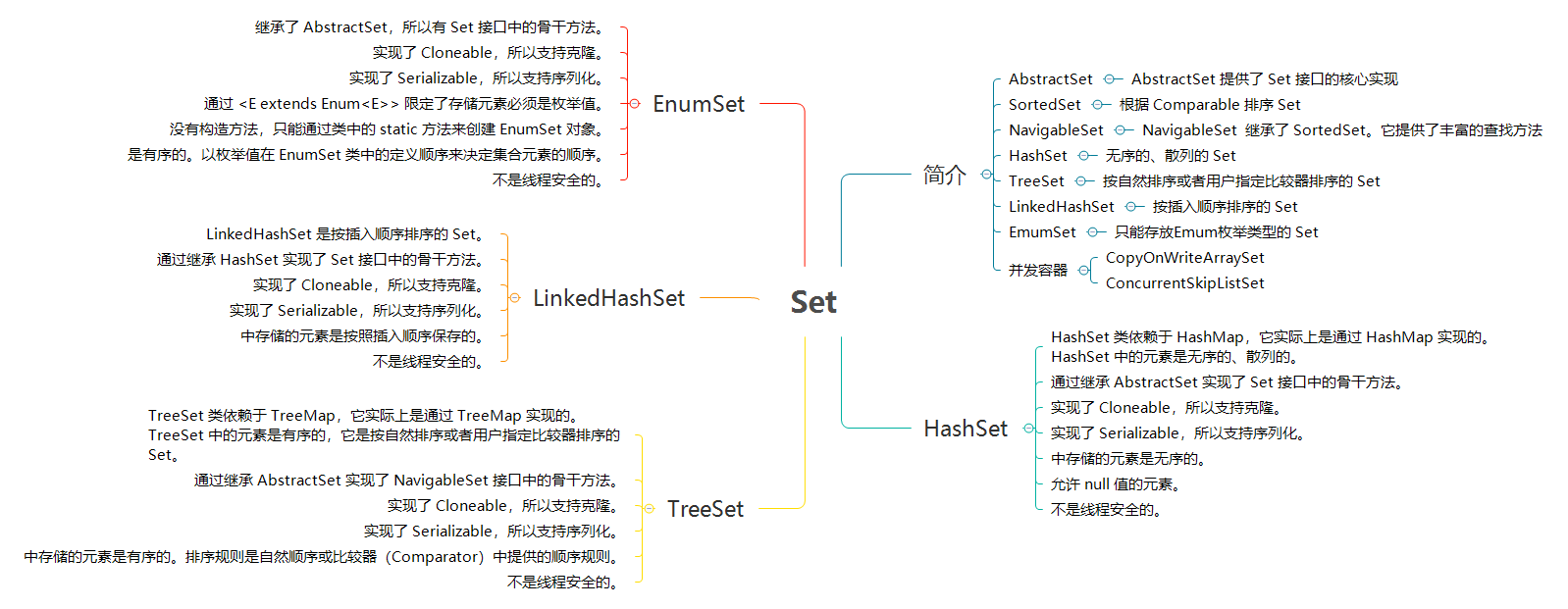
# Java 容器之 Queue
📦 本文以及示例源码已归档在 javacore(opens new window)
- \1. Queue 简介
- 2. ArrayDeque
- 3. LinkedList
- 4. PriorityQueue
- 5. 参考资料
# #1. Queue 简介
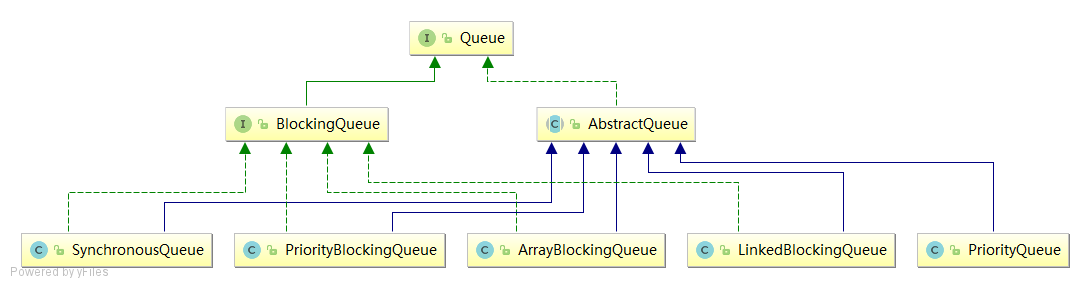
# #1.1. Queue 接口
Queue 接口定义如下:
public interface Queue<E> extends Collection<E> {}# #1.2. AbstractQueue 抽象类
AbstractQueue 类提供 Queue 接口的核心实现,以最大限度地减少实现 Queue 接口所需的工作。
AbstractQueue 抽象类定义如下:
public abstract class AbstractQueue<E>
extends AbstractCollection<E>
implements Queue<E> {}# #1.3. Deque 接口
Deque 接口是 double ended queue 的缩写,即双端队列。Deque 继承 Queue 接口,并扩展支持在队列的两端插入和删除元素。
所以提供了特定的方法,如:
- 尾部插入时需要的 addLast(e) (opens new window)、offerLast(e) (opens new window)。
- 尾部删除所需要的 removeLast() (opens new window)、pollLast() (opens new window)。
大多数的实现对元素的数量没有限制,但这个接口既支持有容量限制的 deque,也支持没有固定大小限制的。
# #2. ArrayDeque
ArrayDeque 是 Deque 的顺序表实现。
ArrayDeque 用一个动态数组实现了栈和队列所需的所有操作。
# #3. LinkedList
LinkedList 是 Deque 的链表实现。
示例:
public class LinkedListQueueDemo {
public static void main(String[] args) {
//add()和remove()方法在失败的时候会抛出异常(不推荐)
Queue<String> queue = new LinkedList<>();
queue.offer("a"); // 入队
queue.offer("b"); // 入队
queue.offer("c"); // 入队
for (String q : queue) {
System.out.println(q);
}
System.out.println("===");
System.out.println("poll=" + queue.poll()); // 出队
for (String q : queue) {
System.out.println(q);
}
System.out.println("===");
System.out.println("element=" + queue.element()); //返回第一个元素
for (String q : queue) {
System.out.println(q);
}
System.out.println("===");
System.out.println("peek=" + queue.peek()); //返回第一个元素
for (String q : queue) {
System.out.println(q);
}
}
}# #4. PriorityQueue
PriorityQueue 类定义如下:
public class PriorityQueue<E> extends AbstractQueue<E>
implements java.io.Serializable {}PriorityQueue 要点:
PriorityQueue实现了Serializable,支持序列化。PriorityQueue类是无界优先级队列。PriorityQueue中的元素根据自然顺序或Comparator提供的顺序排序。PriorityQueue不接受 null 值元素。PriorityQueue不是线程安全的。
# Java IO 模型
📦 本文以及示例源码已归档在 javacore(opens new window)
所谓的 I/O,就是计算机内存与外部设备之间拷贝数据的过程。由于 CPU 访问内存的速度远远高于外部设备,因此 CPU 是先把外部设备的数据读到内存里,然后再进行处理。
关键词:
InputStream、OutputStream、Reader、Writer
# #UNIX I/O 模型
UNIX 系统下的 I/O 模型有 5 种:
- 同步阻塞 I/O
- 同步非阻塞 I/O
- I/O 多路复用
- 信号驱动 I/O
- 异步 I/O
如何去理解 UNIX I/O 模型,大致有以下两个维度:
- 区分同步或异步(synchronous/asynchronous)。简单来说,同步是一种可靠的有序运行机制,当我们进行同步操作时,后续的任务是等待当前调用返回,才会进行下一步;而异步则相反,其他任务不需要等待当前调用返回,通常依靠事件、回调等机制来实现任务间次序关系。
- 区分阻塞与非阻塞(blocking/non-blocking)。在进行阻塞操作时,当前线程会处于阻塞状态,无法从事其他任务,只有当条件就绪才能继续,比如 ServerSocket 新连接建立完毕,或数据读取、写入操作完成;而非阻塞则是不管 IO 操作是否结束,直接返回,相应操作在后台继续处理。
不能一概而论认为同步或阻塞就是低效,具体还要看应用和系统特征。
对于一个网络 I/O 通信过程,比如网络数据读取,会涉及两个对象,一个是调用这个 I/O 操作的用户线程,另外一个就是操作系统内核。一个进程的地址空间分为用户空间和内核空间,用户线程不能直接访问内核空间。
当用户线程发起 I/O 操作后,网络数据读取操作会经历两个步骤:
- 用户线程等待内核将数据从网卡拷贝到内核空间。
- 内核将数据从内核空间拷贝到用户空间。
各种 I/O 模型的区别就是:它们实现这两个步骤的方式是不一样的。
# #同步阻塞 I/O
用户线程发起 read 调用后就阻塞了,让出 CPU。内核等待网卡数据到来,把数据从网卡拷贝到内核空间,接着把数据拷贝到用户空间,再把用户线程叫醒。
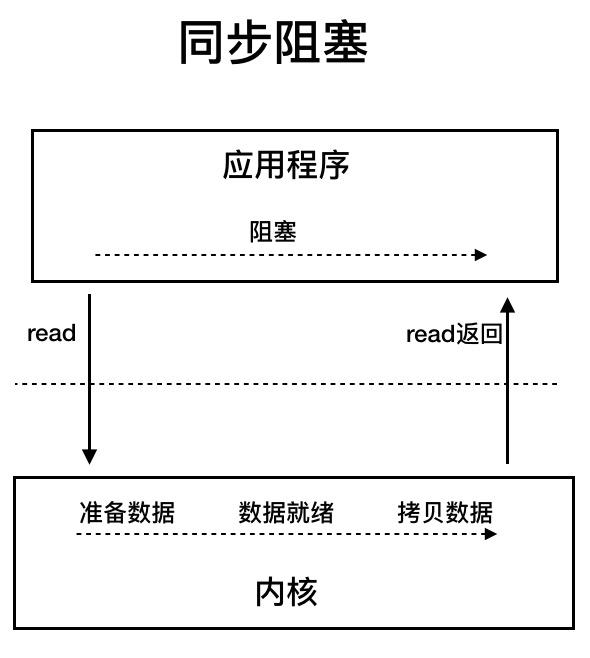
# #同步非阻塞 I/O
用户线程不断的发起 read 调用,数据没到内核空间时,每次都返回失败,直到数据到了内核空间,这一次 read 调用后,在等待数据从内核空间拷贝到用户空间这段时间里,线程还是阻塞的,等数据到了用户空间再把线程叫醒。
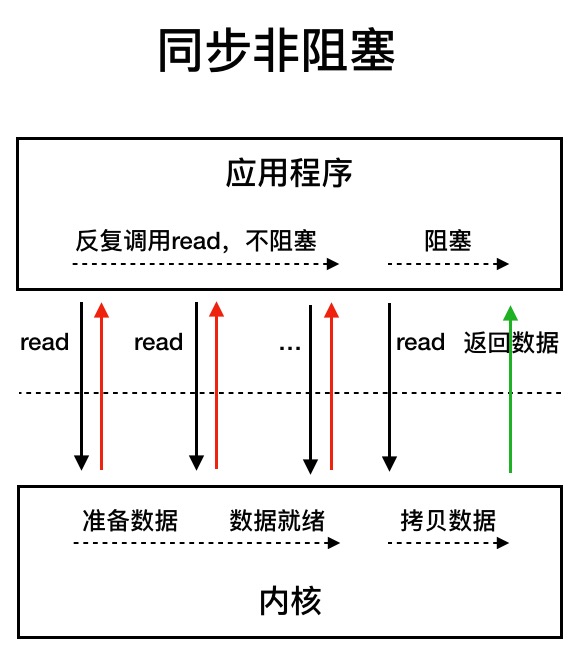
# #I/O 多路复用
用户线程的读取操作分成两步了,线程先发起 select 调用,目的是问内核数据准备好了吗?等内核把数据准备好了,用户线程再发起 read 调用。在等待数据从内核空间拷贝到用户空间这段时间里,线程还是阻塞的。那为什么叫 I/O 多路复用呢?因为一次 select 调用可以向内核查多个数据通道(Channel)的状态,所以叫多路复用。
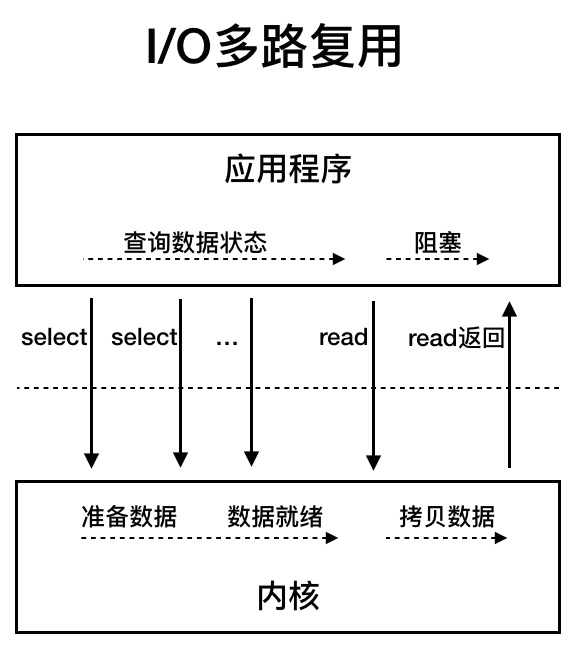
# #信号驱动 I/O
首先开启 Socket 的信号驱动 I/O 功能,并安装一个信号处理函数,进程继续运行并不阻塞。当数据准备好时,进程会收到一个 SIGIO 信号,可以在信号处理函数中调用 I/O 操作函数处理数据。信号驱动式 I/O 模型的优点是我们在数据报到达期间进程不会被阻塞,我们只要等待信号处理函数的通知即可
# #异步 I/O
用户线程发起 read 调用的同时注册一个回调函数,read 立即返回,等内核将数据准备好后,再调用指定的回调函数完成处理。在这个过程中,用户线程一直没有阻塞。
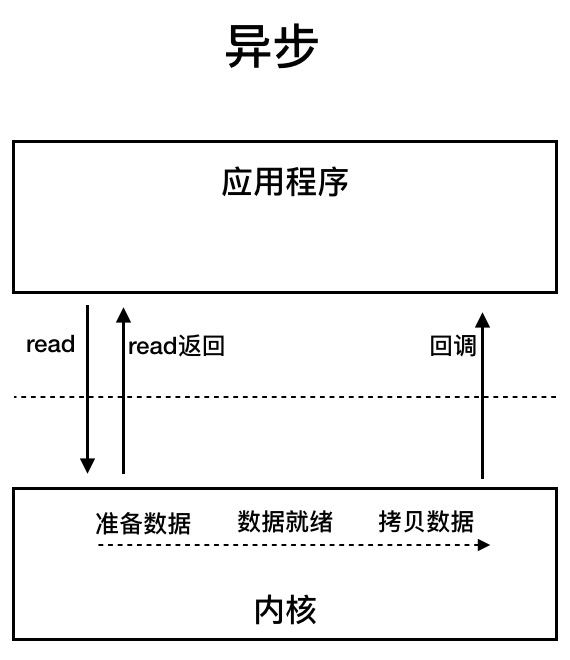
# #Java I/O 模型
# #BIO
BIO(blocking IO) 即阻塞 IO。指的主要是传统的
java.io包,它基于流模型实现。
# #BIO 简介
java.io 包提供了我们最熟知的一些 IO 功能,比如 File 抽象、输入输出流等。交互方式是同步、阻塞的方式,也就是说,在读取输入流或者写入输出流时,在读、写动作完成之前,线程会一直阻塞在那里,它们之间的调用是可靠的线性顺序。
很多时候,人们也把 java.net 下面提供的部分网络 API,比如 Socket 、 ServerSocket 、 HttpURLConnection 也归类到同步阻塞 IO 类库,因为网络通信同样是 IO 行为。
BIO 的优点是代码比较简单、直观;缺点则是 IO 效率和扩展性存在局限性,容易成为应用性能的瓶颈。
# #BIO 的性能缺陷
BIO 会阻塞进程,不适合高并发场景。
采用 BIO 的服务端,通常由一个独立的 Acceptor 线程负责监听客户端连接。服务端一般在 while(true) 循环中调用 accept() 方法等待客户端的连接请求,一旦接收到一个连接请求,就可以建立 Socket,并基于这个 Socket 进行读写操作。此时,不能再接收其他客户端连接请求,只能等待当前连接的操作执行完成。
如果要让 BIO 通信模型 能够同时处理多个客户端请求,就必须使用多线程(主要原因是 socket.accept() 、 socket.read() 、 socket.write() 涉及的三个主要函数都是同步阻塞的),但会造成不必要的线程开销。不过可以通过 线程池机制 改善,线程池还可以让线程的创建和回收成本相对较低。
即使可以用线程池略微优化,但是会消耗宝贵的线程资源,并且在百万级并发场景下也撑不住。如果并发访问量增加会导致线程数急剧膨胀可能会导致线程堆栈溢出、创建新线程失败等问题,最终导致进程宕机或者僵死,不能对外提供服务。
# #NIO
NIO(non-blocking IO) 即非阻塞 IO。指的是 Java 1.4 中引入的
java.nio包。
为了解决 BIO 的性能问题, Java 1.4 中引入的 java.nio 包。NIO 优化了内存复制以及阻塞导致的严重性能问题。
java.nio 包提供了 Channel 、 Selector 、 Buffer 等新的抽象,可以构建多路复用的、同步非阻塞 IO 程序,同时提供了更接近操作系统底层的高性能数据操作方式。
NIO 有哪些性能优化点呢?
# #使用缓冲区优化读写流
NIO 与传统 I/O 不同,它是基于块(Block)的,它以块为基本单位处理数据。在 NIO 中,最为重要的两个组件是缓冲区( Buffer )和通道( Channel )。
Buffer 是一块连续的内存块,是 NIO 读写数据的缓冲。 Buffer 可以将文件一次性读入内存再做后续处理,而传统的方式是边读文件边处理数据。 Channel 表示缓冲数据的源头或者目的地,它用于读取缓冲或者写入数据,是访问缓冲的接口。
# #使用 DirectBuffer 减少内存复制
NIO 还提供了一个可以直接访问物理内存的类 DirectBuffer 。普通的 Buffer 分配的是 JVM 堆内存,而 DirectBuffer 是直接分配物理内存。
数据要输出到外部设备,必须先从用户空间复制到内核空间,再复制到输出设备,而 DirectBuffer 则是直接将步骤简化为从内核空间复制到外部设备,减少了数据拷贝。
这里拓展一点,由于 DirectBuffer 申请的是非 JVM 的物理内存,所以创建和销毁的代价很高。 DirectBuffer 申请的内存并不是直接由 JVM 负责垃圾回收,但在 DirectBuffer 包装类被回收时,会通过 Java 引用机制来释放该内存块。
# #优化 I/O,避免阻塞
传统 I/O 的数据读写是在用户空间和内核空间来回复制,而内核空间的数据是通过操作系统层面的 I/O 接口从磁盘读取或写入。
NIO 的 Channel 有自己的处理器,可以完成内核空间和磁盘之间的 I/O 操作。在 NIO 中,我们读取和写入数据都要通过 Channel ,由于 Channel 是双向的,所以读、写可以同时进行。
# #AIO
AIO(Asynchronous IO) 即异步非阻塞 IO,指的是 Java 7 中,对 NIO 有了进一步的改进,也称为 NIO2,引入了异步非阻塞 IO 方式。
在 Java 7 中,NIO 有了进一步的改进,也就是 NIO 2,引入了异步非阻塞 IO 方式,也有很多人叫它 AIO(Asynchronous IO)。异步 IO 操作基于事件和回调机制,可以简单理解为,应用操作直接返回,而不会阻塞在那里,当后台处理完成,操作系统会通知相应线程进行后续工作。
# #传统 IO 流
流从概念上来说是一个连续的数据流。当程序需要读数据的时候就需要使用输入流读取数据,当需要往外写数据的时候就需要输出流。
BIO 中操作的流主要有两大类,字节流和字符流,两类根据流的方向都可以分为输入流和输出流。
- 字节流
- 输入字节流:
InputStream - 输出字节流:
OutputStream
- 输入字节流:
- 字符流
- 输入字符流:
Reader - 输出字符流:
Writer
- 输入字符流:
# #字节流
字节流主要操作字节数据或二进制对象。
字节流有两个核心抽象类: InputStream 和 OutputStream 。所有的字节流类都继承自这两个抽象类。
# #文件字节流
FileOutputStream 和 FileInputStream 提供了读写字节到文件的能力。
文件流操作一般步骤:
- 使用
File类绑定一个文件。 - 把
File对象绑定到流对象上。 - 进行读或写操作。
- 关闭流
FileOutputStream 和 FileInputStream 示例:
public class FileStreamDemo {
private static final String FILEPATH = "temp.log";
public static void main(String[] args) throws Exception {
write(FILEPATH);
read(FILEPATH);
}
public static void write(String filepath) throws IOException {
// 第1步、使用File类找到一个文件
File f = new File(filepath);
// 第2步、通过子类实例化父类对象
OutputStream out = new FileOutputStream(f);
// 实例化时,默认为覆盖原文件内容方式;如果添加true参数,则变为对原文件追加内容的方式。
// OutputStream out = new FileOutputStream(f, true);
// 第3步、进行写操作
String str = "Hello World\n";
byte[] bytes = str.getBytes();
out.write(bytes);
// 第4步、关闭输出流
out.close();
}
public static void read(String filepath) throws IOException {
// 第1步、使用File类找到一个文件
File f = new File(filepath);
// 第2步、通过子类实例化父类对象
InputStream input = new FileInputStream(f);
// 第3步、进行读操作
// 有三种读取方式,体会其差异
byte[] bytes = new byte[(int) f.length()];
int len = input.read(bytes); // 读取内容
System.out.println("读入数据的长度:" + len);
// 第4步、关闭输入流
input.close();
System.out.println("内容为:\n" + new String(bytes));
}
}# #内存字节流
ByteArrayInputStream 和 ByteArrayOutputStream 是用来完成内存的输入和输出功能。
内存操作流一般在生成一些临时信息时才使用。 如果临时信息保存在文件中,还需要在有效期过后删除文件,这样比较麻烦。
ByteArrayInputStream 和 ByteArrayOutputStream 示例:
public class ByteArrayStreamDemo {
public static void main(String[] args) {
String str = "HELLOWORLD"; // 定义一个字符串,全部由大写字母组成
ByteArrayInputStream bis = new ByteArrayInputStream(str.getBytes());
ByteArrayOutputStream bos = new ByteArrayOutputStream();
// 准备从内存ByteArrayInputStream中读取内容
int temp = 0;
while ((temp = bis.read()) != -1) {
char c = (char) temp; // 读取的数字变为字符
bos.write(Character.toLowerCase(c)); // 将字符变为小写
}
// 所有的数据就全部都在ByteArrayOutputStream中
String newStr = bos.toString(); // 取出内容
try {
bis.close();
bos.close();
} catch (IOException e) {
e.printStackTrace();
}
System.out.println(newStr);
}
}# #管道流
管道流的主要作用是可以进行两个线程间的通信。
如果要进行管道通信,则必须把 PipedOutputStream 连接在 PipedInputStream 上。为此, PipedOutputStream 中提供了 connect() 方法。
public class PipedStreamDemo {
public static void main(String[] args) {
Send s = new Send();
Receive r = new Receive();
try {
s.getPos().connect(r.getPis()); // 连接管道
} catch (IOException e) {
e.printStackTrace();
}
new Thread(s).start(); // 启动线程
new Thread(r).start(); // 启动线程
}
static class Send implements Runnable {
private PipedOutputStream pos = null;
Send() {
pos = new PipedOutputStream(); // 实例化输出流
}
@Override
public void run() {
String str = "Hello World!!!";
try {
pos.write(str.getBytes());
} catch (IOException e) {
e.printStackTrace();
}
try {
pos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 得到此线程的管道输出流
*/
PipedOutputStream getPos() {
return pos;
}
}
static class Receive implements Runnable {
private PipedInputStream pis = null;
Receive() {
pis = new PipedInputStream();
}
@Override
public void run() {
byte[] b = new byte[1024];
int len = 0;
try {
len = pis.read(b);
} catch (IOException e) {
e.printStackTrace();
}
try {
pis.close();
} catch (IOException e) {
e.printStackTrace();
}
System.out.println("接收的内容为:" + new String(b, 0, len));
}
/**
* 得到此线程的管道输入流
*/
PipedInputStream getPis() {
return pis;
}
}
}# #对象字节流
ObjectInputStream 和 ObjectOutputStream 是对象输入输出流,一般用于对象序列化。
这里不展开叙述,想了解详细内容和示例可以参考:Java 序列化
# #数据操作流
数据操作流提供了格式化读入和输出数据的方法,分别为 DataInputStream 和 DataOutputStream 。
DataInputStream 和 DataOutputStream 格式化读写数据示例:
public class DataStreamDemo {
public static final String FILEPATH = "temp.log";
public static void main(String[] args) throws IOException {
write(FILEPATH);
read(FILEPATH);
}
private static void write(String filepath) throws IOException {
// 1.使用 File 类绑定一个文件
File f = new File(filepath);
// 2.把 File 对象绑定到流对象上
DataOutputStream dos = new DataOutputStream(new FileOutputStream(f));
// 3.进行读或写操作
String[] names = { "衬衣", "手套", "围巾" };
float[] prices = { 98.3f, 30.3f, 50.5f };
int[] nums = { 3, 2, 1 };
for (int i = 0; i < names.length; i++) {
dos.writeChars(names[i]);
dos.writeChar('\t');
dos.writeFloat(prices[i]);
dos.writeChar('\t');
dos.writeInt(nums[i]);
dos.writeChar('\n');
}
// 4.关闭流
dos.close();
}
private static void read(String filepath) throws IOException {
// 1.使用 File 类绑定一个文件
File f = new File(filepath);
// 2.把 File 对象绑定到流对象上
DataInputStream dis = new DataInputStream(new FileInputStream(f));
// 3.进行读或写操作
String name = null; // 接收名称
float price = 0.0f; // 接收价格
int num = 0; // 接收数量
char[] temp = null; // 接收商品名称
int len = 0; // 保存读取数据的个数
char c = 0; // '\u0000'
try {
while (true) {
temp = new char[200]; // 开辟空间
len = 0;
while ((c = dis.readChar()) != '\t') { // 接收内容
temp[len] = c;
len++; // 读取长度加1
}
name = new String(temp, 0, len); // 将字符数组变为String
price = dis.readFloat(); // 读取价格
dis.readChar(); // 读取\t
num = dis.readInt(); // 读取int
dis.readChar(); // 读取\n
System.out.printf("名称:%s;价格:%5.2f;数量:%d\n", name, price, num);
}
} catch (EOFException e) {
System.out.println("结束");
} catch (IOException e) {
e.printStackTrace();
}
// 4.关闭流
dis.close();
}
}# #合并流
合并流的主要功能是将多个 InputStream 合并为一个 InputStream 流。合并流的功能由 SequenceInputStream 完成。
public class SequenceInputStreamDemo {
public static void main(String[] args) throws Exception {
InputStream is1 = new FileInputStream("temp1.log");
InputStream is2 = new FileInputStream("temp2.log");
SequenceInputStream sis = new SequenceInputStream(is1, is2);
int temp = 0; // 接收内容
OutputStream os = new FileOutputStream("temp3.logt");
while ((temp = sis.read()) != -1) { // 循环输出
os.write(temp); // 保存内容
}
sis.close(); // 关闭合并流
is1.close(); // 关闭输入流1
is2.close(); // 关闭输入流2
os.close(); // 关闭输出流
}
}# #字符流
字符流主要操作字符,一个字符等于两个字节。
字符流有两个核心类: Reader 类和 Writer 。所有的字符流类都继承自这两个抽象类。
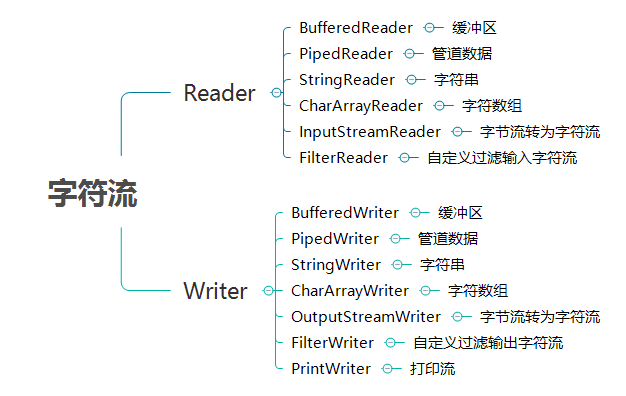
# #文件字符流
文件字符流 FileReader 和 FileWriter 可以向文件读写文本数据。
FileReader 和 FileWriter 读写文件示例:
public class FileReadWriteDemo {
private static final String FILEPATH = "temp.log";
public static void main(String[] args) throws IOException {
write(FILEPATH);
System.out.println("内容为:" + new String(read(FILEPATH)));
}
public static void write(String filepath) throws IOException {
// 1.使用 File 类绑定一个文件
File f = new File(filepath);
// 2.把 File 对象绑定到流对象上
Writer out = new FileWriter(f);
// Writer out = new FileWriter(f, true); // 追加内容方式
// 3.进行读或写操作
String str = "Hello World!!!\r\n";
out.write(str);
// 4.关闭流
// 字符流操作时使用了缓冲区,并在关闭字符流时会强制将缓冲区内容输出
// 如果不关闭流,则缓冲区的内容是无法输出的
// 如果想在不关闭流时,将缓冲区内容输出,可以使用 flush 强制清空缓冲区
out.flush();
out.close();
}
public static char[] read(String filepath) throws IOException {
// 1.使用 File 类绑定一个文件
File f = new File(filepath);
// 2.把 File 对象绑定到流对象上
Reader input = new FileReader(f);
// 3.进行读或写操作
int temp = 0; // 接收每一个内容
int len = 0; // 读取内容
char[] c = new char[1024];
while ((temp = input.read()) != -1) {
// 如果不是-1就表示还有内容,可以继续读取
c[len] = (char) temp;
len++;
}
System.out.println("文件字符数为:" + len);
// 4.关闭流
input.close();
return c;
}
}# #字节流转换字符流
我们可以在程序中通过 InputStream 和 Reader 从数据源中读取数据,然后也可以在程序中将数据通过 OutputStream 和 Writer 输出到目标媒介中
使用 InputStreamReader 可以将输入字节流转化为输入字符流;使用 OutputStreamWriter 可以将输出字节流转化为输出字符流。
OutputStreamWriter 示例:
public class OutputStreamWriterDemo {
public static void main(String[] args) throws IOException {
File f = new File("temp.log");
Writer out = new OutputStreamWriter(new FileOutputStream(f));
out.write("hello world!!");
out.close();
}
}InputStreamReader 示例:
public class InputStreamReaderDemo {
public static void main(String[] args) throws IOException {
File f = new File("temp.log");
Reader reader = new InputStreamReader(new FileInputStream(f));
char[] c = new char[1024];
int len = reader.read(c);
reader.close();
System.out.println(new String(c, 0, len));
}
}# #字节流 vs. 字符流
相同点:
字节流和字符流都有 read() 、 write() 、 flush() 、 close() 这样的方法,这决定了它们的操作方式近似。
不同点:
- 数据类型
- 字节流的数据是字节(二进制对象)。主要核心类是
InputStream类和OutputStream类。 - 字符流的数据是字符,一个字符等于两个字节。主要核心类是
Reader类和Writer类。
- 字节流的数据是字节(二进制对象)。主要核心类是
- 缓冲区
- 字节流在操作时本身不会用到缓冲区(内存),是文件直接操作的。
- 字符流在操作时是使用了缓冲区,通过缓冲区再操作文件。
选择:
所有的文件在硬盘或传输时都是以字节方式保存的,例如图片,影音文件等都是按字节方式存储的。字符流无法读写这些文件。
所以,除了纯文本数据文件使用字符流以外,其他文件类型都应该使用字节流方式。
# Java NIO
📦 本文以及示例源码已归档在 javacore(opens new window)
关键词:
Channel、Buffer、Selector、非阻塞、多路复用
- 一、NIO 简介
- 二、Channel (通道)
- 三、Buffer (缓冲区)
- 四、Selector (选择器)
- 五、NIO vs. BIO
- 参考资料
# #一、NIO 简介
NIO 是一种同步非阻塞的 I/O 模型,在 Java 1.4 中引入了 NIO 框架,对应 java.nio 包,提供了 Channel 、 Selector 、 Buffer 等抽象。
NIO 中的 N 可以理解为 Non-blocking,不单纯是 New。它支持面向缓冲的,基于通道的 I/O 操作方法。 NIO 提供了与传统 BIO 模型中的 Socket 和 ServerSocket 相对应的 SocketChannel 和 ServerSocketChannel 两种不同的套接字通道实现,两种通道都支持阻塞和非阻塞两种模式。阻塞模式使用就像传统中的支持一样,比较简单,但是性能和可靠性都不好;非阻塞模式正好与之相反。对于低负载、低并发的应用程序,可以使用同步阻塞 I/O 来提升开发速率和更好的维护性;对于高负载、高并发的(网络)应用,应使用 NIO 的非阻塞模式来开发。
# #NIO 和 BIO 的区别
# #Non-blocking IO (非阻塞)
BIO 是阻塞的,NIO 是非阻塞的。
BIO 的各种流是阻塞的。这意味着,当一个线程调用 read() 或 write() 时,该线程被阻塞,直到有一些数据被读取,或数据完全写入。在此期间,该线程不能再干其他任何事。
NIO 使我们可以进行非阻塞 IO 操作。比如说,单线程中从通道读取数据到 buffer,同时可以继续做别的事情,当数据读取到 buffer 中后,线程再继续处理数据。写数据也是一样的。另外,非阻塞写也是如此。一个线程请求写入一些数据到某通道,但不需要等待它完全写入,这个线程同时可以去做别的事情。
# #Buffer (缓冲区)
BIO 面向流 (Stream oriented),而 NIO 面向缓冲区 (Buffer oriented)。
Buffer 是一个对象,它包含一些要写入或者要读出的数据。在 NIO 类库中加入 Buffer 对象,体现了 NIO 与 BIO 的一个重要区别。在面向流的 BIO 中可以将数据直接写入或者将数据直接读到 Stream 对象中。虽然 Stream 中也有 Buffer 开头的扩展类,但只是流的包装类,还是从流读到缓冲区,而 NIO 却是直接读到 Buffer 中进行操作。
在 NIO 厍中,所有数据都是用缓冲区处理的。在读取数据时,它是直接读缓冲区中的数据;在写入数据时,写入到缓冲区中。任何时候访问 NIO 中的数据,都是通过缓冲区进行操作。
最常用的缓冲区是 ByteBuffer, 一个 ByteBuffer 提供了一组功能用于操作 byte 数组。除了 ByteBuffer, 还有其他的一些缓冲区,事实上,每一种 Java 基本类型(除了 Boolean 类型)都对应有一种缓冲区。
# #Channel (通道)
NIO 通过 Channel(通道) 进行读写。
通道是双向的,可读也可写,而流的读写是单向的。无论读写,通道只能和 Buffer 交互。因为 Buffer,通道可以异步地读写。
# #Selector (选择器)
NIO 有选择器,而 IO 没有。
选择器用于使用单个线程处理多个通道。因此,它需要较少的线程来处理这些通道。线程之间的切换对于操作系统来说是昂贵的。 因此,为了提高系统效率选择器是有用的。
# #NIO 的基本流程
通常来说 NIO 中的所有 IO 都是从 Channel(通道) 开始的。
- 从通道进行数据读取 :创建一个缓冲区,然后请求通道读取数据。
- 从通道进行数据写入 :创建一个缓冲区,填充数据,并要求通道写入数据。
# #NIO 核心组件
NIO 包含下面几个核心的组件:
- Channel (通道)
- Buffer (缓冲区)
- Selector (选择器)
# #二、Channel (通道)
通道( Channel )是对 BIO 中的流的模拟,可以通过它读写数据。
Channel,类似在 Linux 之类操作系统上看到的文件描述符,是 NIO 中被用来支持批量式 IO 操作的一种抽象。
File 或者 Socket,通常被认为是比较高层次的抽象,而 Channel 则是更加操作系统底层的一种抽象,这也使得 NIO 得以充分利用现代操作系统底层机制,获得特定场景的性能优化,例如,DMA(Direct Memory Access)等。不同层次的抽象是相互关联的,我们可以通过 Socket 获取 Channel,反之亦然。
通道与流的不同之处在于:
- 流是单向的 - 一个流只能单纯的负责读或写。
- 通道是双向的 - 一个通道可以同时用于读写。
通道包括以下类型:
FileChannel:从文件中读写数据;DatagramChannel:通过 UDP 读写网络中数据;SocketChannel:通过 TCP 读写网络中数据;ServerSocketChannel:可以监听新进来的 TCP 连接,对每一个新进来的连接都会创建一个 SocketChannel。
# #三、Buffer (缓冲区)
NIO 与传统 I/O 不同,它是基于块(Block)的,它以块为基本单位处理数据。 Buffer 是一块连续的内存块,是 NIO 读写数据的缓冲。 Buffer 可以将文件一次性读入内存再做后续处理,而传统的方式是边读文件边处理数据。
向 Channel 读写的数据都必须先置于缓冲区中。也就是说,不会直接对通道进行读写数据,而是要先经过缓冲区。缓冲区实质上是一个数组,但它不仅仅是一个数组。缓冲区提供了对数据的结构化访问,而且还可以跟踪系统的读 / 写进程。
BIO 和 NIO 已经很好地集成了, java.io.* 已经以 NIO 为基础重新实现了,所以现在它可以利用 NIO 的一些特性。例如, java.io.* 包中的一些类包含以块的形式读写数据的方法,这使得即使在面向流的系统中,处理速度也会更快。
缓冲区包括以下类型:
ByteBufferCharBufferShortBufferIntBufferLongBufferFloatBufferDoubleBuffer
# #缓冲区状态变量
capacity:最大容量;position:当前已经读写的字节数;limit:还可以读写的字节数。mark:记录上一次 postion 的位置,默认是 0,算是一个便利性的考虑,往往不是必须 的。
缓冲区状态变量的改变过程举例:
- 新建一个大小为 8 个字节的缓冲区,此时 position 为 0,而 limit = capacity = 8。capacity 变量不会改变,下面的讨论会忽略它。
- 从输入通道中读取 5 个字节数据写入缓冲区中,此时 position 移动设置为 5,limit 保持不变。
- 在将缓冲区的数据写到输出通道之前,需要先调用 flip () 方法,这个方法将 limit 设置为当前 position,并将 position 设置为 0。
- 从缓冲区中取 4 个字节到输出缓冲中,此时 position 设为 4。
- 最后需要调用 clear () 方法来清空缓冲区,此时 position 和 limit 都被设置为最初位置。
# #文件 NIO 示例
以下展示了使用 NIO 快速复制文件的实例:
public static void fastCopy(String src, String dist) throws IOException {
/* 获得源文件的输入字节流 */
FileInputStream fin = new FileInputStream(src);
/* 获取输入字节流的文件通道 */
FileChannel fcin = fin.getChannel();
/* 获取目标文件的输出字节流 */
FileOutputStream fout = new FileOutputStream(dist);
/* 获取输出字节流的通道 */
FileChannel fcout = fout.getChannel();
/* 为缓冲区分配 1024 个字节 */
ByteBuffer buffer = ByteBuffer.allocateDirect(1024);
while (true) {
/* 从输入通道中读取数据到缓冲区中 */
int r = fcin.read(buffer);
/* read() 返回 -1 表示 EOF */
if (r == -1) {
break;
}
/* 切换读写 */
buffer.flip();
/* 把缓冲区的内容写入输出文件中 */
fcout.write(buffer);
/* 清空缓冲区 */
buffer.clear();
}
}# #DirectBuffer
NIO 还提供了一个可以直接访问物理内存的类 DirectBuffer 。普通的 Buffer 分配的是 JVM 堆内存,而 DirectBuffer 是直接分配物理内存。
数据要输出到外部设备,必须先从用户空间复制到内核空间,再复制到输出设备,而 DirectBuffer 则是直接将步骤简化为从内核空间复制到外部设备,减少了数据拷贝。
这里拓展一点,由于 DirectBuffer 申请的是非 JVM 的物理内存,所以创建和销毁的代价很高。 DirectBuffer 申请的内存并不是直接由 JVM 负责垃圾回收,但在 DirectBuffer 包装类被回收时,会通过 Java 引用机制来释放该内存块。
# #四、Selector (选择器)
NIO 常常被叫做非阻塞 IO,主要是因为 NIO 在网络通信中的非阻塞特性被广泛使用。
Selector 是 Java NIO 编程的基础。用于检查一个或多个 NIO Channel 的状态是否处于可读、可写。
NIO 实现了 IO 多路复用中的 Reactor 模型:
- 一个线程(
Thread)使用一个选择器Selector通过轮询的方式去监听多个通道Channel上的事件(accpet、read),如果某个Channel上面发生监听事件,这个Channel就处于就绪状态,然后进行 I/O 操作。 - 通过配置监听的通道
Channel为非阻塞,那么当Channel上的 IO 事件还未到达时,就不会进入阻塞状态一直等待,而是继续轮询其它Channel,找到 IO 事件已经到达的Channel执行。 - 因为创建和切换线程的开销很大,因此使用一个线程来处理多个事件而不是一个线程处理一个事件具有更好的性能。
需要注意的是,只有 SocketChannel 才能配置为非阻塞,而 FileChannel 不能,因为 FileChannel 配置非阻塞也没有意义。
目前操作系统的 I/O 多路复用机制都使用了 epoll,相比传统的 select 机制,epoll 没有最大连接句柄 1024 的限制。所以 Selector 在理论上可以轮询成千上万的客户端。
# #创建选择器
Selector selector = Selector.open();# #将通道注册到选择器上
ServerSocketChannel ssChannel = ServerSocketChannel.open();
ssChannel.configureBlocking(false);
ssChannel.register(selector, SelectionKey.OP_ACCEPT);通道必须配置为非阻塞模式,否则使用选择器就没有任何意义了,因为如果通道在某个事件上被阻塞,那么服务器就不能响应其它事件,必须等待这个事件处理完毕才能去处理其它事件,显然这和选择器的作用背道而驰。
在将通道注册到选择器上时,还需要指定要注册的具体事件,主要有以下几类:
SelectionKey.OP_CONNECTSelectionKey.OP_ACCEPTSelectionKey.OP_READSelectionKey.OP_WRITE
它们在 SelectionKey 的定义如下:
public static final int OP_READ = 1 << 0;
public static final int OP_WRITE = 1 << 2;
public static final int OP_CONNECT = 1 << 3;
public static final int OP_ACCEPT = 1 << 4;可以看出每个事件可以被当成一个位域,从而组成事件集整数。例如:
int interestSet = SelectionKey.OP_READ | SelectionKey.OP_WRITE;# #监听事件
int num = selector.select();使用 select() 来监听到达的事件,它会一直阻塞直到有至少一个事件到达。
# #获取到达的事件
Set<SelectionKey> keys = selector.selectedKeys();
Iterator<SelectionKey> keyIterator = keys.iterator();
while (keyIterator.hasNext()) {
SelectionKey key = keyIterator.next();
if (key.isAcceptable()) {
// ...
} else if (key.isReadable()) {
// ...
}
keyIterator.remove();
}# #事件循环
因为一次 select () 调用不能处理完所有的事件,并且服务器端有可能需要一直监听事件,因此服务器端处理事件的代码一般会放在一个死循环内。
while (true) {
int num = selector.select();
Set<SelectionKey> keys = selector.selectedKeys();
Iterator<SelectionKey> keyIterator = keys.iterator();
while (keyIterator.hasNext()) {
SelectionKey key = keyIterator.next();
if (key.isAcceptable()) {
// ...
} else if (key.isReadable()) {
// ...
}
keyIterator.remove();
}
}# #套接字 NIO 示例
public class NIOServer {
public static void main(String[] args) throws IOException {
Selector selector = Selector.open();
ServerSocketChannel ssChannel = ServerSocketChannel.open();
ssChannel.configureBlocking(false);
ssChannel.register(selector, SelectionKey.OP_ACCEPT);
ServerSocket serverSocket = ssChannel.socket();
InetSocketAddress address = new InetSocketAddress("127.0.0.1", 8888);
serverSocket.bind(address);
while (true) {
selector.select();
Set<SelectionKey> keys = selector.selectedKeys();
Iterator<SelectionKey> keyIterator = keys.iterator();
while (keyIterator.hasNext()) {
SelectionKey key = keyIterator.next();
if (key.isAcceptable()) {
ServerSocketChannel ssChannel1 = (ServerSocketChannel) key.channel();
// 服务器会为每个新连接创建一个 SocketChannel
SocketChannel sChannel = ssChannel1.accept();
sChannel.configureBlocking(false);
// 这个新连接主要用于从客户端读取数据
sChannel.register(selector, SelectionKey.OP_READ);
} else if (key.isReadable()) {
SocketChannel sChannel = (SocketChannel) key.channel();
System.out.println(readDataFromSocketChannel(sChannel));
sChannel.close();
}
keyIterator.remove();
}
}
}
private static String readDataFromSocketChannel(SocketChannel sChannel) throws IOException {
ByteBuffer buffer = ByteBuffer.allocate(1024);
StringBuilder data = new StringBuilder();
while (true) {
buffer.clear();
int n = sChannel.read(buffer);
if (n == -1) {
break;
}
buffer.flip();
int limit = buffer.limit();
char[] dst = new char[limit];
for (int i = 0; i < limit; i++) {
dst[i] = (char) buffer.get(i);
}
data.append(dst);
buffer.clear();
}
return data.toString();
}
}
public class NIOClient {
public static void main(String[] args) throws IOException {
Socket socket = new Socket("127.0.0.1", 8888);
OutputStream out = socket.getOutputStream();
String s = "hello world";
out.write(s.getBytes());
out.close();
}
}# #内存映射文件
内存映射文件 I/O 是一种读和写文件数据的方法,它可以比常规的基于流或者基于通道的 I/O 快得多。
向内存映射文件写入可能是危险的,只是改变数组的单个元素这样的简单操作,就可能会直接修改磁盘上的文件。修改数据与将数据保存到磁盘是没有分开的。
下面代码行将文件的前 1024 个字节映射到内存中,map () 方法返回一个 MappedByteBuffer,它是 ByteBuffer 的子类。因此,可以像使用其他任何 ByteBuffer 一样使用新映射的缓冲区,操作系统会在需要时负责执行映射。
MappedByteBuffer mbb = fc.map(FileChannel.MapMode.READ_WRITE, 0, 1024);# #五、NIO vs. BIO
BIO 与 NIO 最重要的区别是数据打包和传输的方式:BIO 以流的方式处理数据,而 NIO 以块的方式处理数据。
- 面向流的 BIO 一次处理一个字节数据:一个输入流产生一个字节数据,一个输出流消费一个字节数据。为流式数据创建过滤器非常容易,链接几个过滤器,以便每个过滤器只负责复杂处理机制的一部分。不利的一面是,面向流的 I/O 通常相当慢。
- 面向块的 NIO 一次处理一个数据块,按块处理数据比按流处理数据要快得多。但是面向块的 NIO 缺少一些面向流的 BIO 所具有的优雅性和简单性。
BIO 模式:
NIO 模式:
# 深入理解 Java 序列化
📦 本文以及示例源码已归档在 javacore(opens new window)
* 关键词:
Serializable、serialVersionUID、transient、Externalizable、writeObject、readObject*
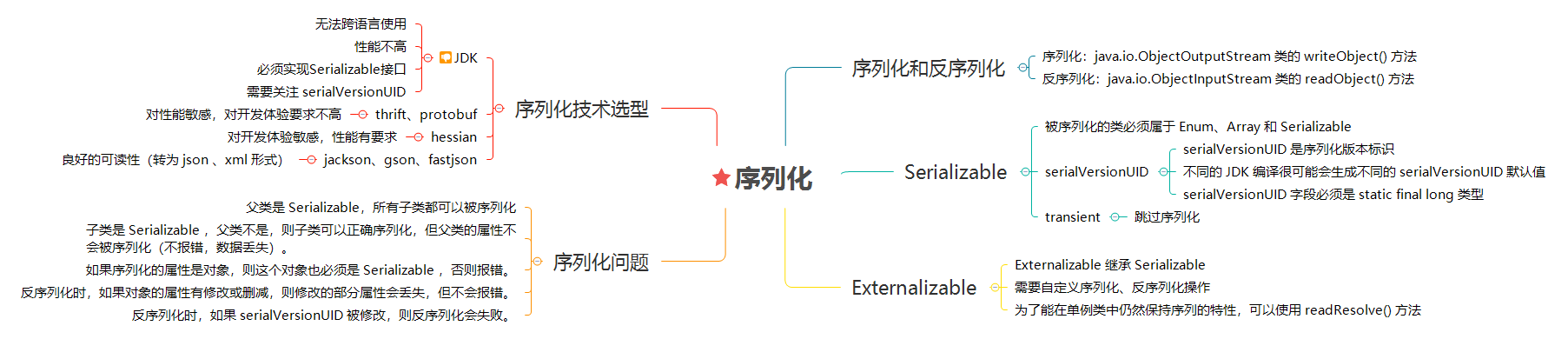
- 1. Java 序列化简介
- 2. Java 序列化和反序列化
- \3. Serializable 接口
- \4. Externalizable 接口
- 5. Java 序列化问题
- 6. Java 序列化的缺陷
- 7. 序列化技术选型
- 8. 参考资料
# #1. Java 序列化简介
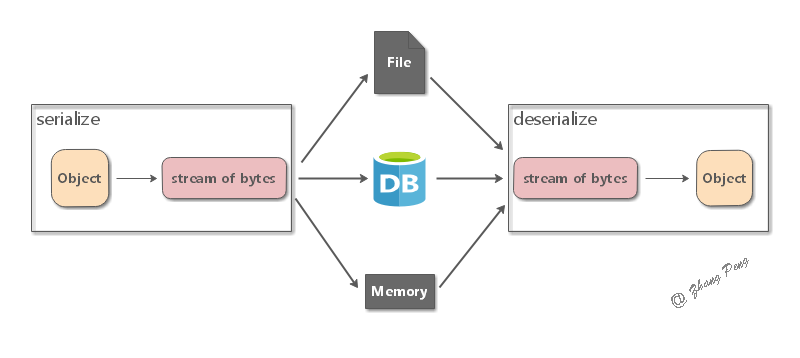
- 序列化(serialize) - 序列化是将对象转换为字节流。
- 反序列化(deserialize) - 反序列化是将字节流转换为对象。
- 序列化用途
- 序列化可以将对象的字节序列持久化 —— 保存在内存、文件、数据库中。
- 在网络上传送对象的字节序列。
- RMI (远程方法调用)
🔔 注意:使用 Java 对象序列化,在保存对象时,会把其状态保存为一组字节,在未来,再将这些字节组装成对象。必须注意地是,对象序列化保存的是对象的” 状态”,即它的成员变量。由此可知,对象序列化不会关注类中的静态变量。
# #2. Java 序列化和反序列化
Java 通过对象输入输出流来实现序列化和反序列化:
java.io.ObjectOutputStream类的writeObject()方法可以实现序列化;java.io.ObjectInputStream类的readObject()方法用于实现反序列化。
序列化和反序列化示例:
public class SerializeDemo01 {
enum Sex {
MALE,
FEMALE
}
static class Person implements Serializable {
private static final long serialVersionUID = 1L;
private String name = null;
private Integer age = null;
private Sex sex;
public Person() { }
public Person(String name, Integer age, Sex sex) {
this.name = name;
this.age = age;
this.sex = sex;
}
@Override
public String toString() {
return "Person{" + "name='" + name + '\'' + ", age=" + age + ", sex=" + sex + '}';
}
}
/**
* 序列化
*/
private static void serialize(String filename) throws IOException {
File f = new File(filename); // 定义保存路径
OutputStream out = new FileOutputStream(f); // 文件输出流
ObjectOutputStream oos = new ObjectOutputStream(out); // 对象输出流
oos.writeObject(new Person("Jack", 30, Sex.MALE)); // 保存对象
oos.close();
out.close();
}
/**
* 反序列化
*/
private static void deserialize(String filename) throws IOException, ClassNotFoundException {
File f = new File(filename); // 定义保存路径
InputStream in = new FileInputStream(f); // 文件输入流
ObjectInputStream ois = new ObjectInputStream(in); // 对象输入流
Object obj = ois.readObject(); // 读取对象
ois.close();
in.close();
System.out.println(obj);
}
public static void main(String[] args) throws IOException, ClassNotFoundException {
final String filename = "d:/text.dat";
serialize(filename);
deserialize(filename);
}
}
// Output:
// Person{name='Jack', age=30, sex=MALE}# #3. Serializable 接口
被序列化的类必须属于 Enum、Array 和 Serializable 类型其中的任何一种,否则将抛出 NotSerializableException 异常。这是因为:在序列化操作过程中会对类型进行检查,如果不满足序列化类型要求,就会抛出异常。
【示例】 NotSerializableException 错误
public class UnSerializeDemo {
static class Person { // 其他内容略 }
// 其他内容略
}输出:结果就是出现如下异常信息。
Exception in thread "main" java.io.NotSerializableException:
...# #3.1. serialVersionUID
请注意 serialVersionUID 字段,你可以在 Java 世界的无数类中看到这个字段。
serialVersionUID 有什么作用,如何使用 serialVersionUID ?
serialVersionUID 是 Java 为每个序列化类产生的版本标识。它可以用来保证在反序列时,发送方发送的和接受方接收的是可兼容的对象。如果接收方接收的类的 serialVersionUID 与发送方发送的 serialVersionUID 不一致,会抛出 InvalidClassException 。
如果可序列化类没有显式声明 serialVersionUID ,则序列化运行时将基于该类的各个方面计算该类的默认 serialVersionUID 值。尽管这样,还是建议在每一个序列化的类中显式指定 serialVersionUID 的值。因为不同的 jdk 编译很可能会生成不同的 serialVersionUID 默认值,从而导致在反序列化时抛出 InvalidClassExceptions 异常。
serialVersionUID 字段必须是 static final long 类型。
我们来举个例子:
(1)有一个可序列化类 Person
public class Person implements Serializable {
private static final long serialVersionUID = 1L;
private String name;
private Integer age;
private String address;
// 构造方法、get、set 方法略
}(2)开发过程中,对 Person 做了修改,增加了一个字段 email,如下:
public class Person implements Serializable {
private static final long serialVersionUID = 1L;
private String name;
private Integer age;
private String address;
private String email;
// 构造方法、get、set 方法略
}由于这个类和老版本不兼容,我们需要修改版本号:
private static final long serialVersionUID = 2L;再次进行反序列化,则会抛出 InvalidClassException 异常。
综上所述,我们大概可以清楚: serialVersionUID 用于控制序列化版本是否兼容。若我们认为修改的可序列化类是向后兼容的,则不修改 serialVersionUID 。
# #3.2. 默认序列化机制
如果仅仅只是让某个类实现 Serializable 接口,而没有其它任何处理的话,那么就会使用默认序列化机制。
使用默认机制,在序列化对象时,不仅会序列化当前对象本身,还会对其父类的字段以及该对象引用的其它对象也进行序列化。同样地,这些其它对象引用的另外对象也将被序列化,以此类推。所以,如果一个对象包含的成员变量是容器类对象,而这些容器所含有的元素也是容器类对象,那么这个序列化的过程就会较复杂,开销也较大。
🔔 注意:这里的父类和引用对象既然要进行序列化,那么它们当然也要满足序列化要求:被序列化的类必须属于 Enum、Array 和 Serializable 类型其中的任何一种。
# #3.3. transient
在现实应用中,有些时候不能使用默认序列化机制。比如,希望在序列化过程中忽略掉敏感数据,或者简化序列化过程。下面将介绍若干影响序列化的方法。
当某个字段被声明为 transient 后,默认序列化机制就会忽略该字段的内容,该字段的内容在序列化后无法获得访问。
我们将 SerializeDemo01 示例中的内部类 Person 的 age 字段声明为 transient ,如下所示:
public class SerializeDemo02 {
static class Person implements Serializable {
transient private Integer age = null;
// 其他内容略
}
// 其他内容略
}
// Output:
// name: Jack, age: null, sex: MALE从输出结果可以看出,age 字段没有被序列化。
# #4. Externalizable 接口
无论是使用 transient 关键字,还是使用 writeObject() 和 readObject() 方法,其实都是基于 Serializable 接口的序列化。
JDK 中提供了另一个序列化接口– Externalizable 。
可序列化类实现 Externalizable 接口之后,基于 Serializable 接口的默认序列化机制就会失效。
我们来基于 SerializeDemo02 再次做一些改动,代码如下:
public class ExternalizeDemo01 {
static class Person implements Externalizable {
transient private Integer age = null;
// 其他内容略
private void writeObject(ObjectOutputStream out) throws IOException {
out.defaultWriteObject();
out.writeInt(age);
}
private void readObject(ObjectInputStream in) throws IOException, ClassNotFoundException {
in.defaultReadObject();
age = in.readInt();
}
@Override
public void writeExternal(ObjectOutput out) throws IOException { }
@Override
public void readExternal(ObjectInput in) throws IOException, ClassNotFoundException { }
}
// 其他内容略
}
// Output:
// call Person()
// name: null, age: null, sex: null从该结果,一方面可以看出 Person 对象中任何一个字段都没有被序列化。另一方面,如果细心的话,还可以发现这此次序列化过程调用了 Person 类的无参构造方法。
-
Externalizable继承于Serializable,它增添了两个方法:writeExternal()与readExternal()。这两个方法在序列化和反序列化过程中会被自动调用,以便执行一些特殊操作。当使用该接口时,序列化的细节需要由程序员去完成。如上所示的代码,由于writeExternal()与readExternal()方法未作任何处理,那么该序列化行为将不会保存 / 读取任何一个字段。这也就是为什么输出结果中所有字段的值均为空。 - 另外,若使用
Externalizable进行序列化,当读取对象时,会调用被序列化类的无参构造方法去创建一个新的对象;然后再将被保存对象的字段的值分别填充到新对象中。这就是为什么在此次序列化过程中 Person 类的无参构造方法会被调用。由于这个原因,实现Externalizable接口的类必须要提供一个无参的构造方法,且它的访问权限为public。
对上述 Person 类作进一步的修改,使其能够对 name 与 age 字段进行序列化,但要忽略掉 gender 字段,如下代码所示:
public class ExternalizeDemo02 {
static class Person implements Externalizable {
transient private Integer age = null;
// 其他内容略
private void writeObject(ObjectOutputStream out) throws IOException {
out.defaultWriteObject();
out.writeInt(age);
}
private void readObject(ObjectInputStream in) throws IOException, ClassNotFoundException {
in.defaultReadObject();
age = in.readInt();
}
@Override
public void writeExternal(ObjectOutput out) throws IOException {
out.writeObject(name);
out.writeInt(age);
}
@Override
public void readExternal(ObjectInput in) throws IOException, ClassNotFoundException {
name = (String) in.readObject();
age = in.readInt();
}
}
// 其他内容略
}
// Output:
// call Person()
// name: Jack, age: 30, sex: null# #4.1. Externalizable 接口的替代方法
实现 Externalizable 接口可以控制序列化和反序列化的细节。它有一个替代方法:实现 Serializable 接口,并添加 writeObject(ObjectOutputStream out) 与 readObject(ObjectInputStream in) 方法。序列化和反序列化过程中会自动回调这两个方法。
示例如下所示:
public class SerializeDemo03 {
static class Person implements Serializable {
transient private Integer age = null;
// 其他内容略
private void writeObject(ObjectOutputStream out) throws IOException {
out.defaultWriteObject();
out.writeInt(age);
}
private void readObject(ObjectInputStream in) throws IOException, ClassNotFoundException {
in.defaultReadObject();
age = in.readInt();
}
// 其他内容略
}
// 其他内容略
}
// Output:
// name: Jack, age: 30, sex: MALE在 writeObject() 方法中会先调用 ObjectOutputStream 中的 defaultWriteObject() 方法,该方法会执行默认的序列化机制,如上节所述,此时会忽略掉 age 字段。然后再调用 writeInt () 方法显示地将 age 字段写入到 ObjectOutputStream 中。readObject () 的作用则是针对对象的读取,其原理与 writeObject () 方法相同。
🔔 注意:
writeObject()与readObject()都是private方法,那么它们是如何被调用的呢?毫无疑问,是使用反射。详情可见ObjectOutputStream中的writeSerialData方法,以及ObjectInputStream中的readSerialData方法。
# #4.2. readResolve () 方法
当我们使用 Singleton 模式时,应该是期望某个类的实例应该是唯一的,但如果该类是可序列化的,那么情况可能会略有不同。此时对第 2 节使用的 Person 类进行修改,使其实现 Singleton 模式,如下所示:
public class SerializeDemo04 {
enum Sex {
MALE, FEMALE
}
static class Person implements Serializable {
private static final long serialVersionUID = 1L;
private String name = null;
transient private Integer age = null;
private Sex sex;
static final Person instatnce = new Person("Tom", 31, Sex.MALE);
private Person() {
System.out.println("call Person()");
}
private Person(String name, Integer age, Sex sex) {
this.name = name;
this.age = age;
this.sex = sex;
}
public static Person getInstance() {
return instatnce;
}
private void writeObject(ObjectOutputStream out) throws IOException {
out.defaultWriteObject();
out.writeInt(age);
}
private void readObject(ObjectInputStream in) throws IOException, ClassNotFoundException {
in.defaultReadObject();
age = in.readInt();
}
public String toString() {
return "name: " + this.name + ", age: " + this.age + ", sex: " + this.sex;
}
}
/**
* 序列化
*/
private static void serialize(String filename) throws IOException {
File f = new File(filename); // 定义保存路径
OutputStream out = new FileOutputStream(f); // 文件输出流
ObjectOutputStream oos = new ObjectOutputStream(out); // 对象输出流
oos.writeObject(new Person("Jack", 30, Sex.MALE)); // 保存对象
oos.close();
out.close();
}
/**
* 反序列化
*/
private static void deserialize(String filename) throws IOException, ClassNotFoundException {
File f = new File(filename); // 定义保存路径
InputStream in = new FileInputStream(f); // 文件输入流
ObjectInputStream ois = new ObjectInputStream(in); // 对象输入流
Object obj = ois.readObject(); // 读取对象
ois.close();
in.close();
System.out.println(obj);
System.out.println(obj == Person.getInstance());
}
public static void main(String[] args) throws IOException, ClassNotFoundException {
final String filename = "d:/text.dat";
serialize(filename);
deserialize(filename);
}
}
// Output:
// name: Jack, age: null, sex: MALE
// false值得注意的是,从文件中获取的 Person 对象与 Person 类中的单例对象并不相等。为了能在单例类中仍然保持序列的特性,可以使用 readResolve() 方法。在该方法中直接返回 Person 的单例对象。我们在 SerializeDemo04 示例的基础上添加一个 readResolve 方法, 如下所示:
public class SerializeDemo05 {
// 其他内容略
static class Person implements Serializable {
// private void readObject(ObjectInputStream in) throws IOException, ClassNotFoundException {
// in.defaultReadObject();
// age = in.readInt();
// }
// 添加此方法
private Object readResolve() {
return instatnce;
}
// 其他内容略
}
// 其他内容略
}
// Output:
// name: Tom, age: 31, sex: MALE
// true# #5. Java 序列化问题
Java 的序列化能保证对象状态的持久保存,但是遇到一些对象结构复杂的情况还是难以处理,这里归纳一下:
- 父类是
Serializable,所有子类都可以被序列化。 - 子类是
Serializable,父类不是,则子类可以正确序列化,但父类的属性不会被序列化(不报错,数据丢失)。 - 如果序列化的属性是对象,则这个对象也必须是
Serializable,否则报错。 - 反序列化时,如果对象的属性有修改或删减,则修改的部分属性会丢失,但不会报错。
- 反序列化时,如果
serialVersionUID被修改,则反序列化会失败。
# #6. Java 序列化的缺陷
- 无法跨语言:Java 序列化目前只适用基于 Java 语言实现的框架,其它语言大部分都没有使用 Java 的序列化框架,也没有实现 Java 序列化这套协议。因此,如果是两个基于不同语言编写的应用程序相互通信,则无法实现两个应用服务之间传输对象的序列化与反序列化。
- 容易被攻击:对象是通过在
ObjectInputStream上调用readObject()方法进行反序列化的,它可以将类路径上几乎所有实现了Serializable接口的对象都实例化。这意味着,在反序列化字节流的过程中,该方法可以执行任意类型的代码,这是非常危险的。对于需要长时间进行反序列化的对象,不需要执行任何代码,也可以发起一次攻击。攻击者可以创建循环对象链,然后将序列化后的对象传输到程序中反序列化,这种情况会导致hashCode方法被调用次数呈次方爆发式增长,从而引发栈溢出异常。例如下面这个案例就可以很好地说明。 - 序列化后的流太大:Java 序列化中使用了
ObjectOutputStream来实现对象转二进制编码,编码后的数组很大,非常影响存储和传输效率。 - 序列化性能太差:Java 的序列化耗时比较大。序列化的速度也是体现序列化性能的重要指标,如果序列化的速度慢,就会影响网络通信的效率,从而增加系统的响应时间。
- 序列化编程限制:
- Java 官方的序列化一定需要实现
Serializable接口。 - Java 官方的序列化需要关注
serialVersionUID。
- Java 官方的序列化一定需要实现
# #7. 序列化技术选型
通过上一章节 ——Java 序列化的缺陷,我们了解到,Java 序列化方式存在许多缺陷。因此,建议使用第三方序列化工具来替代。
当然我们还有更加优秀的一些序列化和反序列化的工具,根据不同的使用场景可以自行选择!
- thrift (opens new window)、protobuf (opens new window)- 适用于对性能敏感,对开发体验要求不高。
- hessian (opens new window)- 适用于对开发体验敏感,性能有要求。
- jackson (opens new window)、gson (opens new window)、fastjson (opens new window)- 适用于对序列化后的数据要求有良好的可读性(转为 json 、xml 形式)。
# Java 网络编程
📦 本文以及示例源码已归档在 javacore(opens new window)
关键词:
Socket、ServerSocket、DatagramPacket、DatagramSocket网络编程是指编写运行在多个设备(计算机)的程序,这些设备都通过网络连接起来。
java.net包中提供了低层次的网络通信细节。你可以直接使用这些类和接口,来专注于解决问题,而不用关注通信细节。java.net 包中提供了两种常见的网络协议的支持:
- TCP - TCP 是传输控制协议的缩写,它保障了两个应用程序之间的可靠通信。通常用于互联网协议,被称 TCP/ IP。
- UDP - UDP 是用户数据报协议的缩写,一个无连接的协议。提供了应用程序之间要发送的数据的数据包。
- Socket 和 ServerSocket
- DatagramSocket 和 DatagramPacket
- InetAddress
- URL
- 参考资料
# #一、Socket 和 ServerSocket
套接字(Socket)使用 TCP 提供了两台计算机之间的通信机制。 客户端程序创建一个套接字,并尝试连接服务器的套接字。
Java 通过 Socket 和 ServerSocket 实现对 TCP 的支持。Java 中的 Socket 通信可以简单理解为: java.net.Socket 代表客户端, java.net.ServerSocket 代表服务端,二者可以建立连接,然后通信。
以下为 Socket 通信中建立建立的基本流程:
- 服务器实例化一个
ServerSocket对象,表示服务器绑定一个端口。 - 服务器调用
ServerSocket的accept()方法,该方法将一直等待,直到客户端连接到服务器的绑定端口(即监听端口)。 - 服务器监听端口时,客户端实例化一个
Socket对象,指定服务器名称和端口号来请求连接。 Socket类的构造函数试图将客户端连接到指定的服务器和端口号。如果通信被建立,则在客户端创建一个 Socket 对象能够与服务器进行通信。- 在服务器端,
accept()方法返回服务器上一个新的Socket引用,该引用连接到客户端的Socket。
连接建立后,可以通过使用 IO 流进行通信。每一个 Socket 都有一个输出流和一个输入流。客户端的输出流连接到服务器端的输入流,而客户端的输入流连接到服务器端的输出流。
TCP 是一个双向的通信协议,因此数据可以通过两个数据流在同一时间发送,以下是一些类提供的一套完整的有用的方法来实现 sockets。
# #ServerSocket
服务器程序通过使用 java.net.ServerSocket 类以获取一个端口,并且监听客户端请求连接此端口的请求。
# #ServerSocket 构造方法
ServerSocket 有多个构造方法:
| 方法 | 描述 |
|---|---|
ServerSocket() |
创建非绑定服务器套接字。 |
ServerSocket(int port) |
创建绑定到特定端口的服务器套接字。 |
ServerSocket(int port, int backlog) |
利用指定的 backlog 创建服务器套接字并将其绑定到指定的本地端口号。 |
ServerSocket(int port, int backlog, InetAddress address) |
使用指定的端口、监听 backlog 和要绑定到的本地 IP 地址创建服务器。 |
# #ServerSocket 常用方法
创建非绑定服务器套接字。 如果 ServerSocket 构造方法没有抛出异常,就意味着你的应用程序已经成功绑定到指定的端口,并且侦听客户端请求。
这里有一些 ServerSocket 类的常用方法:
| 方法 | 描述 |
|---|---|
int getLocalPort() |
返回此套接字在其上侦听的端口。 |
Socket accept() |
监听并接受到此套接字的连接。 |
void setSoTimeout(int timeout) |
通过指定超时值启用 / 禁用 SO_TIMEOUT ,以毫秒为单位。 |
void bind(SocketAddress host, int backlog) |
将 ServerSocket 绑定到特定地址(IP 地址和端口号)。 |
# #Socket
java.net.Socket 类代表客户端和服务器都用来互相沟通的套接字。客户端要获取一个 Socket 对象通过实例化 ,而 服务器获得一个 Socket 对象则通过 accept() 方法 a 的返回值。
# #Socket 构造方法
Socket 类有 5 个构造方法:
| 方法 | 描述 |
|---|---|
Socket() |
通过系统默认类型的 SocketImpl 创建未连接套接字 |
Socket(String host, int port) |
创建一个流套接字并将其连接到指定主机上的指定端口号。 |
Socket(InetAddress host, int port) |
创建一个流套接字并将其连接到指定 IP 地址的指定端口号。 |
Socket(String host, int port, InetAddress localAddress, int localPort) |
创建一个套接字并将其连接到指定远程主机上的指定远程端口。 |
Socket(InetAddress host, int port, InetAddress localAddress, int localPort) |
创建一个套接字并将其连接到指定远程地址上的指定远程端口。 |
当 Socket 构造方法返回,并没有简单的实例化了一个 Socket 对象,它实际上会尝试连接到指定的服务器和端口。
# #Socket 常用方法
下面列出了一些感兴趣的方法,注意客户端和服务器端都有一个 Socket 对象,所以无论客户端还是服务端都能够调用这些方法。
| 方法 | 描述 |
|---|---|
void connect(SocketAddress host, int timeout) |
将此套接字连接到服务器,并指定一个超时值。 |
InetAddress getInetAddress() |
返回套接字连接的地址。 |
int getPort() |
返回此套接字连接到的远程端口。 |
int getLocalPort() |
返回此套接字绑定到的本地端口。 |
SocketAddress getRemoteSocketAddress() |
返回此套接字连接的端点的地址,如果未连接则返回 null。 |
InputStream getInputStream() |
返回此套接字的输入流。 |
OutputStream getOutputStream() |
返回此套接字的输出流。 |
void close() |
关闭此套接字。 |
# #Socket 通信示例
服务端示例:
public class HelloServer {
public static void main(String[] args) throws Exception {
// Socket 服务端
// 服务器在8888端口上监听
ServerSocket server = new ServerSocket(8888);
System.out.println("服务器运行中,等待客户端连接。");
// 得到连接,程序进入到阻塞状态
Socket client = server.accept();
// 打印流输出最方便
PrintStream out = new PrintStream(client.getOutputStream());
// 向客户端输出信息
out.println("hello world");
client.close();
server.close();
System.out.println("服务器已向客户端发送消息,退出。");
}
}客户端示例:
public class HelloClient {
public static void main(String[] args) throws Exception {
// Socket 客户端
Socket client = new Socket("localhost", 8888);
InputStreamReader inputStreamReader = new InputStreamReader(client.getInputStream());
// 一次性接收完成
BufferedReader buf = new BufferedReader(inputStreamReader);
String str = buf.readLine();
buf.close();
client.close();
System.out.println("客户端接收到服务器消息:" + str + ",退出");
}
}# #二、DatagramSocket 和 DatagramPacket
Java 通过 DatagramSocket 和 DatagramPacket 实现对 UDP 协议的支持。
DatagramPacket:数据包类DatagramSocket:通信类
UDP 服务端示例:
public class UDPServer {
public static void main(String[] args) throws Exception { // 所有异常抛出
String str = "hello World!!!";
DatagramSocket ds = new DatagramSocket(3000); // 服务端在3000端口上等待服务器发送信息
DatagramPacket dp =
new DatagramPacket(str.getBytes(), str.length(), InetAddress.getByName("localhost"), 9000); // 所有的信息使用buf保存
System.out.println("发送信息。");
ds.send(dp); // 发送信息出去
ds.close();
}
}UDP 客户端示例:
public class UDPClient {
public static void main(String[] args) throws Exception { // 所有异常抛出
byte[] buf = new byte[1024]; // 开辟空间,以接收数据
DatagramSocket ds = new DatagramSocket(9000); // 客户端在9000端口上等待服务器发送信息
DatagramPacket dp = new DatagramPacket(buf, 1024); // 所有的信息使用buf保存
ds.receive(dp); // 接收数据
String str = new String(dp.getData(), 0, dp.getLength()) + "from " + dp.getAddress().getHostAddress() + ":"
+ dp.getPort();
System.out.println(str); // 输出内容
}
}# #三、InetAddress
InetAddress 类表示互联网协议 (IP) 地址。
没有公有的构造函数,只能通过静态方法来创建实例。
InetAddress.getByName(String host);
InetAddress.getByAddress(byte[] address);# #四、URL
可以直接从 URL 中读取字节流数据。
public static void main(String[] args) throws IOException {
URL url = new URL("http://www.baidu.com");
/* 字节流 */
InputStream is = url.openStream();
/* 字符流 */
InputStreamReader isr = new InputStreamReader(is, "utf-8");
/* 提供缓存功能 */
BufferedReader br = new BufferedReader(isr);
String line;
while ((line = br.readLine()) != null) {
System.out.println(line);
}
br.close();
}# Java IO 工具类
📦 本文以及示例源码已归档在 javacore(opens new window)
* 关键词:
File、RandomAccessFile、System、Scanner*本文介绍 Java IO 的一些常见工具类的用法和特性。
# #一、File
File 类是 java.io 包中唯一对文件本身进行操作的类。它可以对文件、目录进行增删查操作。
# #createNewFille
可以使用 createNewFille() 方法创建一个新文件。
注:
Windows 中使用反斜杠表示目录的分隔符 \ 。
Linux 中使用正斜杠表示目录的分隔符 / 。
最好的做法是使用 File.separator 静态常量,可以根据所在操作系统选取对应的分隔符。
【示例】创建文件
File f = new File(filename);
boolean flag = f.createNewFile();# #mkdir
可以使用 mkdir() 来创建文件夹,但是如果要创建的目录的父路径不存在,则无法创建成功。
如果要解决这个问题,可以使用 mkdirs() ,当父路径不存在时,会连同上级目录都一并创建。
【示例】创建目录
File f = new File(filename);
boolean flag = f.mkdir();# #delete
可以使用 delete() 来删除文件或目录。
需要注意的是,如果删除的是目录,且目录不为空,直接用 delete() 删除会失败。
【示例】删除文件或目录
File f = new File(filename);
boolean flag = f.delete();# #list 和 listFiles
File 中给出了两种列出文件夹内容的方法:
-
list(): 列出全部名称,返回一个字符串数组。 -
listFiles(): 列出完整的路径,返回一个File对象数组。
list() 示例:
File f = new File(filename);
String str[] = f.list();listFiles() 示例:
File f = new File(filename);
File files[] = f.listFiles();# #二、RandomAccessFile
注:
RandomAccessFile类虽然可以实现对文件内容的读写操作,但是比较复杂。所以一般操作文件内容往往会使用字节流或字符流方式。
RandomAccessFile 类是随机读取类,它是一个完全独立的类。
它适用于由大小已知的记录组成的文件,所以我们可以使用 seek() 将记录从一处转移到另一处,然后读取或者修改记录。
文件中记录的大小不一定都相同,只要能够确定哪些记录有多大以及它们在文件中的位置即可。
# #RandomAccessFile 写操作
当用 rw 方式声明 RandomAccessFile 对象时,如果要写入的文件不存在,系统将自行创建。
r 为只读; w 为只写; rw 为读写。
【示例】文件随机读写
public class RandomAccessFileDemo01 {
public static void main(String args[]) throws IOException {
File f = new File("d:" + File.separator + "test.txt"); // 指定要操作的文件
RandomAccessFile rdf = null; // 声明RandomAccessFile类的对象
rdf = new RandomAccessFile(f, "rw");// 读写模式,如果文件不存在,会自动创建
String name = null;
int age = 0;
name = "zhangsan"; // 字符串长度为8
age = 30; // 数字的长度为4
rdf.writeBytes(name); // 将姓名写入文件之中
rdf.writeInt(age); // 将年龄写入文件之中
name = "lisi "; // 字符串长度为8
age = 31; // 数字的长度为4
rdf.writeBytes(name); // 将姓名写入文件之中
rdf.writeInt(age); // 将年龄写入文件之中
name = "wangwu "; // 字符串长度为8
age = 32; // 数字的长度为4
rdf.writeBytes(name); // 将姓名写入文件之中
rdf.writeInt(age); // 将年龄写入文件之中
rdf.close(); // 关闭
}
}# #RandomAccessFile 读操作
读取是直接使用 r 的模式即可,以只读的方式打开文件。
读取时所有的字符串只能按照 byte 数组方式读取出来,而且长度必须和写入时的固定大小相匹配。
public class RandomAccessFileDemo02 {
public static void main(String args[]) throws IOException {
File f = new File("d:" + File.separator + "test.txt"); // 指定要操作的文件
RandomAccessFile rdf = null; // 声明RandomAccessFile类的对象
rdf = new RandomAccessFile(f, "r");// 以只读的方式打开文件
String name = null;
int age = 0;
byte b[] = new byte[8]; // 开辟byte数组
// 读取第二个人的信息,意味着要空出第一个人的信息
rdf.skipBytes(12); // 跳过第一个人的信息
for (int i = 0; i < b.length; i++) {
b[i] = rdf.readByte(); // 读取一个字节
}
name = new String(b); // 将读取出来的byte数组变为字符串
age = rdf.readInt(); // 读取数字
System.out.println("第二个人的信息 --> 姓名:" + name + ";年龄:" + age);
// 读取第一个人的信息
rdf.seek(0); // 指针回到文件的开头
for (int i = 0; i < b.length; i++) {
b[i] = rdf.readByte(); // 读取一个字节
}
name = new String(b); // 将读取出来的byte数组变为字符串
age = rdf.readInt(); // 读取数字
System.out.println("第一个人的信息 --> 姓名:" + name + ";年龄:" + age);
rdf.skipBytes(12); // 空出第二个人的信息
for (int i = 0; i < b.length; i++) {
b[i] = rdf.readByte(); // 读取一个字节
}
name = new String(b); // 将读取出来的byte数组变为字符串
age = rdf.readInt(); // 读取数字
System.out.println("第三个人的信息 --> 姓名:" + name + ";年龄:" + age);
rdf.close(); // 关闭
}
}# #三、System
System 类中提供了大量的静态方法,可以获取系统相关的信息或系统级操作,其中提供了三个常用于 IO 的静态成员:
System.out- 一个 PrintStream 流。System.out 一般会把你写到其中的数据输出到控制台上。System.out 通常仅用在类似命令行工具的控制台程序上。System.out 也经常用于打印程序的调试信息 (尽管它可能并不是获取程序调试信息的最佳方式)。System.err- 一个 PrintStream 流。System.err 与 System.out 的运行方式类似,但它更多的是用于打印错误文本。一些类似 Eclipse 的程序,为了让错误信息更加显眼,会将错误信息以红色文本的形式通过 System.err 输出到控制台上。System.in- 一个典型的连接控制台程序和键盘输入的 InputStream 流。通常当数据通过命令行参数或者配置文件传递给命令行 Java 程序的时候,System.in 并不是很常用。图形界面程序通过界面传递参数给程序,这是一块单独的 Java IO 输入机制。
【示例】重定向 System.out 输出流
import java.io.*;
public class SystemOutDemo {
public static void main(String args[]) throws Exception {
OutputStream out = new FileOutputStream("d:\\test.txt");
PrintStream ps = new PrintStream(out);
System.setOut(ps);
System.out.println("人生若只如初见,何事秋风悲画扇");
ps.close();
out.close();
}
}【示例】重定向 System.err 输出流
public class SystemErrDemo {
public static void main(String args[]) throws IOException {
OutputStream bos = new ByteArrayOutputStream(); // 实例化
PrintStream ps = new PrintStream(bos); // 实例化
System.setErr(ps); // 输出重定向
System.err.print("此处有误");
System.out.println(bos); // 输出内存中的数据
}
}【示例】 System.in 接受控制台输入信息
import java.io.*;
public class SystemInDemo {
public static void main(String args[]) throws IOException {
InputStream input = System.in;
StringBuffer buf = new StringBuffer();
System.out.print("请输入内容:");
int temp = 0;
while ((temp = input.read()) != -1) {
char c = (char) temp;
if (c == '\n') {
break;
}
buf.append(c);
}
System.out.println("输入的内容为:" + buf);
input.close();
}
}# #四、Scanner
Scanner 可以获取用户的输入,并对数据进行校验。
【示例】校验输入数据是否格式正确
import java.io.*;
public class ScannerDemo {
public static void main(String args[]) {
Scanner scan = new Scanner(System.in); // 从键盘接收数据
int i = 0;
float f = 0.0f;
System.out.print("输入整数:");
if (scan.hasNextInt()) { // 判断输入的是否是整数
i = scan.nextInt(); // 接收整数
System.out.println("整数数据:" + i);
} else {
System.out.println("输入的不是整数!");
}
System.out.print("输入小数:");
if (scan.hasNextFloat()) { // 判断输入的是否是小数
f = scan.nextFloat(); // 接收小数
System.out.println("小数数据:" + f);
} else {
System.out.println("输入的不是小数!");
}
Date date = null;
String str = null;
System.out.print("输入日期(yyyy-MM-dd):");
if (scan.hasNext("^\\d{4}-\\d{2}-\\d{2}$")) { // 判断
str = scan.next("^\\d{4}-\\d{2}-\\d{2}$"); // 接收
try {
date = new SimpleDateFormat("yyyy-MM-dd").parse(str);
} catch (Exception e) {}
} else {
System.out.println("输入的日期格式错误!");
}
System.out.println(date);
}
}输出:
输入整数:20
整数数据:20
输入小数:3.2
小数数据:3.2
输入日期(yyyy-MM-dd):1988-13-1
输入的日期格式错误!
null# Java 并发简介
关键词:
进程、线程、安全性、活跃性、性能、死锁、饥饿、上下文切换摘要:并发编程并非 Java 语言所独有,而是一种成熟的编程范式,Java 只是用自己的方式实现了并发工作模型。学习 Java 并发编程,应该先熟悉并发的基本概念,然后进一步了解并发的特性以及其特性所面临的问题。掌握了这些,当学习 Java 并发工具时,才会明白它们各自是为了解决什么问题,为什么要这样设计。通过这样由点到面的学习方式,更容易融会贯通,将并发知识形成体系化。
📦 本文以及示例源码已归档在 javacore(opens new window)
# #1. 并发概念
并发编程中有很多术语概念相近,容易让人混淆。本节内容通过对比分析,力求让读者清晰理解其概念以及差异。
# #1.1. 并发和并行
并发和并行是最容易让新手费解的概念,那么如何理解二者呢?其最关键的差异在于:是否是同时发生:
- 并发:是指具备处理多个任务的能力,但不一定要同时。
- 并行:是指具备同时处理多个任务的能力。
下面是我见过最生动的说明,摘自 并发与并行的区别是什么?—— 知乎的高票答案 (opens new window):
- 你吃饭吃到一半,电话来了,你一直到吃完了以后才去接,这就说明你不支持并发也不支持并行。
- 你吃饭吃到一半,电话来了,你停了下来接了电话,接完后继续吃饭,这说明你支持并发。
- 你吃饭吃到一半,电话来了,你一边打电话一边吃饭,这说明你支持并行。
# #1.2. 同步和异步
- 同步:是指在发出一个调用时,在没有得到结果之前,该调用就不返回。但是一旦调用返回,就得到返回值了。
- 异步:则是相反,调用在发出之后,这个调用就直接返回了,所以没有返回结果。换句话说,当一个异步过程调用发出后,调用者不会立刻得到结果。而是在调用发出后,被调用者通过状态、通知来通知调用者,或通过回调函数处理这个调用。
举例来说明:
- 同步就像是打电话:不挂电话,通话不会结束。
- 异步就像是发短信:发完短信后,就可以做其他事;当收到回复短信时,手机会通过铃声或振动来提醒。
# #1.3. 阻塞和非阻塞
阻塞和非阻塞关注的是程序在等待调用结果(消息,返回值)时的状态:
- 阻塞:是指调用结果返回之前,当前线程会被挂起。调用线程只有在得到结果之后才会返回。
- 非阻塞:是指在不能立刻得到结果之前,该调用不会阻塞当前线程。
举例来说明:
- 阻塞调用就像是打电话,通话不结束,不能放下。
- 非阻塞调用就像是发短信,发完短信后,就可以做其他事,短信来了,手机会提醒。
# #1.4. 进程和线程
- 进程:进程是具有一定独立功能的程序关于某个数据集合上的一次运行活动。进程是操作系统进行资源分配的基本单位。进程可视为一个正在运行的程序。
- 线程:线程是操作系统进行调度的基本单位。
进程和线程的差异:
- 一个程序至少有一个进程,一个进程至少有一个线程。
- 线程比进程划分更细,所以执行开销更小,并发性更高
- 进程是一个实体,拥有独立的资源;而同一个进程中的多个线程共享进程的资源。
JVM 在单个进程中运行,JVM 中的线程共享属于该进程的堆。这就是为什么几个线程可以访问同一个对象。线程共享堆并拥有自己的堆栈空间。这是一个线程如何调用一个方法以及它的局部变量是如何保持线程安全的。但是堆不是线程安全的并且为了线程安全必须进行同步。
# #1.5. 竞态条件和临界区
- 竞态条件(Race Condition):当两个线程竞争同一资源时,如果对资源的访问顺序敏感,就称存在竞态条件。
- 临界区(Critical Sections):导致竞态条件发生的代码区称作临界区。
# #1.6. 管程
管程(Monitor),是指管理共享变量以及对共享变量的操作过程,让他们支持并发。
Java 采用的是管程技术,synchronized 关键字及 wait ()、notify ()、notifyAll () 这三个方法都是管程的组成部分。而管程和信号量是等价的,所谓等价指的是用管程能够实现信号量,也能用信号量实现管程。
# #2. 并发的特点
技术在进步,CPU、内存、I/O 设备的性能也在不断提高。但是,始终存在一个核心矛盾:CPU、内存、I/O 设备存在速度差异。CPU 远快于内存,内存远快于 I/O 设备。
木桶短板理论告诉我们:一只木桶能装多少水,取决于最短的那块木板。同理,程序整体性能取决于最慢的操作(即 I/O 操作),所以单方面提高 CPU、内存的性能是无效的。

为了合理利用 CPU 的高性能,平衡这三者的速度差异,计算机体系机构、操作系统、编译程序都做出了贡献,主要体现为:
- CPU 增加了缓存,以均衡与内存的速度差异;
- 操作系统增加了进程、线程,以分时复用 CPU,进而均衡 CPU 与 I/O 设备的速度差异;
- 编译程序优化指令执行次序,使得缓存能够得到更加合理地利用。
其中,进程、线程使得计算机、程序有了并发处理任务的能力。
并发的优点在于:
- 提升资源利用率
- 程序响应更快
# #2.1. 提升资源利用率
想象一下,一个应用程序需要从本地文件系统中读取和处理文件的情景。比方说,从磁盘读取一个文件需要 5 秒,处理一个文件需要 2 秒。处理两个文件则需要:
5秒读取文件A
2秒处理文件A
5秒读取文件B
2秒处理文件B
---------------------
总共需要14秒从磁盘中读取文件的时候,大部分的 CPU 时间用于等待磁盘去读取数据。在这段时间里,CPU 非常的空闲。它可以做一些别的事情。通过改变操作的顺序,就能够更好的使用 CPU 资源。看下面的顺序:
5秒读取文件A
5秒读取文件B + 2秒处理文件A
2秒处理文件B
---------------------
总共需要12秒CPU 等待第一个文件被读取完。然后开始读取第二个文件。当第二文件在被读取的时候,CPU 会去处理第一个文件。记住,在等待磁盘读取文件的时候,CPU 大 部分时间是空闲的。
总的说来,CPU 能够在等待 IO 的时候做一些其他的事情。这个不一定就是磁盘 IO。它也可以是网络的 IO,或者用户输入。通常情况下,网络和磁盘的 IO 比 CPU 和内存的 IO 慢的多。
# #2.2. 程序响应更快
将一个单线程应用程序变成多线程应用程序的另一个常见的目的是实现一个响应更快的应用程序。设想一个服务器应用,它在某一个端口监听进来的请求。当一个请求到来时,它去处理这个请求,然后再返回去监听。
服务器的流程如下所述:
while(server is active) {
listen for request
process request
}如果一个请求需要占用大量的时间来处理,在这段时间内新的客户端就无法发送请求给服务端。只有服务器在监听的时候,请求才能被接收。另一种设计是,监听线程把请求传递给工作者线程 (worker thread),然后立刻返回去监听。而工作者线程则能够处理这个请求并发送一个回复给客户端。这种设计如下所述:
while(server is active) {
listen for request
hand request to worker thread
}这种方式,服务端线程迅速地返回去监听。因此,更多的客户端能够发送请求给服务端。这个服务也变得响应更快。
桌面应用也是同样如此。如果你点击一个按钮开始运行一个耗时的任务,这个线程既要执行任务又要更新窗口和按钮,那么在任务执行的过程中,这个应用程序看起来好像没有反应一样。相反,任务可以传递给工作者线程(worker thread)。当工作者线程在繁忙地处理任务的时候,窗口线程可以自由地响应其他用户的请求。当工作者线程完成任务的时候,它发送信号给窗口线程。窗口线程便可以更新应用程序窗口,并显示任务的结果。对用户而言,这种具有工作者线程设计的程序显得响应速度更快。
# #2.3. 并发的问题
任何事物都有利弊,并发也不例外。
我们知道了并发带来的好处:提升资源利用率、程序响应更快,同时也要认识到并发带来的问题,主要有:
- 安全性问题
- 活跃性问题
- 性能问题
下面会一一讲解。
# #3. 安全性问题
并发最重要的问题是并发安全问题。
并发安全:是指保证程序的正确性,使得并发处理结果符合预期。
并发安全需要保证几个基本特性:
- 可见性 - 是一个线程修改了某个共享变量,其状态能够立即被其他线程知晓,通常被解释为将线程本地状态反映到主内存上,
volatile就是负责保证可见性的。 - 原子性 - 简单说就是相关操作不会中途被其他线程干扰,一般通过同步机制(加锁:
sychronized、Lock)实现。 - 有序性 - 是保证线程内串行语义,避免指令重排等。
# #3.1. 缓存导致的可见性问题
一个线程对共享变量的修改,另外一个线程能够立刻看到,称为 可见性。
在单核时代,所有的线程都是在一颗 CPU 上执行,CPU 缓存与内存的数据一致性容易解决。因为所有线程都是操作同一个 CPU 的缓存,一个线程对缓存的写,对另外一个线程来说一定是可见的。例如在下面的图中,线程 A 和线程 B 都是操作同一个 CPU 里面的缓存,所以线程 A 更新了变量 V 的值,那么线程 B 之后再访问变量 V,得到的一定是 V 的最新值(线程 A 写过的值)。
多核时代,每颗 CPU 都有自己的缓存,这时 CPU 缓存与内存的数据一致性就没那么容易解决了,当多个线程在不同的 CPU 上执行时,这些线程操作的是不同的 CPU 缓存。比如下图中,线程 A 操作的是 CPU-1 上的缓存,而线程 B 操作的是 CPU-2 上的缓存,很明显,这个时候线程 A 对变量 V 的操作对于线程 B 而言就不具备可见性了。
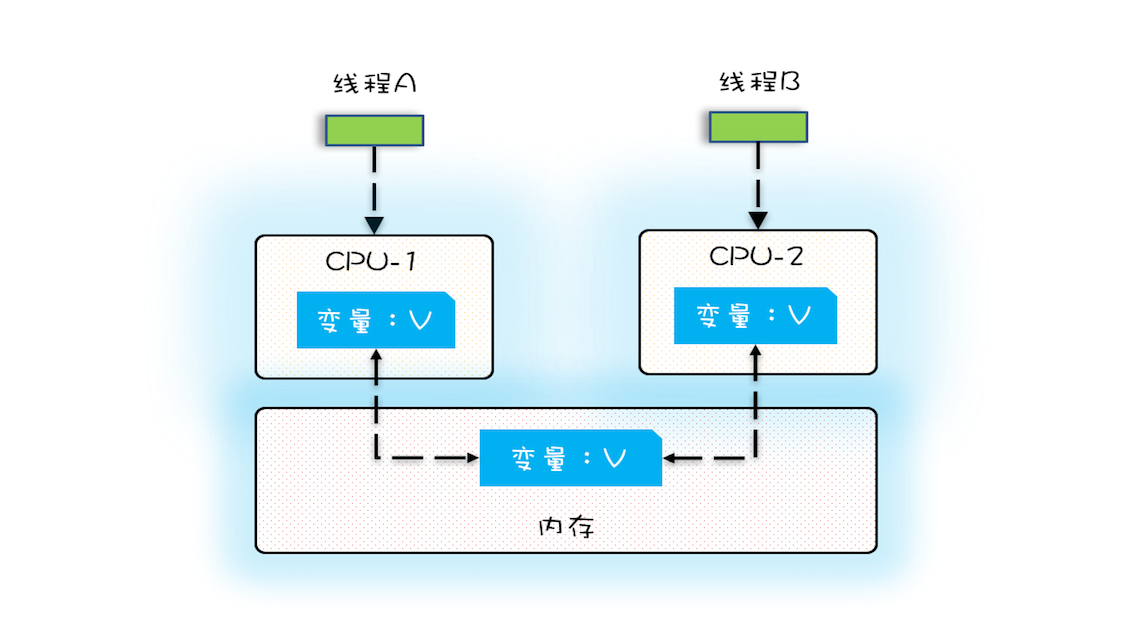
【示例】线程不安全的示例
下面我们再用一段代码来验证一下多核场景下的可见性问题。下面的代码,每执行一次 add10K () 方法,都会循环 10000 次 count+=1 操作。在 calc () 方法中我们创建了两个线程,每个线程调用一次 add10K () 方法,我们来想一想执行 calc () 方法得到的结果应该是多少呢?
public class Test {
private long count = 0;
private void add10K() {
int idx = 0;
while(idx++ < 10000) {
count += 1;
}
}
public static long calc() {
final Test test = new Test();
// 创建两个线程,执行 add() 操作
Thread th1 = new Thread(()->{
test.add10K();
});
Thread th2 = new Thread(()->{
test.add10K();
});
// 启动两个线程
th1.start();
th2.start();
// 等待两个线程执行结束
th1.join();
th2.join();
return count;
}
}直觉告诉我们应该是 20000,因为在单线程里调用两次 add10K () 方法,count 的值就是 20000,但实际上 calc () 的执行结果是个 10000 到 20000 之间的随机数。为什么呢?
我们假设线程 A 和线程 B 同时开始执行,那么第一次都会将 count=0 读到各自的 CPU 缓存里,执行完 count+=1 之后,各自 CPU 缓存里的值都是 1,同时写入内存后,我们会发现内存中是 1,而不是我们期望的 2。之后由于各自的 CPU 缓存里都有了 count 的值,两个线程都是基于 CPU 缓存里的 count 值来计算,所以导致最终 count 的值都是小于 20000 的。这就是缓存的可见性问题。
循环 10000 次 count+=1 操作如果改为循环 1 亿次,你会发现效果更明显,最终 count 的值接近 1 亿,而不是 2 亿。如果循环 10000 次,count 的值接近 20000,原因是两个线程不是同时启动的,有一个时差。
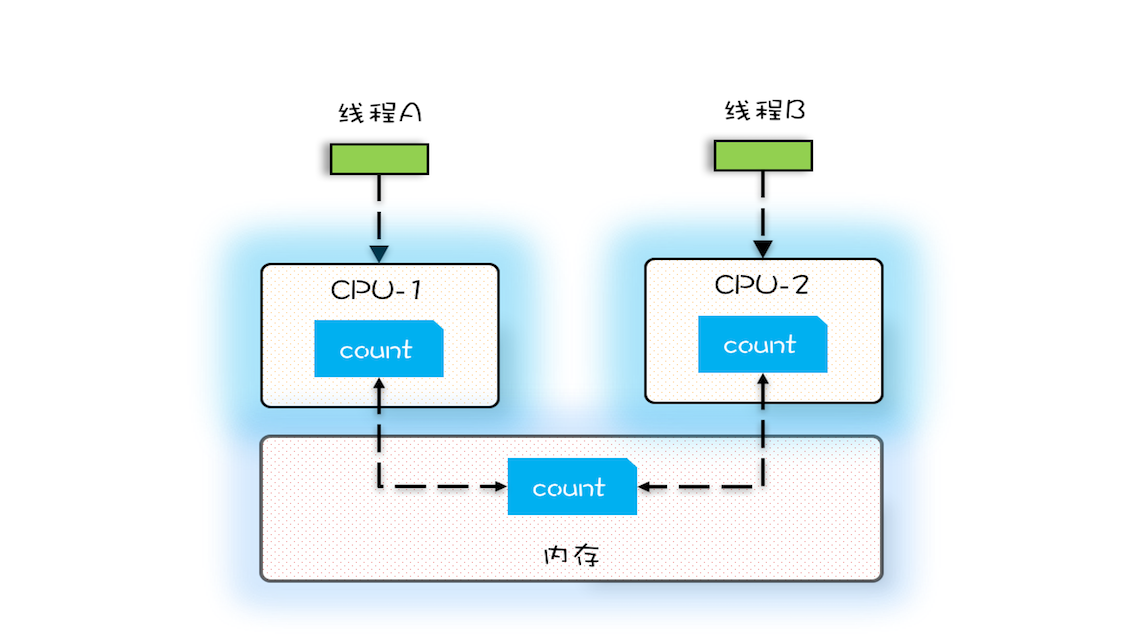
# #3.2. 线程切换带来的原子性问题
由于 IO 太慢,早期的操作系统就发明了多进程,操作系统允许某个进程执行一小段时间(称为 时间片)。
在一个时间片内,如果一个进程进行一个 IO 操作,例如读个文件,这个时候该进程可以把自己标记为 “休眠状态” 并出让 CPU 的使用权,待文件读进内存,操作系统会把这个休眠的进程唤醒,唤醒后的进程就有机会重新获得 CPU 的使用权了。
这里的进程在等待 IO 时之所以会释放 CPU 使用权,是为了让 CPU 在这段等待时间里可以做别的事情,这样一来 CPU 的使用率就上来了;此外,如果这时有另外一个进程也读文件,读文件的操作就会排队,磁盘驱动在完成一个进程的读操作后,发现有排队的任务,就会立即启动下一个读操作,这样 IO 的使用率也上来了。
早期的操作系统基于进程来调度 CPU,不同进程间是不共享内存空间的,所以进程要做任务切换就要切换内存映射地址,而一个进程创建的所有线程,都是共享一个内存空间的,所以线程做任务切换成本就很低了。现代的操作系统都基于更轻量的线程来调度,现在我们提到的 “任务切换” 都是指 “线程切换”。
Java 并发程序都是基于多线程的,自然也会涉及到任务切换,也许你想不到,任务切换竟然也是并发编程里诡异 Bug 的源头之一。任务切换的时机大多数是在时间片结束的时候,我们现在基本都使用高级语言编程,高级语言里一条语句往往需要多条 CPU 指令完成,例如上面代码中的 count += 1 ,至少需要三条 CPU 指令。
- 指令 1:首先,需要把变量 count 从内存加载到 CPU 的寄存器;
- 指令 2:之后,在寄存器中执行 +1 操作;
- 指令 3:最后,将结果写入内存(缓存机制导致可能写入的是 CPU 缓存而不是内存)。
操作系统做任务切换,可以发生在任何一条 CPU 指令执行完,是的,是 CPU 指令,而不是高级语言里的一条语句。对于上面的三条指令来说,我们假设 count=0,如果线程 A 在指令 1 执行完后做线程切换,线程 A 和线程 B 按照下图的序列执行,那么我们会发现两个线程都执行了 count+=1 的操作,但是得到的结果不是我们期望的 2,而是 1。
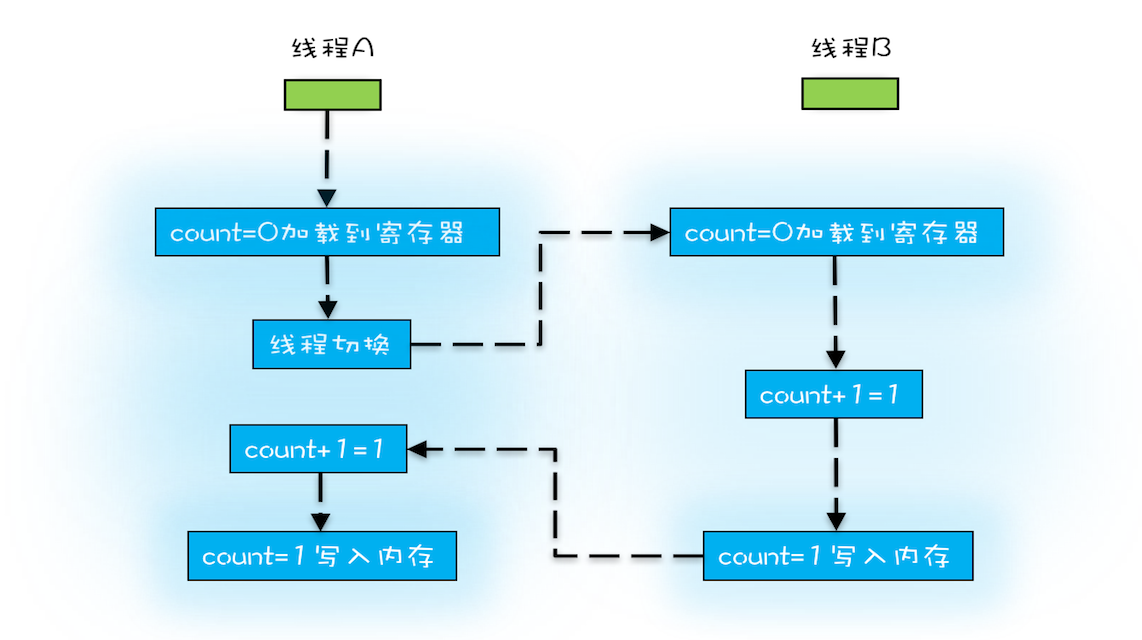
我们潜意识里面觉得 count+=1 这个操作是一个不可分割的整体,就像一个原子一样,线程的切换可以发生在 count+=1 之前,也可以发生在 count+=1 之后,但就是不会发生在中间。我们把一个或者多个操作在 CPU 执行的过程中不被中断的特性称为原子性。CPU 能保证的原子操作是 CPU 指令级别的,而不是高级语言的操作符,这是违背我们直觉的地方。因此,很多时候我们需要在高级语言层面保证操作的原子性。
# #3.3. 编译优化带来的有序性问题
那并发编程里还有没有其他有违直觉容易导致诡异 Bug 的技术呢?有的,就是有序性。顾名思义,有序性指的是程序按照代码的先后顺序执行。编译器为了优化性能,有时候会改变程序中语句的先后顺序,例如程序中:“a=6;b=7;” 编译器优化后可能变成 “b=7;a=6;”,在这个例子中,编译器调整了语句的顺序,但是不影响程序的最终结果。不过有时候编译器及解释器的优化可能导致意想不到的 Bug。
在 Java 领域一个经典的案例就是利用双重检查创建单例对象,例如下面的代码:在获取实例 getInstance () 的方法中,我们首先判断 instance 是否为空,如果为空,则锁定 Singleton.class 并再次检查 instance 是否为空,如果还为空则创建 Singleton 的一个实例。
public class Singleton {
static Singleton instance;
static Singleton getInstance(){
if (instance == null) {
synchronized(Singleton.class) {
if (instance == null)
instance = new Singleton();
}
}
return instance;
}
}假设有两个线程 A、B 同时调用 getInstance () 方法,他们会同时发现 instance == null ,于是同时对 Singleton.class 加锁,此时 JVM 保证只有一个线程能够加锁成功(假设是线程 A),另外一个线程则会处于等待状态(假设是线程 B);线程 A 会创建一个 Singleton 实例,之后释放锁,锁释放后,线程 B 被唤醒,线程 B 再次尝试加锁,此时是可以加锁成功的,加锁成功后,线程 B 检查 instance == null 时会发现,已经创建过 Singleton 实例了,所以线程 B 不会再创建一个 Singleton 实例。
这看上去一切都很完美,无懈可击,但实际上这个 getInstance () 方法并不完美。问题出在哪里呢?出在 new 操作上,我们以为的 new 操作应该是:
- 分配一块内存 M;
- 在内存 M 上初始化 Singleton 对象;
- 然后 M 的地址赋值给 instance 变量。
但是实际上优化后的执行路径却是这样的:
- 分配一块内存 M;
- 将 M 的地址赋值给 instance 变量;
- 最后在内存 M 上初始化 Singleton 对象。
优化后会导致什么问题呢?我们假设线程 A 先执行 getInstance () 方法,当执行完指令 2 时恰好发生了线程切换,切换到了线程 B 上;如果此时线程 B 也执行 getInstance () 方法,那么线程 B 在执行第一个判断时会发现 instance != null ,所以直接返回 instance,而此时的 instance 是没有初始化过的,如果我们这个时候访问 instance 的成员变量就可能触发空指针异常。
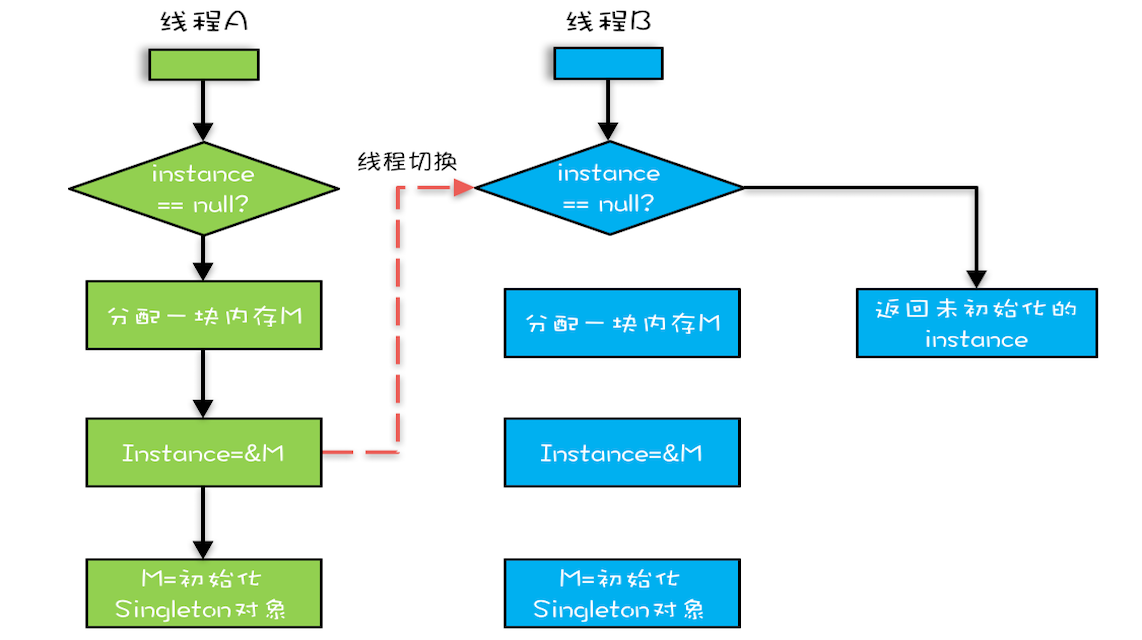
# #3.4. 保证并发安全的思路
# #互斥同步(阻塞同步)
互斥同步是最常见的并发正确性保障手段。
同步是指在多线程并发访问共享数据时,保证共享数据在同一时刻只能被一个线程访问。
互斥是实现同步的一种手段。临界区(Critical Sections)、互斥量(Mutex)和信号量(Semaphore)都是主要的互斥实现方式。
最典型的案例是使用 synchronized 或 Lock 。
互斥同步最主要的问题是线程阻塞和唤醒所带来的性能问题,互斥同步属于一种悲观的并发策略,总是认为只要不去做正确的同步措施,那就肯定会出现问题。无论共享数据是否真的会出现竞争,它都要进行加锁(这里讨论的是概念模型,实际上虚拟机会优化掉很大一部分不必要的加锁)、用户态核心态转换、维护锁计数器和检查是否有被阻塞的线程需要唤醒等操作。
# #非阻塞同步
随着硬件指令集的发展,我们可以使用基于冲突检测的乐观并发策略:先进行操作,如果没有其它线程争用共享数据,那操作就成功了,否则采取补偿措施(不断地重试,直到成功为止)。这种乐观的并发策略的许多实现都不需要将线程阻塞,因此这种同步操作称为非阻塞同步。
为什么说乐观锁需要 硬件指令集的发展 才能进行?因为需要操作和冲突检测这两个步骤具备原子性。而这点是由硬件来完成,如果再使用互斥同步来保证就失去意义了。
这类乐观锁指令常见的有:
- 测试并设置(Test-and-Set)
- 获取并增加(Fetch-and-Increment)
- 交换(Swap)
- 比较并交换(CAS)
- 加载链接、条件存储(Load-linked / Store-Conditional)
Java 典型应用场景:J.U.C 包中的原子类(基于 Unsafe 类的 CAS 操作)
# #无同步
要保证线程安全,不一定非要进行同步。同步只是保证共享数据争用时的正确性,如果一个方法本来就不涉及共享数据,那么自然无须同步。
Java 中的 无同步方案 有:
- 可重入代码 - 也叫纯代码。如果一个方法,它的 返回结果是可以预测的,即只要输入了相同的数据,就能返回相同的结果,那它就满足可重入性,当然也是线程安全的。
- 线程本地存储 - 使用
ThreadLocal为共享变量在每个线程中都创建了一个本地副本,这个副本只能被当前线程访问,其他线程无法访问,那么自然是线程安全的。
# #4. 活跃性问题
# #4.1. 死锁(Deadlock)
# #什么是死锁
多个线程互相等待对方释放锁。
死锁是当线程进入无限期等待状态时发生的情况,因为所请求的锁被另一个线程持有,而另一个线程又等待第一个线程持有的另一个锁。
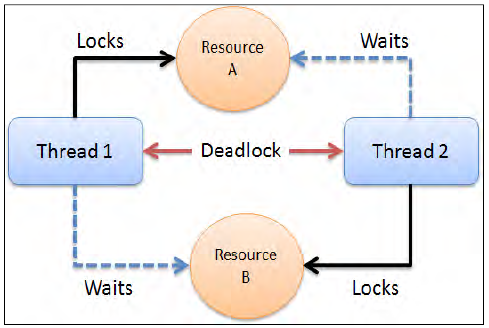
# #避免死锁
(1)按序加锁
当多个线程需要相同的一些锁,但是按照不同的顺序加锁,死锁就很容易发生。
如果能确保所有的线程都是按照相同的顺序获得锁,那么死锁就不会发生。
按照顺序加锁是一种有效的死锁预防机制。但是,这种方式需要你事先知道所有可能会用到的锁 (译者注:并对这些锁做适当的排序),但总有些时候是无法预知的。
(2)超时释放锁
另外一个可以避免死锁的方法是在尝试获取锁的时候加一个超时时间,这也就意味着在尝试获取锁的过程中若超过了这个时限该线程则放弃对该锁请求。若一个线程没有在给定的时限内成功获得所有需要的锁,则会进行回退并释放所有已经获得的锁,然后等待一段随机的时间再重试。这段随机的等待时间让其它线程有机会尝试获取相同的这些锁,并且让该应用在没有获得锁的时候可以继续运行 (译者注:加锁超时后可以先继续运行干点其它事情,再回头来重复之前加锁的逻辑)。
(3)死锁检测
死锁检测是一个更好的死锁预防机制,它主要是针对那些不可能实现按序加锁并且锁超时也不可行的场景。
每当一个线程获得了锁,会在线程和锁相关的数据结构中(map、graph 等等)将其记下。除此之外,每当有线程请求锁,也需要记录在这个数据结构中。
当一个线程请求锁失败时,这个线程可以遍历锁的关系图看看是否有死锁发生。
如果检测出死锁,有两种处理手段:
- 释放所有锁,回退,并且等待一段随机的时间后重试。这个和简单的加锁超时类似,不一样的是只有死锁已经发生了才回退,而不会是因为加锁的请求超时了。虽然有回退和等待,但是如果有大量的线程竞争同一批锁,它们还是会重复地死锁(编者注:原因同超时类似,不能从根本上减轻竞争)。
- 一个更好的方案是给这些线程设置优先级,让一个(或几个)线程回退,剩下的线程就像没发生死锁一样继续保持着它们需要的锁。如果赋予这些线程的优先级是固定不变的,同一批线程总是会拥有更高的优先级。为避免这个问题,可以在死锁发生的时候设置随机的优先级。
# #4.2. 活锁(Livelock)
# #什么是活锁
活锁是一个递归的情况,两个或更多的线程会不断重复一个特定的代码逻辑。预期的逻辑通常为其他线程提供机会继续支持’this’线程。
想象这样一个例子:两个人在狭窄的走廊里相遇,二者都很礼貌,试图移到旁边让对方先通过。但是他们最终在没有取得任何进展的情况下左右摇摆,因为他们都在同一时间向相同的方向移动。
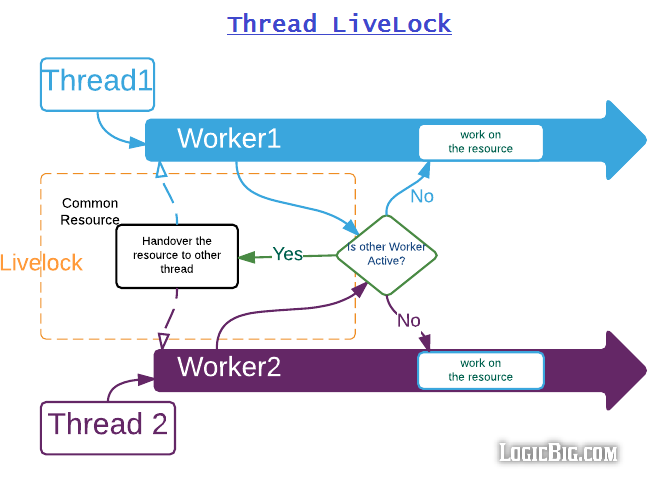
如图所示:两个线程想要通过一个 Worker 对象访问共享公共资源的情况,但是当他们看到另一个 Worker(在另一个线程上调用)也是 “活动的” 时,它们会尝试将该资源交给其他工作者并等待为它完成。如果最初我们让两名工作人员都活跃起来,他们将会面临活锁问题。
# #避免活锁
解决 “活锁” 的方案很简单,谦让时,尝试等待一个随机的时间就可以了。由于等待的时间是随机的,所以同时相撞后再次相撞的概率就很低了。“等待一个随机时间” 的方案虽然很简单,却非常有效,Raft 这样知名的分布式一致性算法中也用到了它。
# #4.3. 饥饿(Starvation)
# #什么是饥饿
- 高优先级线程吞噬所有的低优先级线程的 CPU 时间。
- 线程被永久堵塞在一个等待进入同步块的状态,因为其他线程总是能在它之前持续地对该同步块进行访问。
- 线程在等待一个本身 (在其上调用 wait ()) 也处于永久等待完成的对象,因为其他线程总是被持续地获得唤醒。
饥饿问题最经典的例子就是哲学家问题。如图所示:有五个哲学家用餐,每个人要获得两把叉子才可以就餐。当 2、4 就餐时,1、3、5 永远无法就餐,只能看着盘中的美食饥饿的等待着。
# #解决饥饿
Java 不可能实现 100% 的公平性,我们依然可以通过同步结构在线程间实现公平性的提高。
有三种方案:
- 保证资源充足
- 公平地分配资源
- 避免持有锁的线程长时间执行
这三个方案中,方案一和方案三的适用场景比较有限,因为很多场景下,资源的稀缺性是没办法解决的,持有锁的线程执行的时间也很难缩短。倒是方案二的适用场景相对来说更多一些。
那如何公平地分配资源呢?在并发编程里,主要是使用公平锁。所谓公平锁,是一种先来后到的方案,线程的等待是有顺序的,排在等待队列前面的线程会优先获得资源。
# #5. 性能问题
并发执行一定比串行执行快吗?线程越多执行越快吗?
答案是:并发不一定比串行快。因为有创建线程和线程上下文切换的开销。
# #5.1. 上下文切换
# #什么是上下文切换?
当 CPU 从执行一个线程切换到执行另一个线程时,CPU 需要保存当前线程的本地数据,程序指针等状态,并加载下一个要执行的线程的本地数据,程序指针等。这个开关被称为 “上下文切换”。
# #减少上下文切换的方法
- 无锁并发编程 - 多线程竞争锁时,会引起上下文切换,所以多线程处理数据时,可以用一些办法来避免使用锁,如将数据的 ID 按照 Hash 算法取模分段,不同的线程处理不同段的数据。
- CAS 算法 - Java 的 Atomic 包使用 CAS 算法来更新数据,而不需要加锁。
- 使用最少线程 - 避免创建不需要的线程,比如任务很少,但是创建了很多线程来处理,这样会造成大量线程都处于等待状态。
- 使用协程 - 在单线程里实现多任务的调度,并在单线程里维持多个任务间的切换。
# #5.2. 资源限制
# #什么是资源限制
资源限制是指在进行并发编程时,程序的执行速度受限于计算机硬件资源或软件资源。
# #资源限制引发的问题
在并发编程中,将代码执行速度加快的原则是将代码中串行执行的部分变成并发执行,但是如果将某段串行的代码并发执行,因为受限于资源,仍然在串行执行,这时候程序不仅不会加快执行,反而会更慢,因为增加了上下文切换和资源调度的时间。
# #如何解决资源限制的问题
在资源限制情况下进行并发编程,根据不同的资源限制调整程序的并发度。
- 对于硬件资源限制,可以考虑使用集群并行执行程序。
- 对于软件资源限制,可以考虑使用资源池将资源复用。
# #6. 小结
并发编程可以总结为三个核心问题:分工、同步、互斥。
- 分工:是指如何高效地拆解任务并分配给线程。
- 同步:是指线程之间如何协作。
- 互斥:是指保证同一时刻只允许一个线程访问共享资源。
# Java 线程基础
📦 本文以及示例源码已归档在 javacore(opens new window)
关键词:
Thread、Runnable、Callable、Future、wait、notify、notifyAll、join、sleep、yeild、线程状态、线程通信
# #1. 线程简介
# #1.1. 什么是进程
简言之,进程可视为一个正在运行的程序。它是系统运行程序的基本单位,因此进程是动态的。进程是具有一定独立功能的程序关于某个数据集合上的一次运行活动。进程是操作系统进行资源分配的基本单位。
# #1.2. 什么是线程
线程是操作系统进行调度的基本单位。线程也叫轻量级进程(Light Weight Process),在一个进程里可以创建多个线程,这些线程都拥有各自的计数器、堆栈和局部变量等属性,并且能够访问共享的内存变量。
# #1.3. 进程和线程的区别
- 一个程序至少有一个进程,一个进程至少有一个线程。
- 线程比进程划分更细,所以执行开销更小,并发性更高。
- 进程是一个实体,拥有独立的资源;而同一个进程中的多个线程共享进程的资源。
# #2. 创建线程
创建线程有三种方式:
- 继承
Thread类 - 实现
Runnable接口 - 实现
Callable接口
# #2.1. Thread
通过继承 Thread 类创建线程的步骤:
- 定义
Thread类的子类,并覆写该类的run方法。run方法的方法体就代表了线程要完成的任务,因此把run方法称为执行体。 - 创建
Thread子类的实例,即创建了线程对象。 - 调用线程对象的
start方法来启动该线程。
public class ThreadDemo {
public static void main(String[] args) {
// 实例化对象
MyThread tA = new MyThread("Thread 线程-A");
MyThread tB = new MyThread("Thread 线程-B");
// 调用线程主体
tA.start();
tB.start();
}
static class MyThread extends Thread {
private int ticket = 5;
MyThread(String name) {
super(name);
}
@Override
public void run() {
while (ticket > 0) {
System.out.println(Thread.currentThread().getName() + " 卖出了第 " + ticket + " 张票");
ticket--;
}
}
}
}# #2.2. Runnable
实现 Runnable 接口优于继承 Thread 类,因为:
- Java 不支持多重继承,所有的类都只允许继承一个父类,但可以实现多个接口。如果继承了
Thread类就无法继承其它类,这不利于扩展。 - 类可能只要求可执行就行,继承整个
Thread类开销过大。
通过实现 Runnable 接口创建线程的步骤:
- 定义
Runnable接口的实现类,并覆写该接口的run方法。该run方法的方法体同样是该线程的线程执行体。 - 创建
Runnable实现类的实例,并以此实例作为Thread的 target 来创建Thread对象,该Thread对象才是真正的线程对象。 - 调用线程对象的
start方法来启动该线程。
public class RunnableDemo {
public static void main(String[] args) {
// 实例化对象
Thread tA = new Thread(new MyThread(), "Runnable 线程-A");
Thread tB = new Thread(new MyThread(), "Runnable 线程-B");
// 调用线程主体
tA.start();
tB.start();
}
static class MyThread implements Runnable {
private int ticket = 5;
@Override
public void run() {
while (ticket > 0) {
System.out.println(Thread.currentThread().getName() + " 卖出了第 " + ticket + " 张票");
ticket--;
}
}
}
}# #2.3. Callable、Future、FutureTask
继承 Thread 类和实现 Runnable 接口这两种创建线程的方式都没有返回值。所以,线程执行完后,无法得到执行结果。但如果期望得到执行结果该怎么做?
为了解决这个问题,Java 1.5 后,提供了 Callable 接口和 Future 接口,通过它们,可以在线程执行结束后,返回执行结果。
# #Callable
Callable 接口只声明了一个方法,这个方法叫做 call ():
public interface Callable<V> {
/**
* Computes a result, or throws an exception if unable to do so.
*
* @return computed result
* @throws Exception if unable to compute a result
*/
V call() throws Exception;
}那么怎么使用 Callable 呢?一般情况下是配合 ExecutorService 来使用的,在 ExecutorService 接口中声明了若干个 submit 方法的重载版本:
<T> Future<T> submit(Callable<T> task);
<T> Future<T> submit(Runnable task, T result);
Future<?> submit(Runnable task);第一个 submit 方法里面的参数类型就是 Callable。
# #Future
Future 就是对于具体的 Callable 任务的执行结果进行取消、查询是否完成、获取结果。必要时可以通过 get 方法获取执行结果,该方法会阻塞直到任务返回结果。
public interface Future<V> {
boolean cancel(boolean mayInterruptIfRunning);
boolean isCancelled();
boolean isDone();
V get() throws InterruptedException, ExecutionException;
V get(long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException;
}# #FutureTask
FutureTask 类实现了 RunnableFuture 接口,RunnableFuture 继承了 Runnable 接口和 Future 接口。
所以,FutureTask 既可以作为 Runnable 被线程执行,又可以作为 Future 得到 Callable 的返回值。
public class FutureTask<V> implements RunnableFuture<V> {
// ...
public FutureTask(Callable<V> callable) {}
public FutureTask(Runnable runnable, V result) {}
}
public interface RunnableFuture<V> extends Runnable, Future<V> {
void run();
}事实上,FutureTask 是 Future 接口的一个唯一实现类。
# #Callable + Future + FutureTask 示例
通过实现 Callable 接口创建线程的步骤:
- 创建
Callable接口的实现类,并实现call方法。该call方法将作为线程执行体,并且有返回值。 - 创建
Callable实现类的实例,使用FutureTask类来包装Callable对象,该FutureTask对象封装了该Callable对象的call方法的返回值。 - 使用
FutureTask对象作为Thread对象的 target 创建并启动新线程。 - 调用
FutureTask对象的get方法来获得线程执行结束后的返回值。
public class CallableDemo {
public static void main(String[] args) {
Callable<Long> callable = new MyThread();
FutureTask<Long> future = new FutureTask<>(callable);
new Thread(future, "Callable 线程").start();
try {
System.out.println("任务耗时:" + (future.get() / 1000000) + "毫秒");
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
}
static class MyThread implements Callable<Long> {
private int ticket = 10000;
@Override
public Long call() {
long begin = System.nanoTime();
while (ticket > 0) {
System.out.println(Thread.currentThread().getName() + " 卖出了第 " + ticket + " 张票");
ticket--;
}
long end = System.nanoTime();
return (end - begin);
}
}
}# #3. 线程基本用法
线程( Thread )基本方法清单:
| 方法 | 描述 |
|---|---|
run |
线程的执行实体。 |
start |
线程的启动方法。 |
currentThread |
返回对当前正在执行的线程对象的引用。 |
setName |
设置线程名称。 |
getName |
获取线程名称。 |
setPriority |
设置线程优先级。Java 中的线程优先级的范围是 [1,10],一般来说,高优先级的线程在运行时会具有优先权。可以通过 thread.setPriority(Thread.MAX_PRIORITY) 的方式设置,默认优先级为 5。 |
getPriority |
获取线程优先级。 |
setDaemon |
设置线程为守护线程。 |
isDaemon |
判断线程是否为守护线程。 |
isAlive |
判断线程是否启动。 |
interrupt |
中断另一个线程的运行状态。 |
interrupted |
测试当前线程是否已被中断。通过此方法可以清除线程的中断状态。换句话说,如果要连续调用此方法两次,则第二次调用将返回 false(除非当前线程在第一次调用清除其中断状态之后且在第二次调用检查其状态之前再次中断)。 |
join |
可以使一个线程强制运行,线程强制运行期间,其他线程无法运行,必须等待此线程完成之后才可以继续执行。 |
Thread.sleep |
静态方法。将当前正在执行的线程休眠。 |
Thread.yield |
静态方法。将当前正在执行的线程暂停,让其他线程执行。 |
# #3.1. 线程休眠
使用 Thread.sleep 方法可以使得当前正在执行的线程进入休眠状态。
使用 Thread.sleep 需要向其传入一个整数值,这个值表示线程将要休眠的毫秒数。
Thread.sleep 方法可能会抛出 InterruptedException ,因为异常不能跨线程传播回 main 中,因此必须在本地进行处理。线程中抛出的其它异常也同样需要在本地进行处理。
public class ThreadSleepDemo {
public static void main(String[] args) {
new Thread(new MyThread("线程A", 500)).start();
new Thread(new MyThread("线程B", 1000)).start();
new Thread(new MyThread("线程C", 1500)).start();
}
static class MyThread implements Runnable {
/** 线程名称 */
private String name;
/** 休眠时间 */
private int time;
private MyThread(String name, int time) {
this.name = name;
this.time = time;
}
@Override
public void run() {
try {
// 休眠指定的时间
Thread.sleep(this.time);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(this.name + "休眠" + this.time + "毫秒。");
}
}
}# #3.2. 线程礼让
Thread.yield 方法的调用声明了当前线程已经完成了生命周期中最重要的部分,可以切换给其它线程来执行 。
该方法只是对线程调度器的一个建议,而且也只是建议具有相同优先级的其它线程可以运行。
public class ThreadYieldDemo {
public static void main(String[] args) {
MyThread t = new MyThread();
new Thread(t, "线程A").start();
new Thread(t, "线程B").start();
}
static class MyThread implements Runnable {
@Override
public void run() {
for (int i = 0; i < 5; i++) {
try {
Thread.sleep(1000);
} catch (Exception e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + "运行,i = " + i);
if (i == 2) {
System.out.print("线程礼让:");
Thread.yield();
}
}
}
}
}# #3.3. 终止线程
Thread中的stop方法有缺陷,已废弃。使用
Thread.stop停止线程会导致它解锁所有已锁定的监视器(由于未经检查的ThreadDeath异常会在堆栈中传播,这是自然的结果)。 如果先前由这些监视器保护的任何对象处于不一致状态,则损坏的对象将对其他线程可见,从而可能导致任意行为。stop () 方法会真的杀死线程,不给线程喘息的机会,如果线程持有 ReentrantLock 锁,被 stop () 的线程并不会自动调用 ReentrantLock 的 unlock () 去释放锁,那其他线程就再也没机会获得 ReentrantLock 锁,这实在是太危险了。所以该方法就不建议使用了,类似的方法还有 suspend () 和 resume () 方法,这两个方法同样也都不建议使用了,所以这里也就不多介绍了。
Thread.stop的许多用法应由仅修改某些变量以指示目标线程应停止运行的代码代替。 目标线程应定期检查此变量,如果该变量指示要停止运行,则应按有序方式从其运行方法返回。如果目标线程等待很长时间(例如,在条件变量上),则应使用中断方法来中断等待。
当一个线程运行时,另一个线程可以直接通过 interrupt 方法中断其运行状态。
public class ThreadInterruptDemo {
public static void main(String[] args) {
MyThread mt = new MyThread(); // 实例化Runnable子类对象
Thread t = new Thread(mt, "线程"); // 实例化Thread对象
t.start(); // 启动线程
try {
Thread.sleep(2000); // 线程休眠2秒
} catch (InterruptedException e) {
System.out.println("3、main线程休眠被终止");
}
t.interrupt(); // 中断线程执行
}
static class MyThread implements Runnable {
@Override
public void run() {
System.out.println("1、进入run()方法");
try {
Thread.sleep(10000); // 线程休眠10秒
System.out.println("2、已经完成了休眠");
} catch (InterruptedException e) {
System.out.println("3、MyThread线程休眠被终止");
return; // 返回调用处
}
System.out.println("4、run()方法正常结束");
}
}
}如果一个线程的 run 方法执行一个无限循环,并且没有执行 sleep 等会抛出 InterruptedException 的操作,那么调用线程的 interrupt 方法就无法使线程提前结束。
但是调用 interrupt 方法会设置线程的中断标记,此时调用 interrupted 方法会返回 true 。因此可以在循环体中使用 interrupted 方法来判断线程是否处于中断状态,从而提前结束线程。
安全地终止线程有两种方法:
- 定义
volatile标志位,在run方法中使用标志位控制线程终止 - 使用
interrupt方法和Thread.interrupted方法配合使用来控制线程终止
【示例】使用 volatile 标志位控制线程终止
public class ThreadStopDemo2 {
public static void main(String[] args) throws Exception {
MyTask task = new MyTask();
Thread thread = new Thread(task, "MyTask");
thread.start();
TimeUnit.MILLISECONDS.sleep(50);
task.cancel();
}
private static class MyTask implements Runnable {
private volatile boolean flag = true;
private volatile long count = 0L;
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + " 线程启动");
while (flag) {
System.out.println(count++);
}
System.out.println(Thread.currentThread().getName() + " 线程终止");
}
/**
* 通过 volatile 标志位来控制线程终止
*/
public void cancel() {
flag = false;
}
}
}【示例】使用 interrupt 方法和 Thread.interrupted 方法配合使用来控制线程终止
public class ThreadStopDemo3 {
public static void main(String[] args) throws Exception {
MyTask task = new MyTask();
Thread thread = new Thread(task, "MyTask");
thread.start();
TimeUnit.MILLISECONDS.sleep(50);
thread.interrupt();
}
private static class MyTask implements Runnable {
private volatile long count = 0L;
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + " 线程启动");
// 通过 Thread.interrupted 和 interrupt 配合来控制线程终止
while (!Thread.interrupted()) {
System.out.println(count++);
}
System.out.println(Thread.currentThread().getName() + " 线程终止");
}
}
}# #3.4. 守护线程
什么是守护线程?
- 守护线程(Daemon Thread)是在后台执行并且不会阻止 JVM 终止的线程。当所有非守护线程结束时,程序也就终止,同时会杀死所有守护线程。
- 与守护线程(Daemon Thread)相反的,叫用户线程(User Thread),也就是非守护线程。
为什么需要守护线程?
- 守护线程的优先级比较低,用于为系统中的其它对象和线程提供服务。典型的应用就是垃圾回收器。
如何使用守护线程?
-
可以使用
isDaemon方法判断线程是否为守护线程。 -
可以使用
setDaemon
方法设置线程为守护线程。
- 正在运行的用户线程无法设置为守护线程,所以 `setDaemon` 必须在 `thread.start` 方法之前设置,否则会抛出 `llegalThreadStateException` 异常;
- 一个守护线程创建的子线程依然是守护线程。
- 不要认为所有的应用都可以分配给守护线程来进行服务,比如读写操作或者计算逻辑。
public class ThreadDaemonDemo {
public static void main(String[] args) {
Thread t = new Thread(new MyThread(), "线程");
t.setDaemon(true); // 此线程在后台运行
System.out.println("线程 t 是否是守护进程:" + t.isDaemon());
t.start(); // 启动线程
}
static class MyThread implements Runnable {
@Override
public void run() {
while (true) {
System.out.println(Thread.currentThread().getName() + "在运行。");
}
}
}
}# #4. 线程通信
当多个线程可以一起工作去解决某个问题时,如果某些部分必须在其它部分之前完成,那么就需要对线程进行协调。
# #4.1. wait/notify/notifyAll
wait-wait会自动释放当前线程占有的对象锁,并请求操作系统挂起当前线程,让线程从Running状态转入Waiting状态,等待notify/notifyAll来唤醒。如果没有释放锁,那么其它线程就无法进入对象的同步方法或者同步控制块中,那么就无法执行notify或者notifyAll来唤醒挂起的线程,造成死锁。notify- 唤醒一个正在Waiting状态的线程,并让它拿到对象锁,具体唤醒哪一个线程由 JVM 控制 。notifyAll- 唤醒所有正在Waiting状态的线程,接下来它们需要竞争对象锁。
注意:
wait、notify、notifyAll都是Object类中的方法,而非Thread。wait、notify、notifyAll只能用在synchronized方法或者synchronized代码块中使用,否则会在运行时抛出IllegalMonitorStateException。为什么
wait、notify、notifyAll不定义在Thread中?为什么wait、notify、notifyAll要配合synchronized使用?首先,需要了解几个基本知识点:
- 每一个 Java 对象都有一个与之对应的 监视器(monitor)
- 每一个监视器里面都有一个 对象锁 、一个 等待队列、一个 同步队列
了解了以上概念,我们回过头来理解前面两个问题。
为什么这几个方法不定义在
Thread中?由于每个对象都拥有对象锁,让当前线程等待某个对象锁,自然应该基于这个对象(
Object)来操作,而非使用当前线程(Thread)来操作。因为当前线程可能会等待多个线程的锁,如果基于线程(Thread)来操作,就非常复杂了。为什么
wait、notify、notifyAll要配合synchronized使用?如果调用某个对象的
wait方法,当前线程必须拥有这个对象的对象锁,因此调用wait方法必须在synchronized方法和synchronized代码块中。
生产者、消费者模式是 wait 、 notify 、 notifyAll 的一个经典使用案例:
public class ThreadWaitNotifyDemo02 {
private static final int QUEUE_SIZE = 10;
private static final PriorityQueue<Integer> queue = new PriorityQueue<>(QUEUE_SIZE);
public static void main(String[] args) {
new Producer("生产者A").start();
new Producer("生产者B").start();
new Consumer("消费者A").start();
new Consumer("消费者B").start();
}
static class Consumer extends Thread {
Consumer(String name) {
super(name);
}
@Override
public void run() {
while (true) {
synchronized (queue) {
while (queue.size() == 0) {
try {
System.out.println("队列空,等待数据");
queue.wait();
} catch (InterruptedException e) {
e.printStackTrace();
queue.notifyAll();
}
}
queue.poll(); // 每次移走队首元素
queue.notifyAll();
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + " 从队列取走一个元素,队列当前有:" + queue.size() + "个元素");
}
}
}
}
static class Producer extends Thread {
Producer(String name) {
super(name);
}
@Override
public void run() {
while (true) {
synchronized (queue) {
while (queue.size() == QUEUE_SIZE) {
try {
System.out.println("队列满,等待有空余空间");
queue.wait();
} catch (InterruptedException e) {
e.printStackTrace();
queue.notifyAll();
}
}
queue.offer(1); // 每次插入一个元素
queue.notifyAll();
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + " 向队列取中插入一个元素,队列当前有:" + queue.size() + "个元素");
}
}
}
}
}# #4.2. join
在线程操作中,可以使用 join 方法让一个线程强制运行,线程强制运行期间,其他线程无法运行,必须等待此线程完成之后才可以继续执行。
public class ThreadJoinDemo {
public static void main(String[] args) {
MyThread mt = new MyThread(); // 实例化Runnable子类对象
Thread t = new Thread(mt, "mythread"); // 实例化Thread对象
t.start(); // 启动线程
for (int i = 0; i < 50; i++) {
if (i > 10) {
try {
t.join(); // 线程强制运行
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("Main 线程运行 --> " + i);
}
}
static class MyThread implements Runnable {
@Override
public void run() {
for (int i = 0; i < 50; i++) {
System.out.println(Thread.currentThread().getName() + " 运行,i = " + i); // 取得当前线程的名字
}
}
}
}# #4.3. 管道
管道输入 / 输出流和普通的文件输入 / 输出流或者网络输入 / 输出流不同之处在于,它主要用于线程之间的数据传输,而传输的媒介为内存。 管道输入 / 输出流主要包括了如下 4 种具体实现: PipedOutputStream 、 PipedInputStream 、 PipedReader 和 PipedWriter ,前两种面向字节,而后两种面向字符。
public class Piped {
public static void main(String[] args) throws Exception {
PipedWriter out = new PipedWriter();
PipedReader in = new PipedReader();
// 将输出流和输入流进行连接,否则在使用时会抛出IOException
out.connect(in);
Thread printThread = new Thread(new Print(in), "PrintThread");
printThread.start();
int receive = 0;
try {
while ((receive = System.in.read()) != -1) {
out.write(receive);
}
} finally {
out.close();
}
}
static class Print implements Runnable {
private PipedReader in;
Print(PipedReader in) {
this.in = in;
}
public void run() {
int receive = 0;
try {
while ((receive = in.read()) != -1) {
System.out.print((char) receive);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}# #5. 线程生命周期
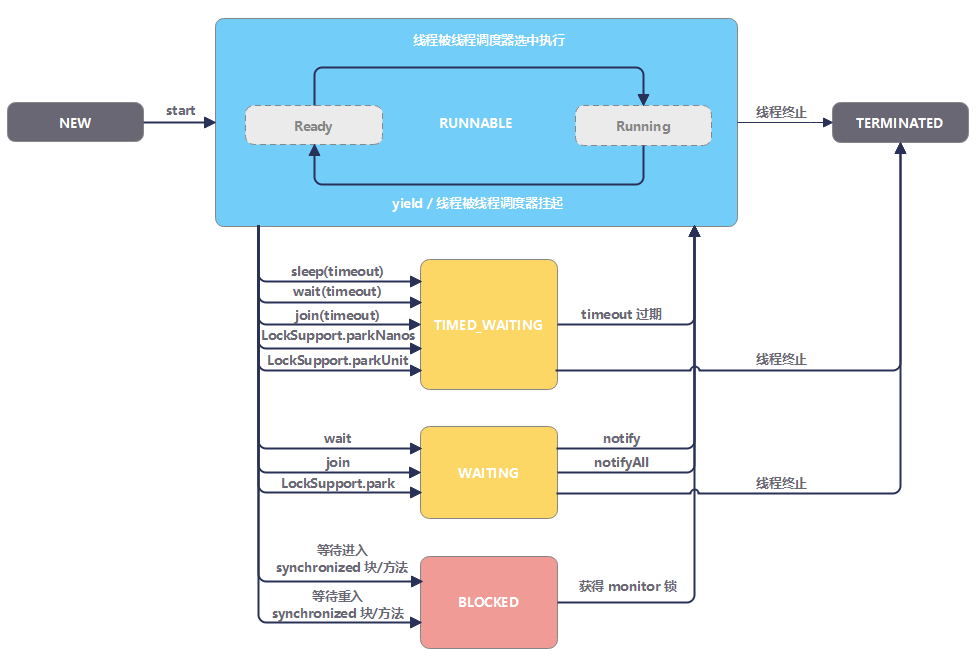
java.lang.Thread.State 中定义了 6 种不同的线程状态,在给定的一个时刻,线程只能处于其中的一个状态。
以下是各状态的说明,以及状态间的联系:
-
新建(New) - 尚未调用
start方法的线程处于此状态。此状态意味着:创建的线程尚未启动。 -
就绪(Runnable) - 已经调用了
start方法的线程处于此状态。此状态意味着:线程已经在 JVM 中运行。但是在操作系统层面,它可能处于运行状态,也可能等待资源调度(例如处理器资源),资源调度完成就进入运行状态。所以该状态的可运行是指可以被运行,具体有没有运行要看底层操作系统的资源调度。 -
阻塞(Blocked) - 此状态意味着:线程处于被阻塞状态。表示线程在等待
synchronized的隐式锁(Monitor lock)。synchronized修饰的方法、代码块同一时刻只允许一个线程执行,其他线程只能等待,即处于阻塞状态。当占用synchronized隐式锁的线程释放锁,并且等待的线程获得synchronized隐式锁时,就又会从BLOCKED转换到RUNNABLE状态。 -
等待(Waiting) - 此状态意味着:线程无限期等待,直到被其他线程显式地唤醒。 阻塞和等待的区别在于,阻塞是被动的,它是在等待获取
synchronized的隐式锁。而等待是主动的,通过调用Object.wait等方法进入。进入方法 退出方法 没有设置 Timeout 参数的 Object.wait方法Object.notify/Object.notifyAll没有设置 Timeout 参数的 Thread.join方法被调用的线程执行完毕 |
LockSupport.park方法(Java 并发包中的锁,都是基于它实现的) |LockSupport.unpark| -
定时等待(Timed waiting) - 此状态意味着:无需等待其它线程显式地唤醒,在一定时间之后会被系统自动唤醒。
进入方法 退出方法 |
Thread.sleep方法 | 时间结束 |
| 获得synchronized隐式锁的线程,调用设置了 Timeout 参数的Object.wait方法 | 时间结束 /Object.notify/Object.notifyAll|
| 设置了 Timeout 参数的Thread.join方法 | 时间结束 / 被调用的线程执行完毕 |
|LockSupport.parkNanos方法 |LockSupport.unpark|
|LockSupport.parkUntil方法 |LockSupport.unpark| -
终止 (Terminated) - 线程执行完
run方法,或者因异常退出了run方法。此状态意味着:线程结束了生命周期。
# #6. 线程常见问题
# #6.1. sleep、yield、join 方法有什么区别
-
yield 方法 - `yield` 方法会 **让线程从 `Running` 状态转入 `Runnable` 状态**。 - 当调用了 `yield` 方法后,只有**与当前线程相同或更高优先级的`Runnable` 状态线程才会获得执行的机会**。 - ``` sleep
方法
- `sleep` 方法会 **让线程从 `Running` 状态转入 `Waiting` 状态**。
- `sleep` 方法需要指定等待的时间,**超过等待时间后,JVM 会将线程从 `Waiting` 状态转入 `Runnable` 状态**。
- 当调用了 `sleep` 方法后,**无论什么优先级的线程都可以得到执行机会**。
- `sleep` 方法不会释放“锁标志”,也就是说如果有 `synchronized` 同步块,其他线程仍然不能访问共享数据。
-
join- `join` 方法会 **让线程从 `Running` 状态转入 `Waiting` 状态**。 - 当调用了 `join` 方法后,**当前线程必须等待调用 `join` 方法的线程结束后才能继续执行**。 ### [#](https://dunwu.github.io/javacore/concurrent/Java线程基础.html#_6-2-为什么-sleep-和-yield-方法是静态的)6.2. 为什么 sleep 和 yield 方法是静态的 `Thread` 类的 `sleep` 和 `yield` 方法将处理 `Running` 状态的线程。 所以在其他处于非 `Running` 状态的线程上执行这两个方法是没有意义的。这就是为什么这些方法是静态的。它们可以在当前正在执行的线程中工作,并避免程序员错误的认为可以在其他非运行线程调用这些方法。 ### [#](https://dunwu.github.io/javacore/concurrent/Java线程基础.html#_6-3-java-线程是否按照线程优先级严格执行)6.3. Java 线程是否按照线程优先级严格执行 即使设置了线程的优先级,也**无法保证高优先级的线程一定先执行**。 原因在于线程优先级依赖于操作系统的支持,然而,不同的操作系统支持的线程优先级并不相同,不能很好的和 Java 中线程优先级一一对应。 ### [#](https://dunwu.github.io/javacore/concurrent/Java线程基础.html#_6-4-一个线程两次调用-start-方法会怎样)6.4. 一个线程两次调用 start()方法会怎样 Java 的线程是不允许启动两次的,第二次调用必然会抛出 IllegalThreadStateException,这是一种运行时异常,多次调用 start 被认为是编程错误。 ### [#](https://dunwu.github.io/javacore/concurrent/Java线程基础.html#_6-5-start-和-run-方法有什么区别)6.5. `start` 和 `run` 方法有什么区别 - `run` 方法是线程的执行体。 - `start` 方法会启动线程,然后 JVM 会让这个线程去执行 `run` 方法。 ### [#](https://dunwu.github.io/javacore/concurrent/Java线程基础.html#_6-6-可以直接调用-thread-类的-run-方法么)6.6. 可以直接调用 `Thread` 类的 `run` 方法么 - 可以。但是如果直接调用 `Thread` 的 `run` 方法,它的行为就会和普通的方法一样。 - 为了在新的线程中执行我们的代码,必须使用 `Thread` 的 `start` 方法。 --- # Java 并发核心机制 > **📦 本文以及示例源码已归档在 [javacore(opens new window)](https://github.com/dunwu/javacore/)** > > Java 对于并发的支持主要汇聚在 `java.util.concurrent`,即 J.U.C。而 J.U.C 的核心是 `AQS`。 - [1. J.U.C 简介](https://dunwu.github.io/javacore/concurrent/Java并发核心机制.html#1-juc-简介) - \2. synchronized - [2.1. synchronized 的应用](https://dunwu.github.io/javacore/concurrent/Java并发核心机制.html#21-synchronized-的应用) - [2.2. synchronized 的原理](https://dunwu.github.io/javacore/concurrent/Java并发核心机制.html#22-synchronized-的原理) - [2.3. synchronized 的优化](https://dunwu.github.io/javacore/concurrent/Java并发核心机制.html#23-synchronized-的优化) - [2.4. synchronized 的误区](https://dunwu.github.io/javacore/concurrent/Java并发核心机制.html#24-synchronized-的误区) - \3. volatile - [3.1. volatile 的要点](https://dunwu.github.io/javacore/concurrent/Java并发核心机制.html#31-volatile-的要点) - [3.2. volatile 的应用](https://dunwu.github.io/javacore/concurrent/Java并发核心机制.html#32-volatile-的应用) - [3.3. volatile 的原理](https://dunwu.github.io/javacore/concurrent/Java并发核心机制.html#33-volatile-的原理) - [3.4. volatile 的问题](https://dunwu.github.io/javacore/concurrent/Java并发核心机制.html#34-volatile-的问题) - \4. CAS - [4.1. CAS 的要点](https://dunwu.github.io/javacore/concurrent/Java并发核心机制.html#41-cas-的要点) - [4.2. CAS 的应用](https://dunwu.github.io/javacore/concurrent/Java并发核心机制.html#42-cas-的应用) - [4.3. CAS 的原理](https://dunwu.github.io/javacore/concurrent/Java并发核心机制.html#43-cas-的原理) - [4.4. CAS 的问题](https://dunwu.github.io/javacore/concurrent/Java并发核心机制.html#44-cas-的问题) - \5. ThreadLocal - [5.1. ThreadLocal 的应用](https://dunwu.github.io/javacore/concurrent/Java并发核心机制.html#51-threadlocal-的应用) - [5.2. ThreadLocal 的原理](https://dunwu.github.io/javacore/concurrent/Java并发核心机制.html#52-threadlocal-的原理) - [5.3. ThreadLocal 的误区](https://dunwu.github.io/javacore/concurrent/Java并发核心机制.html#53-threadlocal-的误区) - [5.4. InheritableThreadLocal](https://dunwu.github.io/javacore/concurrent/Java并发核心机制.html#54-inheritablethreadlocal) - [6. 参考资料](https://dunwu.github.io/javacore/concurrent/Java并发核心机制.html#6-参考资料) ## [#](https://dunwu.github.io/javacore/concurrent/Java并发核心机制.html#_1-j-u-c-简介)1. J.U.C 简介 Java 的 `java.util.concurrent` 包(简称 J.U.C)中提供了大量并发工具类,是 Java 并发能力的主要体现(注意,不是全部,有部分并发能力的支持在其他包中)。从功能上,大致可以分为: - 原子类 - 如:`AtomicInteger`、`AtomicIntegerArray`、`AtomicReference`、`AtomicStampedReference` 等。 - 锁 - 如:`ReentrantLock`、`ReentrantReadWriteLock` 等。 - 并发容器 - 如:`ConcurrentHashMap`、`CopyOnWriteArrayList`、`CopyOnWriteArraySet` 等。 - 阻塞队列 - 如:`ArrayBlockingQueue`、`LinkedBlockingQueue` 等。 - 非阻塞队列 - 如: `ConcurrentLinkedQueue` 、`LinkedTransferQueue` 等。 - `Executor` 框架(线程池)- 如:`ThreadPoolExecutor`、`Executors` 等。 我个人理解,Java 并发框架可以分为以下层次。  由 Java 并发框架图不难看出,J.U.C 包中的工具类是基于 `synchronized`、`volatile`、`CAS`、`ThreadLocal` 这样的并发核心机制打造的。所以,要想深入理解 J.U.C 工具类的特性、为什么具有这样那样的特性,就必须先理解这些核心机制。 ## [#](https://dunwu.github.io/javacore/concurrent/Java并发核心机制.html#_2-synchronized)2. synchronized > `synchronized` 是 Java 中的关键字,是 **利用锁的机制来实现互斥同步的**。 > > **`synchronized` 可以保证在同一个时刻,只有一个线程可以执行某个方法或者某个代码块**。 > > 如果不需要 `Lock` 、`ReadWriteLock` 所提供的高级同步特性,应该优先考虑使用 `synchronized` ,理由如下: > > - Java 1.6 以后,`synchronized` 做了大量的优化,其性能已经与 `Lock` 、`ReadWriteLock` 基本上持平。从趋势来看,Java 未来仍将继续优化 `synchronized` ,而不是 `ReentrantLock` 。 > - `ReentrantLock` 是 Oracle JDK 的 API,在其他版本的 JDK 中不一定支持;而 `synchronized` 是 JVM 的内置特性,所有 JDK 版本都提供支持。 ### [#](https://dunwu.github.io/javacore/concurrent/Java并发核心机制.html#_2-1-synchronized-的应用)2.1. synchronized 的应用 `synchronized` 有 3 种应用方式: - **同步实例方法** - 对于普通同步方法,锁是当前实例对象 - **同步静态方法** - 对于静态同步方法,锁是当前类的 `Class` 对象 - **同步代码块** - 对于同步方法块,锁是 `synchonized` 括号里配置的对象 > 说明: > > 类似 `Vector`、`Hashtable` 这类同步类,就是使用 `synchonized` 修饰其重要方法,来保证其线程安全。 > > 事实上,这类同步容器也非绝对的线程安全,当执行迭代器遍历,根据条件删除元素这种场景下,就可能出现线程不安全的情况。此外,Java 1.6 针对 `synchonized` 进行优化前,由于阻塞,其性能不高。 > > 综上,这类同步容器,在现代 Java 程序中,已经渐渐不用了。 #### [#](https://dunwu.github.io/javacore/concurrent/Java并发核心机制.html#同步实例方法)同步实例方法 ❌ 错误示例 - 未同步的示例 ```java public class NoSynchronizedDemo implements Runnable { public static final int MAX = 100000; private static int count = 0; public static void main(String[] args) throws InterruptedException { NoSynchronizedDemo instance = new NoSynchronizedDemo(); Thread t1 = new Thread(instance); Thread t2 = new Thread(instance); t1.start(); t2.start(); t1.join(); t2.join(); System.out.println(count); } @Override public void run() { for (int i = 0; i < MAX; i++) { increase(); } } public void increase() { count++; } } // 输出结果: 小于 200000 的随机数字
Java 实例方法同步是同步在拥有该方法的对象上。这样,每个实例其方法同步都同步在不同的对象上,即该方法所属的实例。只有一个线程能够在实例方法同步块中运行。如果有多个实例存在,那么一个线程一次可以在一个实例同步块中执行操作。一个实例一个线程。
public class SynchronizedDemo implements Runnable {
private static final int MAX = 100000;
private static int count = 0;
public static void main(String[] args) throws InterruptedException {
SynchronizedDemo instance = new SynchronizedDemo();
Thread t1 = new Thread(instance);
Thread t2 = new Thread(instance);
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(count);
}
@Override
public void run() {
for (int i = 0; i < MAX; i++) {
increase();
}
}
/**
* synchronized 修饰普通方法
*/
public synchronized void increase() {
count++;
}
}【示例】错误示例
class Account {
private int balance;
// 转账
synchronized void transfer(
Account target, int amt){
if (this.balance > amt) {
this.balance -= amt;
target.balance += amt;
}
}
}在这段代码中,临界区内有两个资源,分别是转出账户的余额 this.balance 和转入账户的余额 target.balance,并且用的是一把锁 this,符合我们前面提到的,多个资源可以用一把锁来保护,这看上去完全正确呀。真的是这样吗?可惜,这个方案仅仅是看似正确,为什么呢?
问题就出在 this 这把锁上,this 这把锁可以保护自己的余额 this.balance,却保护不了别人的余额 target.balance,就像你不能用自家的锁来保护别人家的资产,也不能用自己的票来保护别人的座位一样。
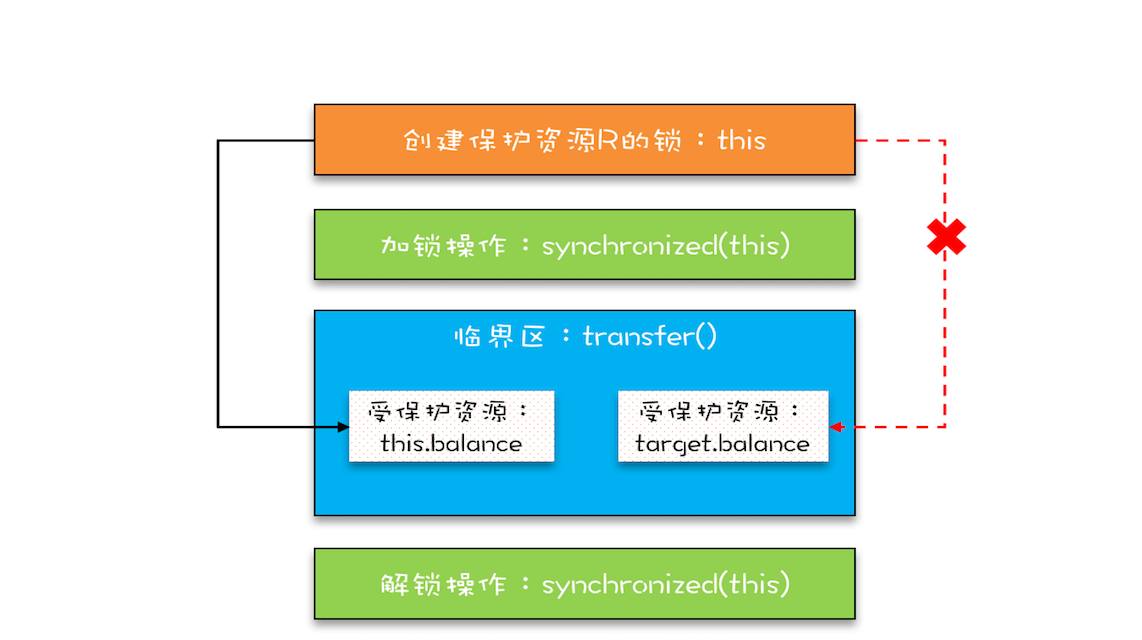
应该保证使用的锁能覆盖所有受保护资源。
【示例】正确姿势
class Account {
private Object lock;
private int balance;
private Account();
// 创建 Account 时传入同一个 lock 对象
public Account(Object lock) {
this.lock = lock;
}
// 转账
void transfer(Account target, int amt){
// 此处检查所有对象共享的锁
synchronized(lock) {
if (this.balance > amt) {
this.balance -= amt;
target.balance += amt;
}
}
}
}这个办法确实能解决问题,但是有点小瑕疵,它要求在创建 Account 对象的时候必须传入同一个对象,如果创建 Account 对象时,传入的 lock 不是同一个对象,那可就惨了,会出现锁自家门来保护他家资产的荒唐事。在真实的项目场景中,创建 Account 对象的代码很可能分散在多个工程中,传入共享的 lock 真的很难。
上面的方案缺乏实践的可行性,我们需要更好的方案。还真有,就是用 Account.class 作为共享的锁。Account.class 是所有 Account 对象共享的,而且这个对象是 Java 虚拟机在加载 Account 类的时候创建的,所以我们不用担心它的唯一性。使用 Account.class 作为共享的锁,我们就无需在创建 Account 对象时传入了,代码更简单。
【示例】正确姿势
class Account {
private int balance;
// 转账
void transfer(Account target, int amt){
synchronized(Account.class) {
if (this.balance > amt) {
this.balance -= amt;
target.balance += amt;
}
}
}
}# #同步静态方法
静态方法的同步是指同步在该方法所在的类对象上。因为在 JVM 中一个类只能对应一个类对象,所以同时只允许一个线程执行同一个类中的静态同步方法。
对于不同类中的静态同步方法,一个线程可以执行每个类中的静态同步方法而无需等待。不管类中的哪个静态同步方法被调用,一个类只能由一个线程同时执行。
public class SynchronizedDemo2 implements Runnable {
private static final int MAX = 100000;
private static int count = 0;
public static void main(String[] args) throws InterruptedException {
SynchronizedDemo2 instance = new SynchronizedDemo2();
Thread t1 = new Thread(instance);
Thread t2 = new Thread(instance);
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(count);
}
@Override
public void run() {
for (int i = 0; i < MAX; i++) {
increase();
}
}
/**
* synchronized 修饰静态方法
*/
public synchronized static void increase() {
count++;
}
}# #同步代码块
有时你不需要同步整个方法,而是同步方法中的一部分。Java 可以对方法的一部分进行同步。
@ThreadSafe
public class SynchronizedDemo05 implements Runnable {
private static final int MAX = 100000;
private static int count = 0;
public static void main(String[] args) throws InterruptedException {
SynchronizedDemo05 instance = new SynchronizedDemo05();
Thread t1 = new Thread(instance);
Thread t2 = new Thread(instance);
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(count);
}
@Override
public void run() {
for (int i = 0; i < MAX; i++) {
increase();
}
}
/**
* synchronized 修饰代码块
*/
public void increase() {
synchronized (this) {
count++;
}
}
}注意 Java 同步块构造器用括号将对象括起来。在上例中,使用了 this ,即为调用 increase 方法的实例本身。用括号括起来的对象叫做监视器对象。一次只有一个线程能够在同步于同一个监视器对象的 Java 方法内执行。
如果是静态方法,就不能用 this 对象作为监视器对象了,而是使用 Class 对象,如下:
public class SynchronizedDemo3 implements Runnable {
private static final int MAX = 100000;
private static int count = 0;
public static void main(String[] args) throws InterruptedException {
SynchronizedDemo3 instance = new SynchronizedDemo3();
Thread t1 = new Thread(instance);
Thread t2 = new Thread(instance);
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(count);
}
@Override
public void run() {
for (int i = 0; i < MAX; i++) {
increase();
}
}
/**
* synchronized 修饰代码块
*/
public static void increase() {
synchronized (SynchronizedDemo3.class) {
count++;
}
}
}# #2.2. synchronized 的原理
synchronized 代码块是由一对 monitorenter 和 monitorexit 指令实现的, Monitor 对象是同步的基本实现单元。在 Java 6 之前, Monitor 的实现完全是依靠操作系统内部的互斥锁,因为需要进行用户态到内核态的切换,所以同步操作是一个无差别的重量级操作。
如果 synchronized 明确制定了对象参数,那就是这个对象的引用;如果没有明确指定,那就根据 synchronized 修饰的是实例方法还是静态方法,去对对应的对象实例或 Class 对象来作为锁对象。
synchronized 同步块对同一线程来说是可重入的,不会出现锁死问题。
synchronized 同步块是互斥的,即已进入的线程执行完成前,会阻塞其他试图进入的线程。
【示例】
public void foo(Object lock) {
synchronized (lock) {
lock.hashCode();
}
}
// 上面的 Java 代码将编译为下面的字节码
public void foo(java.lang.Object);
Code:
0: aload_1
1: dup
2: astore_2
3: monitorenter
4: aload_1
5: invokevirtual java/lang/Object.hashCode:()I
8: pop
9: aload_2
10: monitorexit
11: goto 19
14: astore_3
15: aload_2
16: monitorexit
17: aload_3
18: athrow
19: return
Exception table:
from to target type
4 11 14 any
14 17 14 any# #同步代码块
synchronized 在修饰同步代码块时,是由 monitorenter 和 monitorexit 指令来实现同步的。进入 monitorenter 指令后,线程将持有 Monitor 对象,退出 monitorenter 指令后,线程将释放该 Monitor 对象。
# #同步方法
synchronized 修饰同步方法时,会设置一个 ACC_SYNCHRONIZED 标志。当方法调用时,调用指令将会检查该方法是否被设置 ACC_SYNCHRONIZED 访问标志。如果设置了该标志,执行线程将先持有 Monitor 对象,然后再执行方法。在该方法运行期间,其它线程将无法获取到该 Mointor 对象,当方法执行完成后,再释放该 Monitor 对象。
# #Monitor
每个对象实例都会有一个 Monitor , Monitor 可以和对象一起创建、销毁。 Monitor 是由 ObjectMonitor 实现,而 ObjectMonitor 是由 C++ 的 ObjectMonitor.hpp 文件实现。
当多个线程同时访问一段同步代码时,多个线程会先被存放在 EntryList 集合中,处于 block 状态的线程,都会被加入到该列表。接下来当线程获取到对象的 Monitor 时,Monitor 是依靠底层操作系统的 Mutex Lock 来实现互斥的,线程申请 Mutex 成功,则持有该 Mutex,其它线程将无法获取到该 Mutex。
如果线程调用 wait () 方法,就会释放当前持有的 Mutex,并且该线程会进入 WaitSet 集合中,等待下一次被唤醒。如果当前线程顺利执行完方法,也将释放 Mutex。
# #2.3. synchronized 的优化
Java 1.6 以后,
synchronized做了大量的优化,其性能已经与Lock、ReadWriteLock基本上持平。
# #Java 对象头
在 JDK1.6 JVM 中,对象实例在堆内存中被分为了三个部分:对象头、实例数据和对齐填充。其中 Java 对象头由 Mark Word、指向类的指针以及数组长度三部分组成。
Mark Word 记录了对象和锁有关的信息。Mark Word 在 64 位 JVM 中的长度是 64bit,我们可以一起看下 64 位 JVM 的存储结构是怎么样的。如下图所示:
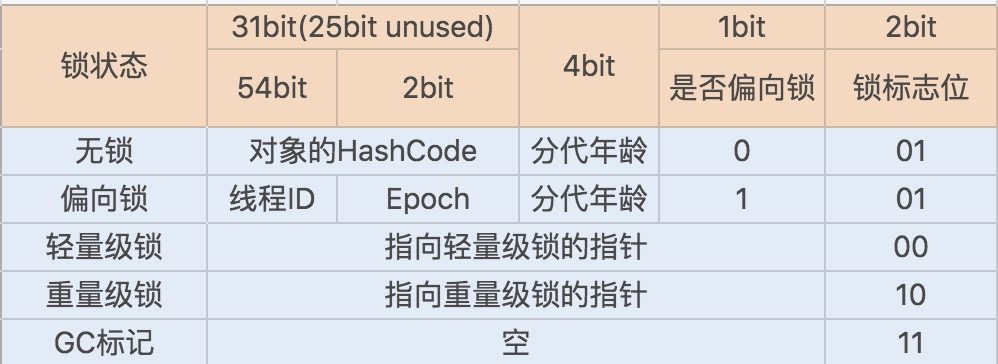
锁升级功能主要依赖于 Mark Word 中的锁标志位和是否偏向锁标志位, synchronized 同步锁就是从偏向锁开始的,随着竞争越来越激烈,偏向锁升级到轻量级锁,最终升级到重量级锁。
Java 1.6 引入了偏向锁和轻量级锁,从而让 synchronized 拥有了四个状态:
- 无锁状态(unlocked)
- 偏向锁状态(biasble)
- 轻量级锁状态(lightweight locked)
- 重量级锁状态(inflated)
当 JVM 检测到不同的竞争状况时,会自动切换到适合的锁实现。
当没有竞争出现时,默认会使用偏向锁。JVM 会利用 CAS 操作(compare and swap),在对象头上的 Mark Word 部分设置线程 ID,以表示这个对象偏向于当前线程,所以并不涉及真正的互斥锁。这样做的假设是基于在很多应用场景中,大部分对象生命周期中最多会被一个线程锁定,使用偏斜锁可以降低无竞争开销。
如果有另外的线程试图锁定某个已经被偏斜过的对象,JVM 就需要撤销(revoke)偏向锁,并切换到轻量级锁实现。轻量级锁依赖 CAS 操作 Mark Word 来试图获取锁,如果重试成功,就使用普通的轻量级锁;否则,进一步升级为重量级锁。
# #偏向锁
偏向锁的思想是偏向于第一个获取锁对象的线程,这个线程在之后获取该锁就不再需要进行同步操作,甚至连 CAS 操作也不再需要。
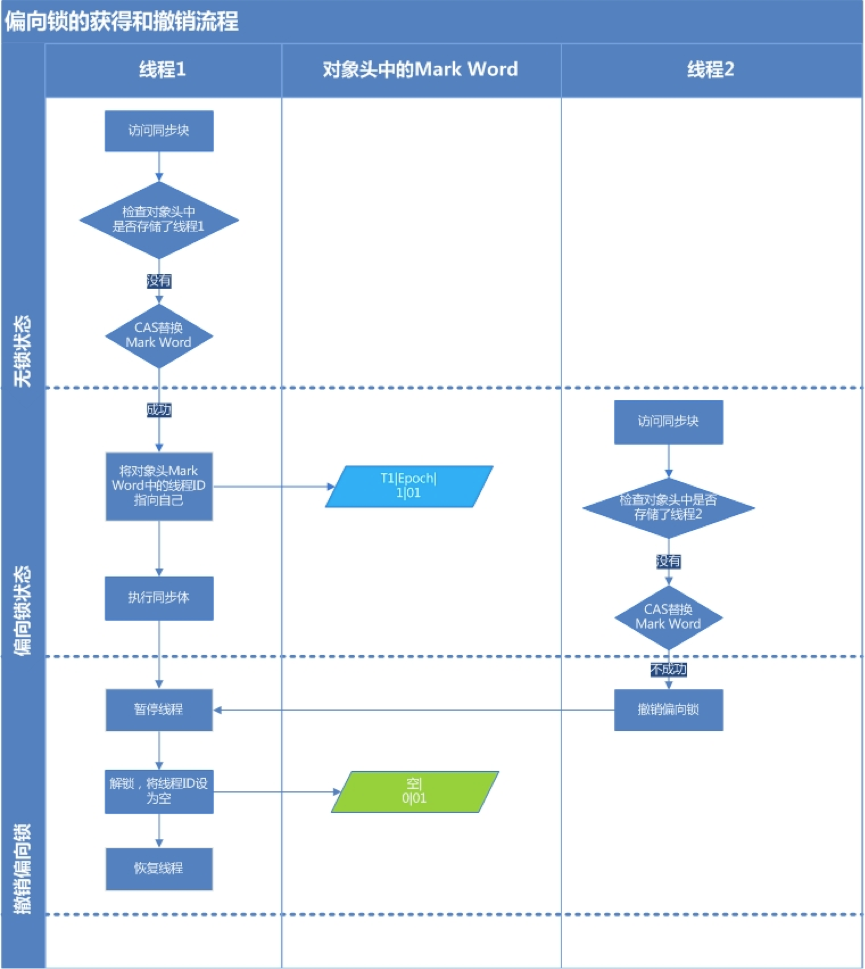
# #轻量级锁
轻量级锁是相对于传统的重量级锁而言,它 使用 CAS 操作来避免重量级锁使用互斥量的开销。对于绝大部分的锁,在整个同步周期内都是不存在竞争的,因此也就不需要都使用互斥量进行同步,可以先采用 CAS 操作进行同步,如果 CAS 失败了再改用互斥量进行同步。
当尝试获取一个锁对象时,如果锁对象标记为 0|01 ,说明锁对象的锁未锁定(unlocked)状态。此时虚拟机在当前线程的虚拟机栈中创建 Lock Record,然后使用 CAS 操作将对象的 Mark Word 更新为 Lock Record 指针。如果 CAS 操作成功了,那么线程就获取了该对象上的锁,并且对象的 Mark Word 的锁标记变为 00,表示该对象处于轻量级锁状态。
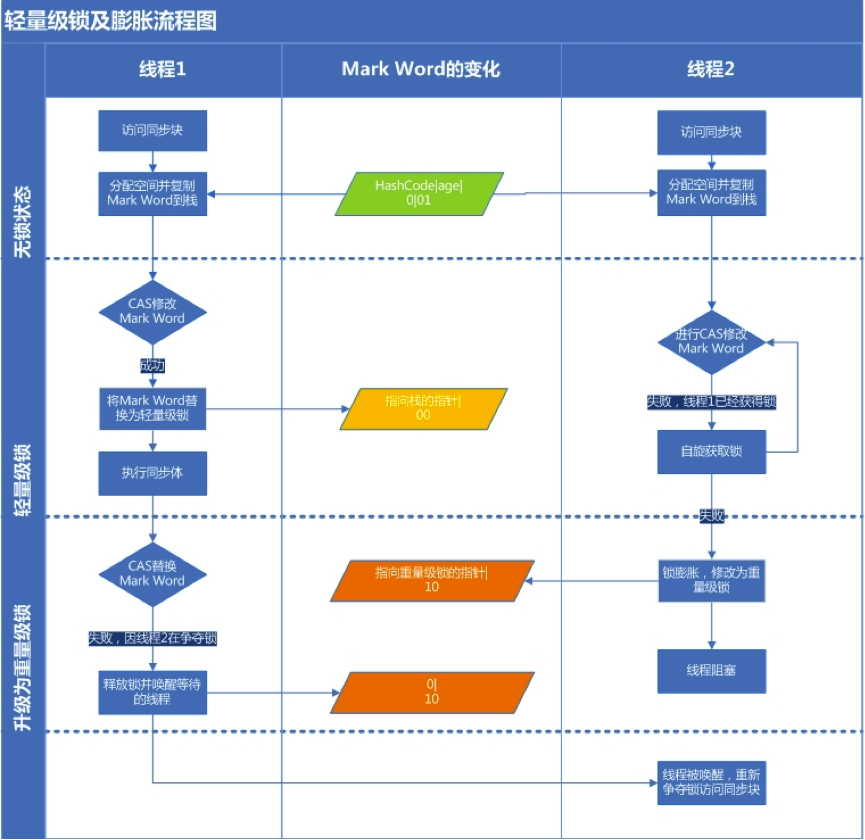
# #锁消除 / 锁粗化
除了锁升级优化,Java 还使用了编译器对锁进行优化。
(1)锁消除
锁消除是指对于被检测出不可能存在竞争的共享数据的锁进行消除。
JIT 编译器在动态编译同步块的时候,借助了一种被称为逃逸分析的技术,来判断同步块使用的锁对象是否只能够被一个线程访问,而没有被发布到其它线程。
确认是的话,那么 JIT 编译器在编译这个同步块的时候不会生成 synchronized 所表示的锁的申请与释放的机器码,即消除了锁的使用。在 Java7 之后的版本就不需要手动配置了,该操作可以自动实现。
对于一些看起来没有加锁的代码,其实隐式的加了很多锁。例如下面的字符串拼接代码就隐式加了锁:
public static String concatString(String s1, String s2, String s3) {
return s1 + s2 + s3;
}String 是一个不可变的类,编译器会对 String 的拼接自动优化。在 Java 1.5 之前,会转化为 StringBuffer 对象的连续 append() 操作:
public static String concatString(String s1, String s2, String s3) {
StringBuffer sb = new StringBuffer();
sb.append(s1);
sb.append(s2);
sb.append(s3);
return sb.toString();
}每个 append() 方法中都有一个同步块。虚拟机观察变量 sb,很快就会发现它的动态作用域被限制在 concatString() 方法内部。也就是说,sb 的所有引用永远不会逃逸到 concatString() 方法之外,其他线程无法访问到它,因此可以进行消除。
(2)锁粗化
锁粗化同理,就是在 JIT 编译器动态编译时,如果发现几个相邻的同步块使用的是同一个锁实例,那么 JIT 编译器将会把这几个同步块合并为一个大的同步块,从而避免一个线程 “反复申请、释放同一个锁 “所带来的性能开销。
如果一系列的连续操作都对同一个对象反复加锁和解锁,频繁的加锁操作就会导致性能损耗。
上一节的示例代码中连续的 append() 方法就属于这类情况。如果虚拟机探测到由这样的一串零碎的操作都对同一个对象加锁,将会把加锁的范围扩展(粗化)到整个操作序列的外部。对于上一节的示例代码就是扩展到第一个 append() 操作之前直至最后一个 append() 操作之后,这样只需要加锁一次就可以了。
# #自旋锁
互斥同步进入阻塞状态的开销都很大,应该尽量避免。在许多应用中,共享数据的锁定状态只会持续很短的一段时间。自旋锁的思想是让一个线程在请求一个共享数据的锁时执行忙循环(自旋)一段时间,如果在这段时间内能获得锁,就可以避免进入阻塞状态。
自旋锁虽然能避免进入阻塞状态从而减少开销,但是它需要进行忙循环操作占用 CPU 时间,它只适用于共享数据的锁定状态很短的场景。
在 Java 1.6 中引入了自适应的自旋锁。自适应意味着自旋的次数不再固定了,而是由前一次在同一个锁上的自旋次数及锁的拥有者的状态来决定。
# #2.4. synchronized 的误区
# #synchronized 使用范围不当导致的错误
public class Interesting {
volatile int a = 1;
volatile int b = 1;
public static void main(String[] args) {
Interesting interesting = new Interesting();
new Thread(() -> interesting.add()).start();
new Thread(() -> interesting.compare()).start();
}
public synchronized void add() {
log.info("add start");
for (int i = 0; i < 10000; i++) {
a++;
b++;
}
log.info("add done");
}
public void compare() {
log.info("compare start");
for (int i = 0; i < 10000; i++) {
//a始终等于b吗?
if (a < b) {
log.info("a:{},b:{},{}", a, b, a > b);
//最后的a>b应该始终是false吗?
}
}
log.info("compare done");
}
}【输出】
16:05:25.541 [Thread-0] INFO io.github.dunwu.javacore.concurrent.sync.synchronized使用范围不当 - add start
16:05:25.544 [Thread-0] INFO io.github.dunwu.javacore.concurrent.sync.synchronized使用范围不当 - add done
16:05:25.544 [Thread-1] INFO io.github.dunwu.javacore.concurrent.sync.synchronized使用范围不当 - compare start
16:05:25.544 [Thread-1] INFO io.github.dunwu.javacore.concurrent.sync.synchronized使用范围不当 - compare done之所以出现这种错乱,是因为两个线程是交错执行 add 和 compare 方法中的业务逻辑,而且这些业务逻辑不是原子性的:a++ 和 b++ 操作中可以穿插在 compare 方法的比较代码中;更需要注意的是,a<b 这种比较操作在字节码层面是加载 a、加载 b 和比较三步,代码虽然是一行但也不是原子性的。
所以,正确的做法应该是,为 add 和 compare 都加上方法锁,确保 add 方法执行时,compare 无法读取 a 和 b:
public synchronized void add()
public synchronized void compare()所以,使用锁解决问题之前一定要理清楚,我们要保护的是什么逻辑,多线程执行的情况又是怎样的。
# #synchronized 保护对象不对导致的错误
加锁前要清楚锁和被保护的对象是不是一个层面的。
静态字段属于类,类级别的锁才能保护;而非静态字段属于类实例,实例级别的锁就可以保护。
public class synchronized错误使用示例2 {
public static void main(String[] args) {
synchronized错误使用示例2 demo = new synchronized错误使用示例2();
System.out.println(demo.wrong(1000000));
System.out.println(demo.right(1000000));
}
public int wrong(int count) {
Data.reset();
IntStream.rangeClosed(1, count).parallel().forEach(i -> new Data().wrong());
return Data.getCounter();
}
public int right(int count) {
Data.reset();
IntStream.rangeClosed(1, count).parallel().forEach(i -> new Data().right());
return Data.getCounter();
}
private static class Data {
@Getter
private static int counter = 0;
private static Object locker = new Object();
public static int reset() {
counter = 0;
return counter;
}
public synchronized void wrong() {
counter++;
}
public void right() {
synchronized (locker) {
counter++;
}
}
}
}wrong 方法中试图对一个静态对象加对象级别的 synchronized 锁,并不能保证线程安全。
# #锁粒度导致的问题
要尽可能的缩小加锁的范围,这可以提高并发吞吐。
如果精细化考虑了锁应用范围后,性能还无法满足需求的话,我们就要考虑另一个维度的粒度问题了,即:区分读写场景以及资源的访问冲突,考虑使用悲观方式的锁还是乐观方式的锁。
public class synchronized锁粒度不当 {
public static void main(String[] args) {
Demo demo = new Demo();
demo.wrong();
demo.right();
}
private static class Demo {
private List<Integer> data = new ArrayList<>();
private void slow() {
try {
TimeUnit.MILLISECONDS.sleep(10);
} catch (InterruptedException e) {
}
}
public int wrong() {
long begin = System.currentTimeMillis();
IntStream.rangeClosed(1, 1000).parallel().forEach(i -> {
synchronized (this) {
slow();
data.add(i);
}
});
log.info("took:{}", System.currentTimeMillis() - begin);
return data.size();
}
public int right() {
long begin = System.currentTimeMillis();
IntStream.rangeClosed(1, 1000).parallel().forEach(i -> {
slow();
synchronized (data) {
data.add(i);
}
});
log.info("took:{}", System.currentTimeMillis() - begin);
return data.size();
}
}
}# #3. volatile
# #3.1. volatile 的要点
volatile 是轻量级的 synchronized ,它在多处理器开发中保证了共享变量的 “可见性”。
被 volatile 修饰的变量,具备以下特性:
- 线程可见性 - 保证了不同线程对这个变量进行操作时的可见性,即一个线程修改了某个共享变量,另外一个线程能读到这个修改的值。
- 禁止指令重排序
- 不保证原子性
我们知道,线程安全需要具备:可见性、原子性、顺序性。 volatile 不保证原子性,所以决定了它不能彻底地保证线程安全。
# #3.2. volatile 的应用
如果 volatile 变量修饰符使用恰当的话,它比 synchronized 的使用和执行成本更低,因为它不会引起线程上下文的切换和调度。但是, volatile 无法替代 synchronized ,因为 volatile 无法保证操作的原子性。
通常来说,使用 volatile 必须具备以下 2 个条件:
- 对变量的写操作不依赖于当前值
- 该变量没有包含在具有其他变量的表达式中
【示例】状态标记量
volatile boolean flag = false;
while(!flag) {
doSomething();
}
public void setFlag() {
flag = true;
}【示例】双重锁实现线程安全的单例模式
class Singleton {
private volatile static Singleton instance = null;
private Singleton() {}
public static Singleton getInstance() {
if(instance==null) {
synchronized (Singleton.class) {
if(instance==null)
instance = new Singleton();
}
}
return instance;
}
}# #3.3. volatile 的原理
观察加入 volatile 关键字和没有加入 volatile 关键字时所生成的汇编代码发现,加入 volatile 关键字时,会多出一个 lock 前缀指令。 lock 前缀指令实际上相当于一个内存屏障(也成内存栅栏),内存屏障会提供 3 个功能:
- 它确保指令重排序时不会把其后面的指令排到内存屏障之前的位置,也不会把前面的指令排到内存屏障的后面;即在执行到内存屏障这句指令时,在它前面的操作已经全部完成;
- 它会强制将对缓存的修改操作立即写入主存;
- 如果是写操作,它会导致其他 CPU 中对应的缓存行无效。
# #3.4. volatile 的问题
volatile 的要点中,已经提到, volatile 不保证原子性,所以 volatile 并不能保证线程安全。
那么,如何做到线程安全呢?有两种方案:
volatile+synchronized- 可以参考:【示例】双重锁实现线程安全的单例模式- 使用原子类替代
volatile
# #4. CAS
# #4.1. CAS 的要点
互斥同步是最常见的并发正确性保障手段。
互斥同步最主要的问题是线程阻塞和唤醒所带来的性能问题,因此互斥同步也被称为阻塞同步。互斥同步属于一种悲观的并发策略,总是认为只要不去做正确的同步措施,那就肯定会出现问题。无论共享数据是否真的会出现竞争,它都要进行加锁(这里讨论的是概念模型,实际上虚拟机会优化掉很大一部分不必要的加锁)、用户态核心态转换、维护锁计数器和检查是否有被阻塞的线程需要唤醒等操作。
随着硬件指令集的发展,我们可以使用基于冲突检测的乐观并发策略:先进行操作,如果没有其它线程争用共享数据,那操作就成功了,否则采取补偿措施(不断地重试,直到成功为止)。这种乐观的并发策略的许多实现都不需要将线程阻塞,因此这种同步操作称为非阻塞同步。
为什么说乐观锁需要 硬件指令集的发展 才能进行?因为需要操作和冲突检测这两个步骤具备原子性。而这点是由硬件来完成,如果再使用互斥同步来保证就失去意义了。硬件支持的原子性操作最典型的是:CAS。
CAS(Compare and Swap),字面意思为比较并交换。CAS 有 3 个操作数,分别是:内存值 M,期望值 E,更新值 U。当且仅当内存值 M 和期望值 E 相等时,将内存值 M 修改为 U,否则什么都不做。
# #4.2. CAS 的应用
CAS 只适用于线程冲突较少的情况。
CAS 的典型应用场景是:
- 原子类
- 自旋锁
# #原子类
原子类是 CAS 在 Java 中最典型的应用。
我们先来看一个常见的代码片段。
if(a==b) {
a++;
}如果 a++ 执行前, a 的值被修改了怎么办?还能得到预期值吗?出现该问题的原因是在并发环境下,以上代码片段不是原子操作,随时可能被其他线程所篡改。
解决这种问题的最经典方式是应用原子类的 incrementAndGet 方法。
public class AtomicIntegerDemo {
public static void main(String[] args) throws InterruptedException {
ExecutorService executorService = Executors.newFixedThreadPool(3);
final AtomicInteger count = new AtomicInteger(0);
for (int i = 0; i < 10; i++) {
executorService.execute(new Runnable() {
@Override
public void run() {
count.incrementAndGet();
}
});
}
executorService.shutdown();
executorService.awaitTermination(3, TimeUnit.SECONDS);
System.out.println("Final Count is : " + count.get());
}
}J.U.C 包中提供了 AtomicBoolean 、 AtomicInteger 、 AtomicLong 分别针对 Boolean 、 Integer 、 Long 执行原子操作,操作和上面的示例大体相似,不做赘述。
# #自旋锁
利用原子类(本质上是 CAS),可以实现自旋锁。
所谓自旋锁,是指线程反复检查锁变量是否可用,直到成功为止。由于线程在这一过程中保持执行,因此是一种忙等待。一旦获取了自旋锁,线程会一直保持该锁,直至显式释放自旋锁。
示例:非线程安全示例
public class AtomicReferenceDemo {
private static int ticket = 10;
public static void main(String[] args) {
ExecutorService executorService = Executors.newFixedThreadPool(3);
for (int i = 0; i < 5; i++) {
executorService.execute(new MyThread());
}
executorService.shutdown();
}
static class MyThread implements Runnable {
@Override
public void run() {
while (ticket > 0) {
System.out.println(Thread.currentThread().getName() + " 卖出了第 " + ticket + " 张票");
ticket--;
}
}
}
}输出结果:
pool-1-thread-2 卖出了第 10 张票
pool-1-thread-1 卖出了第 10 张票
pool-1-thread-3 卖出了第 10 张票
pool-1-thread-1 卖出了第 8 张票
pool-1-thread-2 卖出了第 9 张票
pool-1-thread-1 卖出了第 6 张票
pool-1-thread-3 卖出了第 7 张票
pool-1-thread-1 卖出了第 4 张票
pool-1-thread-2 卖出了第 5 张票
pool-1-thread-1 卖出了第 2 张票
pool-1-thread-3 卖出了第 3 张票
pool-1-thread-2 卖出了第 1 张票很明显,出现了重复售票的情况。
【示例】使用自旋锁来保证线程安全
可以通过自旋锁这种非阻塞同步来保证线程安全,下面使用 AtomicReference 来实现一个自旋锁。
public class AtomicReferenceDemo2 {
private static int ticket = 10;
public static void main(String[] args) {
threadSafeDemo();
}
private static void threadSafeDemo() {
SpinLock lock = new SpinLock();
ExecutorService executorService = Executors.newFixedThreadPool(3);
for (int i = 0; i < 5; i++) {
executorService.execute(new MyThread(lock));
}
executorService.shutdown();
}
static class SpinLock {
private AtomicReference<Thread> atomicReference = new AtomicReference<>();
public void lock() {
Thread current = Thread.currentThread();
while (!atomicReference.compareAndSet(null, current)) {}
}
public void unlock() {
Thread current = Thread.currentThread();
atomicReference.compareAndSet(current, null);
}
}
static class MyThread implements Runnable {
private SpinLock lock;
public MyThread(SpinLock lock) {
this.lock = lock;
}
@Override
public void run() {
while (ticket > 0) {
lock.lock();
if (ticket > 0) {
System.out.println(Thread.currentThread().getName() + " 卖出了第 " + ticket + " 张票");
ticket--;
}
lock.unlock();
}
}
}
}输出结果:
pool-1-thread-2 卖出了第 10 张票
pool-1-thread-1 卖出了第 9 张票
pool-1-thread-3 卖出了第 8 张票
pool-1-thread-2 卖出了第 7 张票
pool-1-thread-3 卖出了第 6 张票
pool-1-thread-1 卖出了第 5 张票
pool-1-thread-2 卖出了第 4 张票
pool-1-thread-1 卖出了第 3 张票
pool-1-thread-3 卖出了第 2 张票
pool-1-thread-1 卖出了第 1 张票# #4.3. CAS 的原理
Java 主要利用 Unsafe 这个类提供的 CAS 操作。 Unsafe 的 CAS 依赖的是 JVM 针对不同的操作系统实现的硬件指令 Atomic::cmpxchg 。 Atomic::cmpxchg 的实现使用了汇编的 CAS 操作,并使用 CPU 提供的 lock 信号保证其原子性。
# #4.4. CAS 的问题
一般情况下,CAS 比锁性能更高。因为 CAS 是一种非阻塞算法,所以其避免了线程阻塞和唤醒的等待时间。
但是,事物总会有利有弊,CAS 也存在三大问题:
- ABA 问题
- 循环时间长开销大
- 只能保证一个共享变量的原子性
# #ABA 问题
如果一个变量初次读取的时候是 A 值,它的值被改成了 B,后来又被改回为 A,那 CAS 操作就会误认为它从来没有被改变过。
J.U.C 包提供了一个带有标记的原子引用类 AtomicStampedReference 来解决这个问题,它可以通过控制变量值的版本来保证 CAS 的正确性。大部分情况下 ABA 问题不会影响程序并发的正确性,如果需要解决 ABA 问题,改用传统的互斥同步可能会比原子类更高效。
# #循环时间长开销大
自旋 CAS (不断尝试,直到成功为止)如果长时间不成功,会给 CPU 带来非常大的执行开销。
如果 JVM 能支持处理器提供的 pause 指令那么效率会有一定的提升, pause 指令有两个作用:
- 它可以延迟流水线执行指令(de-pipeline), 使 CPU 不会消耗过多的执行资源,延迟的时间取决于具体实现的版本,在一些处理器上延迟时间是零。
- 它可以避免在退出循环的时候因内存顺序冲突(memory order violation)而引起 CPU 流水线被清空(CPU pipeline flush),从而提高 CPU 的执行效率。
比较花费 CPU 资源,即使没有任何用也会做一些无用功。
# #只能保证一个共享变量的原子性
当对一个共享变量执行操作时,我们可以使用循环 CAS 的方式来保证原子操作,但是对多个共享变量操作时,循环 CAS 就无法保证操作的原子性,这个时候就可以用锁。
或者有一个取巧的办法,就是把多个共享变量合并成一个共享变量来操作。比如有两个共享变量 i = 2, j = a ,合并一下 ij=2a ,然后用 CAS 来操作 ij 。从 Java 1.5 开始 JDK 提供了 AtomicReference 类来保证引用对象之间的原子性,你可以把多个变量放在一个对象里来进行 CAS 操作。
# #5. ThreadLocal
ThreadLocal是一个存储线程本地副本的工具类。要保证线程安全,不一定非要进行同步。同步只是保证共享数据争用时的正确性,如果一个方法本来就不涉及共享数据,那么自然无须同步。
Java 中的 无同步方案 有:
- 可重入代码 - 也叫纯代码。如果一个方法,它的 返回结果是可以预测的,即只要输入了相同的数据,就能返回相同的结果,那它就满足可重入性,当然也是线程安全的。
- 线程本地存储 - 使用
ThreadLocal为共享变量在每个线程中都创建了一个本地副本,这个副本只能被当前线程访问,其他线程无法访问,那么自然是线程安全的。
# #5.1. ThreadLocal 的应用
ThreadLocal 的方法:
public class ThreadLocal<T> {
public T get() {}
public void set(T value) {}
public void remove() {}
public static <S> ThreadLocal<S> withInitial(Supplier<? extends S> supplier) {}
}说明:
get- 用于获取ThreadLocal在当前线程中保存的变量副本。set- 用于设置当前线程中变量的副本。remove- 用于删除当前线程中变量的副本。如果此线程局部变量随后被当前线程读取,则其值将通过调用其initialValue方法重新初始化,除非其值由中间线程中的当前线程设置。 这可能会导致当前线程中多次调用initialValue方法。initialValue- 为 ThreadLocal 设置默认的get初始值,需要重写initialValue方法 。
ThreadLocal 常用于防止对可变的单例(Singleton)变量或全局变量进行共享。典型应用场景有:管理数据库连接、Session。
【示例】数据库连接
private static ThreadLocal<Connection> connectionHolder = new ThreadLocal<Connection>() {
@Override
public Connection initialValue() {
return DriverManager.getConnection(DB_URL);
}
};
public static Connection getConnection() {
return connectionHolder.get();
}【示例】Session 管理
private static final ThreadLocal<Session> sessionHolder = new ThreadLocal<>();
public static Session getSession() {
Session session = (Session) sessionHolder.get();
try {
if (session == null) {
session = createSession();
sessionHolder.set(session);
}
} catch (Exception e) {
e.printStackTrace();
}
return session;
}【示例】完整使用 ThreadLocal 示例
public class ThreadLocalDemo {
private static ThreadLocal<Integer> threadLocal = new ThreadLocal<Integer>() {
@Override
protected Integer initialValue() {
return 0;
}
};
public static void main(String[] args) {
ExecutorService executorService = Executors.newFixedThreadPool(10);
for (int i = 0; i < 10; i++) {
executorService.execute(new MyThread());
}
executorService.shutdown();
}
static class MyThread implements Runnable {
@Override
public void run() {
int count = threadLocal.get();
for (int i = 0; i < 10; i++) {
try {
count++;
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
threadLocal.set(count);
threadLocal.remove();
System.out.println(Thread.currentThread().getName() + " : " + count);
}
}
}全部输出 count = 10
# #5.2. ThreadLocal 的原理
# #存储结构
Thread 类中维护着一个 ThreadLocal.ThreadLocalMap 类型的成员 threadLocals 。这个成员就是用来存储当前线程独占的变量副本。
ThreadLocalMap 是 ThreadLocal 的内部类,它维护着一个 Entry 数组, Entry 继承了 WeakReference ,所以是弱引用。 Entry 用于保存键值对,其中:
key是ThreadLocal对象;value是传递进来的对象(变量副本)。
public class Thread implements Runnable {
// ...
ThreadLocal.ThreadLocalMap threadLocals = null;
// ...
}
static class ThreadLocalMap {
// ...
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
// ...
}# #如何解决 Hash 冲突
ThreadLocalMap 虽然是类似 Map 结构的数据结构,但它并没有实现 Map 接口。它不支持 Map 接口中的 next 方法,这意味着 ThreadLocalMap 中解决 Hash 冲突的方式并非 拉链表 方式。
实际上, ThreadLocalMap 采用线性探测的方式来解决 Hash 冲突。所谓线性探测,就是根据初始 key 的 hashcode 值确定元素在 table 数组中的位置,如果发现这个位置上已经被其他的 key 值占用,则利用固定的算法寻找一定步长的下个位置,依次判断,直至找到能够存放的位置。
# #内存泄漏问题
ThreadLocalMap 的 Entry 继承了 WeakReference ,所以它的 key ( ThreadLocal 对象)是弱引用,而 value (变量副本)是强引用。
- 如果
ThreadLocal对象没有外部强引用来引用它,那么ThreadLocal对象会在下次 GC 时被回收。 - 此时,
Entry中的 key 已经被回收,但是 value 由于是强引用不会被垃圾收集器回收。如果创建ThreadLocal的线程一直持续运行,那么 value 就会一直得不到回收,产生内存泄露。
那么如何避免内存泄漏呢?方法就是:使用 ThreadLocal 的 set 方法后,显示的调用 remove 方法 。
ThreadLocal<String> threadLocal = new ThreadLocal();
try {
threadLocal.set("xxx");
// ...
} finally {
threadLocal.remove();
}# #5.3. ThreadLocal 的误区
ThreadLocal 适用于变量在线程间隔离,而在方法或类间共享的场景。
前文提到,ThreadLocal 是线程隔离的,那么是不是使用 ThreadLocal 就一定高枕无忧呢?
# #ThreadLocal 错误案例
使用 Spring Boot 创建一个 Web 应用程序,使用 ThreadLocal 存放一个 Integer 的值,来暂且代表需要在线程中保存的用户信息,这个值初始是 null。
private ThreadLocal<Integer> currentUser = ThreadLocal.withInitial(() -> null);
@GetMapping("wrong")
public Map<String, String> wrong(@RequestParam("id") Integer userId) {
//设置用户信息之前先查询一次ThreadLocal中的用户信息
String before = Thread.currentThread().getName() + ":" + currentUser.get();
//设置用户信息到ThreadLocal
currentUser.set(userId);
//设置用户信息之后再查询一次ThreadLocal中的用户信息
String after = Thread.currentThread().getName() + ":" + currentUser.get();
//汇总输出两次查询结果
Map<String, String> result = new HashMap<>();
result.put("before", before);
result.put("after", after);
return result;
}【预期】从代码逻辑来看,我们预期第一次获取的值始终应该是 null。
【实际】
为了方便复现,将 Tomcat 工作线程设为 1:
server.tomcat.max-threads=1当访问 id = 1 时,符合预期
当访问 id = 2 时,before 的应答不是 null,而是 1,不符合预期。

【分析】实际情况和预期存在偏差。Spring Boot 程序运行在 Tomcat 中,执行程序的线程是 Tomcat 的工作线程,而 Tomcat 的工作线程是基于线程池的。线程池会重用固定的几个线程,一旦线程重用,那么很可能首次从 ThreadLocal 获取的值是之前其他用户的请求遗留的值。这时,ThreadLocal 中的用户信息就是其他用户的信息。
并不能认为没有显式开启多线程就不会有线程安全问题。使用类似 ThreadLocal 工具来存放一些数据时,需要特别注意在代码运行完后,显式地去清空设置的数据。
# #ThreadLocal 错误案例修正
@GetMapping("right")
public Map<String, String> right(@RequestParam("id") Integer userId) {
String before = Thread.currentThread().getName() + ":" + currentUser.get();
currentUser.set(userId);
try {
String after = Thread.currentThread().getName() + ":" + currentUser.get();
Map<String, String> result = new HashMap<>();
result.put("before", before);
result.put("after", after);
return result;
} finally {
//在finally代码块中删除ThreadLocal中的数据,确保数据不串
currentUser.remove();
}
}# #5.4. InheritableThreadLocal
InheritableThreadLocal 类是 ThreadLocal 类的子类。
ThreadLocal 中每个线程拥有它自己独占的数据。与 ThreadLocal 不同的是, InheritableThreadLocal 允许一个线程以及该线程创建的所有子线程都可以访问它保存的数据。
# 深入理解 Java 并发锁
📦 本文以及示例源码已归档在 javacore(opens new window)
本文先阐述 Java 中各种锁的概念。
然后,介绍锁的核心实现 AQS。
然后,重点介绍 Lock 和 Condition 两个接口及其实现。并发编程有两个核心问题:同步和互斥。
互斥,即同一时刻只允许一个线程访问共享资源;
同步,即线程之间如何通信、协作。
这两大问题,管程(
sychronized)都是能够解决的。J.U.C 包还提供了 Lock 和 Condition 两个接口来实现管程,其中 Lock 用于解决互斥问题,Condition 用于解决同步问题。
- \1. 并发锁简介
- \2. Lock 和 Condition
- \3. ReentrantLock
- \4. ReentrantReadWriteLock
- 5. StampedLock
- \6. AQS
- \7. 死锁
- 8. 参考资料
# #1. 并发锁简介
确保线程安全最常见的做法是利用锁机制( Lock 、 sychronized )来对共享数据做互斥同步,这样在同一个时刻,只有一个线程可以执行某个方法或者某个代码块,那么操作必然是原子性的,线程安全的。
在工作、面试中,经常会听到各种五花八门的锁,听的人云里雾里。锁的概念术语很多,它们是针对不同的问题所提出的,通过简单的梳理,也不难理解。
# #1.1. 可重入锁
可重入锁,顾名思义,指的是线程可以重复获取同一把锁。即同一个线程在外层方法获取了锁,在进入内层方法会自动获取锁。
可重入锁可以在一定程度上避免死锁。
-
ReentrantLock、ReentrantReadWriteLock是可重入锁。这点,从其命名也不难看出。 -
synchronized也是一个可重入锁。
【示例】 synchronized 的可重入示例
synchronized void setA() throws Exception{
Thread.sleep(1000);
setB();
}
synchronized void setB() throws Exception{
Thread.sleep(1000);
}上面的代码就是一个典型场景:如果使用的锁不是可重入锁的话, setB 可能不会被当前线程执行,从而造成死锁。
【示例】 ReentrantLock 的可重入示例
class Task {
private int value;
private final Lock lock = new ReentrantLock();
public Task() {
this.value = 0;
}
public int get() {
// 获取锁
lock.lock();
try {
return value;
} finally {
// 保证锁能释放
lock.unlock();
}
}
public void addOne() {
// 获取锁
lock.lock();
try {
// 注意:此处已经成功获取锁,进入 get 方法后,又尝试获取锁,
// 如果锁不是可重入的,会导致死锁
value = 1 + get();
} finally {
// 保证锁能释放
lock.unlock();
}
}
}# #1.2. 公平锁与非公平锁
- 公平锁 - 公平锁是指 多线程按照申请锁的顺序来获取锁。
- 非公平锁 - 非公平锁是指 多线程不按照申请锁的顺序来获取锁 。这就可能会出现优先级反转(后来者居上)或者饥饿现象(某线程总是抢不过别的线程,导致始终无法执行)。
公平锁为了保证线程申请顺序,势必要付出一定的性能代价,因此其吞吐量一般低于非公平锁。
公平锁与非公平锁 在 Java 中的典型实现:
-
synchronized只支持非公平锁。 -
ReentrantLock、ReentrantReadWriteLock,默认是非公平锁,但支持公平锁。
# #1.3. 独享锁与共享锁
独享锁与共享锁是一种广义上的说法,从实际用途上来看,也常被称为互斥锁与读写锁。
- 独享锁 - 独享锁是指 锁一次只能被一个线程所持有。
- 共享锁 - 共享锁是指 锁可被多个线程所持有。
独享锁与共享锁在 Java 中的典型实现:
-
synchronized、ReentrantLock只支持独享锁。 -
ReentrantReadWriteLock其写锁是独享锁,其读锁是共享锁。读锁是共享锁使得并发读是非常高效的,读写,写读 ,写写的过程是互斥的。
# #1.4. 悲观锁与乐观锁
乐观锁与悲观锁不是指具体的什么类型的锁,而是处理并发同步的策略。
- 悲观锁 - 悲观锁对于并发采取悲观的态度,认为:不加锁的并发操作一定会出问题。悲观锁适合写操作频繁的场景。
- 乐观锁 - 乐观锁对于并发采取乐观的态度,认为:不加锁的并发操作也没什么问题。对于同一个数据的并发操作,是不会发生修改的。在更新数据的时候,会采用不断尝试更新的方式更新数据。乐观锁适合读多写少的场景。
悲观锁与乐观锁在 Java 中的典型实现:
- 悲观锁在 Java 中的应用就是通过使用
synchronized和Lock显示加锁来进行互斥同步,这是一种阻塞同步。 - 乐观锁在 Java 中的应用就是采用
CAS机制(CAS操作通过Unsafe类提供,但这个类不直接暴露为 API,所以都是间接使用,如各种原子类)。
# #1.5. 偏向锁、轻量级锁、重量级锁
所谓轻量级锁与重量级锁,指的是锁控制粒度的粗细。显然,控制粒度越细,阻塞开销越小,并发性也就越高。
Java 1.6 以前,重量级锁一般指的是 synchronized ,而轻量级锁指的是 volatile 。
Java 1.6 以后,针对 synchronized 做了大量优化,引入 4 种锁状态: 无锁状态、偏向锁、轻量级锁和重量级锁。锁可以单向的从偏向锁升级到轻量级锁,再从轻量级锁升级到重量级锁 。
- 偏向锁 - 偏向锁是指一段同步代码一直被一个线程所访问,那么该线程会自动获取锁。降低获取锁的代价。
- 轻量级锁 - 是指当锁是偏向锁的时候,被另一个线程所访问,偏向锁就会升级为轻量级锁,其他线程会通过自旋的形式尝试获取锁,不会阻塞,提高性能。
- 重量级锁 - 是指当锁为轻量级锁的时候,另一个线程虽然是自旋,但自旋不会一直持续下去,当自旋一定次数的时候,还没有获取到锁,就会进入阻塞,该锁膨胀为重量级锁。重量级锁会让其他申请的线程进入阻塞,性能降低。
# #1.6. 分段锁
分段锁其实是一种锁的设计,并不是具体的一种锁。所谓分段锁,就是把锁的对象分成多段,每段独立控制,使得锁粒度更细,减少阻塞开销,从而提高并发性。这其实很好理解,就像高速公路上的收费站,如果只有一个收费口,那所有的车只能排成一条队缴费;如果有多个收费口,就可以分流了。
Hashtable 使用 synchronized 修饰方法来保证线程安全性,那么面对线程的访问,Hashtable 就会锁住整个对象,所有的其它线程只能等待,这种阻塞方式的吞吐量显然很低。
Java 1.7 以前的 ConcurrentHashMap 就是分段锁的典型案例。 ConcurrentHashMap 维护了一个 Segment 数组,一般称为分段桶。
final Segment<K,V>[] segments;当有线程访问 ConcurrentHashMap 的数据时, ConcurrentHashMap 会先根据 hashCode 计算出数据在哪个桶(即哪个 Segment),然后锁住这个 Segment 。
# #1.7. 显示锁和内置锁
Java 1.5 之前,协调对共享对象的访问时可以使用的机制只有 synchronized 和 volatile 。这两个都属于内置锁,即锁的申请和释放都是由 JVM 所控制。
Java 1.5 之后,增加了新的机制: ReentrantLock 、 ReentrantReadWriteLock ,这类锁的申请和释放都可以由程序所控制,所以常被称为显示锁。
💡
synchronized的用法和原理可以参考:Java 并发基础机制 - synchronized (opens new window)。🔔 注意:如果不需要
ReentrantLock、ReentrantReadWriteLock所提供的高级同步特性,应该优先考虑使用synchronized。理由如下:
- Java 1.6 以后,
synchronized做了大量的优化,其性能已经与ReentrantLock、ReentrantReadWriteLock基本上持平。- 从趋势来看,Java 未来更可能会优化
synchronized,而不是ReentrantLock、ReentrantReadWriteLock,因为synchronized是 JVM 内置属性,它能执行一些优化。ReentrantLock、ReentrantReadWriteLock申请和释放锁都是由程序控制,如果使用不当,可能造成死锁,这是很危险的。
以下对比一下显示锁和内置锁的差异:
- 主动获取锁和释放锁
synchronized不能主动获取锁和释放锁。获取锁和释放锁都是 JVM 控制的。ReentrantLock可以主动获取锁和释放锁。(如果忘记释放锁,就可能产生死锁)。
- 响应中断
synchronized不能响应中断。ReentrantLock可以响应中断。
- 超时机制
synchronized没有超时机制。ReentrantLock有超时机制。ReentrantLock可以设置超时时间,超时后自动释放锁,避免一直等待。
- 支持公平锁
synchronized只支持非公平锁。ReentrantLock支持非公平锁和公平锁。
- 是否支持共享
- 被
synchronized修饰的方法或代码块,只能被一个线程访问(独享)。如果这个线程被阻塞,其他线程也只能等待 ReentrantLock可以基于Condition灵活的控制同步条件。
- 被
- 是否支持读写分离
synchronized不支持读写锁分离;ReentrantReadWriteLock支持读写锁,从而使阻塞读写的操作分开,有效提高并发性。
# #2. Lock 和 Condition
# #2.1. 为何引入 Lock 和 Condition
并发编程领域,有两大核心问题:一个是互斥,即同一时刻只允许一个线程访问共享资源;另一个是同步,即线程之间如何通信、协作。这两大问题,管程都是能够解决的。Java SDK 并发包通过 Lock 和 Condition 两个接口来实现管程,其中 Lock 用于解决互斥问题,Condition 用于解决同步问题。
synchronized 是管程的一种实现,既然如此,何必再提供 Lock 和 Condition。
JDK 1.6 以前,synchronized 还没有做优化,性能远低于 Lock。但是,性能不是引入 Lock 的最重要因素。真正关键在于:synchronized 使用不当,可能会出现死锁。
synchronized 无法通过破坏不可抢占条件来避免死锁。原因是 synchronized 申请资源的时候,如果申请不到,线程直接进入阻塞状态了,而线程进入阻塞状态,啥都干不了,也释放不了线程已经占有的资源。
与内置锁 synchronized 不同的是, Lock 提供了一组无条件的、可轮询的、定时的以及可中断的锁操作,所有获取锁、释放锁的操作都是显式的操作。
- 能够响应中断。synchronized 的问题是,持有锁 A 后,如果尝试获取锁 B 失败,那么线程就进入阻塞状态,一旦发生死锁,就没有任何机会来唤醒阻塞的线程。但如果阻塞状态的线程能够响应中断信号,也就是说当我们给阻塞的线程发送中断信号的时候,能够唤醒它,那它就有机会释放曾经持有的锁 A。这样就破坏了不可抢占条件了。
- 支持超时。如果线程在一段时间之内没有获取到锁,不是进入阻塞状态,而是返回一个错误,那这个线程也有机会释放曾经持有的锁。这样也能破坏不可抢占条件。
- 非阻塞地获取锁。如果尝试获取锁失败,并不进入阻塞状态,而是直接返回,那这个线程也有机会释放曾经持有的锁。这样也能破坏不可抢占条件。
# #2.2. Lock 接口
Lock 的接口定义如下:
public interface Lock {
void lock();
void lockInterruptibly() throws InterruptedException;
boolean tryLock();
boolean tryLock(long time, TimeUnit unit) throws InterruptedException;
void unlock();
Condition newCondition();
}lock()- 获取锁。unlock()- 释放锁。tryLock()- 尝试获取锁,仅在调用时锁未被另一个线程持有的情况下,才获取该锁。tryLock(long time, TimeUnit unit)- 和tryLock()类似,区别仅在于限定时间,如果限定时间内未获取到锁,视为失败。lockInterruptibly()- 锁未被另一个线程持有,且线程没有被中断的情况下,才能获取锁。newCondition()- 返回一个绑定到Lock对象上的Condition实例。
# #2.3. Condition
Condition 实现了管程模型里面的条件变量。
前文中提过 Lock 接口中 有一个 newCondition() 方法用于返回一个绑定到 Lock 对象上的 Condition 实例。 Condition 是什么?有什么作用?本节将一一讲解。
在单线程中,一段代码的执行可能依赖于某个状态,如果不满足状态条件,代码就不会被执行(典型的场景,如: if ... else ... )。在并发环境中,当一个线程判断某个状态条件时,其状态可能是由于其他线程的操作而改变,这时就需要有一定的协调机制来确保在同一时刻,数据只能被一个线程锁修改,且修改的数据状态被所有线程所感知。
Java 1.5 之前,主要是利用 Object 类中的 wait 、 notify 、 notifyAll 配合 synchronized 来进行线程间通信(如果不了解其特性,可以参考:Java 线程基础 - wait/notify/notifyAll (opens new window))。
wait 、 notify 、 notifyAll 需要配合 synchronized 使用,不适用于 Lock 。而使用 Lock 的线程,彼此间通信应该使用 Condition 。这可以理解为,什么样的锁配什么样的钥匙。内置锁( synchronized )配合内置条件队列( wait 、 notify 、 notifyAll ),显式锁( Lock )配合显式条件队列( Condition )。
# #Condition 的特性
Condition 接口定义如下:
public interface Condition {
void await() throws InterruptedException;
void awaitUninterruptibly();
long awaitNanos(long nanosTimeout) throws InterruptedException;
boolean await(long time, TimeUnit unit) throws InterruptedException;
boolean awaitUntil(Date deadline) throws InterruptedException;
void signal();
void signalAll();
}其中, await 、 signal 、 signalAll 与 wait 、 notify 、 notifyAll 相对应,功能也相似。除此以外, Condition 相比内置条件队列( wait 、 notify 、 notifyAll ),提供了更为丰富的功能:
- 每个锁(
Lock)上可以存在多个Condition,这意味着锁的状态条件可以有多个。 - 支持公平的或非公平的队列操作。
- 支持可中断的条件等待,相关方法:
awaitUninterruptibly()。 - 支持可定时的等待,相关方法:
awaitNanos(long)、await(long, TimeUnit)、awaitUntil(Date)。
# #Condition 的用法
这里以 Condition 来实现一个消费者、生产者模式。
🔔 注意:事实上,解决此类问题使用
CountDownLatch、Semaphore等工具更为便捷、安全。想了解详情,可以参考 Java 并发工具类 (opens new window)。
产品类
class Message {
private final Lock lock = new ReentrantLock();
private final Condition producedMsg = lock.newCondition();
private final Condition consumedMsg = lock.newCondition();
private String message;
private boolean state;
private boolean end;
public void consume() {
//lock
lock.lock();
try {
// no new message wait for new message
while (!state) { producedMsg.await(); }
System.out.println("consume message : " + message);
state = false;
// message consumed, notify waiting thread
consumedMsg.signal();
} catch (InterruptedException ie) {
System.out.println("Thread interrupted - viewMessage");
} finally {
lock.unlock();
}
}
public void produce(String message) {
lock.lock();
try {
// last message not consumed, wait for it be consumed
while (state) { consumedMsg.await(); }
System.out.println("produce msg: " + message);
this.message = message;
state = true;
// new message added, notify waiting thread
producedMsg.signal();
} catch (InterruptedException ie) {
System.out.println("Thread interrupted - publishMessage");
} finally {
lock.unlock();
}
}
public boolean isEnd() {
return end;
}
public void setEnd(boolean end) {
this.end = end;
}
}消费者
class MessageConsumer implements Runnable {
private Message message;
public MessageConsumer(Message msg) {
message = msg;
}
@Override
public void run() {
while (!message.isEnd()) { message.consume(); }
}
}生产者
class MessageProducer implements Runnable {
private Message message;
public MessageProducer(Message msg) {
message = msg;
}
@Override
public void run() {
produce();
}
public void produce() {
List<String> msgs = new ArrayList<>();
msgs.add("Begin");
msgs.add("Msg1");
msgs.add("Msg2");
for (String msg : msgs) {
message.produce(msg);
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
message.produce("End");
message.setEnd(true);
}
}测试
public class LockConditionDemo {
public static void main(String[] args) {
Message msg = new Message();
Thread producer = new Thread(new MessageProducer(msg));
Thread consumer = new Thread(new MessageConsumer(msg));
producer.start();
consumer.start();
}
}# #3. ReentrantLock
ReentrantLock 类是 Lock 接口的具体实现,与内置锁 synchronized 相同的是,它是一个可重入锁。
# #3.1. ReentrantLock 的特性
ReentrantLock 的特性如下:
-
ReentrantLock提供了与synchronized相同的互斥性、内存可见性和可重入性。 -
ReentrantLock支持公平锁和非公平锁(默认)两种模式。 -
ReentrantLock
Lock 实现了
synchronized 接口,支持了 所不具备的 灵活性 。 - `synchronized` 无法中断一个正在等待获取锁的线程 - `synchronized` 无法在请求获取一个锁时无休止地等待 ### [#](https://dunwu.github.io/javacore/concurrent/Java锁.html#_3-2-reentrantlock-的用法)3.2. ReentrantLock 的用法 前文了解了 `ReentrantLock` 的特性,接下来,我们要讲述其具体用法。 #### [#](https://dunwu.github.io/javacore/concurrent/Java锁.html#reentrantlock-的构造方法)ReentrantLock 的构造方法 `ReentrantLock` 有两个构造方法: ```java public ReentrantLock() {} public ReentrantLock(boolean fair) {} -
ReentrantLock()- 默认构造方法会初始化一个非公平锁(NonfairSync); -
ReentrantLock(boolean)-new ReentrantLock(true)会初始化一个公平锁(FairSync)。
# #lock 和 unlock 方法
lock()- 无条件获取锁。如果当前线程无法获取锁,则当前线程进入休眠状态不可用,直至当前线程获取到锁。如果该锁没有被另一个线程持有,则获取该锁并立即返回,将锁的持有计数设置为 1。unlock()- 用于释放锁。
🔔 注意:请务必牢记,获取锁操作
lock()必须在try catch块中进行,并且将释放锁操作unlock()放在finally块中进行,以保证锁一定被被释放,防止死锁的发生。
示例: ReentrantLock 的基本操作
public class ReentrantLockDemo {
public static void main(String[] args) {
Task task = new Task();
MyThread tA = new MyThread("Thread-A", task);
MyThread tB = new MyThread("Thread-B", task);
MyThread tC = new MyThread("Thread-C", task);
tA.start();
tB.start();
tC.start();
}
static class MyThread extends Thread {
private Task task;
public MyThread(String name, Task task) {
super(name);
this.task = task;
}
@Override
public void run() {
task.execute();
}
}
static class Task {
private ReentrantLock lock = new ReentrantLock();
public void execute() {
lock.lock();
try {
for (int i = 0; i < 3; i++) {
System.out.println(lock.toString());
// 查询当前线程 hold 住此锁的次数
System.out.println("\t holdCount: " + lock.getHoldCount());
// 查询正等待获取此锁的线程数
System.out.println("\t queuedLength: " + lock.getQueueLength());
// 是否为公平锁
System.out.println("\t isFair: " + lock.isFair());
// 是否被锁住
System.out.println("\t isLocked: " + lock.isLocked());
// 是否被当前线程持有锁
System.out.println("\t isHeldByCurrentThread: " + lock.isHeldByCurrentThread());
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
} finally {
lock.unlock();
}
}
}
}输出结果:
java.util.concurrent.locks.ReentrantLock@64fcd88a[Locked by thread Thread-A]
holdCount: 1
queuedLength: 2
isFair: false
isLocked: true
isHeldByCurrentThread: true
java.util.concurrent.locks.ReentrantLock@64fcd88a[Locked by thread Thread-C]
holdCount: 1
queuedLength: 1
isFair: false
isLocked: true
isHeldByCurrentThread: true
// ...# #tryLock 方法
与无条件获取锁相比,tryLock 有更完善的容错机制。
tryLock()- 可轮询获取锁。如果成功,则返回 true;如果失败,则返回 false。也就是说,这个方法无论成败都会立即返回,获取不到锁(锁已被其他线程获取)时不会一直等待。tryLock(long, TimeUnit)- 可定时获取锁。和tryLock()类似,区别仅在于这个方法在获取不到锁时会等待一定的时间,在时间期限之内如果还获取不到锁,就返回 false。如果如果一开始拿到锁或者在等待期间内拿到了锁,则返回 true。
示例: ReentrantLock 的 tryLock() 操作
修改上个示例中的 execute() 方法
public void execute() {
if (lock.tryLock()) {
try {
for (int i = 0; i < 3; i++) {
// 略...
}
} finally {
lock.unlock();
}
} else {
System.out.println(Thread.currentThread().getName() + " 获取锁失败");
}
}示例: ReentrantLock 的 tryLock(long, TimeUnit) 操作
修改上个示例中的 execute() 方法
public void execute() {
try {
if (lock.tryLock(2, TimeUnit.SECONDS)) {
try {
for (int i = 0; i < 3; i++) {
// 略...
}
} finally {
lock.unlock();
}
} else {
System.out.println(Thread.currentThread().getName() + " 获取锁失败");
}
} catch (InterruptedException e) {
System.out.println(Thread.currentThread().getName() + " 获取锁超时");
e.printStackTrace();
}
}# #lockInterruptibly 方法
-
lockInterruptibly()
try-catch \- 可中断获取锁 。可中断获取锁可以在获得锁的同时保持对中断的响应。可中断获取锁比其它获取锁的方式稍微复杂一些,需要两个
InterruptedException 块(如果在获取锁的操作中抛出了
try-finally ,那么可以使用标准的 加锁模式)。 - 举例来说:假设有两个线程同时通过 `lock.lockInterruptibly()` 获取某个锁时,若线程 A 获取到了锁,则线程 B 只能等待。若此时对线程 B 调用 `threadB.interrupt()` 方法能够中断线程 B 的等待过程。由于 `lockInterruptibly()` 的声明中抛出了异常,所以 `lock.lockInterruptibly()` 必须放在 `try` 块中或者在调用 `lockInterruptibly()` 的方法外声明抛出 `InterruptedException`。 > 🔔 注意:当一个线程获取了锁之后,是不会被 `interrupt()` 方法中断的。单独调用 `interrupt()` 方法不能中断正在运行状态中的线程,只能中断阻塞状态中的线程。因此当通过 `lockInterruptibly()` 方法获取某个锁时,如果未获取到锁,只有在等待的状态下,才可以响应中断。 示例:`ReentrantLock` 的 `lockInterruptibly()` 操作 修改上个示例中的 `execute()` 方法 ```java public void execute() { try { lock.lockInterruptibly(); for (int i = 0; i < 3; i++) { // 略... } } catch (InterruptedException e) { System.out.println(Thread.currentThread().getName() + "被中断"); e.printStackTrace(); } finally { lock.unlock(); } }
# #newCondition 方法
newCondition() - 返回一个绑定到 Lock 对象上的 Condition 实例。 Condition 的特性和具体方法请阅读下文 Condition 。
# #3.3. ReentrantLock 的原理
# #ReentrantLock 的可见性
class X {
private final Lock rtl =
new ReentrantLock();
int value;
public void addOne() {
// 获取锁
rtl.lock();
try {
value+=1;
} finally {
// 保证锁能释放
rtl.unlock();
}
}
}ReentrantLock,内部持有一个 volatile 的成员变量 state,获取锁的时候,会读写 state 的值;解锁的时候,也会读写 state 的值(简化后的代码如下面所示)。也就是说,在执行 value+=1 之前,程序先读写了一次 volatile 变量 state,在执行 value+=1 之后,又读写了一次 volatile 变量 state。根据相关的 Happens-Before 规则:
- 顺序性规则:对于线程 T1,value+=1 Happens-Before 释放锁的操作 unlock ();
- volatile 变量规则:由于 state = 1 会先读取 state,所以线程 T1 的 unlock () 操作 Happens-Before 线程 T2 的 lock () 操作;
- 传递性规则:线程 T1 的 value+=1 Happens-Before 线程 T2 的 lock () 操作。
# #ReentrantLock 的数据结构
阅读 ReentrantLock 的源码,可以发现它有一个核心字段:
private final Sync sync;sync- 内部抽象类ReentrantLock.Sync对象,Sync继承自 AQS。它有两个子类:ReentrantLock.FairSync- 公平锁。ReentrantLock.NonfairSync- 非公平锁。
查看源码可以发现, ReentrantLock 实现 Lock 接口其实是调用 ReentrantLock.FairSync 或 ReentrantLock.NonfairSync 中各自的实现,这里不一一列举。
# #ReentrantLock 的获取锁和释放锁
ReentrantLock 获取锁和释放锁的接口,从表象看,是调用 ReentrantLock.FairSync 或 ReentrantLock.NonfairSync 中各自的实现;从本质上看,是基于 AQS 的实现。
仔细阅读源码很容易发现:
void lock()调用 Sync 的 lock () 方法。void lockInterruptibly()直接调用 AQS 的 获取可中断的独占锁 方法lockInterruptibly()。boolean tryLock()调用 Sync 的nonfairTryAcquire()。boolean tryLock(long time, TimeUnit unit)直接调用 AQS 的 获取超时等待式的独占锁 方法tryAcquireNanos(int arg, long nanosTimeout)。void unlock()直接调用 AQS 的 释放独占锁 方法release(int arg)。
直接调用 AQS 接口的方法就不再赘述了,其原理在 [AQS 的原理](#AQS 的原理) 中已经用很大篇幅进行过讲解。
nonfairTryAcquire 方法源码如下:
// 公平锁和非公平锁都会用这个方法区尝试获取锁
final boolean nonfairTryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
if (compareAndSetState(0, acquires)) {
// 如果同步状态为0,将其设为 acquires,并设置当前线程为排它线程
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0) // overflow
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}处理流程很简单:
- 如果同步状态为 0,设置同步状态设为 acquires,并设置当前线程为排它线程,然后返回 true,获取锁成功。
- 如果同步状态不为 0 且当前线程为排它线程,设置同步状态为当前状态值 + acquires 值,然后返回 true,获取锁成功。
- 否则,返回 false,获取锁失败。
# #公平锁和非公平锁
ReentrantLock 这个类有两个构造函数,一个是无参构造函数,一个是传入 fair 参数的构造函数。fair 参数代表的是锁的公平策略,如果传入 true 就表示需要构造一个公平锁,反之则表示要构造一个非公平锁。
锁都对应着一个等待队列,如果一个线程没有获得锁,就会进入等待队列,当有线程释放锁的时候,就需要从等待队列中唤醒一个等待的线程。如果是公平锁,唤醒的策略就是谁等待的时间长,就唤醒谁,很公平;如果是非公平锁,则不提供这个公平保证,有可能等待时间短的线程反而先被唤醒。
lock 方法在公平锁和非公平锁中的实现:
二者的区别仅在于申请非公平锁时,如果同步状态为 0,尝试将其设为 1,如果成功,直接将当前线程置为排它线程;否则和公平锁一样,调用 AQS 获取独占锁方法 acquire 。
// 非公平锁实现
final void lock() {
if (compareAndSetState(0, 1))
// 如果同步状态为0,将其设为1,并设置当前线程为排它线程
setExclusiveOwnerThread(Thread.currentThread());
else
// 调用 AQS 获取独占锁方法 acquire
acquire(1);
}
// 公平锁实现
final void lock() {
// 调用 AQS 获取独占锁方法 acquire
acquire(1);
}# #4. ReentrantReadWriteLock
ReadWriteLock 适用于读多写少的场景。
ReentrantReadWriteLock 类是 ReadWriteLock 接口的具体实现,它是一个可重入的读写锁。 ReentrantReadWriteLock 维护了一对读写锁,将读写锁分开,有利于提高并发效率。
读写锁,并不是 Java 语言特有的,而是一个广为使用的通用技术,所有的读写锁都遵守以下三条基本原则:
- 允许多个线程同时读共享变量;
- 只允许一个线程写共享变量;
- 如果一个写线程正在执行写操作,此时禁止读线程读共享变量。
读写锁与互斥锁的一个重要区别就是读写锁允许多个线程同时读共享变量,而互斥锁是不允许的,这是读写锁在读多写少场景下性能优于互斥锁的关键。但读写锁的写操作是互斥的,当一个线程在写共享变量的时候,是不允许其他线程执行写操作和读操作。
# #4.1. ReentrantReadWriteLock 的特性
ReentrantReadWriteLock 的特性如下:
-
ReentrantReadWriteLock适用于读多写少的场景。如果是写多读少的场景,由于ReentrantReadWriteLock其内部实现比ReentrantLock复杂,性能可能反而要差一些。如果存在这样的问题,需要具体问题具体分析。由于ReentrantReadWriteLock的读写锁(ReadLock、WriteLock)都实现了Lock接口,所以要替换为ReentrantLock也较为容易。 ReentrantReadWriteLock实现了ReadWriteLock接口,支持了ReentrantLock所不具备的读写锁分离。ReentrantReadWriteLock维护了一对读写锁(ReadLock、WriteLock)。将读写锁分开,有利于提高并发效率。ReentrantReadWriteLock的加锁策略是:允许多个读操作并发执行,但每次只允许一个写操作。ReentrantReadWriteLock为读写锁都提供了可重入的加锁语义。ReentrantReadWriteLock支持公平锁和非公平锁(默认)两种模式。
ReadWriteLock 接口定义如下:
public interface ReadWriteLock {
Lock readLock();
Lock writeLock();
}readLock- 返回用于读操作的锁(ReadLock)。writeLock- 返回用于写操作的锁(WriteLock)。
在读写锁和写入锁之间的交互可以采用多种实现方式, ReadWriteLock 的一些可选实现包括:
- 释放优先 - 当一个写入操作释放写锁,并且队列中同时存在读线程和写线程,那么应该优先选择读线程、写线程,还是最先发出请求的线程?
- 读线程插队 - 如果锁是由读线程持有,但有写线程正在等待,那么新到达的读线程能否立即获得访问权,还是应该在写线程后面等待?如果允许读线程插队到写线程之前,那么将提高并发性,但可能造成线程饥饿问题。
- 重入性 - 读锁和写锁是否是可重入的?
- 降级 - 如果一个线程持有写入锁,那么它能否在不释放该锁的情况下获得读锁?这可能会使得写锁被降级为读锁,同时不允许其他写线程修改被保护的资源。
- 升级 - 读锁能否优先于其他正在等待的读线程和写线程而升级为一个写锁?在大多数的读写锁实现中并不支持升级,因为如果没有显式的升级操作,那么很容易造成死锁。
# #4.2. ReentrantReadWriteLock 的用法
前文了解了 ReentrantReadWriteLock 的特性,接下来,我们要讲述其具体用法。
# #ReentrantReadWriteLock 的构造方法
ReentrantReadWriteLock 和 ReentrantLock 一样,也有两个构造方法,且用法相似。
public ReentrantReadWriteLock() {}
public ReentrantReadWriteLock(boolean fair) {}ReentrantReadWriteLock()- 默认构造方法会初始化一个非公平锁(NonfairSync)。在非公平的锁中,线程获得锁的顺序是不确定的。写线程降级为读线程是可以的,但读线程升级为写线程是不可以的(这样会导致死锁)。ReentrantReadWriteLock(boolean)-new ReentrantLock(true)会初始化一个公平锁(FairSync)。对于公平锁,等待时间最长的线程将优先获得锁。如果这个锁是读线程持有,则另一个线程请求写锁,那么其他读线程都不能获得读锁,直到写线程释放写锁。
# #ReentrantReadWriteLock 的使用实例
在 ReentrantReadWriteLock 的特性 中已经介绍过, ReentrantReadWriteLock 的读写锁( ReadLock 、 WriteLock )都实现了 Lock 接口,所以其各自独立的使用方式与 ReentrantLock 一样,这里不再赘述。
ReentrantReadWriteLock 与 ReentrantLock 用法上的差异,主要在于读写锁的配合使用。本文以一个典型使用场景来进行讲解。
【示例】基于 ReadWriteLock 实现一个简单的泛型无界缓存
/**
* 简单的无界缓存实现
* <p>
* 使用 WeakHashMap 存储键值对。WeakHashMap 中存储的对象是弱引用,JVM GC 时会自动清除没有被引用的弱引用对象。
*/
static class UnboundedCache<K, V> {
private final Map<K, V> cacheMap = new WeakHashMap<>();
private final ReadWriteLock cacheLock = new ReentrantReadWriteLock();
public V get(K key) {
cacheLock.readLock().lock();
V value;
try {
value = cacheMap.get(key);
String log = String.format("%s 读数据 %s:%s", Thread.currentThread().getName(), key, value);
System.out.println(log);
} finally {
cacheLock.readLock().unlock();
}
return value;
}
public V put(K key, V value) {
cacheLock.writeLock().lock();
try {
cacheMap.put(key, value);
String log = String.format("%s 写入数据 %s:%s", Thread.currentThread().getName(), key, value);
System.out.println(log);
} finally {
cacheLock.writeLock().unlock();
}
return value;
}
public V remove(K key) {
cacheLock.writeLock().lock();
try {
return cacheMap.remove(key);
} finally {
cacheLock.writeLock().unlock();
}
}
public void clear() {
cacheLock.writeLock().lock();
try {
this.cacheMap.clear();
} finally {
cacheLock.writeLock().unlock();
}
}
}说明:
- 使用
WeakHashMap而不是HashMap来存储键值对。WeakHashMap中存储的对象是弱引用,JVM GC 时会自动清除没有被引用的弱引用对象。 - 向
Map写数据前加写锁,写完后,释放写锁。 - 向
Map读数据前加读锁,读完后,释放读锁。
测试其线程安全性:
/**
* @author <a href="mailto:forbreak@163.com">Zhang Peng</a>
* @since 2020-01-01
*/
public class ReentrantReadWriteLockDemo {
static UnboundedCache<Integer, Integer> cache = new UnboundedCache<>();
public static void main(String[] args) {
ExecutorService executorService = Executors.newCachedThreadPool();
for (int i = 0; i < 20; i++) {
executorService.execute(new MyThread());
cache.get(0);
}
executorService.shutdown();
}
/** 线程任务每次向缓存中写入 3 个随机值,key 固定 */
static class MyThread implements Runnable {
@Override
public void run() {
Random random = new Random();
for (int i = 0; i < 3; i++) {
cache.put(i, random.nextInt(100));
}
}
}
}说明:示例中,通过线程池启动 20 个并发任务。任务每次向缓存中写入 3 个随机值,key 固定;然后主线程每次固定读取缓存中第一个 key 的值。
输出结果:
main 读数据 0:null
pool-1-thread-1 写入数据 0:16
pool-1-thread-1 写入数据 1:58
pool-1-thread-1 写入数据 2:50
main 读数据 0:16
pool-1-thread-1 写入数据 0:85
pool-1-thread-1 写入数据 1:76
pool-1-thread-1 写入数据 2:46
pool-1-thread-2 写入数据 0:21
pool-1-thread-2 写入数据 1:41
pool-1-thread-2 写入数据 2:63
main 读数据 0:21
main 读数据 0:21
// ...# #4.3. ReentrantReadWriteLock 的原理
前面了解了 ReentrantLock 的原理,理解 ReentrantReadWriteLock 就容易多了。
# #ReentrantReadWriteLock 的数据结构
阅读 ReentrantReadWriteLock 的源码,可以发现它有三个核心字段:
/** Inner class providing readlock */
private final ReentrantReadWriteLock.ReadLock readerLock;
/** Inner class providing writelock */
private final ReentrantReadWriteLock.WriteLock writerLock;
/** Performs all synchronization mechanics */
final Sync sync;
public ReentrantReadWriteLock.WriteLock writeLock() { return writerLock; }
public ReentrantReadWriteLock.ReadLock readLock() { return readerLock; }sync- 内部类ReentrantReadWriteLock.Sync对象。与ReentrantLock类似,它有两个子类:ReentrantReadWriteLock.FairSync和ReentrantReadWriteLock.NonfairSync,分别表示公平锁和非公平锁的实现。readerLock- 内部类ReentrantReadWriteLock.ReadLock对象,这是一把读锁。writerLock- 内部类ReentrantReadWriteLock.WriteLock对象,这是一把写锁。
# #ReentrantReadWriteLock 的获取锁和释放锁
public static class ReadLock implements Lock, java.io.Serializable {
// 调用 AQS 获取共享锁方法
public void lock() {
sync.acquireShared(1);
}
// 调用 AQS 释放共享锁方法
public void unlock() {
sync.releaseShared(1);
}
}
public static class WriteLock implements Lock, java.io.Serializable {
// 调用 AQS 获取独占锁方法
public void lock() {
sync.acquire(1);
}
// 调用 AQS 释放独占锁方法
public void unlock() {
sync.release(1);
}
}# #5. StampedLock
ReadWriteLock 支持两种模式:一种是读锁,一种是写锁。而 StampedLock 支持三种模式,分别是:写锁、悲观读锁和乐观读。其中,写锁、悲观读锁的语义和 ReadWriteLock 的写锁、读锁的语义非常类似,允许多个线程同时获取悲观读锁,但是只允许一个线程获取写锁,写锁和悲观读锁是互斥的。不同的是:StampedLock 里的写锁和悲观读锁加锁成功之后,都会返回一个 stamp;然后解锁的时候,需要传入这个 stamp。
注意这里,用的是 “乐观读” 这个词,而不是 “乐观读锁”,是要提醒你,乐观读这个操作是无锁的,所以相比较 ReadWriteLock 的读锁,乐观读的性能更好一些。
StampedLock 的性能之所以比 ReadWriteLock 还要好,其关键是 StampedLock 支持乐观读的方式。
- ReadWriteLock 支持多个线程同时读,但是当多个线程同时读的时候,所有的写操作会被阻塞;
- 而 StampedLock 提供的乐观读,是允许一个线程获取写锁的,也就是说不是所有的写操作都被阻塞。
对于读多写少的场景 StampedLock 性能很好,简单的应用场景基本上可以替代 ReadWriteLock,但是 StampedLock 的功能仅仅是 ReadWriteLock 的子集,在使用的时候,还是有几个地方需要注意一下。
- StampedLock 不支持重入
- StampedLock 的悲观读锁、写锁都不支持条件变量。
- 如果线程阻塞在 StampedLock 的 readLock () 或者 writeLock () 上时,此时调用该阻塞线程的 interrupt () 方法,会导致 CPU 飙升。使用 StampedLock 一定不要调用中断操作,如果需要支持中断功能,一定使用可中断的悲观读锁 readLockInterruptibly () 和写锁 writeLockInterruptibly ()。
【示例】StampedLock 阻塞时,调用 interrupt () 导致 CPU 飙升
final StampedLock lock
= new StampedLock();
Thread T1 = new Thread(()->{
// 获取写锁
lock.writeLock();
// 永远阻塞在此处,不释放写锁
LockSupport.park();
});
T1.start();
// 保证 T1 获取写锁
Thread.sleep(100);
Thread T2 = new Thread(()->
// 阻塞在悲观读锁
lock.readLock()
);
T2.start();
// 保证 T2 阻塞在读锁
Thread.sleep(100);
// 中断线程 T2
// 会导致线程 T2 所在 CPU 飙升
T2.interrupt();
T2.join();【示例】StampedLock 读模板:
final StampedLock sl =
new StampedLock();
// 乐观读
long stamp =
sl.tryOptimisticRead();
// 读入方法局部变量
......
// 校验 stamp
if (!sl.validate(stamp)){
// 升级为悲观读锁
stamp = sl.readLock();
try {
// 读入方法局部变量
.....
} finally {
// 释放悲观读锁
sl.unlockRead(stamp);
}
}
// 使用方法局部变量执行业务操作
......【示例】StampedLock 写模板:
long stamp = sl.writeLock();
try {
// 写共享变量
......
} finally {
sl.unlockWrite(stamp);
}# #6. AQS
AbstractQueuedSynchronizer(简称 AQS)是队列同步器,顾名思义,其主要作用是处理同步。它是并发锁和很多同步工具类的实现基石(如ReentrantLock、ReentrantReadWriteLock、CountDownLatch、Semaphore、FutureTask等)。
# #6.1. AQS 的要点
AQS 提供了对独享锁与共享锁的支持。
在 java.util.concurrent.locks 包中的相关锁(常用的有 ReentrantLock 、 ReadWriteLock )都是基于 AQS 来实现。这些锁都没有直接继承 AQS,而是定义了一个 Sync 类去继承 AQS。为什么要这样呢?因为锁面向的是使用用户,而同步器面向的则是线程控制,那么在锁的实现中聚合同步器而不是直接继承 AQS 就可以很好的隔离二者所关注的事情。
# #6.2. AQS 的应用
AQS 提供了对独享锁与共享锁的支持。
# #独享锁 API
获取、释放独享锁的主要 API 如下:
public final void acquire(int arg)
public final void acquireInterruptibly(int arg)
public final boolean tryAcquireNanos(int arg, long nanosTimeout)
public final boolean release(int arg)-
acquire- 获取独占锁。 -
acquireInterruptibly- 获取可中断的独占锁。 -
tryAcquireNanos \- 尝试在指定时间内获取可中断的独占锁。在以下三种情况下回返回: - 在超时时间内,当前线程成功获取了锁; - 当前线程在超时时间内被中断; - 超时时间结束,仍未获得锁返回 false。 - `release` - 释放独占锁。 #### [#](https://dunwu.github.io/javacore/concurrent/Java锁.html#共享锁-api)共享锁 API 获取、释放共享锁的主要 API 如下: ```java public final void acquireShared(int arg) public final void acquireSharedInterruptibly(int arg) public final boolean tryAcquireSharedNanos(int arg, long nanosTimeout) public final boolean releaseShared(int arg) -
acquireShared- 获取共享锁。 -
acquireSharedInterruptibly- 获取可中断的共享锁。 -
tryAcquireSharedNanos- 尝试在指定时间内获取可中断的共享锁。 -
release- 释放共享锁。
# #6.3. AQS 的原理
ASQ 原理要点:
- AQS 使用一个整型的
volatile变量来 维护同步状态。状态的意义由子类赋予。- AQS 维护了一个 FIFO 的双链表,用来存储获取锁失败的线程。
AQS 围绕同步状态提供两种基本操作 “获取” 和 “释放”,并提供一系列判断和处理方法,简单说几点:
- state 是独占的,还是共享的;
- state 被获取后,其他线程需要等待;
- state 被释放后,唤醒等待线程;
- 线程等不及时,如何退出等待。
至于线程是否可以获得 state,如何释放 state,就不是 AQS 关心的了,要由子类具体实现。
# #AQS 的数据结构
阅读 AQS 的源码,可以发现:AQS 继承自 AbstractOwnableSynchronize 。
public abstract class AbstractQueuedSynchronizer
extends AbstractOwnableSynchronizer
implements java.io.Serializable {
/** 等待队列的队头,懒加载。只能通过 setHead 方法修改。 */
private transient volatile Node head;
/** 等待队列的队尾,懒加载。只能通过 enq 方法添加新的等待节点。*/
private transient volatile Node tail;
/** 同步状态 */
private volatile int state;
}-
state
volatile \- AQS 使用一个整型的 变量来 维护同步状态 。 - 这个整数状态的意义由子类来赋予,如`ReentrantLock` 中该状态值表示所有者线程已经重复获取该锁的次数,`Semaphore` 中该状态值表示剩余的许可数量。 - `head` 和 `tail` - AQS **维护了一个 `Node` 类型(AQS 的内部类)的双链表来完成同步状态的管理**。这个双链表是一个双向的 FIFO 队列,通过 `head` 和 `tail` 指针进行访问。当 **有线程获取锁失败后,就被添加到队列末尾**。  再来看一下 `Node` 的源码 ```java static final class Node { /** 该等待同步的节点处于共享模式 */ static final Node SHARED = new Node(); /** 该等待同步的节点处于独占模式 */ static final Node EXCLUSIVE = null; /** 线程等待状态,状态值有: 0、1、-1、-2、-3 */ volatile int waitStatus; static final int CANCELLED = 1; static final int SIGNAL = -1; static final int CONDITION = -2; static final int PROPAGATE = -3; /** 前驱节点 */ volatile Node prev; /** 后继节点 */ volatile Node next; /** 等待锁的线程 */ volatile Thread thread; /** 和节点是否共享有关 */ Node nextWaiter; }
很显然,Node 是一个双链表结构。
-
waitStatus
Node \-
volatile 使用一个整型的
waitStatus 变量来 维护 AQS 同步队列中线程节点的状态。 有五个状态值: - `CANCELLED(1)` - 此状态表示:该节点的线程可能由于超时或被中断而 **处于被取消(作废)状态**,一旦处于这个状态,表示这个节点应该从等待队列中移除。 - `SIGNAL(-1)` - 此状态表示:**后继节点会被挂起**,因此在当前节点释放锁或被取消之后,必须唤醒(`unparking`)其后继结点。 - `CONDITION(-2)` - 此状态表示:该节点的线程 **处于等待条件状态**,不会被当作是同步队列上的节点,直到被唤醒(`signal`),设置其值为 0,再重新进入阻塞状态。 - `PROPAGATE(-3)` - 此状态表示:下一个 `acquireShared` 应无条件传播。 - 0 - 非以上状态。 #### [#](https://dunwu.github.io/javacore/concurrent/Java锁.html#独占锁的获取和释放)独占锁的获取和释放 ##### [#](https://dunwu.github.io/javacore/concurrent/Java锁.html#获取独占锁)获取独占锁 AQS 中使用 `acquire(int arg)` 方法获取独占锁,其大致流程如下: 1. 先尝试获取同步状态,如果获取同步状态成功,则结束方法,直接返回。 2. 如果获取同步状态不成功,AQS 会不断尝试利用 CAS 操作将当前线程插入等待同步队列的队尾,直到成功为止。 3. 接着,不断尝试为等待队列中的线程节点获取独占锁。   详细流程可以用下图来表示,请结合源码来理解(一图胜千言): 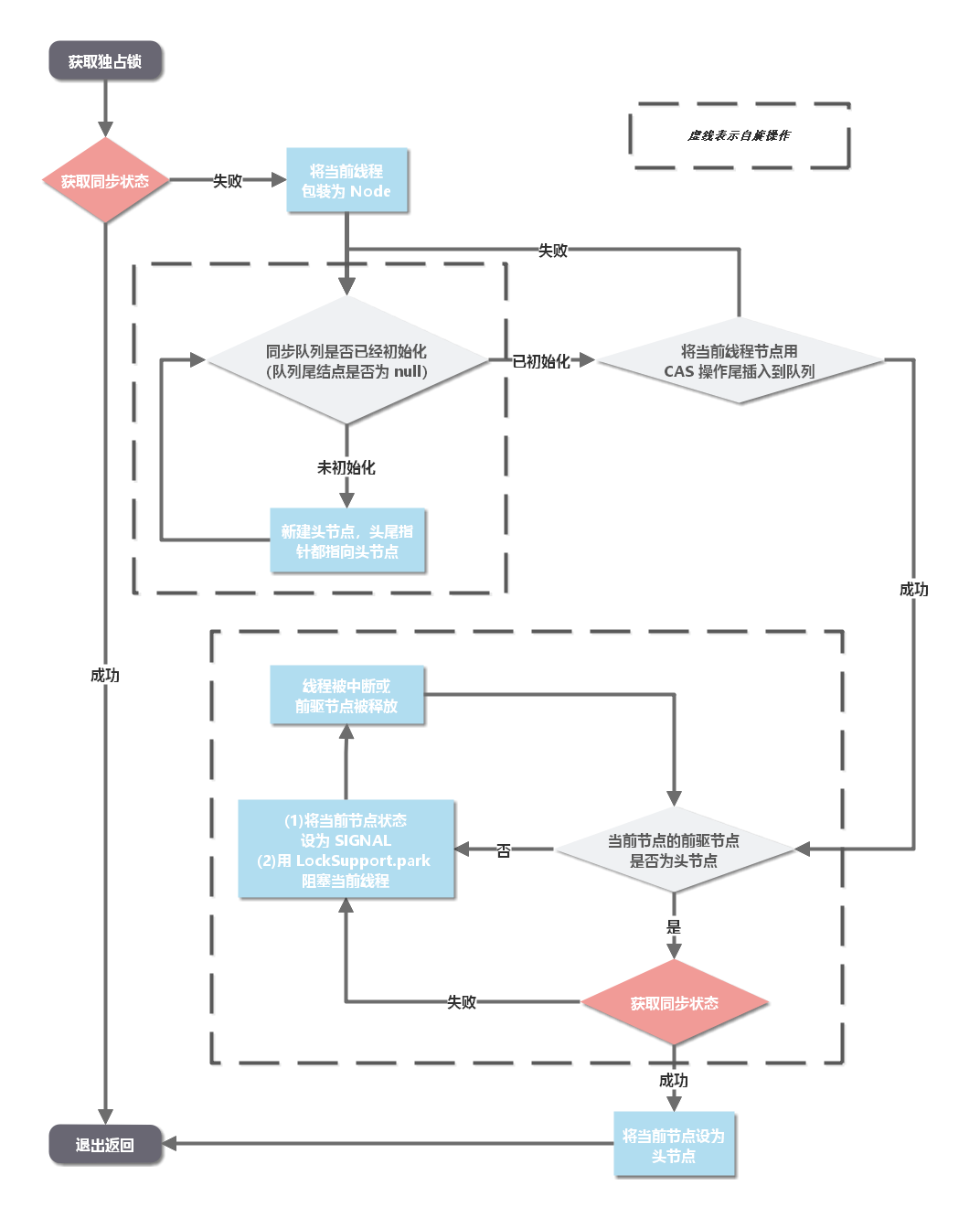 ##### [#](https://dunwu.github.io/javacore/concurrent/Java锁.html#释放独占锁)释放独占锁 AQS 中使用 `release(int arg)` 方法释放独占锁,其大致流程如下: 1. 先尝试获取解锁线程的同步状态,如果获取同步状态不成功,则结束方法,直接返回。 2. 如果获取同步状态成功,AQS 会尝试唤醒当前线程节点的后继节点。 ##### [#](https://dunwu.github.io/javacore/concurrent/Java锁.html#获取可中断的独占锁)获取可中断的独占锁 AQS 中使用 `acquireInterruptibly(int arg)` 方法获取可中断的独占锁。 `acquireInterruptibly(int arg)` 实现方式**相较于获取独占锁方法( `acquire`)非常相似**,区别仅在于它会**通过 `Thread.interrupted` 检测当前线程是否被中断**,如果是,则立即抛出中断异常(`InterruptedException`)。 ##### [#](https://dunwu.github.io/javacore/concurrent/Java锁.html#获取超时等待式的独占锁)获取超时等待式的独占锁 AQS 中使用 `tryAcquireNanos(int arg)` 方法获取超时等待的独占锁。 doAcquireNanos 的实现方式 **相较于获取独占锁方法( `acquire`)非常相似**,区别在于它会根据超时时间和当前时间计算出截止时间。在获取锁的流程中,会不断判断是否超时,如果超时,直接返回 false;如果没超时,则用 `LockSupport.parkNanos` 来阻塞当前线程。 #### [#](https://dunwu.github.io/javacore/concurrent/Java锁.html#共享锁的获取和释放)共享锁的获取和释放 ##### [#](https://dunwu.github.io/javacore/concurrent/Java锁.html#获取共享锁)获取共享锁 AQS 中使用 `acquireShared(int arg)` 方法获取共享锁。 `acquireShared` 方法和 `acquire` 方法的逻辑很相似,区别仅在于自旋的条件以及节点出队的操作有所不同。 成功获得共享锁的条件如下: - `tryAcquireShared(arg)` 返回值大于等于 0 (这意味着共享锁的 permit 还没有用完)。 - 当前节点的前驱节点是头结点。 ##### [#](https://dunwu.github.io/javacore/concurrent/Java锁.html#释放共享锁)释放共享锁 AQS 中使用 `releaseShared(int arg)` 方法释放共享锁。 `releaseShared` 首先会尝试释放同步状态,如果成功,则解锁一个或多个后继线程节点。释放共享锁和释放独享锁流程大体相似,区别在于: 对于独享模式,如果需要 SIGNAL,释放仅相当于调用头节点的 `unparkSuccessor`。 ##### [#](https://dunwu.github.io/javacore/concurrent/Java锁.html#获取可中断的共享锁)获取可中断的共享锁 AQS 中使用 `acquireSharedInterruptibly(int arg)` 方法获取可中断的共享锁。 `acquireSharedInterruptibly` 方法与 `acquireInterruptibly` 几乎一致,不再赘述。 ##### [#](https://dunwu.github.io/javacore/concurrent/Java锁.html#获取超时等待式的共享锁)获取超时等待式的共享锁 AQS 中使用 `tryAcquireSharedNanos(int arg)` 方法获取超时等待式的共享锁。 `tryAcquireSharedNanos` 方法与 `tryAcquireNanos` 几乎一致,不再赘述。 ## [#](https://dunwu.github.io/javacore/concurrent/Java锁.html#_7-死锁)7. 死锁 ### [#](https://dunwu.github.io/javacore/concurrent/Java锁.html#_7-1-什么是死锁)7.1. 什么是死锁 死锁是一种特定的程序状态,在实体之间,由于循环依赖导致彼此一直处于等待之中,没有任何个体可以继续前进。死锁不仅仅是在线程之间会发生,存在资源独占的进程之间同样也 可能出现死锁。通常来说,我们大多是聚焦在多线程场景中的死锁,指两个或多个线程之间,由于互相持有对方需要的锁,而永久处于阻塞的状态。 ### [#](https://dunwu.github.io/javacore/concurrent/Java锁.html#_7-2-如何定位死锁)7.2. 如何定位死锁 定位死锁最常见的方式就是利用 jstack 等工具获取线程栈,然后定位互相之间的依赖关系,进而找到死锁。如果是比较明显的死锁,往往 jstack 等就能直接定位,类似 JConsole 甚至可以在图形界面进行有限的死锁检测。 如果我们是开发自己的管理工具,需要用更加程序化的方式扫描服务进程、定位死锁,可以考虑使用 Java 提供的标准管理 API,`ThreadMXBean`,其直接就提供了 `findDeadlockedThreads()` 方法用于定位。 ### [#](https://dunwu.github.io/javacore/concurrent/Java锁.html#_7-3-如何避免死锁)7.3. 如何避免死锁 基本上死锁的发生是因为: - 互斥,类似 Java 中 Monitor 都是独占的。 - 长期保持互斥,在使用结束之前,不会释放,也不能被其他线程抢占。 - 循环依赖,多个个体之间出现了锁的循环依赖,彼此依赖上一环释放锁。 由此,我们可以分析出避免死锁的思路和方法。 (1)避免一个线程同时获取多个锁。 避免一个线程在锁内同时占用多个资源,尽量保证每个锁只占用一个资源。 尝试使用定时锁 `lock.tryLock(timeout)`,避免锁一直不能释放。 对于数据库锁,加锁和解锁必须在一个数据库连接中里,否则会出现解锁失败的情况 --- # Java 原子变量类 > **📦 本文以及示例源码已归档在 [javacore(opens new window)](https://github.com/dunwu/javacore/)** - \1. 原子变量类简介 - [1.1. 为何需要原子变量类](https://dunwu.github.io/javacore/concurrent/Java原子类.html#11-为何需要原子变量类) - [1.2. 原子变量类的作用](https://dunwu.github.io/javacore/concurrent/Java原子类.html#12-原子变量类的作用) - \2. 基本类型 - [2.1. **`AtomicInteger` 用法**](https://dunwu.github.io/javacore/concurrent/Java原子类.html#21-atomicinteger-用法) - [2.2. **`AtomicInteger` 实现**](https://dunwu.github.io/javacore/concurrent/Java原子类.html#22-atomicinteger-实现) - [3. 引用类型](https://dunwu.github.io/javacore/concurrent/Java原子类.html#3-引用类型) - [4. 数组类型](https://dunwu.github.io/javacore/concurrent/Java原子类.html#4-数组类型) - [5. 属性更新器类型](https://dunwu.github.io/javacore/concurrent/Java原子类.html#5-属性更新器类型) - [6. 原子化的累加器](https://dunwu.github.io/javacore/concurrent/Java原子类.html#6-原子化的累加器) - [7. 参考资料](https://dunwu.github.io/javacore/concurrent/Java原子类.html#7-参考资料) ## [#](https://dunwu.github.io/javacore/concurrent/Java原子类.html#_1-原子变量类简介)1. 原子变量类简介 ### [#](https://dunwu.github.io/javacore/concurrent/Java原子类.html#_1-1-为何需要原子变量类)1.1. 为何需要原子变量类 保证线程安全是 Java 并发编程必须要解决的重要问题。Java 从原子性、可见性、有序性这三大特性入手,确保多线程的数据一致性。 - 确保线程安全最常见的做法是利用锁机制(`Lock`、`sychronized`)来对共享数据做互斥同步,这样在同一个时刻,只有一个线程可以执行某个方法或者某个代码块,那么操作必然是原子性的,线程安全的。互斥同步最主要的问题是线程阻塞和唤醒所带来的性能问题。 - `volatile` 是轻量级的锁(自然比普通锁性能要好),它保证了共享变量在多线程中的可见性,但无法保证原子性。所以,它只能在一些特定场景下使用。 - 为了兼顾原子性以及锁带来的性能问题,Java 引入了 CAS (主要体现在 `Unsafe` 类)来实现非阻塞同步(也叫乐观锁)。并基于 CAS ,提供了一套原子工具类。 ### [#](https://dunwu.github.io/javacore/concurrent/Java原子类.html#_1-2-原子变量类的作用)1.2. 原子变量类的作用 原子变量类 **比锁的粒度更细,更轻量级**,并且对于在多处理器系统上实现高性能的并发代码来说是非常关键的。原子变量将发生竞争的范围缩小到单个变量上。 原子变量类相当于一种泛化的 `volatile` 变量,能够**支持原子的、有条件的读/改/写操**作。 原子类在内部使用 CAS 指令(基于硬件的支持)来实现同步。这些指令通常比锁更快。 原子变量类可以分为 4 组: - 基本类型 - `AtomicBoolean` - 布尔类型原子类 - `AtomicInteger` - 整型原子类 - `AtomicLong` - 长整型原子类 - 引用类型 - `AtomicReference` - 引用类型原子类 - `AtomicMarkableReference` - 带有标记位的引用类型原子类 - `AtomicStampedReference` - 带有版本号的引用类型原子类 - 数组类型 - `AtomicIntegerArray` - 整形数组原子类 - `AtomicLongArray` - 长整型数组原子类 - `AtomicReferenceArray` - 引用类型数组原子类 - 属性更新器类型 - `AtomicIntegerFieldUpdater` - 整型字段的原子更新器。 - `AtomicLongFieldUpdater` - 长整型字段的原子更新器。 - `AtomicReferenceFieldUpdater` - 原子更新引用类型里的字段。 > 这里不对 CAS、volatile、互斥同步做深入探讨。如果想了解更多细节,不妨参考:[Java 并发核心机制(opens new window)](https://github.com/dunwu/javacore/blob/master/docs/concurrent/Java并发核心机制.md) ## [#](https://dunwu.github.io/javacore/concurrent/Java原子类.html#_2-基本类型)2. 基本类型 这一类型的原子类是针对 Java 基本类型进行操作。 - `AtomicBoolean` - 布尔类型原子类 - `AtomicInteger` - 整型原子类 - `AtomicLong` - 长整型原子类 以上类都支持 CAS([compare-and-swap (opens new window)](https://en.wikipedia.org/wiki/Compare-and-swap))技术,此外,`AtomicInteger`、`AtomicLong` 还支持算术运算。 > 💡 提示: > > 虽然 Java 只提供了 `AtomicBoolean` 、`AtomicInteger`、`AtomicLong`,但是可以模拟其他基本类型的原子变量。要想模拟其他基本类型的原子变量,可以将 `short` 或 `byte` 等类型与 `int` 类型进行转换,以及使用 `Float.floatToIntBits` 、`Double.doubleToLongBits` 来转换浮点数。 > > 由于 `AtomicBoolean`、`AtomicInteger`、`AtomicLong` 实现方式、使用方式都相近,所以本文仅针对 `AtomicInteger` 进行介绍。 ### [#](https://dunwu.github.io/javacore/concurrent/Java原子类.html#_2-1-atomicinteger-用法)2.1. **`AtomicInteger` 用法** ```java public final int get() // 获取当前值 public final int getAndSet(int newValue) // 获取当前值,并设置新值 public final int getAndIncrement()// 获取当前值,并自增 public final int getAndDecrement() // 获取当前值,并自减 public final int getAndAdd(int delta) // 获取当前值,并加上预期值 boolean compareAndSet(int expect, int update) // 如果输入值(update)等于预期值,将该值设置为输入值 public final void lazySet(int newValue) // 最终设置为 newValue,使用 lazySet 设置之后可能导致其他线程在之后的一小段时间内还是可以读到旧的值。
AtomicInteger 使用示例:
public class AtomicIntegerDemo {
public static void main(String[] args) throws InterruptedException {
ExecutorService executorService = Executors.newFixedThreadPool(5);
AtomicInteger count = new AtomicInteger(0);
for (int i = 0; i < 1000; i++) {
executorService.submit((Runnable) () -> {
System.out.println(Thread.currentThread().getName() + " count=" + count.get());
count.incrementAndGet();
});
}
executorService.shutdown();
executorService.awaitTermination(30, TimeUnit.SECONDS);
System.out.println("Final Count is : " + count.get());
}
}# #2.2. AtomicInteger 实现
阅读 AtomicInteger 源码,可以看到如下定义:
private static final Unsafe unsafe = Unsafe.getUnsafe();
private static final long valueOffset;
static {
try {
valueOffset = unsafe.objectFieldOffset
(AtomicInteger.class.getDeclaredField("value"));
} catch (Exception ex) { throw new Error(ex); }
}
private volatile int value;说明:
value- value 属性使用volatile修饰,使得对 value 的修改在并发环境下对所有线程可见。valueOffset- value 属性的偏移量,通过这个偏移量可以快速定位到 value 字段,这个是实现 AtomicInteger 的关键。unsafe- Unsafe 类型的属性,它为AtomicInteger提供了 CAS 操作。
# #3. 引用类型
Java 数据类型分为 基本数据类型 和 引用数据类型 两大类(不了解 Java 数据类型划分可以参考: Java 基本数据类型 (opens new window))。
上一节中提到了针对基本数据类型的原子类,那么如果想针对引用类型做原子操作怎么办?Java 也提供了相关的原子类:
AtomicReference- 引用类型原子类AtomicMarkableReference- 带有标记位的引用类型原子类AtomicStampedReference- 带有版本号的引用类型原子类
AtomicStampedReference类在引用类型原子类中,彻底地解决了 ABA 问题,其它的 CAS 能力与另外两个类相近,所以最具代表性。因此,本节只针对AtomicStampedReference进行说明。
示例:基于 AtomicReference 实现一个简单的自旋锁
public class AtomicReferenceDemo2 {
private static int ticket = 10;
public static void main(String[] args) {
threadSafeDemo();
}
private static void threadSafeDemo() {
SpinLock lock = new SpinLock();
ExecutorService executorService = Executors.newFixedThreadPool(3);
for (int i = 0; i < 5; i++) {
executorService.execute(new MyThread(lock));
}
executorService.shutdown();
}
/**
* 基于 {@link AtomicReference} 实现的简单自旋锁
*/
static class SpinLock {
private AtomicReference<Thread> atomicReference = new AtomicReference<>();
public void lock() {
Thread current = Thread.currentThread();
while (!atomicReference.compareAndSet(null, current)) {}
}
public void unlock() {
Thread current = Thread.currentThread();
atomicReference.compareAndSet(current, null);
}
}
/**
* 利用自旋锁 {@link SpinLock} 并发处理数据
*/
static class MyThread implements Runnable {
private SpinLock lock;
public MyThread(SpinLock lock) {
this.lock = lock;
}
@Override
public void run() {
while (ticket > 0) {
lock.lock();
if (ticket > 0) {
System.out.println(Thread.currentThread().getName() + " 卖出了第 " + ticket + " 张票");
ticket--;
}
lock.unlock();
}
}
}
}原子类的实现基于 CAS 机制,而 CAS 存在 ABA 问题(不了解 ABA 问题,可以参考:Java 并发基础机制 - CAS 的问题 (opens new window))。正是为了解决 ABA 问题,才有了 AtomicMarkableReference 和 AtomicStampedReference 。
AtomicMarkableReference 使用一个布尔值作为标记,修改时在 true /false 之间切换。这种策略不能根本上解决 ABA 问题,但是可以降低 ABA 发生的几率。常用于缓存或者状态描述这样的场景。
public class AtomicMarkableReferenceDemo {
private final static String INIT_TEXT = "abc";
public static void main(String[] args) throws InterruptedException {
final AtomicMarkableReference<String> amr = new AtomicMarkableReference<>(INIT_TEXT, false);
ExecutorService executorService = Executors.newFixedThreadPool(3);
for (int i = 0; i < 10; i++) {
executorService.submit(new Runnable() {
@Override
public void run() {
try {
Thread.sleep(Math.abs((int) (Math.random() * 100)));
} catch (InterruptedException e) {
e.printStackTrace();
}
String name = Thread.currentThread().getName();
if (amr.compareAndSet(INIT_TEXT, name, amr.isMarked(), !amr.isMarked())) {
System.out.println(Thread.currentThread().getName() + " 修改了对象!");
System.out.println("新的对象为:" + amr.getReference());
}
}
});
}
executorService.shutdown();
executorService.awaitTermination(3, TimeUnit.SECONDS);
}
} AtomicStampedReference 使用一个整型值做为版本号,每次更新前先比较版本号,如果一致,才进行修改。通过这种策略,可以根本上解决 ABA 问题。
public class AtomicStampedReferenceDemo {
private final static String INIT_REF = "pool-1-thread-3";
private final static AtomicStampedReference<String> asr = new AtomicStampedReference<>(INIT_REF, 0);
public static void main(String[] args) throws InterruptedException {
System.out.println("初始对象为:" + asr.getReference());
ExecutorService executorService = Executors.newFixedThreadPool(3);
for (int i = 0; i < 3; i++) {
executorService.execute(new MyThread());
}
executorService.shutdown();
executorService.awaitTermination(3, TimeUnit.SECONDS);
}
static class MyThread implements Runnable {
@Override
public void run() {
try {
Thread.sleep(Math.abs((int) (Math.random() * 100)));
} catch (InterruptedException e) {
e.printStackTrace();
}
final int stamp = asr.getStamp();
if (asr.compareAndSet(INIT_REF, Thread.currentThread().getName(), stamp, stamp + 1)) {
System.out.println(Thread.currentThread().getName() + " 修改了对象!");
System.out.println("新的对象为:" + asr.getReference());
}
}
}
}# #4. 数组类型
Java 提供了以下针对数组的原子类:
AtomicIntegerArray- 整形数组原子类AtomicLongArray- 长整型数组原子类AtomicReferenceArray- 引用类型数组原子类
已经有了针对基本类型和引用类型的原子类,为什么还要提供针对数组的原子类呢?
数组类型的原子类为 数组元素 提供了 volatile 类型的访问语义,这是普通数组所不具备的特性 —— volatile 类型的数组仅在数组引用上具有 volatile 语义。
示例: AtomicIntegerArray 使用示例( AtomicLongArray 、 AtomicReferenceArray 使用方式也类似)
public class AtomicIntegerArrayDemo {
private static AtomicIntegerArray atomicIntegerArray = new AtomicIntegerArray(10);
public static void main(final String[] arguments) throws InterruptedException {
System.out.println("Init Values: ");
for (int i = 0; i < atomicIntegerArray.length(); i++) {
atomicIntegerArray.set(i, i);
System.out.print(atomicIntegerArray.get(i) + " ");
}
System.out.println();
Thread t1 = new Thread(new Increment());
Thread t2 = new Thread(new Compare());
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println("Final Values: ");
for (int i = 0; i < atomicIntegerArray.length(); i++) {
System.out.print(atomicIntegerArray.get(i) + " ");
}
System.out.println();
}
static class Increment implements Runnable {
@Override
public void run() {
for (int i = 0; i < atomicIntegerArray.length(); i++) {
int value = atomicIntegerArray.incrementAndGet(i);
System.out.println(Thread.currentThread().getName() + ", index = " + i + ", value = " + value);
}
}
}
static class Compare implements Runnable {
@Override
public void run() {
for (int i = 0; i < atomicIntegerArray.length(); i++) {
boolean swapped = atomicIntegerArray.compareAndSet(i, 2, 3);
if (swapped) {
System.out.println(Thread.currentThread().getName() + " swapped, index = " + i + ", value = 3");
}
}
}
}
}# #5. 属性更新器类型
更新器类支持基于反射机制的更新字段值的原子操作。
AtomicIntegerFieldUpdater- 整型字段的原子更新器。AtomicLongFieldUpdater- 长整型字段的原子更新器。AtomicReferenceFieldUpdater- 原子更新引用类型里的字段。
这些类的使用有一定限制:
- 因为对象的属性修改类型原子类都是抽象类,所以每次使用都必须使用静态方法
newUpdater()创建一个更新器,并且需要设置想要更新的类和属性。 - 字段必须是
volatile类型的; - 不能作用于静态变量(
static); - 不能作用于常量(
final);
public class AtomicReferenceFieldUpdaterDemo {
static User user = new User("begin");
static AtomicReferenceFieldUpdater<User, String> updater =
AtomicReferenceFieldUpdater.newUpdater(User.class, String.class, "name");
public static void main(String[] args) {
ExecutorService executorService = Executors.newFixedThreadPool(3);
for (int i = 0; i < 5; i++) {
executorService.execute(new MyThread());
}
executorService.shutdown();
}
static class MyThread implements Runnable {
@Override
public void run() {
if (updater.compareAndSet(user, "begin", "end")) {
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + " 已修改 name = " + user.getName());
} else {
System.out.println(Thread.currentThread().getName() + " 已被其他线程修改");
}
}
}
static class User {
volatile String name;
public User(String name) {
this.name = name;
}
public String getName() {
return name;
}
public User setName(String name) {
this.name = name;
return this;
}
}
}# #6. 原子化的累加器
DoubleAccumulator 、 DoubleAdder 、 LongAccumulator 和 LongAdder ,这四个类仅仅用来执行累加操作,相比原子化的基本数据类型,速度更快,但是不支持 compareAndSet() 方法。如果你仅仅需要累加操作,使用原子化的累加器性能会更好,代价就是会消耗更多的内存空间。
LongAdder 内部由一个 base 变量和一个 cell[] 数组组成。
- 当只有一个写线程,没有竞争的情况下,
LongAdder会直接使用base变量作为原子操作变量,通过 CAS 操作修改变量; - 当有多个写线程竞争的情况下,除了占用
base变量的一个写线程之外,其它各个线程会将修改的变量写入到自己的槽cell[]数组中。
我们可以发现, LongAdder 在操作后的返回值只是一个近似准确的数值,但是 LongAdder 最终返回的是一个准确的数值, 所以在一些对实时性要求比较高的场景下, LongAdder 并不能取代 AtomicInteger 或 AtomicLong 。
# Java 并发和容器
📦 本文以及示例源码已归档在 javacore(opens new window)
# #1. 同步容器
# #1.1. 同步容器简介
在 Java 中,同步容器主要包括 2 类:
-
Vector
Stack、
Hashtable、- `Vector` - `Vector` 实现了 `List` 接口。`Vector` 实际上就是一个数组,和 `ArrayList` 类似。但是 `Vector` 中的方法都是 `synchronized` 方法,即进行了同步措施。 - `Stack` - `Stack` 也是一个同步容器,它的方法也用 `synchronized` 进行了同步,它实际上是继承于 `Vector` 类。 - `Hashtable`- `Hashtable` 实现了 `Map` 接口,它和 `HashMap` 很相似,但是 `Hashtable` 进行了同步处理,而 `HashMap` 没有。 - `Collections` 类中提供的静态工厂方法创建的类(由 `Collections.synchronizedXXX` 等方法) ### [#](https://dunwu.github.io/javacore/concurrent/Java并发和容器.html#_1-2-同步容器的问题)1.2. 同步容器的问题 同步容器的同步原理就是在其 `get`、`set`、`size` 等主要方法上用 `synchronized` 修饰。 **`synchronized` 可以保证在同一个时刻,只有一个线程可以执行某个方法或者某个代码块**。 > 想详细了解 `synchronized` 用法和原理可以参考:[Java 并发核心机制(opens new window)](https://github.com/dunwu/javacore/blob/master/docs/concurrent/Java并发核心机制.md) #### [#](https://dunwu.github.io/javacore/concurrent/Java并发和容器.html#性能问题)性能问题 `synchronized` 的互斥同步会产生阻塞和唤醒线程的开销。显然,这种方式比没有使用 `synchronized` 的容器性能要差很多。 > 注:尤其是在 Java 1.6 没有对 `synchronized` 进行优化前,阻塞开销很高。 #### [#](https://dunwu.github.io/javacore/concurrent/Java并发和容器.html#安全问题)安全问题 同步容器真的绝对安全吗? 其实也未必。在做复合操作(非原子操作)时,仍然需要加锁来保护。常见复合操作如下: - **迭代**:反复访问元素,直到遍历完全部元素; - **跳转**:根据指定顺序寻找当前元素的下一个(下 n 个)元素; - **条件运算**:例如若没有则添加等; ❌ 不安全的示例 ```java public class VectorDemo { static Vector<Integer> vector = new Vector<>(); public static void main(String[] args) { while (true) { vector.clear(); for (int i = 0; i < 10; i++) { vector.add(i); } Thread thread1 = new Thread() { @Override public void run() { for (int i = 0; i < vector.size(); i++) { vector.remove(i); } } }; Thread thread2 = new Thread() { @Override public void run() { for (int i = 0; i < vector.size(); i++) { vector.get(i); } } }; thread1.start(); thread2.start(); while (Thread.activeCount() > 10) { System.out.println("同时存在 10 个以上线程,退出"); return; } } } }
以上程序执行时可能会出现数组越界错误。
Vector 是线程安全的,那为什么还会报这个错?
这是因为,对于 Vector,虽然能保证每一个时刻只能有一个线程访问它,但是不排除这种可能:
当某个线程在某个时刻执行这句时:
for(int i=0;i<vector.size();i++)
vector.get(i);假若此时 vector 的 size 方法返回的是 10,i 的值为 9
然后另外一个线程执行了这句:
for(int i=0;i<vector.size();i++)
vector.remove(i);将下标为 9 的元素删除了。
那么通过 get 方法访问下标为 9 的元素肯定就会出问题了。
✔ 安全示例
因此为了保证线程安全,必须在方法调用端做额外的同步措施,如下面所示:
public class VectorDemo2 {
static Vector<Integer> vector = new Vector<Integer>();
public static void main(String[] args) {
while (true) {
for (int i = 0; i < 10; i++) {
vector.add(i);
}
Thread thread1 = new Thread() {
@Override
public void run() {
synchronized (VectorDemo2.class) { //进行额外的同步
for (int i = 0; i < vector.size(); i++) {
vector.remove(i);
}
}
}
};
Thread thread2 = new Thread() {
@Override
public void run() {
synchronized (VectorDemo2.class) {
for (int i = 0; i < vector.size(); i++) {
vector.get(i);
}
}
}
};
thread1.start();
thread2.start();
while (Thread.activeCount() > 10) {
System.out.println("同时存在 10 个以上线程,退出");
return;
}
}
}
}ConcurrentModificationException 异常
在对 Vector 等容器并发地进行迭代修改时,会报 ConcurrentModificationException 异常,关于这个异常将会在后续文章中讲述。
但是在并发容器中不会出现这个问题。
# #2. 并发容器简介
同步容器将所有对容器状态的访问都串行化,以保证线程安全性,这种策略会严重降低并发性。
Java 1.5 后提供了多种并发容器,使用并发容器来替代同步容器,可以极大地提高伸缩性并降低风险。
J.U.C 包中提供了几个非常有用的并发容器作为线程安全的容器:
| 并发容器 | 对应的普通容器 | 描述 |
|---|---|---|
ConcurrentHashMap |
HashMap |
Java 1.8 之前采用分段锁机制细化锁粒度,降低阻塞,从而提高并发性;Java 1.8 之后基于 CAS 实现。 |
ConcurrentSkipListMap |
SortedMap |
基于跳表实现的 |
CopyOnWriteArrayList |
ArrayList |
|
CopyOnWriteArraySet |
Set |
基于 CopyOnWriteArrayList 实现。 |
ConcurrentSkipListSet |
SortedSet |
基于 ConcurrentSkipListMap 实现。 |
ConcurrentLinkedQueue |
Queue |
线程安全的无界队列。底层采用单链表。支持 FIFO。 |
ConcurrentLinkedDeque |
Deque |
线程安全的无界双端队列。底层采用双向链表。支持 FIFO 和 FILO。 |
ArrayBlockingQueue |
Queue |
数组实现的阻塞队列。 |
LinkedBlockingQueue |
Queue |
链表实现的阻塞队列。 |
LinkedBlockingDeque |
Deque |
双向链表实现的双端阻塞队列。 |
J.U.C 包中提供的并发容器命名一般分为三类:
-
Concurrent- 这类型的锁竞争相对于 `CopyOnWrite` 要高一些,但写操作代价要小一些。 - 此外,`Concurrent` 往往提供了较低的遍历一致性,即:当利用迭代器遍历时,如果容器发生修改,迭代器仍然可以继续进行遍历。代价就是,在获取容器大小 `size()` ,容器是否为空等方法,不一定完全精确,但这是为了获取并发吞吐量的设计取舍,可以理解。与之相比,如果是使用同步容器,就会出现 `fail-fast` 问题,即:检测到容器在遍历过程中发生了修改,则抛出 `ConcurrentModificationException`,不再继续遍历。 - `CopyOnWrite` - 一个线程写,多个线程读。读操作时不加锁,写操作时通过在副本上加锁保证并发安全,空间开销较大。 - `Blocking` - 内部实现一般是基于锁,提供阻塞队列的能力。 ❌ 错误示例,产生 `ConcurrentModificationException` 异常: ```java public void removeKeys(Map<String, Object> map, final String... keys) { map.keySet().removeIf(key -> ArrayUtil.contains(keys, key)); }
❌ 错误示例,产生 ConcurrentModificationException 异常:
public static <K, V> Map<K, V> removeKeys(Map<String, Object> map, final String... keys) {
for (K key : keys) {
map.remove(key);
}
return map;
}# #2.1. 并发场景下的 Map
如果对数据有强一致要求,则需使用 Hashtable ;在大部分场景通常都是弱一致性的情况下,使用 ConcurrentHashMap 即可;如果数据量在千万级别,且存在大量增删改操作,则可以考虑使用 ConcurrentSkipListMap 。
# #2.2. 并发场景下的 List
读多写少用 CopyOnWriteArrayList 。
写多读少用 ConcurrentLinkedQueue ,但由于是无界的,要有容量限制,避免无限膨胀,导致内存溢出。
# #3. Map
Map 接口的两个实现是 ConcurrentHashMap 和 ConcurrentSkipListMap,它们从应用的角度来看,主要区别在于 ConcurrentHashMap 的 key 是无序的,而 ConcurrentSkipListMap 的 key 是有序的。所以如果你需要保证 key 的顺序,就只能使用 ConcurrentSkipListMap。
使用 ConcurrentHashMap 和 ConcurrentSkipListMap 需要注意的地方是,它们的 key 和 value 都不能为空,否则会抛出 NullPointerException 这个运行时异常。
# #3.1. ConcurrentHashMap
ConcurrentHashMap 是线程安全的 HashMap ,用于替代 Hashtable 。
# # ConcurrentHashMap 的特性
ConcurrentHashMap 实现了 ConcurrentMap 接口,而 ConcurrentMap 接口扩展了 Map 接口。
public class ConcurrentHashMap<K,V> extends AbstractMap<K,V>
implements ConcurrentMap<K,V>, Serializable {
// ...
}ConcurrentHashMap 的实现包含了 HashMap 所有的基本特性,如:数据结构、读写策略等。
ConcurrentHashMap 没有实现对 Map 加锁以提供独占访问。因此无法通过在客户端加锁的方式来创建新的原子操作。但是,一些常见的复合操作,如:“若没有则添加”、“若相等则移除”、“若相等则替换”,都已经实现为原子操作,并且是围绕 ConcurrentMap 的扩展接口而实现。
public interface ConcurrentMap<K, V> extends Map<K, V> {
// 仅当 K 没有相应的映射值才插入
V putIfAbsent(K key, V value);
// 仅当 K 被映射到 V 时才移除
boolean remove(Object key, Object value);
// 仅当 K 被映射到 oldValue 时才替换为 newValue
boolean replace(K key, V oldValue, V newValue);
// 仅当 K 被映射到某个值时才替换为 newValue
V replace(K key, V value);
}不同于 Hashtable , ConcurrentHashMap 提供的迭代器不会抛出 ConcurrentModificationException ,因此不需要在迭代过程中对容器加锁。
🔔 注意:一些需要对整个
Map进行计算的方法,如size和isEmpty,由于返回的结果在计算时可能已经过期,所以并非实时的精确值。这是一种策略上的权衡,在并发环境下,这类方法由于总在不断变化,所以获取其实时精确值的意义不大。ConcurrentHashMap弱化这类方法,以换取更重要操作(如:get、put、containesKey、remove等)的性能。
# #ConcurrentHashMap 的用法
示例:不会出现 ConcurrentModificationException
ConcurrentHashMap 的基本操作与 HashMap 的用法基本一样。不同于 HashMap 、 Hashtable , ConcurrentHashMap 提供的迭代器不会抛出 ConcurrentModificationException ,因此不需要在迭代过程中对容器加锁。
public class ConcurrentHashMapDemo {
public static void main(String[] args) throws InterruptedException {
// HashMap 在并发迭代访问时会抛出 ConcurrentModificationException 异常
// Map<Integer, Character> map = new HashMap<>();
Map<Integer, Character> map = new ConcurrentHashMap<>();
Thread wthread = new Thread(() -> {
System.out.println("写操作线程开始执行");
for (int i = 0; i < 26; i++) {
map.put(i, (char) ('a' + i));
}
});
Thread rthread = new Thread(() -> {
System.out.println("读操作线程开始执行");
for (Integer key : map.keySet()) {
System.out.println(key + " - " + map.get(key));
}
});
wthread.start();
rthread.start();
Thread.sleep(1000);
}
}# #ConcurrentHashMap 的原理
ConcurrentHashMap一直在演进,尤其在 Java 1.7 和 Java 1.8,其数据结构和并发机制有很大的差异。
- Java 1.7
- 数据结构:数组+单链表
- 并发机制:采用分段锁机制细化锁粒度,降低阻塞,从而提高并发性。
- Java 1.8
- 数据结构:数组+单链表+红黑树
- 并发机制:取消分段锁,之后基于 CAS + synchronized 实现。
# #Java 1.7 的实现
分段锁,是将内部进行分段(Segment),里面是 HashEntry 数组,和 HashMap 类似,哈希相同的条目也是以链表形式存放。 HashEntry 内部使用 volatile 的 value 字段来保证可见性,也利用了不可变对象的机制,以改进利用 Unsafe 提供的底层能力,比如 volatile access,去直接完成部分操作,以最优化性能,毕竟 Unsafe 中的很多操作都是 JVM intrinsic 优化过的。
在进行并发写操作时, ConcurrentHashMap 会获取可重入锁( ReentrantLock ),以保证数据一致性。所以,在并发修改期间,相应 Segment 是被锁定的。
public class ConcurrentHashMap<K, V> extends AbstractMap<K, V>
implements ConcurrentMap<K, V>, Serializable {
// 将整个hashmap分成几个小的map,每个segment都是一个锁;与hashtable相比,这么设计的目的是对于put, remove等操作,可以减少并发冲突,对
// 不属于同一个片段的节点可以并发操作,大大提高了性能
final Segment<K,V>[] segments;
// 本质上Segment类就是一个小的hashmap,里面table数组存储了各个节点的数据,继承了ReentrantLock, 可以作为互拆锁使用
static final class Segment<K,V> extends ReentrantLock implements Serializable {
transient volatile HashEntry<K,V>[] table;
transient int count;
}
// 基本节点,存储Key, Value值
static final class HashEntry<K,V> {
final int hash;
final K key;
volatile V value;
volatile HashEntry<K,V> next;
}
}# #Java 1.8 的实现
- 数据结构改进:与 HashMap 一样,将原先 数组+单链表 的数据结构,变更为 数组+单链表+红黑树 的结构。当出现哈希冲突时,数据会存入数组指定桶的单链表,当链表长度达到 8,则将其转换为红黑树结构,这样其查询的时间复杂度可以降低到 $$O (logN)$$,以改进性能。
- 并发机制改进:
- 取消 segments 字段,直接采用
transient volatile HashEntry<K,V>[] table保存数据,采用 table 数组元素作为锁,从而实现了对每一行数据进行加锁,进一步减少并发冲突的概率。 - 使用 CAS +
sychronized操作,在特定场景进行无锁并发操作。使用 Unsafe、LongAdder 之类底层手段,进行极端情况的优化。现代 JDK 中,synchronized 已经被不断优化,可以不再过分担心性能差异,另外,相比于 ReentrantLock,它可以减少内存消耗,这是个非常大的优势。
- 取消 segments 字段,直接采用
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
// 如果table为空,初始化;否则,根据hash值计算得到数组索引i,如果tab[i]为空,直接新建节点Node即可。注:tab[i]实质为链表或者红黑树的首节点。
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
// 如果tab[i]不为空并且hash值为MOVED,说明该链表正在进行transfer操作,返回扩容完成后的table。
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
// 针对首个节点进行加锁操作,而不是segment,进一步减少线程冲突
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
// 如果在链表中找到值为key的节点e,直接设置e.val = value即可。
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
// 如果没有找到值为key的节点,直接新建Node并加入链表即可。
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
// 如果首节点为TreeBin类型,说明为红黑树结构,执行putTreeVal操作。
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
// 如果节点数>=8,那么转换链表结构为红黑树结构。
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
// 计数增加1,有可能触发transfer操作(扩容)。
addCount(1L, binCount);
return null;
}# #ConcurrentHashMap 的实战
# #ConcurrentHashMap 错误示例
//线程个数
private static int THREAD_COUNT = 10;
//总元素数量
private static int ITEM_COUNT = 1000;
public static void main(String[] args) throws InterruptedException {
ConcurrentHashMap<String, Long> concurrentHashMap = getData(ITEM_COUNT - 100);
//初始900个元素
System.out.println("init size:" + concurrentHashMap.size());
ForkJoinPool forkJoinPool = new ForkJoinPool(THREAD_COUNT);
//使用线程池并发处理逻辑
forkJoinPool.execute(() -> IntStream.rangeClosed(1, 10).parallel().forEach(i -> {
//查询还需要补充多少个元素
int gap = ITEM_COUNT - concurrentHashMap.size();
System.out.println("gap size:" + gap);
//补充元素
concurrentHashMap.putAll(getData(gap));
}));
//等待所有任务完成
forkJoinPool.shutdown();
forkJoinPool.awaitTermination(1, TimeUnit.HOURS);
//最后元素个数会是1000吗?
System.out.println("finish size:" + concurrentHashMap.size());
}
private static ConcurrentHashMap<String, Long> getData(int count) {
return LongStream.rangeClosed(1, count)
.boxed()
.collect(
Collectors.toConcurrentMap(
i -> UUID.randomUUID().toString(),
i -> i,
(o1, o2) -> o1,
ConcurrentHashMap::new));
}初始大小 900 符合预期,还需要填充 100 个元素。
预期结果为 1000 个元素,实际大于 1000 个元素。
【分析】
ConcurrentHashMap 对外提供的方法或能力的限制:
- 使用了 ConcurrentHashMap,不代表对它的多个操作之间的状态是一致的,是没有其他线程在操作它的,如果需要确保需要手动加锁。
- 诸如 size、isEmpty 和 containsValue 等聚合方法,在并发情况下可能会反映 ConcurrentHashMap 的中间状态。因此在并发情况下,这些方法的返回值只能用作参考,而不能用于流程控制。显然,利用 size 方法计算差异值,是一个流程控制。
- 诸如 putAll 这样的聚合方法也不能确保原子性,在 putAll 的过程中去获取数据可能会获取到部分数据。
# #ConcurrentHashMap 错误示例修正 1.0 版
通过 synchronized 加锁,当然可以保证数据一致性,但是牺牲了 ConcurrentHashMap 的性能,没哟真正发挥出 ConcurrentHashMap 的特性。
//线程个数
private static int THREAD_COUNT = 10;
//总元素数量
private static int ITEM_COUNT = 1000;
public static void main(String[] args) throws InterruptedException {
ConcurrentHashMap<String, Long> concurrentHashMap = getData(ITEM_COUNT - 100);
//初始900个元素
System.out.println("init size:" + concurrentHashMap.size());
ForkJoinPool forkJoinPool = new ForkJoinPool(THREAD_COUNT);
//使用线程池并发处理逻辑
forkJoinPool.execute(() -> IntStream.rangeClosed(1, 10).parallel().forEach(i -> {
//查询还需要补充多少个元素
synchronized (concurrentHashMap) {
int gap = ITEM_COUNT - concurrentHashMap.size();
System.out.println("gap size:" + gap);
//补充元素
concurrentHashMap.putAll(getData(gap));
}
}));
//等待所有任务完成
forkJoinPool.shutdown();
forkJoinPool.awaitTermination(1, TimeUnit.HOURS);
//最后元素个数会是1000吗?
System.out.println("finish size:" + concurrentHashMap.size());
}
private static ConcurrentHashMap<String, Long> getData(int count) {
return LongStream.rangeClosed(1, count)
.boxed()
.collect(
Collectors.toConcurrentMap(
i -> UUID.randomUUID().toString(),
i -> i,
(o1, o2) -> o1,
ConcurrentHashMap::new));
}# #ConcurrentHashMap 错误示例修正 2.0 版
//循环次数
private static int LOOP_COUNT = 10000000;
//线程个数
private static int THREAD_COUNT = 10;
//总元素数量
private static int ITEM_COUNT = 1000;
public static void main(String[] args) throws InterruptedException {
StopWatch stopWatch = new StopWatch();
stopWatch.start("normaluse");
Map<String, Long> normaluse = normaluse();
stopWatch.stop();
Assert.isTrue(normaluse.size() == ITEM_COUNT, "normaluse size error");
Assert.isTrue(normaluse.values().stream()
.mapToLong(aLong -> aLong).reduce(0, Long::sum) == LOOP_COUNT
, "normaluse count error");
stopWatch.start("gooduse");
Map<String, Long> gooduse = gooduse();
stopWatch.stop();
Assert.isTrue(gooduse.size() == ITEM_COUNT, "gooduse size error");
Assert.isTrue(gooduse.values().stream()
.mapToLong(l -> l)
.reduce(0, Long::sum) == LOOP_COUNT
, "gooduse count error");
System.out.println(stopWatch.prettyPrint());
}
private static Map<String, Long> normaluse() throws InterruptedException {
ConcurrentHashMap<String, Long> freqs = new ConcurrentHashMap<>(ITEM_COUNT);
ForkJoinPool forkJoinPool = new ForkJoinPool(THREAD_COUNT);
forkJoinPool.execute(() -> IntStream.rangeClosed(1, LOOP_COUNT).parallel().forEach(i -> {
String key = "item" + ThreadLocalRandom.current().nextInt(ITEM_COUNT);
synchronized (freqs) {
if (freqs.containsKey(key)) {
freqs.put(key, freqs.get(key) + 1);
} else {
freqs.put(key, 1L);
}
}
}
));
forkJoinPool.shutdown();
forkJoinPool.awaitTermination(1, TimeUnit.HOURS);
return freqs;
}
private static Map<String, Long> gooduse() throws InterruptedException {
ConcurrentHashMap<String, LongAdder> freqs = new ConcurrentHashMap<>(ITEM_COUNT);
ForkJoinPool forkJoinPool = new ForkJoinPool(THREAD_COUNT);
forkJoinPool.execute(() -> IntStream.rangeClosed(1, LOOP_COUNT).parallel().forEach(i -> {
String key = "item" + ThreadLocalRandom.current().nextInt(ITEM_COUNT);
freqs.computeIfAbsent(key, k -> new LongAdder()).increment();
}
));
forkJoinPool.shutdown();
forkJoinPool.awaitTermination(1, TimeUnit.HOURS);
return freqs.entrySet().stream()
.collect(Collectors.toMap(
e -> e.getKey(),
e -> e.getValue().longValue())
);
}# #4. List
# #4.1. CopyOnWriteArrayList
CopyOnWriteArrayList 是线程安全的 ArrayList 。 CopyOnWrite 字面意思为写的时候会将共享变量新复制一份出来。复制的好处在于读操作是无锁的(也就是无阻塞)。
CopyOnWriteArrayList 仅适用于写操作非常少的场景,而且能够容忍读写的短暂不一致。如果读写比例均衡或者有大量写操作的话,使用 CopyOnWriteArrayList 的性能会非常糟糕。
# #CopyOnWriteArrayList 原理
CopyOnWriteArrayList 内部维护了一个数组,成员变量 array 就指向这个内部数组,所有的读操作都是基于 array 进行的,如下图所示,迭代器 Iterator 遍历的就是 array 数组。
- lock - 执行写时复制操作,需要使用可重入锁加锁
- array - 对象数组,用于存放元素
/** The lock protecting all mutators */
final transient ReentrantLock lock = new ReentrantLock();
/** The array, accessed only via getArray/setArray. */
private transient volatile Object[] array;
(1)读操作
在 CopyOnWriteAarrayList 中,读操作不同步,因为它们在内部数组的快照上工作,所以多个迭代器可以同时遍历而不会相互阻塞(图 1,2,4)。
CopyOnWriteArrayList 的读操作是不用加锁的,性能很高。
public E get(int index) {
return get(getArray(), index);
}
private E get(Object[] a, int index) {
return (E) a[index];
}(2)写操作
所有的写操作都是同步的。他们在备份数组(图 3)的副本上工作。写操作完成后,后备阵列将被替换为复制的阵列,并释放锁定。支持数组变得易变,所以替换数组的调用是原子(图 5)。
写操作后创建的迭代器将能够看到修改的结构(图 6,7)。
写时复制集合返回的迭代器不会抛出 ConcurrentModificationException ,因为它们在数组的快照上工作,并且无论后续的修改(2,4)如何,都会像迭代器创建时那样完全返回元素。
添加操作 - 添加的逻辑很简单,先将原容器 copy 一份,然后在新副本上执行写操作,之后再切换引用。当然此过程是要加锁的。
public boolean add(E e) {
//ReentrantLock加锁,保证线程安全
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
//拷贝原容器,长度为原容器长度加一
Object[] newElements = Arrays.copyOf(elements, len + 1);
//在新副本上执行添加操作
newElements[len] = e;
//将原容器引用指向新副本
setArray(newElements);
return true;
} finally {
//解锁
lock.unlock();
}
}删除操作 - 删除操作同理,将除要删除元素之外的其他元素拷贝到新副本中,然后切换引用,将原容器引用指向新副本。同属写操作,需要加锁。
public E remove(int index) {
//加锁
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
E oldValue = get(elements, index);
int numMoved = len - index - 1;
if (numMoved == 0)
//如果要删除的是列表末端数据,拷贝前len-1个数据到新副本上,再切换引用
setArray(Arrays.copyOf(elements, len - 1));
else {
//否则,将除要删除元素之外的其他元素拷贝到新副本中,并切换引用
Object[] newElements = new Object[len - 1];
System.arraycopy(elements, 0, newElements, 0, index);
System.arraycopy(elements, index + 1, newElements, index,
numMoved);
setArray(newElements);
}
return oldValue;
} finally {
//解锁
lock.unlock();
}
}# #CopyOnWriteArrayList 示例
public class CopyOnWriteArrayListDemo {
static class ReadTask implements Runnable {
List<String> list;
ReadTask(List<String> list) {
this.list = list;
}
public void run() {
for (String str : list) {
System.out.println(str);
}
}
}
static class WriteTask implements Runnable {
List<String> list;
int index;
WriteTask(List<String> list, int index) {
this.list = list;
this.index = index;
}
public void run() {
list.remove(index);
list.add(index, "write_" + index);
}
}
public void run() {
final int NUM = 10;
// ArrayList 在并发迭代访问时会抛出 ConcurrentModificationException 异常
// List<String> list = new ArrayList<>();
CopyOnWriteArrayList<String> list = new CopyOnWriteArrayList<>();
for (int i = 0; i < NUM; i++) {
list.add("main_" + i);
}
ExecutorService executorService = Executors.newFixedThreadPool(NUM);
for (int i = 0; i < NUM; i++) {
executorService.execute(new ReadTask(list));
executorService.execute(new WriteTask(list, i));
}
executorService.shutdown();
}
public static void main(String[] args) {
new CopyOnWriteArrayListDemo().run();
}
}# #CopyOnWriteArrayList 实战
@Slf4j
public class WrongCopyOnWriteList {
public static void main(String[] args) {
testRead();
testWrite();
}
public static Map testWrite() {
List<Integer> copyOnWriteArrayList = new CopyOnWriteArrayList<>();
List<Integer> synchronizedList = Collections.synchronizedList(new ArrayList<>());
StopWatch stopWatch = new StopWatch();
int loopCount = 100000;
stopWatch.start("Write:copyOnWriteArrayList");
IntStream.rangeClosed(1, loopCount)
.parallel()
.forEach(__ -> copyOnWriteArrayList.add(ThreadLocalRandom.current().nextInt(loopCount)));
stopWatch.stop();
stopWatch.start("Write:synchronizedList");
IntStream.rangeClosed(1, loopCount)
.parallel()
.forEach(__ -> synchronizedList.add(ThreadLocalRandom.current().nextInt(loopCount)));
stopWatch.stop();
log.info(stopWatch.prettyPrint());
Map result = new HashMap();
result.put("copyOnWriteArrayList", copyOnWriteArrayList.size());
result.put("synchronizedList", synchronizedList.size());
return result;
}
private static void addAll(List<Integer> list) {
list.addAll(IntStream.rangeClosed(1, 1000000).boxed().collect(Collectors.toList()));
}
public static Map testRead() {
List<Integer> copyOnWriteArrayList = new CopyOnWriteArrayList<>();
List<Integer> synchronizedList = Collections.synchronizedList(new ArrayList<>());
addAll(copyOnWriteArrayList);
addAll(synchronizedList);
StopWatch stopWatch = new StopWatch();
int loopCount = 1000000;
int count = copyOnWriteArrayList.size();
stopWatch.start("Read:copyOnWriteArrayList");
IntStream.rangeClosed(1, loopCount)
.parallel()
.forEach(__ -> copyOnWriteArrayList.get(ThreadLocalRandom.current().nextInt(count)));
stopWatch.stop();
stopWatch.start("Read:synchronizedList");
IntStream.range(0, loopCount)
.parallel()
.forEach(__ -> synchronizedList.get(ThreadLocalRandom.current().nextInt(count)));
stopWatch.stop();
log.info(stopWatch.prettyPrint());
Map result = new HashMap();
result.put("copyOnWriteArrayList", copyOnWriteArrayList.size());
result.put("synchronizedList", synchronizedList.size());
return result;
}
}读性能差不多是写性能的一百倍。
# #5. Set
Set 接口的两个实现是 CopyOnWriteArraySet 和 ConcurrentSkipListSet,使用场景可以参考前面讲述的 CopyOnWriteArrayList 和 ConcurrentSkipListMap,它们的原理都是一样的。
# #6. Queue
Java 并发包里面 Queue 这类并发容器是最复杂的,你可以从以下两个维度来分类。一个维度是阻塞与非阻塞,所谓阻塞指的是:当队列已满时,入队操作阻塞;当队列已空时,出队操作阻塞。另一个维度是单端与双端,单端指的是只能队尾入队,队首出队;而双端指的是队首队尾皆可入队出队。Java 并发包里阻塞队列都用 Blocking 关键字标识,单端队列使用 Queue 标识,双端队列使用 Deque 标识。
# #6.1. BlockingQueue
BlockingQueue 顾名思义,是一个阻塞队列。 BlockingQueue 基本都是基于锁实现。在 BlockingQueue 中,当队列已满时,入队操作阻塞;当队列已空时,出队操作阻塞。
BlockingQueue 接口定义如下:
public interface BlockingQueue<E> extends Queue<E> {}核心 API:
// 获取并移除队列头结点,如果必要,其会等待直到队列出现元素
E take() throws InterruptedException;
// 插入元素,如果队列已满,则等待直到队列出现空闲空间
void put(E e) throws InterruptedException;BlockingQueue 对插入操作、移除操作、获取元素操作提供了四种不同的方法用于不同的场景中使用:
- 抛出异常;
- 返回特殊值(
null或true/false,取决于具体的操作); - 阻塞等待此操作,直到这个操作成功;
- 阻塞等待此操作,直到成功或者超时指定时间。
总结如下:
| Throws exception | Special value | Blocks | Times out | |
|---|---|---|---|---|
| Insert | add(e) | offer(e) | put(e) | offer(e, time, unit) |
| Remove | remove() | poll() | take() | poll(time, unit) |
| Examine | element() | peek() | not applicable | not applicable |
BlockingQueue 的各个实现类都遵循了这些规则。
BlockingQueue 不接受 null 值元素。
JDK 提供了以下阻塞队列:
ArrayBlockingQueue- 一个由数组结构组成的有界阻塞队列。LinkedBlockingQueue- 一个由链表结构组成的有界阻塞队列。PriorityBlockingQueue- 一个支持优先级排序的无界阻塞队列。SynchronousQueue- 一个不存储元素的阻塞队列。DelayQueue- 一个使用优先级队列实现的无界阻塞队列。LinkedTransferQueue- 一个由链表结构组成的无界阻塞队列。
BlockingQueue 基本都是基于锁实现。
# #6.2. PriorityBlockingQueue 类
PriorityBlockingQueue 类定义如下:
public class PriorityBlockingQueue<E> extends AbstractQueue<E>
implements BlockingQueue<E>, java.io.Serializable {}# #PriorityBlockingQueue 要点
PriorityBlockingQueue可以视为PriorityQueue的线程安全版本。PriorityBlockingQueue实现了BlockingQueue,也是一个阻塞队列。PriorityBlockingQueue实现了Serializable,支持序列化。PriorityBlockingQueue不接受null值元素。PriorityBlockingQueue的插入操作put方法不会 block,因为它是无界队列(take 方法在队列为空的时候会阻塞)。
# #PriorityBlockingQueue 原理
PriorityBlockingQueue 有两个重要成员:
private transient Object[] queue;
private final ReentrantLock lock;queue是一个Object数组,用于保存PriorityBlockingQueue的元素。- 而可重入锁
lock则用于在执行插入、删除操作时,保证这个方法在当前线程释放锁之前,其他线程不能访问。
PriorityBlockingQueue 的容量虽然有初始化大小,但是不限制大小,如果当前容量已满,插入新元素时会自动扩容。
# #6.3. ArrayBlockingQueue 类
ArrayBlockingQueue 是由数组结构组成的有界阻塞队列。
# #ArrayBlockingQueue 要点
ArrayBlockingQueue 类定义如下:
public class ArrayBlockingQueue<E> extends AbstractQueue<E>
implements BlockingQueue<E>, java.io.Serializable {
// 数组的大小就决定了队列的边界,所以初始化时必须指定容量
public ArrayBlockingQueue(int capacity) { //... }
public ArrayBlockingQueue(int capacity, boolean fair) { //... }
public ArrayBlockingQueue(int capacity, boolean fair, Collection<? extends E> c) { //... }
}说明:
ArrayBlockingQueue实现了BlockingQueue,也是一个阻塞队列。ArrayBlockingQueue实现了Serializable,支持序列化。ArrayBlockingQueue是基于数组实现的有界阻塞队列。所以初始化时必须指定容量。
# #ArrayBlockingQueue 原理
ArrayBlockingQueue 的重要成员如下:
// 用于存放元素的数组
final Object[] items;
// 下一次读取操作的位置
int takeIndex;
// 下一次写入操作的位置
int putIndex;
// 队列中的元素数量
int count;
// 以下几个就是控制并发用的同步器
final ReentrantLock lock;
private final Condition notEmpty;
private final Condition notFull;ArrayBlockingQueue 内部以 final 的数组保存数据,数组的大小就决定了队列的边界。
ArrayBlockingQueue 实现并发同步的原理就是,读操作和写操作都需要获取到 AQS 独占锁才能进行操作。
- 如果队列为空,这个时候读操作的线程进入到读线程队列排队,等待写线程写入新的元素,然后唤醒读线程队列的第一个等待线程。
- 如果队列已满,这个时候写操作的线程进入到写线程队列排队,等待读线程将队列元素移除,然后唤醒写线程队列的第一个等待线程。
对于 ArrayBlockingQueue ,我们可以在构造的时候指定以下三个参数:
- 队列容量,其限制了队列中最多允许的元素个数;
- 指定独占锁是公平锁还是非公平锁。非公平锁的吞吐量比较高,公平锁可以保证每次都是等待最久的线程获取到锁;
- 可以指定用一个集合来初始化,将此集合中的元素在构造方法期间就先添加到队列中。
# #6.4. LinkedBlockingQueue 类
LinkedBlockingQueue 是由链表结构组成的有界阻塞队列。容易被误解为无边界,但其实其行为和内部代码都是基于有界的逻辑实现的,只不过如果我们没有在创建队列时就指定容量,那么其容量限制就自动被设置为 Integer.MAX_VALUE ,成为了无界队列。
# #LinkedBlockingQueue 要点
LinkedBlockingQueue 类定义如下:
public class LinkedBlockingQueue<E> extends AbstractQueue<E>
implements BlockingQueue<E>, java.io.Serializable {}LinkedBlockingQueue实现了BlockingQueue,也是一个阻塞队列。LinkedBlockingQueue实现了Serializable,支持序列化。LinkedBlockingQueue是基于单链表实现的阻塞队列,可以当做无界队列也可以当做有界队列来使用。LinkedBlockingQueue中元素按照插入顺序保存(FIFO)。
# #LinkedBlockingQueue 原理
LinkedBlockingQueue 中的重要数据结构:
// 队列容量
private final int capacity;
// 队列中的元素数量
private final AtomicInteger count = new AtomicInteger(0);
// 队头
private transient Node<E> head;
// 队尾
private transient Node<E> last;
// take, poll, peek 等读操作的方法需要获取到这个锁
private final ReentrantLock takeLock = new ReentrantLock();
// 如果读操作的时候队列是空的,那么等待 notEmpty 条件
private final Condition notEmpty = takeLock.newCondition();
// put, offer 等写操作的方法需要获取到这个锁
private final ReentrantLock putLock = new ReentrantLock();
// 如果写操作的时候队列是满的,那么等待 notFull 条件
private final Condition notFull = putLock.newCondition();这里用了两对 Lock 和 Condition ,简单介绍如下:
takeLock和notEmpty搭配:如果要获取(take)一个元素,需要获取takeLock锁,但是获取了锁还不够,如果队列此时为空,还需要队列不为空(notEmpty)这个条件(Condition)。putLock需要和notFull搭配:如果要插入(put)一个元素,需要获取putLock锁,但是获取了锁还不够,如果队列此时已满,还需要队列不是满的(notFull)这个条件(Condition)。
# #6.5. SynchronousQueue 类
SynchronousQueue 是不存储元素的阻塞队列。每个删除操作都要等待插入操作,反之每个插入操作也都要等待删除动作。那么这个队列的容量是多少呢?是 1 吗?其实不是的,其内部容量是 0。
SynchronousQueue 定义如下:
public class SynchronousQueue<E> extends AbstractQueue<E>
implements BlockingQueue<E>, java.io.Serializable {}SynchronousQueue 这个类,在线程池的实现类 ScheduledThreadPoolExecutor 中得到了应用。
SynchronousQueue 的队列其实是虚的,即队列容量为 0。数据必须从某个写线程交给某个读线程,而不是写到某个队列中等待被消费。
SynchronousQueue 中不能使用 peek 方法(在这里这个方法直接返回 null),peek 方法的语义是只读取不移除,显然,这个方法的语义是不符合 SynchronousQueue 的特征的。
SynchronousQueue 也不能被迭代,因为根本就没有元素可以拿来迭代的。
虽然 SynchronousQueue 间接地实现了 Collection 接口,但是如果你将其当做 Collection 来用的话,那么集合是空的。
当然, SynchronousQueue 也不允许传递 null 值的(并发包中的容器类好像都不支持插入 null 值,因为 null 值往往用作其他用途,比如用于方法的返回值代表操作失败)。
# #6.6. ConcurrentLinkedDeque 类
Deque 的侧重点是支持对队列头尾都进行插入和删除,所以提供了特定的方法,如:
- 尾部插入时需要的
addLast(e)、offerLast(e)。 - 尾部删除所需要的
removeLast()、pollLast()。
# #6.7. Queue 的并发应用
Queue 被广泛使用在生产者 - 消费者场景。而在并发场景,利用 BlockingQueue 的阻塞机制,可以减少很多并发协调工作。
这么多并发 Queue 的实现,如何选择呢?
- 考虑应用场景中对队列边界的要求。
ArrayBlockingQueue是有明确的容量限制的,而LinkedBlockingQueue则取决于我们是否在创建时指定,SynchronousQueue则干脆不能缓存任何元素。 - 从空间利用角度,数组结构的
ArrayBlockingQueue要比LinkedBlockingQueue紧凑,因为其不需要创建所谓节点,但是其初始分配阶段就需要一段连续的空间,所以初始内存需求更大。 - 通用场景中,
LinkedBlockingQueue的吞吐量一般优于ArrayBlockingQueue,因为它实现了更加细粒度的锁操作。 ArrayBlockingQueue实现比较简单,性能更好预测,属于表现稳定的 “选手”。- 可能令人意外的是,很多时候
SynchronousQueue的性能表现,往往大大超过其他实现,尤其是在队列元素较小的场景。
# Java 线程池
📦 本文以及示例源码已归档在 javacore(opens new window)
- \1. 简介
- \2. Executor 框架
- \3. ThreadPoolExecutor
- \4. Executors
- \5. 线程池最佳实践
- 6. 参考资料
# #1. 简介
# #1.1. 什么是线程池
线程池是一种多线程处理形式,处理过程中将任务添加到队列,然后在创建线程后自动启动这些任务。
# #1.2. 为什么要用线程池
如果并发请求数量很多,但每个线程执行的时间很短,就会出现频繁的创建和销毁线程。如此一来,会大大降低系统的效率,可能频繁创建和销毁线程的时间、资源开销要大于实际工作的所需。
正是由于这个问题,所以有必要引入线程池。使用 线程池的好处 有以下几点:
- 降低资源消耗 - 通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
- 提高响应速度 - 当任务到达时,任务可以不需要等到线程创建就能立即执行。
- 提高线程的可管理性 - 线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。但是要做到合理的利用线程池,必须对其原理了如指掌。
# #2. Executor 框架
Executor 框架是一个根据一组执行策略调用,调度,执行和控制的异步任务的框架,目的是提供一种将” 任务提交” 与” 任务如何运行” 分离开来的机制。
# #2.1. 核心 API 概述
Executor 框架核心 API 如下:
-
Executor- 运行任务的简单接口。 -
ExecutorService
Executor \- 扩展了 接口。扩展能力: - 支持有返回值的线程; - 支持管理线程的生命周期。 - `ScheduledExecutorService` - 扩展了 `ExecutorService` 接口。扩展能力:支持定期执行任务。 - `AbstractExecutorService` - `ExecutorService` 接口的默认实现。 - `ThreadPoolExecutor` - Executor 框架最核心的类,它继承了 `AbstractExecutorService` 类。 - `ScheduledThreadPoolExecutor` - `ScheduledExecutorService` 接口的实现,一个可定时调度任务的线程池。 - `Executors` - 可以通过调用 `Executors` 的静态工厂方法来创建线程池并返回一个 `ExecutorService` 对象。 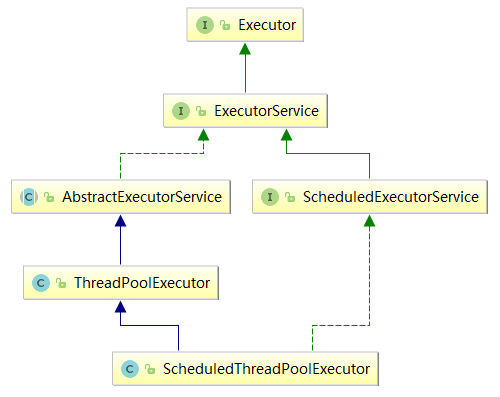 ### [#](https://dunwu.github.io/javacore/concurrent/Java线程池.html#_2-2-executor)2.2. Executor `Executor` 接口中只定义了一个 `execute` 方法,用于接收一个 `Runnable` 对象。 ```java public interface Executor { void execute(Runnable command); }
# #2.3. ExecutorService
ExecutorService 接口继承了 Executor 接口,它还提供了 invokeAll 、 invokeAny 、 shutdown 、 submit 等方法。
public interface ExecutorService extends Executor {
void shutdown();
List<Runnable> shutdownNow();
boolean isShutdown();
boolean isTerminated();
boolean awaitTermination(long timeout, TimeUnit unit)
throws InterruptedException;
<T> Future<T> submit(Callable<T> task);
<T> Future<T> submit(Runnable task, T result);
Future<?> submit(Runnable task);
<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks)
throws InterruptedException;
<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks,
long timeout, TimeUnit unit)
throws InterruptedException;
<T> T invokeAny(Collection<? extends Callable<T>> tasks)
throws InterruptedException, ExecutionException;
<T> T invokeAny(Collection<? extends Callable<T>> tasks,
long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException;
}从其支持的方法定义,不难看出:相比于 Executor 接口, ExecutorService 接口主要的扩展是:
- 支持有返回值的线程 -
sumbit、invokeAll、invokeAny方法中都支持传入Callable对象。 - 支持管理线程生命周期 -
shutdown、shutdownNow、isShutdown等方法。
# #2.4. ScheduledExecutorService
ScheduledExecutorService 接口扩展了 ExecutorService 接口。
它除了支持前面两个接口的所有能力以外,还支持定时调度线程。
public interface ScheduledExecutorService extends ExecutorService {
public ScheduledFuture<?> schedule(Runnable command,
long delay, TimeUnit unit);
public <V> ScheduledFuture<V> schedule(Callable<V> callable,
long delay, TimeUnit unit);
public ScheduledFuture<?> scheduleAtFixedRate(Runnable command,
long initialDelay,
long period,
TimeUnit unit);
public ScheduledFuture<?> scheduleWithFixedDelay(Runnable command,
long initialDelay,
long delay,
TimeUnit unit);
}其扩展的接口提供以下能力:
schedule方法可以在指定的延时后执行一个Runnable或者Callable任务。scheduleAtFixedRate方法和scheduleWithFixedDelay方法可以按照指定时间间隔,定期执行任务。
# #3. ThreadPoolExecutor
java.uitl.concurrent.ThreadPoolExecutor 类是 Executor 框架中最核心的类。所以,本文将着重讲述一下这个类。
# #3.1. 重要字段
ThreadPoolExecutor 有以下重要字段:
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
private static final int COUNT_BITS = Integer.SIZE - 3;
private static final int CAPACITY = (1 << COUNT_BITS) - 1;
// runState is stored in the high-order bits
private static final int RUNNING = -1 << COUNT_BITS;
private static final int SHUTDOWN = 0 << COUNT_BITS;
private static final int STOP = 1 << COUNT_BITS;
private static final int TIDYING = 2 << COUNT_BITS;
private static final int TERMINATED = 3 << COUNT_BITS;参数说明:
-
ctl
\- 关闭状态 。不接受新任务,但可以处理阻塞队列中的任务。 - 在线程池处于 `RUNNING` 状态时,调用 `shutdown` 方法会使线程池进入到该状态。 - `finalize` 方法在执行过程中也会调用 `shutdown` 方法进入该状态。 - `STOP` - **停止状态**。不接受新任务,也不处理队列中的任务。会中断正在处理任务的线程。在线程池处于 `RUNNING` 或 `SHUTDOWN` 状态时,调用 `shutdownNow` 方法会使线程池进入到该状态。 - `TIDYING` - **整理状态**。如果所有的任务都已终止了,`workerCount` (有效线程数) 为 0,线程池进入该状态后会调用 `terminated` 方法进入 `TERMINATED` 状态。 - ``` TERMINATED \- 用于控制线程池的运行状态和线程池中的有效线程数量 。它包含两部分的信息: - 线程池的运行状态 (`runState`) - 线程池内有效线程的数量 (`workerCount`) - 可以看到,`ctl` 使用了 `Integer` 类型来保存,高 3 位保存 `runState`,低 29 位保存 `workerCount`。`COUNT_BITS` 就是 29,`CAPACITY` 就是 1 左移 29 位减 1(29 个 1),这个常量表示 `workerCount` 的上限值,大约是 5 亿。 - 运行状态 - 线程池一共有五种运行状态: - `RUNNING` - **运行状态**。接受新任务,并且也能处理阻塞队列中的任务。 - ``` SHUTDOWN
terminated \- 已终止状态 。在
terminated 方法执行完后进入该状态。默认
TERMINATED 方法中什么也没有做。进入 的条件如下: - 线程池不是 `RUNNING` 状态; - 线程池状态不是 `TIDYING` 状态或 `TERMINATED` 状态; - 如果线程池状态是 `SHUTDOWN` 并且 `workerQueue` 为空; - `workerCount` 为 0; - 设置 `TIDYING` 状态成功。 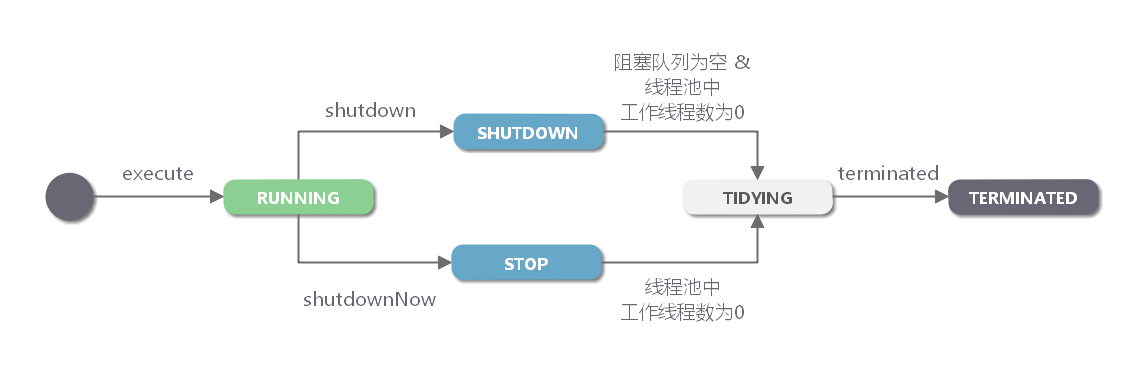 ### [#](https://dunwu.github.io/javacore/concurrent/Java线程池.html#_3-2-构造方法)3.2. 构造方法 `ThreadPoolExecutor` 有四个构造方法,前三个都是基于第四个实现。第四个构造方法定义如下: ```java public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler) {
参数说明:
-
corePoolSize
execute \- 核心线程数量 。当有新任务通过 方法提交时 ,线程池会执行以下判断: - 如果运行的线程数少于 `corePoolSize`,则创建新线程来处理任务,即使线程池中的其他线程是空闲的。 - 如果线程池中的线程数量大于等于 `corePoolSize` 且小于 `maximumPoolSize`,则只有当 `workQueue` 满时才创建新的线程去处理任务; - 如果设置的 `corePoolSize` 和 `maximumPoolSize` 相同,则创建的线程池的大小是固定的。这时如果有新任务提交,若 `workQueue` 未满,则将请求放入 `workQueue` 中,等待有空闲的线程去从 `workQueue` 中取任务并处理; - 如果运行的线程数量大于等于 `maximumPoolSize`,这时如果 `workQueue` 已经满了,则使用 `handler` 所指定的策略来处理任务; - 所以,任务提交时,判断的顺序为 `corePoolSize` => `workQueue` => `maximumPoolSize`。 - ``` maximumPoolSize
\-
最大线程数量
。
- 如果队列满了,并且已创建的线程数小于最大线程数,则线程池会再创建新的线程执行任务。
- 值得注意的是:如果使用了无界的任务队列这个参数就没什么效果。
-
keepAliveTime: 线程保持活动的时间 。 - 当线程池中的线程数量大于 `corePoolSize` 的时候,如果这时没有新的任务提交,核心线程外的线程不会立即销毁,而是会等待,直到等待的时间超过了 `keepAliveTime`。 - 所以,如果任务很多,并且每个任务执行的时间比较短,可以调大这个时间,提高线程的利用率。 - `unit` - **`keepAliveTime` 的时间单位**。有 7 种取值。可选的单位有天(DAYS),小时(HOURS),分钟(MINUTES),毫秒(MILLISECONDS),微秒(MICROSECONDS, 千分之一毫秒)和毫微秒(NANOSECONDS, 千分之一微秒)。 - ``` workQueue
\-
等待执行的任务队列
。用于保存等待执行的任务的阻塞队列。 可以选择以下几个阻塞队列。
- ```
ArrayBlockingQueue
\-
有界阻塞队列
。
- 此队列是**基于数组的先进先出队列(FIFO)**。
- 此队列创建时必须指定大小。
- ```
LinkedBlockingQueue
\-
无界阻塞队列
。
- 此队列是**基于链表的先进先出队列(FIFO)**。
- 如果创建时没有指定此队列大小,则默认为 `Integer.MAX_VALUE`。
- 吞吐量通常要高于 `ArrayBlockingQueue`。
- 使用 `LinkedBlockingQueue` 意味着: `maximumPoolSize` 将不起作用,线程池能创建的最大线程数为 `corePoolSize`,因为任务等待队列是无界队列。
- `Executors.newFixedThreadPool` 使用了这个队列。
- ```
SynchronousQueue
\-
不会保存提交的任务,而是将直接新建一个线程来执行新来的任务
。
- 每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态。
- 吞吐量通常要高于 `LinkedBlockingQueue`。
- `Executors.newCachedThreadPool` 使用了这个队列。
- `PriorityBlockingQueue` - **具有优先级的无界阻塞队列**。
- `threadFactory` - **线程工厂**。可以通过线程工厂给每个创建出来的线程设置更有意义的名字。
- ```
handler
\-
饱和策略
。它是
RejectedExecutionHandler
类型的变量。当队列和线程池都满了,说明线程池处于饱和状态,那么必须采取一种策略处理提交的新任务。线程池支持以下策略:
- `AbortPolicy` - 丢弃任务并抛出异常。这也是默认策略。
- `DiscardPolicy` - 丢弃任务,但不抛出异常。
- `DiscardOldestPolicy` - 丢弃队列最前面的任务,然后重新尝试执行任务(重复此过程)。
- `CallerRunsPolicy` - 直接调用 `run` 方法并且阻塞执行。
- 如果以上策略都不能满足需要,也可以通过实现 `RejectedExecutionHandler` 接口来定制处理策略。如记录日志或持久化不能处理的任务。
# #3.3. execute 方法
默认情况下,创建线程池之后,线程池中是没有线程的,需要提交任务之后才会创建线程。
提交任务可以使用 execute 方法,它是 ThreadPoolExecutor 的核心方法,通过这个方法可以向线程池提交一个任务,交由线程池去执行。
execute 方法工作流程如下:
- 如果
workerCount < corePoolSize,则创建并启动一个线程来执行新提交的任务; - 如果
workerCount >= corePoolSize,且线程池内的阻塞队列未满,则将任务添加到该阻塞队列中; - 如果
workerCount >= corePoolSize && workerCount < maximumPoolSize,且线程池内的阻塞队列已满,则创建并启动一个线程来执行新提交的任务; - 如果
workerCount >= maximumPoolSize,并且线程池内的阻塞队列已满,则根据拒绝策略来处理该任务,默认的处理方式是直接抛异常。
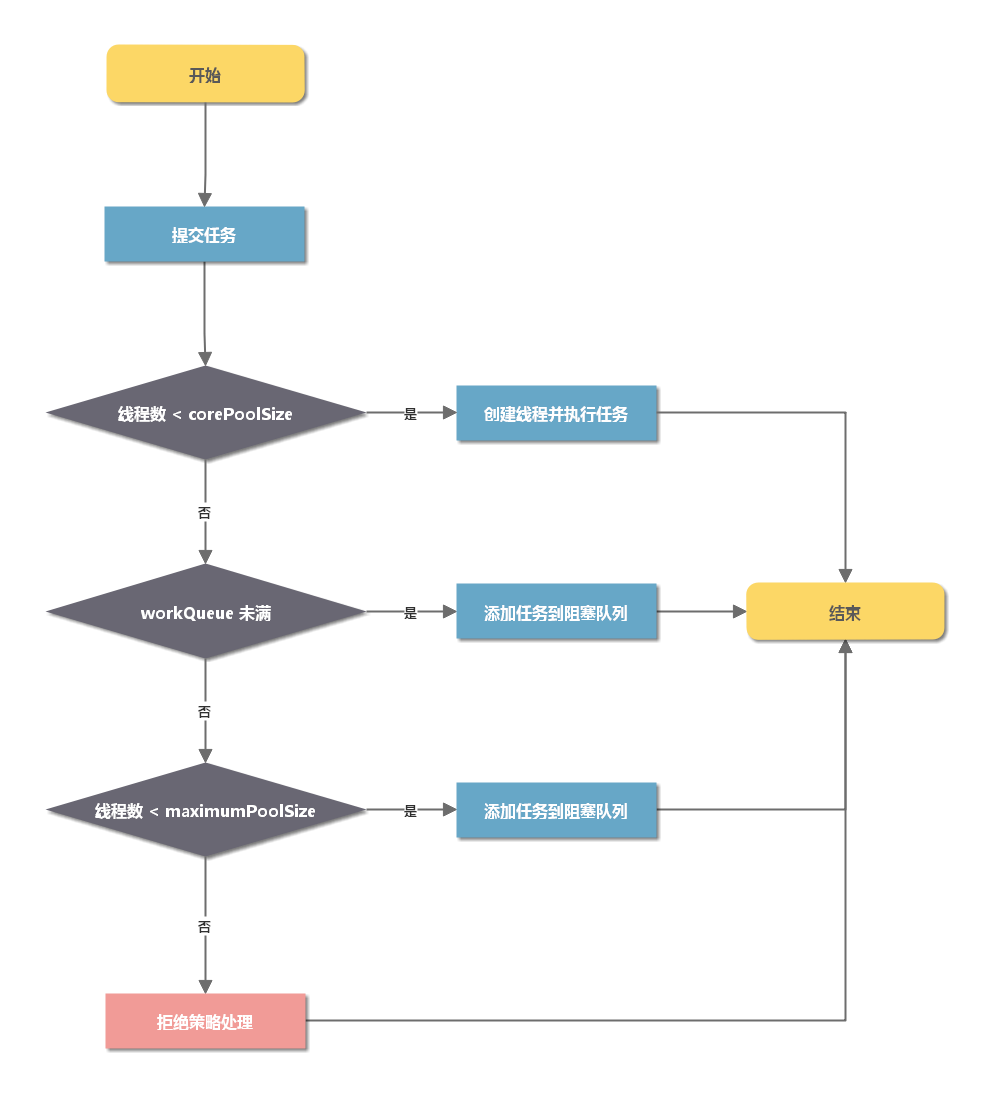
# #3.4. 其他重要方法
在 ThreadPoolExecutor 类中还有一些重要的方法:
-
submit- 类似于execute,但是针对的是有返回值的线程。submit方法是在ExecutorService中声明的方法,在AbstractExecutorService就已经有了具体的实现。ThreadPoolExecutor直接复用AbstractExecutorService的submit方法。 -
shutdown \- 不会立即终止线程池,而是要等所有任务缓存队列中的任务都执行完后才终止,但再也不会接受新的任务。 - 将线程池切换到 `SHUTDOWN` 状态; - 并调用 `interruptIdleWorkers` 方法请求中断所有空闲的 worker; - 最后调用 `tryTerminate` 尝试结束线程池。 - ``` shutdownNow
\- 立即终止线程池,并尝试打断正在执行的任务,并且清空任务缓存队列,返回尚未执行的任务。与
shutdown
方法类似,不同的地方在于:
- 设置状态为 `STOP`;
- 中断所有工作线程,无论是否是空闲的;
- 取出阻塞队列中没有被执行的任务并返回。
-
isShutdown- 调用了shutdown或shutdownNow方法后,isShutdown方法就会返回 true。 -
isTerminaed- 当所有的任务都已关闭后,才表示线程池关闭成功,这时调用isTerminaed方法会返回 true。 -
setCorePoolSize- 设置核心线程数大小。 -
setMaximumPoolSize- 设置最大线程数大小。 -
getTaskCount- 线程池已经执行的和未执行的任务总数; -
getCompletedTaskCount- 线程池已完成的任务数量,该值小于等于taskCount; -
getLargestPoolSize- 线程池曾经创建过的最大线程数量。通过这个数据可以知道线程池是否满过,也就是达到了maximumPoolSize; -
getPoolSize- 线程池当前的线程数量; -
getActiveCount- 当前线程池中正在执行任务的线程数量。
# #3.5. 使用示例
public class ThreadPoolExecutorDemo {
public static void main(String[] args) {
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(5, 10, 500, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.AbortPolicy());
for (int i = 0; i < 100; i++) {
threadPoolExecutor.execute(new MyThread());
String info = String.format("线程池中线程数目:%s,队列中等待执行的任务数目:%s,已执行玩别的任务数目:%s",
threadPoolExecutor.getPoolSize(),
threadPoolExecutor.getQueue().size(),
threadPoolExecutor.getCompletedTaskCount());
System.out.println(info);
}
threadPoolExecutor.shutdown();
}
static class MyThread implements Runnable {
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + " 执行");
}
}
}# #4. Executors
JDK 的 Executors 类中提供了几种具有代表性的线程池,这些线程池 都是基于 ThreadPoolExecutor 的定制化实现。
在实际使用线程池的场景中,我们往往不是直接使用 ThreadPoolExecutor ,而是使用 JDK 中提供的具有代表性的线程池实例。
# #4.1. newSingleThreadExecutor
创建一个单线程的线程池。
只会创建唯一的工作线程来执行任务,保证所有任务按照指定顺序 (FIFO, LIFO, 优先级) 执行。 如果这个唯一的线程因为异常结束,那么会有一个新的线程来替代它 。
单工作线程最大的特点是:可保证顺序地执行各个任务。
示例:
public class SingleThreadExecutorDemo {
public static void main(String[] args) {
ExecutorService executorService = Executors.newSingleThreadExecutor();
for (int i = 0; i < 100; i++) {
executorService.execute(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + " 执行");
}
});
}
executorService.shutdown();
}
}# #4.2. newFixedThreadPool
创建一个固定大小的线程池。
每次提交一个任务就会新创建一个工作线程,如果工作线程数量达到线程池最大线程数,则将提交的任务存入到阻塞队列中。
FixedThreadPool 是一个典型且优秀的线程池,它具有线程池提高程序效率和节省创建线程时所耗的开销的优点。但是,在线程池空闲时,即线程池中没有可运行任务时,它不会释放工作线程,还会占用一定的系统资源。
示例:
public class FixedThreadPoolDemo {
public static void main(String[] args) {
ExecutorService executorService = Executors.newFixedThreadPool(3);
for (int i = 0; i < 100; i++) {
executorService.execute(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + " 执行");
}
});
}
executorService.shutdown();
}
}# #4.3. newCachedThreadPool
创建一个可缓存的线程池。
- 如果线程池大小超过处理任务所需要的线程数,就会回收部分空闲的线程;
- 如果长时间没有往线程池中提交任务,即如果工作线程空闲了指定的时间(默认为 1 分钟),则该工作线程将自动终止。终止后,如果你又提交了新的任务,则线程池重新创建一个工作线程。
- 此线程池不会对线程池大小做限制,线程池大小完全依赖于操作系统(或者说 JVM)能够创建的最大线程大小。 因此,使用
CachedThreadPool时,一定要注意控制任务的数量,否则,由于大量线程同时运行,很有会造成系统瘫痪。
示例:
public class CachedThreadPoolDemo {
public static void main(String[] args) {
ExecutorService executorService = Executors.newCachedThreadPool();
for (int i = 0; i < 100; i++) {
executorService.execute(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + " 执行");
}
});
}
executorService.shutdown();
}
}# #4.4. newScheduleThreadPool
创建一个大小无限的线程池。此线程池支持定时以及周期性执行任务的需求。
public class ScheduledThreadPoolDemo {
public static void main(String[] args) {
schedule();
scheduleAtFixedRate();
}
private static void schedule() {
ScheduledExecutorService executorService = Executors.newScheduledThreadPool(5);
for (int i = 0; i < 100; i++) {
executorService.schedule(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + " 执行");
}
}, 1, TimeUnit.SECONDS);
}
executorService.shutdown();
}
private static void scheduleAtFixedRate() {
ScheduledExecutorService executorService = Executors.newScheduledThreadPool(5);
for (int i = 0; i < 100; i++) {
executorService.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + " 执行");
}
}, 1, 1, TimeUnit.SECONDS);
}
executorService.shutdown();
}
}# #4.5. newWorkStealingPool
Java 8 才引入。
其内部会构建 ForkJoinPool ,利用 Work-Stealing (opens new window) 算法,并行地处理任务,不保证处理顺序。
# #5. 线程池最佳实践
# #5.1. 计算线程数量
一般多线程执行的任务类型可以分为 CPU 密集型和 I/O 密集型,根据不同的任务类型,我们计算线程数的方法也不一样。
**CPU 密集型任务:** 这种任务消耗的主要是 CPU 资源,可以将线程数设置为 N(CPU 核心数)+1,比 CPU 核心数多出来的一个线程是为了防止线程偶发的缺页中断,或者其它原因导致的任务暂停而带来的影响。一旦任务暂停,CPU 就会处于空闲状态,而在这种情况下多出来的一个线程就可以充分利用 CPU 的空闲时间。
**I/O 密集型任务:** 这种任务应用起来,系统会用大部分的时间来处理 I/O 交互,而线程在处理 I/O 的时间段内不会占用 CPU 来处理,这时就可以将 CPU 交出给其它线程使用。因此在 I/O 密集型任务的应用中,我们可以多配置一些线程,具体的计算方法是 2N。
# #5.2. 建议使用有界阻塞队列
不建议使用 Executors 的最重要的原因是: Executors 提供的很多方法默认使用的都是无界的 LinkedBlockingQueue ,高负载情境下,无界队列很容易导致 OOM,而 OOM 会导致所有请求都无法处理,这是致命问题。所以强烈建议使用有界队列。
《阿里巴巴 Java 开发手册》中提到,禁止使用这些方法来创建线程池,而应该手动 new ThreadPoolExecutor 来创建线程池。制订这条规则是因为容易导致生产事故,最典型的就是 newFixedThreadPool 和 newCachedThreadPool ,可能因为资源耗尽导致 OOM 问题。
【示例】 newFixedThreadPool OOM
ThreadPoolExecutor threadPool = (ThreadPoolExecutor) Executors.newFixedThreadPool(1);
printStats(threadPool);
for (int i = 0; i < 100000000; i++) {
threadPool.execute(() -> {
String payload = IntStream.rangeClosed(1, 1000000)
.mapToObj(__ -> "a")
.collect(Collectors.joining("")) + UUID.randomUUID().toString();
try {
TimeUnit.HOURS.sleep(1);
} catch (InterruptedException e) {
}
log.info(payload);
});
}
threadPool.shutdown();
threadPool.awaitTermination(1, TimeUnit.HOURS);newFixedThreadPool 使用的工作队列是 LinkedBlockingQueue ,而默认构造方法的 LinkedBlockingQueue 是一个 Integer.MAX_VALUE 长度的队列,可以认为是无界的。如果任务较多并且执行较慢的话,队列可能会快速积压,撑爆内存导致 OOM。
【示例】 newCachedThreadPool OOM
ThreadPoolExecutor threadPool = (ThreadPoolExecutor) Executors.newCachedThreadPool();
printStats(threadPool);
for (int i = 0; i < 100000000; i++) {
threadPool.execute(() -> {
String payload = UUID.randomUUID().toString();
try {
TimeUnit.HOURS.sleep(1);
} catch (InterruptedException e) {
}
log.info(payload);
});
}
threadPool.shutdown();
threadPool.awaitTermination(1, TimeUnit.HOURS);newCachedThreadPool 的最大线程数是 Integer.MAX_VALUE ,可以认为是没有上限的,而其工作队列 SynchronousQueue 是一个没有存储空间的阻塞队列。这意味着,只要有请求到来,就必须找到一条工作线程来处理,如果当前没有空闲的线程就再创建一条新的。
如果大量的任务进来后会创建大量的线程。我们知道线程是需要分配一定的内存空间作为线程栈的,比如 1MB,因此无限制创建线程必然会导致 OOM。
# #5.3. 重要任务应该自定义拒绝策略
使用有界队列,当任务过多时,线程池会触发执行拒绝策略,线程池默认的拒绝策略会 throw RejectedExecutionException 这是个运行时异常,对于运行时异常编译器并不强制 catch 它,所以开发人员很容易忽略。因此默认拒绝策略要慎重使用。如果线程池处理的任务非常重要,建议自定义自己的拒绝策略;并且在实际工作中,自定义的拒绝策略往往和降级策略配合使用。
# Java 并发工具类
📦 本文以及示例源码已归档在 javacore(opens new window)
JDK 的
java.util.concurrent包(即 J.U.C)中提供了几个非常有用的并发工具类。
# #1. CountDownLatch
字面意思为 递减计数锁。用于控制一个线程等待多个线程。
CountDownLatch维护一个计数器 count,表示需要等待的事件数量。countDown方法递减计数器,表示有一个事件已经发生。调用await方法的线程会一直阻塞直到计数器为零,或者等待中的线程中断,或者等待超时。
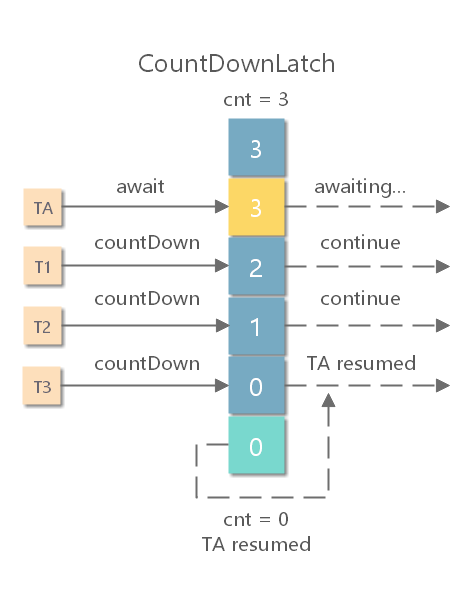
CountDownLatch 是基于 AQS ( AbstractQueuedSynchronizer ) 实现的。
CountDownLatch 唯一的构造方法:
// 初始化计数器
public CountDownLatch(int count) {};说明:
- count 为统计值。
CountDownLatch 的重要方法:
public void await() throws InterruptedException { };
public boolean await(long timeout, TimeUnit unit) throws InterruptedException { };
public void countDown() { };说明:
await()- 调用await()方法的线程会被挂起,它会等待直到 count 值为 0 才继续执行。await(long timeout, TimeUnit unit)- 和await()类似,只不过等待一定的时间后 count 值还没变为 0 的话就会继续执行countDown()- 将统计值 count 减 1
示例:
public class CountDownLatchDemo {
public static void main(String[] args) {
final CountDownLatch latch = new CountDownLatch(2);
new Thread(new MyThread(latch)).start();
new Thread(new MyThread(latch)).start();
try {
System.out.println("等待2个子线程执行完毕...");
latch.await();
System.out.println("2个子线程已经执行完毕");
System.out.println("继续执行主线程");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
static class MyThread implements Runnable {
private CountDownLatch latch;
public MyThread(CountDownLatch latch) {
this.latch = latch;
}
@Override
public void run() {
System.out.println("子线程" + Thread.currentThread().getName() + "正在执行");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("子线程" + Thread.currentThread().getName() + "执行完毕");
latch.countDown();
}
}
}# #2. CyclicBarrier
字面意思是 循环栅栏。
CyclicBarrier可以让一组线程等待至某个状态(遵循字面意思,不妨称这个状态为栅栏)之后再全部同时执行。之所以叫循环栅栏是因为:当所有等待线程都被释放以后,CyclicBarrier可以被重用。
CyclicBarrier维护一个计数器 count。每次执行await方法之后,count 加 1,直到计数器的值和设置的值相等,等待的所有线程才会继续执行。
CyclicBarrier 是基于 ReentrantLock 和 Condition 实现的。
CyclicBarrier 应用场景: CyclicBarrier 在并行迭代算法中非常有用。
CyclicBarrier 提供了 2 个构造方法
public CyclicBarrier(int parties) {}
public CyclicBarrier(int parties, Runnable barrierAction) {}说明:
parties-parties数相当于一个阈值,当有parties数量的线程在等待时,CyclicBarrier处于栅栏状态。barrierAction- 当CyclicBarrier处于栅栏状态时执行的动作。
CyclicBarrier 的重要方法:
public int await() throws InterruptedException, BrokenBarrierException {}
public int await(long timeout, TimeUnit unit)
throws InterruptedException,
BrokenBarrierException,
TimeoutException {}
// 将屏障重置为初始状态
public void reset() {}说明:
await()- 等待调用await()的线程数达到屏障数。如果当前线程是最后一个到达的线程,并且在构造函数中提供了非空屏障操作,则当前线程在允许其他线程继续之前运行该操作。如果在屏障动作期间发生异常,那么该异常将在当前线程中传播并且屏障被置于断开状态。await(long timeout, TimeUnit unit)- 相比于await()方法,这个方法让这些线程等待至一定的时间,如果还有线程没有到达栅栏状态就直接让到达栅栏状态的线程执行后续任务。reset()- 将屏障重置为初始状态。
示例:
public class CyclicBarrierDemo {
final static int N = 4;
public static void main(String[] args) {
CyclicBarrier barrier = new CyclicBarrier(N,
new Runnable() {
@Override
public void run() {
System.out.println("当前线程" + Thread.currentThread().getName());
}
});
for (int i = 0; i < N; i++) {
MyThread myThread = new MyThread(barrier);
new Thread(myThread).start();
}
}
static class MyThread implements Runnable {
private CyclicBarrier cyclicBarrier;
MyThread(CyclicBarrier cyclicBarrier) {
this.cyclicBarrier = cyclicBarrier;
}
@Override
public void run() {
System.out.println("线程" + Thread.currentThread().getName() + "正在写入数据...");
try {
Thread.sleep(3000); // 以睡眠来模拟写入数据操作
System.out.println("线程" + Thread.currentThread().getName() + "写入数据完毕,等待其他线程写入完毕");
cyclicBarrier.await();
} catch (InterruptedException | BrokenBarrierException e) {
e.printStackTrace();
}
}
}
}# #3. Semaphore
字面意思为 信号量。
Semaphore用来控制某段代码块的并发数。
Semaphore管理着一组虚拟的许可(permit),permit 的初始数量可通过构造方法来指定。每次执行acquire方法可以获取一个 permit,如果没有就等待;而release方法可以释放一个 permit。
Semaphore 应用场景:
Semaphore可以用于实现资源池,如数据库连接池。Semaphore可以用于将任何一种容器变成有界阻塞容器。
Semaphore 提供了 2 个构造方法:
// 参数 permits 表示许可数目,即同时可以允许多少线程进行访问
public Semaphore(int permits) {}
// 参数 fair 表示是否是公平的,即等待时间越久的越先获取许可
public Semaphore(int permits, boolean fair) {}说明:
permits- 初始化固定数量的 permit,并且默认为非公平模式。fair- 设置是否为公平模式。所谓公平,是指等待久的优先获取 permit。
Semaphore 的重要方法:
// 获取 1 个许可
public void acquire() throws InterruptedException {}
//获取 permits 个许可
public void acquire(int permits) throws InterruptedException {}
// 释放 1 个许可
public void release() {}
//释放 permits 个许可
public void release(int permits) {}说明:
acquire()- 获取 1 个 permit。acquire(int permits)- 获取 permits 数量的 permit。release()- 释放 1 个 permit。release(int permits)- 释放 permits 数量的 permit。
示例:
public class SemaphoreDemo {
private static final int THREAD_COUNT = 30;
private static ExecutorService threadPool = Executors.newFixedThreadPool(THREAD_COUNT);
private static Semaphore semaphore = new Semaphore(10);
public static void main(String[] args) {
for (int i = 0; i < THREAD_COUNT; i++) {
threadPool.execute(new Runnable() {
@Override
public void run() {
try {
semaphore.acquire();
System.out.println("save data");
semaphore.release();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
threadPool.shutdown();
}
}# #4. 总结
CountDownLatch和CyclicBarrier都能够实现线程之间的等待,只不过它们侧重点不同:CountDownLatch一般用于某个线程 A 等待若干个其他线程执行完任务之后,它才执行;CyclicBarrier一般用于一组线程互相等待至某个状态,然后这一组线程再同时执行;- 另外,
CountDownLatch是不可以重用的,而CyclicBarrier是可以重用的。
Semaphore其实和锁有点类似,它一般用于控制对某组资源的访问权限。
# Java 内存模型
关键词:
JMM、volatile、synchronized、final、Happens-Before、内存屏障摘要:Java 内存模型(Java Memory Model),简称 JMM。Java 内存模型的目标是为了解决由可见性和有序性导致的并发安全问题。Java 内存模型通过 屏蔽各种硬件和操作系统的内存访问差异,以实现让 Java 程序在各种平台下都能达到一致的内存访问效果。
📦 本文以及示例源码已归档在 javacore(opens new window)
- \1. 物理内存模型
- \2. Java 内存模型
- 3. Happens-Before
- 4. 内存屏障
- 5. volatile
- \6. synchronized
- 7. 参考资料
# #1. 物理内存模型
物理机遇到的并发问题与虚拟机中的情况有不少相似之处,物理机对并发的处理方案对于虚拟机的实现也有相当大的参考意义。
# #1.1. 硬件处理效率
物理内存的第一个问题是:硬件处理效率。
- 绝大多数的运算任务都不可能只靠处理器 “计算” 就能完成,处理器至少需要与内存交互,如读取运算数据、存储运算结果,这个 I/O 操作是很难消除的(无法仅靠寄存器完成所有运算任务)。
- 由于计算机的存储设备与处理器的运算速度有几个数量级的差距 ,这种速度上的矛盾,会降低硬件的处理效率。所以,现代计算机都不得不 加入高速缓存(Cache) 来作为内存和处理器之间的缓冲。将需要用到的数据复制到缓存中,让运算能快速进行,当运算结束后再从缓存同步会内存中,这样处理器就无需等待缓慢的内存读写了。
# #1.2. 缓存一致性
高速缓存解决了 硬件效率问题,但是引入了一个新的问题:缓存一致性(Cache Coherence)。
在多处理器系统中,每个处理器都有自己的高速缓存,而它们又共享同一主内存。当多个处理器的运算任务都涉及同一块主内存区域时,将可能导致各自的缓存数据不一致。
为了解决缓存一致性问题,需要各个处理器访问缓存时都遵循一些协议,在读写时要根据协议来进行操作。
# #1.3. 代码乱序执行优化
除了高速缓存以外,为了使得处理器内部的运算单元尽量被充分利用,处理器可能会对输入代码进行乱序执行(Out-Of-Order Execution)优化。处理器会在计算之后将乱序执行的结果重组,保证该结果与顺序执行的结果是一致的,但不保证程序中各个语句计算的先后顺序与输入代码中的顺序一致。
乱序执行技术是处理器为提高运算速度而做出违背代码原有顺序的优化。
- 单核环境下,处理器保证做出的优化不会导致执行结果远离预期目标,但在多核环境下却并非如此。
- 多核环境下, 如果存在一个核的计算任务依赖另一个核的计算任务的中间结果,而且对相关数据读写没做任何防护措施,那么其顺序性并不能靠代码的先后顺序来保证。
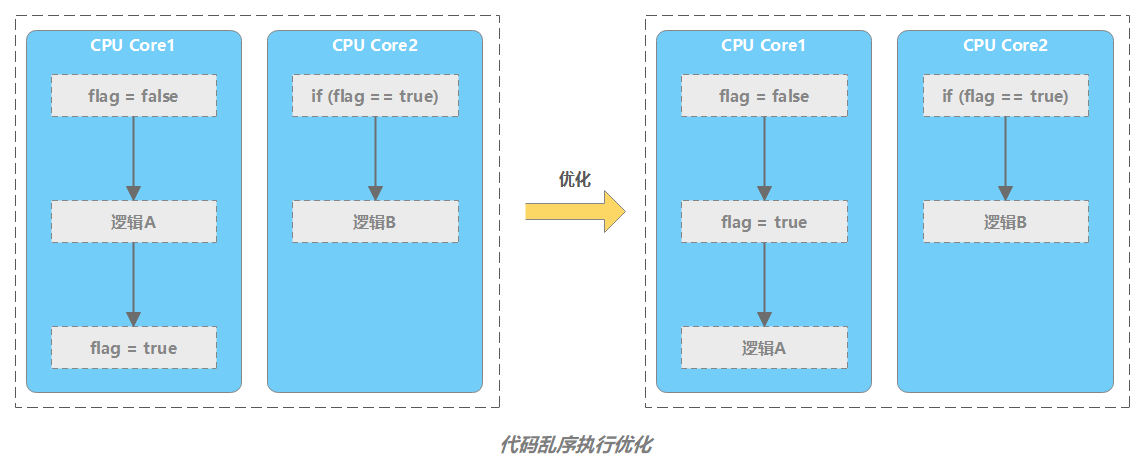
# #2. Java 内存模型
内存模型 这个概念。我们可以理解为:在特定的操作协议下,对特定的内存或高速缓存进行读写访问的过程抽象。不同架构的物理计算机可以有不一样的内存模型,JVM 也有自己的内存模型。
JVM 中试图定义一种 Java 内存模型(Java Memory Model, JMM)来屏蔽各种硬件和操作系统的内存访问差异,以实现让 Java 程序 在各种平台下都能达到一致的内存访问效果。
在 Java 并发简介 (opens new window) 中已经介绍了,并发安全需要满足可见性、有序性、原子性。其中,导致可见性的原因是缓存,导致有序性的原因是编译优化。那解决可见性、有序性最直接的办法就是禁用缓存和编译优化 。但这么做,性能就堪忧了。
合理的方案应该是按需禁用缓存以及编译优化。那么,如何做到呢?,Java 内存模型规范了 JVM 如何提供按需禁用缓存和编译优化的方法。具体来说,这些方法包括 volatile、synchronized 和 final 三个关键字,以及 Happens-Before 规则。
# #2.1. 主内存和工作内存
JMM 的主要目标是 定义程序中各个变量的访问规则,即在虚拟机中将变量存储到内存和从内存中取出变量这样的底层细节。此处的变量(Variables)与 Java 编程中所说的变量有所区别,它包括了实例字段、静态字段和构成数值对象的元素,但不包括局部变量与方法参数,因为后者是线程私有的,不会被共享,自然就不会存在竞争问题。为了获得较好的执行效能,JMM 并没有限制执行引擎使用处理器的特定寄存器或缓存来和主存进行交互,也没有限制即使编译器进行调整代码执行顺序这类优化措施。
JMM 规定了所有的变量都存储在主内存(Main Memory)中。
每条线程还有自己的工作内存(Working Memory),工作内存中保留了该线程使用到的变量的主内存的副本。工作内存是 JMM 的一个抽象概念,并不真实存在,它涵盖了缓存,写缓冲区,寄存器以及其他的硬件和编译器优化。
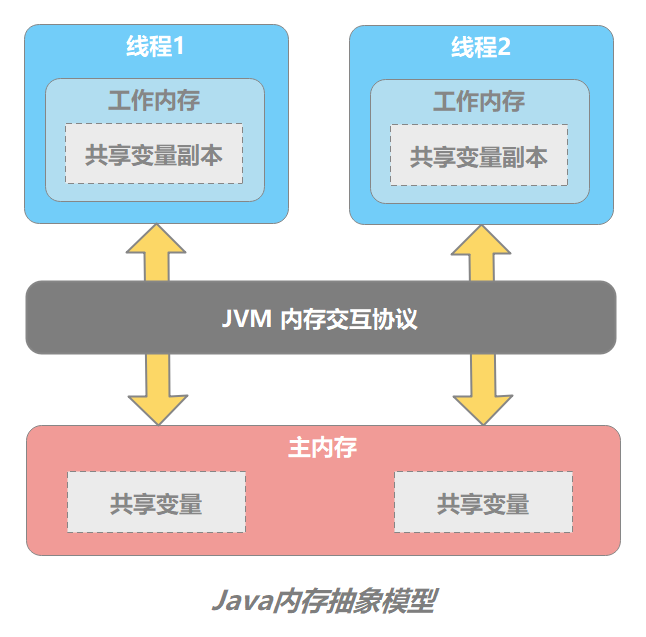
线程对变量的所有操作都必须在工作内存中进行,而不能直接读写主内存中的变量。不同的线程间也无法直接访问对方工作内存中的变量,线程间变量值的传递均需要通过主内存来完成。
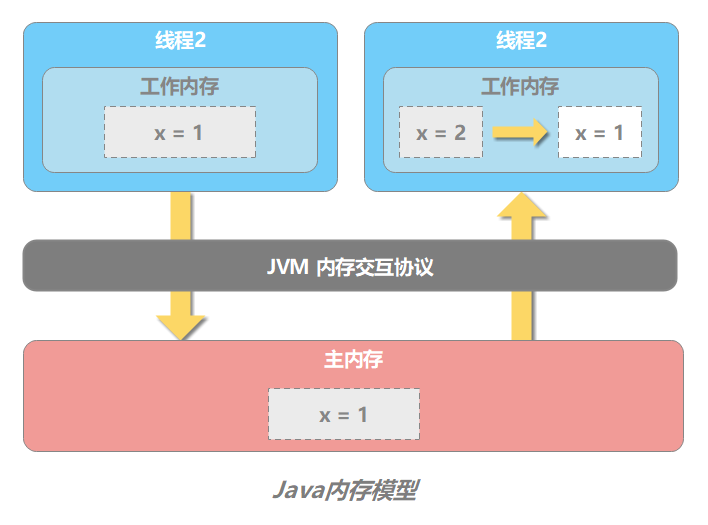
说明:
这里说的主内存、工作内存与 Java 内存区域中的堆、栈、方法区等不是同一个层次的内存划分。
# #2.2. JMM 内存操作的问题
类似于物理内存模型面临的问题,JMM 存在以下两个问题:
-
工作内存数据一致性 - 各个线程操作数据时会保存使用到的主内存中的共享变量副本,当多个线程的运算任务都涉及同一个共享变量时,将导致各自的的共享变量副本不一致。如果真的发生这种情况,数据同步回主内存以谁的副本数据为准? Java 内存模型主要通过一系列的数据同步协议、规则来保证数据的一致性。
-
指令重排序优化
\- Java 中重排序通常是编译器或运行时环境为了优化程序性能而采取的对指令进行重新排序执行的一种手段。重排序分为两类:
编译期重排序和运行期重排序
,分别对应编译时和运行时环境。 同样的,指令重排序不是随意重排序,它需要满足以下两个条件:
- 在单线程环境下不能改变程序运行的结果。即时编译器(和处理器)需要保证程序能够遵守 `as-if-serial` 属性。通俗地说,就是在单线程情况下,要给程序一个顺序执行的假象。即经过重排序的执行结果要与顺序执行的结果保持一致。
- 存在数据依赖关系的不允许重排序。
- 多线程环境下,如果线程处理逻辑之间存在依赖关系,有可能因为指令重排序导致运行结果与预期不同。
# #2.3. 内存间交互操作
JMM 定义了 8 个操作来完成主内存和工作内存之间的交互操作。JVM 实现时必须保证下面介绍的每种操作都是 原子的(对于 double 和 long 型的变量来说,load、store、read、和 write 操作在某些平台上允许有例外 )。
lock(锁定) - 作用于主内存的变量,它把一个变量标识为一条线程独占的状态。unlock(解锁) - 作用于主内存的变量,它把一个处于锁定状态的变量释放出来,释放后的变量才可以被其他线程锁定。read(读取) - 作用于主内存的变量,它把一个变量的值从主内存传输到线程的工作内存中,以便随后的load动作使用。write(写入) - 作用于主内存的变量,它把 store 操作从工作内存中得到的变量的值放入主内存的变量中。load(载入) - 作用于工作内存的变量,它把 read 操作从主内存中得到的变量值放入工作内存的变量副本中。use(使用) - 作用于工作内存的变量,它把工作内存中一个变量的值传递给执行引擎,每当虚拟机遇到一个需要使用到变量的值得字节码指令时就会执行这个操作。assign(赋值) - 作用于工作内存的变量,它把一个从执行引擎接收到的值赋给工作内存的变量,每当虚拟机遇到一个给变量赋值的字节码指令时执行这个操作。store(存储) - 作用于工作内存的变量,它把工作内存中一个变量的值传送到主内存中,以便随后write操作使用。
如果要把一个变量从主内存中复制到工作内存,就需要按序执行 read 和 load 操作;如果把变量从工作内存中同步回主内存中,就需要按序执行 store 和 write 操作。但 Java 内存模型只要求上述操作必须按顺序执行,而没有保证必须是连续执行。
JMM 还规定了上述 8 种基本操作,需要满足以下规则:
- read 和 load 必须成对出现;store 和 write 必须成对出现。即不允许一个变量从主内存读取了但工作内存不接受,或从工作内存发起回写了但主内存不接受的情况出现。
- 不允许一个线程丢弃它的最近 assign 的操作,即变量在工作内存中改变了之后必须把变化同步到主内存中。
- 不允许一个线程无原因的(没有发生过任何 assign 操作)把数据从工作内存同步回主内存中。
- 一个新的变量只能在主内存中诞生,不允许在工作内存中直接使用一个未被初始化(load 或 assign )的变量。换句话说,就是对一个变量实施 use 和 store 操作之前,必须先执行过了 load 或 assign 操作。
- 一个变量在同一个时刻只允许一条线程对其进行 lock 操作,但 lock 操作可以被同一条线程重复执行多次,多次执行 lock 后,只有执行相同次数的 unlock 操作,变量才会被解锁。所以 lock 和 unlock 必须成对出现。
- 如果对一个变量执行 lock 操作,将会清空工作内存中此变量的值,在执行引擎使用这个变量前,需要重新执行 load 或 assign 操作初始化变量的值。
- 如果一个变量事先没有被 lock 操作锁定,则不允许对它执行 unlock 操作,也不允许去 unlock 一个被其他线程锁定的变量。
- 对一个变量执行 unlock 操作之前,必须先把此变量同步到主内存中(执行 store 和 write 操作)
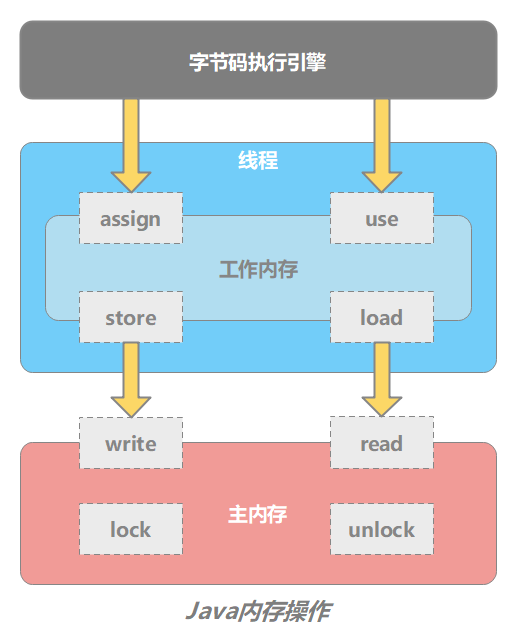
# #2.4. 并发安全特性
上文介绍了 Java 内存交互的 8 种基本操作,它们遵循 Java 内存三大特性:原子性、可见性、有序性。
而这三大特性,归根结底,是为了实现多线程的 数据一致性,使得程序在多线程并发,指令重排序优化的环境中能如预期运行。
# #原子性
原子性即一个操作或者多个操作,要么全部执行(执行的过程不会被任何因素打断),要么就都不执行。即使在多个线程一起执行的时候,一个操作一旦开始,就不会被其他线程所干扰。
在 Java 中,为了保证原子性,提供了两个高级的字节码指令 monitorenter 和 monitorexit 。这两个字节码,在 Java 中对应的关键字就是 synchronized 。
因此,在 Java 中可以使用 synchronized 来保证方法和代码块内的操作是原子性的。
# #可见性
可见性是指当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改的值。
JMM 是通过 " 变量修改后将新值同步回主内存, 变量读取前从主内存刷新变量值 " 这种依赖主内存作为传递媒介的方式来实现的。
Java 实现多线程可见性的方式有:
volatilesynchronizedfinal
# #有序性
有序性规则表现在以下两种场景:线程内和线程间
- 线程内 - 从某个线程的角度看方法的执行,指令会按照一种叫 “串行”(
as-if-serial)的方式执行,此种方式已经应用于顺序编程语言。 - 线程间 - 这个线程 “观察” 到其他线程并发地执行非同步的代码时,由于指令重排序优化,任何代码都有可能交叉执行。唯一起作用的约束是:对于同步方法,同步块(
synchronized关键字修饰)以及volatile字段的操作仍维持相对有序。
在 Java 中,可以使用 synchronized 和 volatile 来保证多线程之间操作的有序性。实现方式有所区别:
volatile关键字会禁止指令重排序。synchronized关键字通过互斥保证同一时刻只允许一条线程操作。
# #3. Happens-Before
JMM 为程序中所有的操作定义了一个偏序关系,称之为 先行发生原则(Happens-Before) 。
Happens-Before 是指 前面一个操作的结果对后续操作是可见的。
Happens-Before 非常重要,它是判断数据是否存在竞争、线程是否安全的主要依据,依靠这个原则,我们可以通过几条规则一揽子地解决并发环境下两个操作间是否可能存在冲突的所有问题。
- 程序次序规则 - 一个线程内,按照代码顺序,书写在前面的操作先行发生于书写在后面的操作。
- 锁定规则 - 一个
unLock操作先行发生于后面对同一个锁的lock操作。 - volatile 变量规则 - 对一个
volatile变量的写操作先行发生于后面对这个变量的读操作。 - 线程启动规则 -
Thread对象的start()方法先行发生于此线程的每个一个动作。 - 线程终止规则 - 线程中所有的操作都先行发生于线程的终止检测,我们可以通过
Thread.join()方法结束、Thread.isAlive()的返回值手段检测到线程已经终止执行。 - 线程中断规则 - 对线程
interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生,可以通过Thread.interrupted()方法检测到是否有中断发生。 - 对象终结规则 - 一个对象的初始化完成先行发生于它的
finalize()方法的开始。 - 传递性 - 如果操作 A 先行发生于 操作 B,而操作 B 又 先行发生于 操作 C,则可以得出操作 A 先行发生于 操作 C。
# #4. 内存屏障
Java 中如何保证底层操作的有序性和可见性?可以通过内存屏障(memory barrier)。
内存屏障是被插入两个 CPU 指令之间的一种指令,用来禁止处理器指令发生重排序(像屏障一样),从而保障有序性的。另外,为了达到屏障的效果,它也会使处理器写入、读取值之前,将主内存的值写入高速缓存,清空无效队列,从而保障可见性。
举个例子:
Store1;
Store2;
Load1;
StoreLoad; //内存屏障
Store3;
Load2;
Load3;
复制代码对于上面的一组 CPU 指令(Store 表示写入指令,Load 表示读取指令),StoreLoad 屏障之前的 Store 指令无法与 StoreLoad 屏障之后的 Load 指令进行交换位置,即重排序。但是 StoreLoad 屏障之前和之后的指令是可以互换位置的,即 Store1 可以和 Store2 互换,Load2 可以和 Load3 互换。
常见有 4 种屏障
LoadLoad屏障 - 对于这样的语句Load1; LoadLoad; Load2,在 Load2 及后续读取操作要读取的数据被访问前,保证 Load1 要读取的数据被读取完毕。StoreStore屏障 - 对于这样的语句Store1; StoreStore; Store2,在 Store2 及后续写入操作执行前,保证 Store1 的写入操作对其它处理器可见。LoadStore屏障 - 对于这样的语句Load1; LoadStore; Store2,在 Store2 及后续写入操作被执行前,保证 Load1 要读取的数据被读取完毕。StoreLoad屏障 - 对于这样的语句Store1; StoreLoad; Load2,在 Load2 及后续所有读取操作执行前,保证 Store1 的写入对所有处理器可见。它的开销是四种屏障中最大的(冲刷写缓冲器,清空无效化队列)。在大多数处理器的实现中,这个屏障是个万能屏障,兼具其它三种内存屏障的功能。
Java 中对内存屏障的使用在一般的代码中不太容易见到,常见的有 volatile 和 synchronized 关键字修饰的代码块 (后面再展开介绍),还可以通过 Unsafe 这个类来使用内存屏障。
# #5. volatile
volatile 是 JVM 提供的 最轻量级的同步机制。
volatile 的中文意思是不稳定的,易变的,用 volatile 修饰变量是为了保证变量在多线程中的可见性。
# #volatile 变量的特性
volatile 变量具有两种特性:
- 保证变量对所有线程的可见性。
- 禁止进行指令重排序
# #保证变量对所有线程的可见性
这里的可见性是指当一条线程修改了 volatile 变量的值,新值对于其他线程来说是可以立即得知的。而普通变量不能做到这一点,普通变量的值在线程间传递均需要通过主内存来完成。
线程写 volatile 变量的过程:
- 改变线程工作内存中 volatile 变量副本的值
- 将改变后的副本的值从工作内存刷新到主内存
线程读 volatile 变量的过程:
- 从主内存中读取 volatile 变量的最新值到线程的工作内存中
- 从工作内存中读取 volatile 变量的副本
注意:保证可见性不等同于 volatile 变量保证并发操作的安全性
在不符合以下两点的场景中,仍然要通过枷锁来保证原子性:
- 运算结果并不依赖变量的当前值,或者能够确保只有单一的线程修改变量的值。
- 变量不需要与其他状态变量共同参与不变约束。
但是如果多个线程同时把更新后的变量值同时刷新回主内存,可能导致得到的值不是预期结果:
举个例子: 定义 volatile int count = 0 ,2 个线程同时执行 count++ 操作,每个线程都执行 500 次,最终结果小于 1000,原因是每个线程执行 count++ 需要以下 3 个步骤:
- 线程从主内存读取最新的 count 的值
- 执行引擎把 count 值加 1,并赋值给线程工作内存
- 线程工作内存把 count 值保存到主内存 有可能某一时刻 2 个线程在步骤 1 读取到的值都是 100,执行完步骤 2 得到的值都是 101,最后刷新了 2 次 101 保存到主内存。
# #语义 2 禁止进行指令重排序
具体一点解释,禁止重排序的规则如下:
- 当程序执行到
volatile变量的读操作或者写操作时,在其前面的操作的更改肯定全部已经进行,且结果已经对后面的操作可见;在其后面的操作肯定还没有进行; - 在进行指令优化时,不能将在对
volatile变量访问的语句放在其后面执行,也不能把volatile变量后面的语句放到其前面执行。
普通的变量仅仅会保证该方法的执行过程中所有依赖赋值结果的地方都能获取到正确的结果,而不能保证赋值操作的顺序与程序代码中的执行顺序一致。
举个例子:
volatile boolean initialized = false;
// 下面代码线程A中执行
// 读取配置信息,当读取完成后将initialized设置为true以通知其他线程配置可用
doSomethingReadConfg();
initialized = true;
// 下面代码线程B中执行
// 等待initialized 为true,代表线程A已经把配置信息初始化完成
while (!initialized) {
sleep();
}
// 使用线程A初始化好的配置信息
doSomethingWithConfig();
复制代码上面代码中如果定义 initialized 变量时没有使用 volatile 修饰,就有可能会由于指令重排序的优化,导致线程 A 中最后一句代码 “initialized = true” 在 “doSomethingReadConfg ()” 之前被执行,这样会导致线程 B 中使用配置信息的代码就可能出现错误,而 volatile 关键字就禁止重排序的语义可以避免此类情况发生。
# #volatile 的原理
具体实现方式是在编译期生成字节码时,会在指令序列中增加内存屏障来保证,下面是基于保守策略的 JMM 内存屏障插入策略:
- 在每个 volatile 写操作的前面插入一个 StoreStore 屏障。 该屏障除了保证了屏障之前的写操作和该屏障之后的写操作不能重排序,还会保证了 volatile 写操作之前,任何的读写操作都会先于 volatile 被提交。
- 在每个 volatile 写操作的后面插入一个 StoreLoad 屏障。 该屏障除了使 volatile 写操作不会与之后的读操作重排序外,还会刷新处理器缓存,使 volatile 变量的写更新对其他线程可见。
- 在每个 volatile 读操作的后面插入一个 LoadLoad 屏障。 该屏障除了使 volatile 读操作不会与之前的写操作发生重排序外,还会刷新处理器缓存,使 volatile 变量读取的为最新值。
- 在每个 volatile 读操作的后面插入一个 LoadStore 屏障。 该屏障除了禁止了 volatile 读操作与其之后的任何写操作进行重排序,还会刷新处理器缓存,使其他线程 volatile 变量的写更新对 volatile 读操作的线程可见。
# #volatile 的使用场景
总结起来,就是 “一次写入,到处读取”,某一线程负责更新变量,其他线程只读取变量 (不更新变量),并根据变量的新值执行相应逻辑。例如状态标志位更新,观察者模型变量值发布。
# #6. synchronized
# #6.1. long 和 double 变量的特殊规则
JMM 要求 lock、unlock、read、load、assign、use、store、write 这 8 种操作都具有原子性,但是对于 64 位的数据类型(long 和 double),在模型中特别定义相对宽松的规定:允许虚拟机将没有被 volatile 修饰的 64 位数据的读写操作分为 2 次 32 位的操作来进行,即允许虚拟机可选择不保证 64 位数据类型的 load、store、read 和 write 这 4 个操作的原子性。由于这种非原子性,有可能导致其他线程读到同步未完成的 “32 位的半个变量” 的值。
不过实际开发中,Java 内存模型强烈建议虚拟机把 64 位数据的读写实现为具有原子性,目前各种平台下的商用虚拟机都选择把 64 位数据的读写操作作为原子操作来对待,因此我们在编写代码时一般不需要把用到的 long 和 double 变量专门声明为 volatile。
# #6.2. final 型量的特殊规则
我们知道,final 成员变量必须在声明的时候初始化或者在构造器中初始化,否则就会报编译错误。 final 关键字的可见性是指:被 final 修饰的字段在声明时或者构造器中,一旦初始化完成,那么在其他线程无须同步就能正确看见 final 字段的值。这是因为一旦初始化完成,final 变量的值立刻回写到主内存。
# VM 体系结构
JVM 能跨平台工作,主要是由于 JVM 屏蔽了与各个计算机平台相关的软件、硬件之间的差异。
- \1. JVM 简介
- \2. Hotspot 架构
- 3. 参考资料
# #1. JVM 简介
# #1.1. 计算机体系结构
真实的计算机体系结构的核心部分包含:
- 指令集
- 计算单元(CPU)
- 寻址方式
- 寄存器
- 存储单元
# #1.2. JVM 体系结构简介
JVM 体系结构与计算机体系结构相似,它的核心部分包含:
- JVM 指令集
- 类加载器
- 执行引擎 - 相当于 JVM 的 CPU
- 内存区 - JVM 的存储
- 本地方法调用 - 调用 C/C++ 实现的本地方法
# #2. Hotspot 架构
Hotspot 是最流行的 JVM。
Java 虚拟机的主要组件,包括类加载器、运行时数据区和执行引擎。
Hotspot 虚拟机拥有一个架构,它支持强大特性和能力的基础平台,支持实现高性能和强大的可伸缩性的能力。举个例子,Hotspot 虚拟机 JIT 编译器生成动态的优化,换句话说,它们在 Java 应用执行期做出优化,为底层系统架构生成高性能的本地机器指令。另外,经过它的运行时环境和多线程垃圾回收成熟的进化和连续的设计, Hotspot 虚拟机在高可用计算系统上产出了高伸缩性。
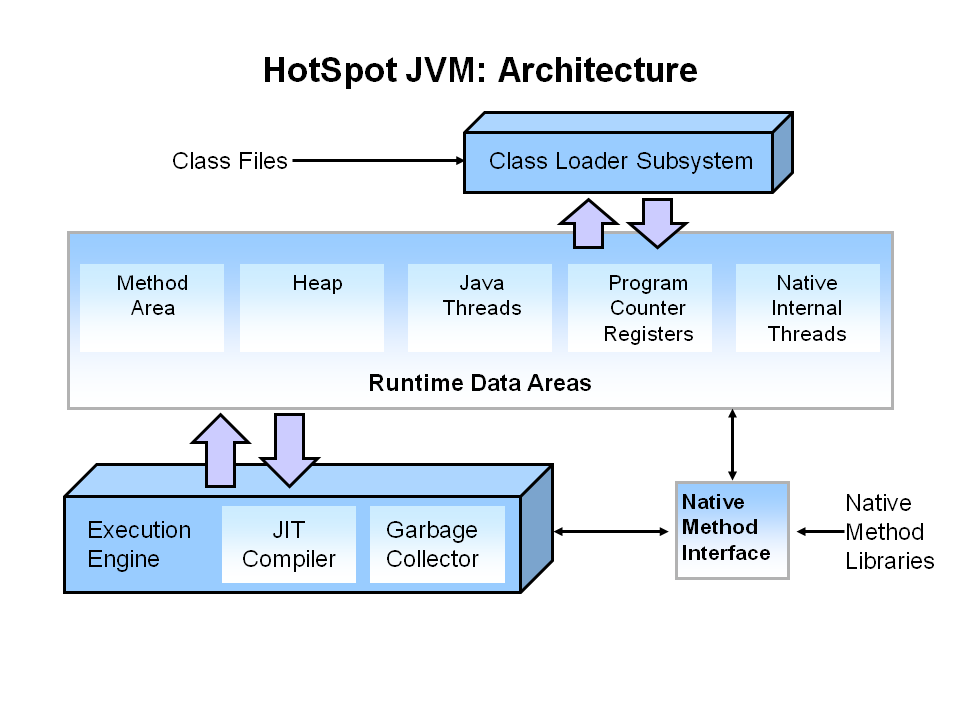
# #2.1. Hotspot 关键组件
Java 虚拟机有三个组件关注着什么时候进行性能优化,堆空间是对象所存储的地方,这个区域被启动时选择的垃圾回收器管理,大部分调优选项与调整堆大小和根据你的情况选择最适当的垃圾收集器相关。即时编译器对性能也有很大的影响,但是使用新版本的 Java 虚拟机时很少需要调整。
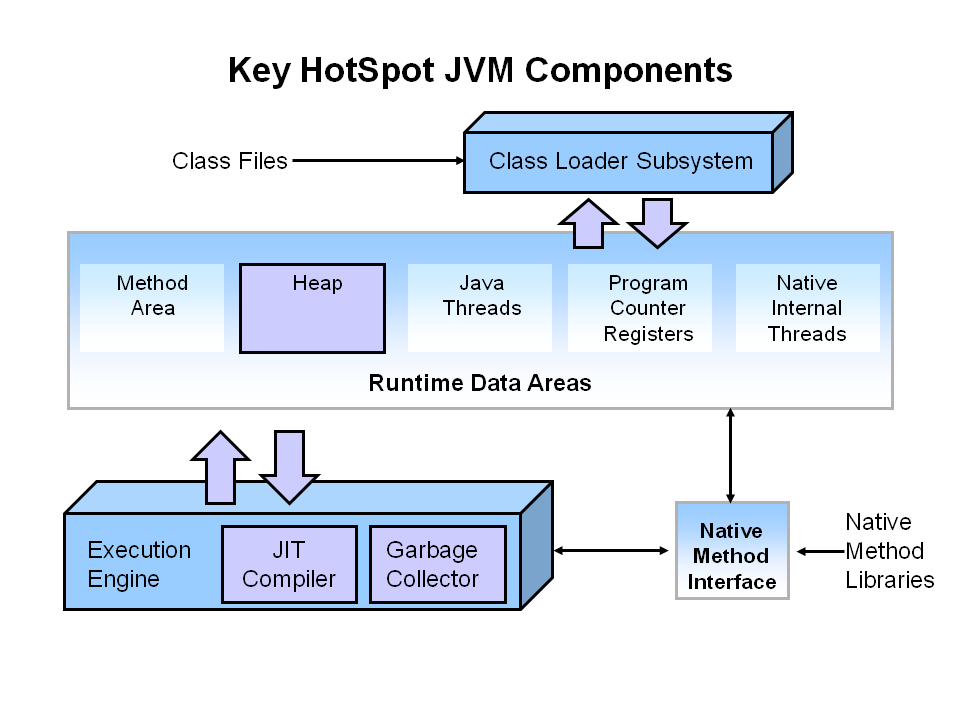
# #2.2. 性能指标
Java 虚拟机的性能指标主要有两点:
- 停顿时间
\- 响应延迟是指一个应用回应一个请求的速度有多快。对关注响应能力的应用来说,长暂停时间是不可接受的,重点是在短的时间周期内能做出响应。
- 桌面 UI 响应事件的速度
- 网站返回网页的速度
- 数据查询返回的速度
- 吞吐量
\- 吞吐量关注在特定的时间周期内一个应用的工作量的最大值。对关注吞吐量的应用来说长暂停时间是可以接受的。由于高吞吐量的应用关注的基准在更长周期时间上,所以快速响应时间不在考虑之内。
- 给定时间内完成事务的数量
- 一小时内批处理程序完成的工作数量
- 一小时内数据查询完成的数量
# Java 内存管理
📦 本文以及示例源码已归档在 javacore(opens new window)
- \1. 内存简介
- \2. 运行时数据区域
- 3. JVM 运行原理
- \4. OutOfMemoryError
- 5. StackOverflowError
- 6. 参考资料
# #1. 内存简介
# #1.1. 物理内存和虚拟内存
所谓物理内存就是通常所说的 RAM(随机存储器)。
虚拟内存使得多个进程在同时运行时可以共享物理内存,这里的共享只是空间上共享,在逻辑上彼此仍然是隔离的。
# #1.2. 内核空间和用户空间
一个计算通常有固定大小的内存空间,但是程序并不能使用全部的空间。因为这些空间被划分为内核空间和用户空间,而程序只能使用用户空间的内存。
# #1.3. 使用内存的 Java 组件
Java 启动后,作为一个进程运行在操作系统中。
有哪些 Java 组件需要占用内存呢?
- 堆内存:Java 堆、类和类加载器
- 栈内存:线程
- 本地内存:NIO、JNI
# #2. 运行时数据区域
JVM 在执行 Java 程序的过程中会把它所管理的内存划分为若干个不同的数据区域。这些区域都有各自的用途,以及创建和销毁的时间,有的区域随着虚拟机进程的启动而存在,有些区域则依赖用户线程的启动和结束而建立和销毁。如下图所示:
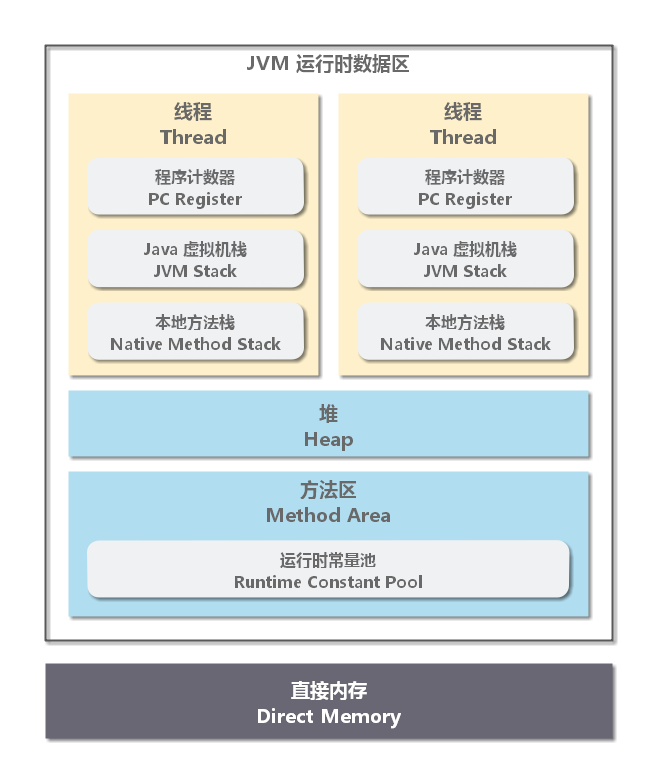
# #2.1. 程序计数器
程序计数器(Program Counter Register) 是一块较小的内存空间,它可以看做是当前线程所执行的字节码的行号指示器。例如,分支、循环、跳转、异常、线程恢复等都依赖于计数器。
当执行的线程数量超过 CPU 数量时,线程之间会根据时间片轮询争夺 CPU 资源。如果一个线程的时间片用完了,或者是其它原因导致这个线程的 CPU 资源被提前抢夺,那么这个退出的线程就需要单独的一个程序计数器,来记录下一条运行的指令,从而在线程切换后能恢复到正确的执行位置。各条线程间的计数器互不影响,独立存储,我们称这类内存区域为 “线程私有” 的内存。
- 如果线程正在执行的是一个 Java 方法,这个计数器记录的是正在执行的虚拟机字节码指令的地址;
- 如果正在执行的是 Native 方法,这个计数器值则为空(Undefined)。
🔔 注意:此内存区域是唯一一个在 JVM 中没有规定任何
OutOfMemoryError情况的区域。
# #2.2. Java 虚拟机栈
Java 虚拟机栈(Java Virtual Machine Stacks) 也是线程私有的,它的生命周期与线程相同。
每个 Java 方法在执行的同时都会创建一个栈帧(Stack Frame)用于存储 局部变量表、操作数栈、常量池引用 等信息。每一个方法从调用直至执行完成的过程,就对应着一个栈帧在 Java 虚拟机栈中入栈和出栈的过程。

- 局部变量表 - 32 位变量槽,存放了编译期可知的各种基本数据类型、对象引用、
ReturnAddress类型。 - 操作数栈 - 基于栈的执行引擎,虚拟机把操作数栈作为它的工作区,大多数指令都要从这里弹出数据、执行运算,然后把结果压回操作数栈。
- 动态链接 - 每个栈帧都包含一个指向运行时常量池(方法区的一部分)中该栈帧所属方法的引用。持有这个引用是为了支持方法调用过程中的动态连接。Class 文件的常量池中有大量的符号引用,字节码中的方法调用指令就以常量池中指向方法的符号引用为参数。这些符号引用一部分会在类加载阶段或第一次使用的时候转化为直接引用,这种转化称为静态解析。另一部分将在每一次的运行期间转化为直接应用,这部分称为动态链接。
- 方法出口 - 返回方法被调用的位置,恢复上层方法的局部变量和操作数栈,如果无返回值,则把它压入调用者的操作数栈。
🔔 注意:
该区域可能抛出以下异常:
- 如果线程请求的栈深度超过最大值,就会抛出
StackOverflowError异常;- 如果虚拟机栈进行动态扩展时,无法申请到足够内存,就会抛出
OutOfMemoryError异常。💡 提示:
可以通过
-Xss这个虚拟机参数来指定一个程序的 Java 虚拟机栈内存大小:java -Xss=512M HackTheJava
# #2.3. 本地方法栈
本地方法栈(Native Method Stack) 与虚拟机栈的作用相似。
二者的区别在于:虚拟机栈为 Java 方法服务;本地方法栈为 Native 方法服务。本地方法并不是用 Java 实现的,而是由 C 语言实现的。

🔔 注意:本地方法栈也会抛出
StackOverflowError异常和OutOfMemoryError异常。
# #2.4. Java 堆
Java 堆(Java Heap) 的作用就是存放对象实例,几乎所有的对象实例都是在这里分配内存。
Java 堆是垃圾收集的主要区域(因此也被叫做 "GC 堆")。现代的垃圾收集器基本都是采用分代收集算法,该算法的思想是针对不同的对象采取不同的垃圾回收算法。
因此虚拟机把 Java 堆分成以下三块:
新生代(Young Generation)Eden- Eden 和 Survivor 的比例为 8:1From SurvivorTo Survivor
-
老年代(Old Generation) -
永久代(Permanent Generation)
当一个对象被创建时,它首先进入新生代,之后有可能被转移到老年代中。新生代存放着大量的生命很短的对象,因此新生代在三个区域中垃圾回收的频率最高。

🔔 注意:Java 堆不需要连续内存,并且可以动态扩展其内存,扩展失败会抛出
OutOfMemoryError异常。💡 提示:可以通过
-Xms和-Xmx两个虚拟机参数来指定一个程序的 Java 堆内存大小,第一个参数设置初始值,第二个参数设置最大值。java -Xms=1M -Xmx=2M HackTheJava
# #2.5. 方法区
方法区(Method Area)也被称为永久代。方法区用于存放已被加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。
对这块区域进行垃圾回收的主要目标是对常量池的回收和对类的卸载,但是一般比较难实现。
🔔 注意:和 Java 堆一样不需要连续的内存,并且可以动态扩展,动态扩展失败一样会抛出
OutOfMemoryError异常。💡 提示:
- JDK 1.7 之前,HotSpot 虚拟机把它当成永久代来进行垃圾回收。可通过参数
-XX:PermSize和-XX:MaxPermSize设置。- JDK 1.8 之后,取消了永久代,用 **
metaspace(元数据)** 区替代。可通过参数-XX:MaxMetaspaceSize设置。
# #2.6. 运行时常量池
运行时常量池(Runtime Constant Pool) 是方法区的一部分,Class 文件中除了有类的版本、字段、方法、接口等描述信息,还有一项信息是常量池(Constant Pool Table),用于存放编译器生成的各种字面量和符号引用,这部分内容会在类加载后被放入这个区域。
- 字面量 - 文本字符串、声明为
final的常量值等。 - 符号引用 - 类和接口的完全限定名(Fully Qualified Name)、字段的名称和描述符(Descriptor)、方法的名称和描述符。
除了在编译期生成的常量,还允许动态生成,例如 String 类的 intern() 。这部分常量也会被放入运行时常量池。
🔔 注意:当常量池无法再申请到内存时会抛出
OutOfMemoryError异常。
# #2.7. 直接内存
直接内存(Direct Memory)并不是虚拟机运行时数据区的一部分,也不是 JVM 规范中定义的内存区域。
在 JDK 1.4 中新加入了 NIO 类,它可以使用 Native 函数库直接分配堆外内存,然后通过一个存储在 Java 堆里的 DirectByteBuffer 对象作为这块内存的引用进行操作。这样能在一些场景中显著提高性能,因为避免了在 Java 堆和 Native 堆中来回复制数据。
🔔 注意:直接内存这部分也被频繁的使用,且也可能导致
OutOfMemoryError异常。💡 提示:直接内存容量可通过
-XX:MaxDirectMemorySize指定,如果不指定,则默认与 Java 堆最大值(-Xmx指定)一样。
# #2.8. Java 内存区域对比
| 内存区域 | 内存作用范围 | 异常 |
|---|---|---|
| 程序计数器 | 线程私有 | 无 |
| Java 虚拟机栈 | 线程私有 | StackOverflowError 和 OutOfMemoryError |
| 本地方法栈 | 线程私有 | StackOverflowError 和 OutOfMemoryError |
| Java 堆 | 线程共享 | OutOfMemoryError |
| 方法区 | 线程共享 | OutOfMemoryError |
| 运行时常量池 | 线程共享 | OutOfMemoryError |
| 直接内存 | 非运行时数据区 | OutOfMemoryError |
# #3. JVM 运行原理
public class JVMCase {
// 常量
public final static String MAN_SEX_TYPE = "man";
// 静态变量
public static String WOMAN_SEX_TYPE = "woman";
public static void main(String[] args) {
Student stu = new Student();
stu.setName("nick");
stu.setSexType(MAN_SEX_TYPE);
stu.setAge(20);
JVMCase jvmcase = new JVMCase();
// 调用静态方法
print(stu);
// 调用非静态方法
jvmcase.sayHello(stu);
}
// 常规静态方法
public static void print(Student stu) {
System.out.println("name: " + stu.getName() + "; sex:" + stu.getSexType() + "; age:" + stu.getAge());
}
// 非静态方法
public void sayHello(Student stu) {
System.out.println(stu.getName() + "say: hello");
}
}
class Student{
String name;
String sexType;
int age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getSexType() {
return sexType;
}
public void setSexType(String sexType) {
this.sexType = sexType;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}运行以上代码时,JVM 处理过程如下:
(1)JVM 向操作系统申请内存,JVM 第一步就是通过配置参数或者默认配置参数向操作系统申请内存空间,根据内存大小找到具体的内存分配表,然后把内存段的起始地址和终止地址分配给 JVM,接下来 JVM 就进行内部分配。
(2)JVM 获得内存空间后,会根据配置参数分配堆、栈以及方法区的内存大小。
(3)class 文件加载、验证、准备以及解析,其中准备阶段会为类的静态变量分配内存,初始化为系统的初始值(这部分我在第 21 讲还会详细介绍)。

(4)完成上一个步骤后,将会进行最后一个初始化阶段。在这个阶段中,JVM 首先会执行构造器 <clinit> 方法,编译器会在 .java 文件被编译成 .class 文件时,收集所有类的初始化代码,包括静态变量赋值语句、静态代码块、静态方法,收集在一起成为 <clinit>() 方法。
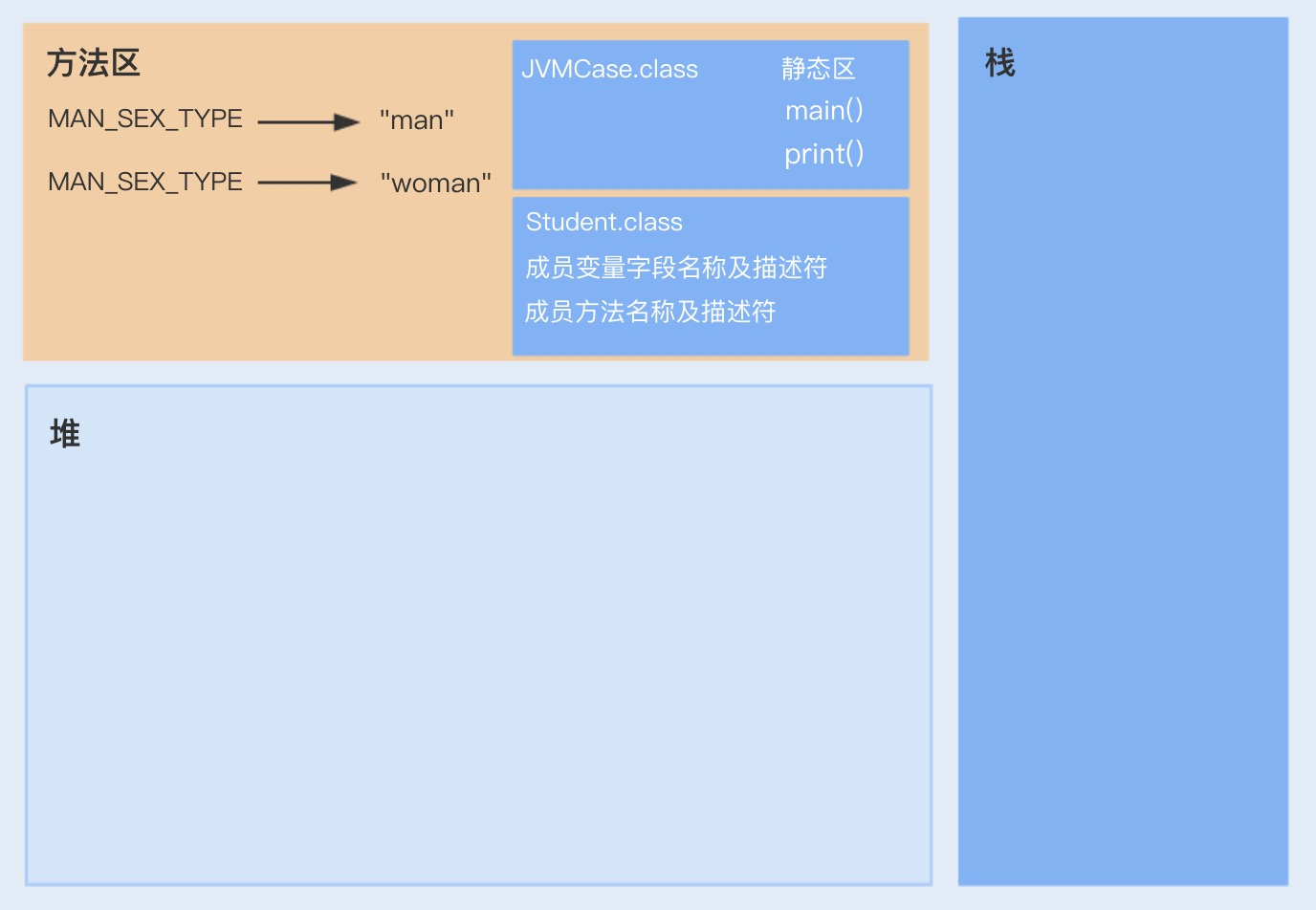
(5)执行方法。启动 main 线程,执行 main 方法,开始执行第一行代码。此时堆内存中会创建一个 student 对象,对象引用 student 就存放在栈中。

(6)此时再次创建一个 JVMCase 对象,调用 sayHello 非静态方法,sayHello 方法属于对象 JVMCase,此时 sayHello 方法入栈,并通过栈中的 student 引用调用堆中的 Student 对象;之后,调用静态方法 print,print 静态方法属于 JVMCase 类,是从静态方法中获取,之后放入到栈中,也是通过 student 引用调用堆中的 student 对象。

# #4. OutOfMemoryError
# #4.1. 什么是 OutOfMemoryError
OutOfMemoryError 简称为 OOM。Java 中对 OOM 的解释是,没有空闲内存,并且垃圾收集器也无法提供更多内存。通俗的解释是:JVM 内存不足了。
在 JVM 规范中,除了程序计数器区域外,其他运行时区域都可能发生 OutOfMemoryError 异常(简称 OOM)。
下面逐一介绍 OOM 发生场景。
# #4.2. 堆空间溢出
java.lang.OutOfMemoryError: Java heap space 这个错误意味着:堆空间溢出。
更细致的说法是:Java 堆内存已经达到 -Xmx 设置的最大值。Java 堆用于存储对象实例,只要不断地创建对象,并且保证 GC Roots 到对象之间有可达路径来避免垃圾收集器回收这些对象,那么当堆空间到达最大容量限制后就会产生 OOM。
堆空间溢出有可能是 ** 内存泄漏(Memory Leak) ** 或 内存溢出(Memory Overflow) 。需要使用 jstack 和 jmap 生成 threaddump 和 heapdump,然后用内存分析工具(如:MAT)进行分析。
# #Java heap space 分析步骤
- 使用
jmap或-XX:+HeapDumpOnOutOfMemoryError获取堆快照。 - 使用内存分析工具(visualvm、mat、jProfile 等)对堆快照文件进行分析。
- 根据分析图,重点是确认内存中的对象是否是必要的,分清究竟是是内存泄漏(Memory Leak)还是内存溢出(Memory Overflow)。
# #内存泄漏
内存泄漏是指由于疏忽或错误造成程序未能释放已经不再使用的内存的情况。
内存泄漏并非指内存在物理上的消失,而是应用程序分配某段内存后,由于设计错误,失去了对该段内存的控制,因而造成了内存的浪费。内存泄漏随着被执行的次数不断增加,最终会导致内存溢出。
内存泄漏常见场景:
- 静态容器
- 声明为静态(
static)的HashMap、Vector等集合 - 通俗来讲 A 中有 B,当前只把 B 设置为空,A 没有设置为空,回收时 B 无法回收。因为被 A 引用。
- 声明为静态(
- 监听器
- 监听器被注册后释放对象时没有删除监听器
- 物理连接
- 各种连接池建立了连接,必须通过
close()关闭链接
- 各种连接池建立了连接,必须通过
- 内部类和外部模块等的引用
- 发现它的方式同内存溢出,可再加个实时观察
jstat -gcutil 7362 2500 70
重点关注:
FGC— 从应用程序启动到采样时发生 Full GC 的次数。FGCT— 从应用程序启动到采样时 Full GC 所用的时间(单位秒)。FGC次数越多,FGCT所需时间越多,越有可能存在内存泄漏。
如果是内存泄漏,可以进一步查看泄漏对象到 GC Roots 的对象引用链。这样就能找到泄漏对象是怎样与 GC Roots 关联并导致 GC 无法回收它们的。掌握了这些原因,就可以较准确的定位出引起内存泄漏的代码。
导致内存泄漏的常见原因是使用容器,且不断向容器中添加元素,但没有清理,导致容器内存不断膨胀。
【示例】
/**
* 内存泄漏示例
* 错误现象:java.lang.OutOfMemoryError: Java heap space
* VM Args:-verbose:gc -Xms10M -Xmx10M -XX:+HeapDumpOnOutOfMemoryError
*/
public class HeapOutOfMemoryDemo {
public static void main(String[] args) {
List<OomObject> list = new ArrayList<>();
while (true) {
list.add(new OomObject());
}
}
static class OomObject {}
}# #内存溢出
如果不存在内存泄漏,即内存中的对象确实都必须存活着,则应当检查虚拟机的堆参数( -Xmx 和 -Xms ),与机器物理内存进行对比,看看是否可以调大。并从代码上检查是否存在某些对象生命周期过长、持有时间过长的情况,尝试减少程序运行期的内存消耗。
【示例】
/**
* 堆溢出示例
* <p>
* 错误现象:java.lang.OutOfMemoryError: Java heap space
* <p>
* VM Args:-verbose:gc -Xms10M -Xmx10M
*
* @author <a href="mailto:forbreak@163.com">Zhang Peng</a>
* @since 2019-06-25
*/
public class HeapOutOfMemoryDemo {
public static void main(String[] args) {
Double[] array = new Double[999999999];
System.out.println("array length = [" + array.length + "]");
}
}执行 java -verbose:gc -Xms10M -Xmx10M -XX:+HeapDumpOnOutOfMemoryError io.github.dunwu.javacore.jvm.memory.HeapMemoryLeakMemoryErrorDemo
上面的例子是一个极端的例子,试图创建一个维度很大的数组,堆内存无法分配这么大的内存,从而报错: Java heap space 。
但如果在现实中,代码并没有问题,仅仅是因为堆内存不足,可以通过 -Xms 和 -Xmx 适当调整堆内存大小。
# #4.3. GC 开销超过限制
java.lang.OutOfMemoryError: GC overhead limit exceeded 这个错误,官方给出的定义是:超过 98% 的时间用来做 GC 并且回收了不到 2% 的堆内存时会抛出此异常。这意味着,发生在 GC 占用大量时间为释放很小空间的时候发生的,是一种保护机制。导致异常的原因:一般是因为堆太小,没有足够的内存。
【示例】
/**
* GC overhead limit exceeded 示例
* 错误现象:java.lang.OutOfMemoryError: GC overhead limit exceeded
* 发生在GC占用大量时间为释放很小空间的时候发生的,是一种保护机制。导致异常的原因:一般是因为堆太小,没有足够的内存。
* 官方对此的定义:超过98%的时间用来做GC并且回收了不到2%的堆内存时会抛出此异常。
* VM Args: -Xms10M -Xmx10M
*/
public class GcOverheadLimitExceededDemo {
public static void main(String[] args) {
List<Double> list = new ArrayList<>();
double d = 0.0;
while (true) {
list.add(d++);
}
}
}【处理】
与 Java heap space 错误处理方法类似,先判断是否存在内存泄漏。如果有,则修正代码;如果没有,则通过 -Xms 和 -Xmx 适当调整堆内存大小。
# #4.4. 永久代空间不足
【错误】
java.lang.OutOfMemoryError: PermGen space【原因】
Perm (永久代)空间主要用于存放 Class 和 Meta 信息,包括类的名称和字段,带有方法字节码的方法,常量池信息,与类关联的对象数组和类型数组以及即时编译器优化。GC 在主程序运行期间不会对永久代空间进行清理,默认是 64M 大小。
根据上面的定义,可以得出 PermGen 大小要求取决于加载的类的数量以及此类声明的大小。因此,可以说造成该错误的主要原因是永久代中装入了太多的类或太大的类。
在 JDK8 之前的版本中,可以通过 -XX:PermSize 和 -XX:MaxPermSize 设置永久代空间大小,从而限制方法区大小,并间接限制其中常量池的容量。
# #初始化时永久代空间不足
【示例】
/**
* 永久代内存空间不足示例
* <p>
* 错误现象:
* <ul>
* <li>java.lang.OutOfMemoryError: PermGen space (JDK8 以前版本)</li>
* <li>java.lang.OutOfMemoryError: Metaspace (JDK8 及以后版本)</li>
* </ul>
* VM Args:
* <ul>
* <li>-Xmx100M -XX:MaxPermSize=16M (JDK8 以前版本)</li>
* <li>-Xmx100M -XX:MaxMetaspaceSize=16M (JDK8 及以后版本)</li>
* </ul>
*/
public class PermOutOfMemoryErrorDemo {
public static void main(String[] args) throws Exception {
for (int i = 0; i < 100_000_000; i++) {
generate("eu.plumbr.demo.Generated" + i);
}
}
public static Class generate(String name) throws Exception {
ClassPool pool = ClassPool.getDefault();
return pool.makeClass(name).toClass();
}
}在此示例中,源代码遍历循环并在运行时生成类。javassist 库正在处理类生成的复杂性。
# #重部署时永久代空间不足
对于更复杂,更实际的示例,让我们逐步介绍一下在应用程序重新部署期间发生的 Permgen 空间错误。重新部署应用程序时,你希望垃圾回收会摆脱引用所有先前加载的类的加载器,并被加载新类的类加载器取代。
不幸的是,许多第三方库以及对线程,JDBC 驱动程序或文件系统句柄等资源的不良处理使得无法卸载以前使用的类加载器。反过来,这意味着在每次重新部署期间,所有先前版本的类仍将驻留在 PermGen 中,从而在每次重新部署期间生成数十兆的垃圾。
让我们想象一个使用 JDBC 驱动程序连接到关系数据库的示例应用程序。启动应用程序时,初始化代码将加载 JDBC 驱动程序以连接到数据库。对应于规范,JDBC 驱动程序向 java.sql.DriverManager 进行注册。该注册包括将对驱动程序实例的引用存储在 DriverManager 的静态字段中。
现在,当从应用程序服务器取消部署应用程序时,java.sql.DriverManager 仍将保留该引用。我们最终获得了对驱动程序类的实时引用,而驱动程序类又保留了用于加载应用程序的 java.lang.Classloader 实例的引用。反过来,这意味着垃圾回收算法无法回收空间。
而且该 java.lang.ClassLoader 实例仍引用应用程序的所有类,通常在 PermGen 中占据数十兆字节。这意味着只需少量重新部署即可填充通常大小的 PermGen。
# #PermGen space 解决方案
(1)解决初始化时的 OutOfMemoryError
在应用程序启动期间触发由于 PermGen 耗尽导致的 OutOfMemoryError 时,解决方案很简单。该应用程序仅需要更多空间才能将所有类加载到 PermGen 区域,因此我们只需要增加其大小即可。为此,更改你的应用程序启动配置并添加(或增加,如果存在) -XX:MaxPermSize 参数,类似于以下示例:
java -XX:MaxPermSize=512m com.yourcompany.YourClass上面的配置将告诉 JVM,PermGen 可以增长到 512MB。
清理应用程序中 WEB-INF/lib 下的 jar,用不上的 jar 删除掉,多个应用公共的 jar 移动到 Tomcat 的 lib 目录,减少重复加载。
🔔 注意: -XX:PermSize 一般设为 64M
(2)解决重新部署时的 OutOfMemoryError
重新部署应用程序后立即发生 OutOfMemoryError 时,应用程序会遭受类加载器泄漏的困扰。在这种情况下,解决问题的最简单,继续进行堆转储分析–使用类似于以下命令的重新部署后进行堆转储:
jmap -dump:format=b,file=dump.hprof <process-id>然后使用你最喜欢的堆转储分析器打开转储(Eclipse MAT 是一个很好的工具)。在分析器中可以查找重复的类,尤其是那些正在加载应用程序类的类。从那里,你需要进行所有类加载器的查找,以找到当前活动的类加载器。
对于非活动类加载器,你需要通过从非活动类加载器收集到 GC 根的最短路径来确定阻止它们被垃圾收集的引用。有了此信息,你将找到根本原因。如果根本原因是在第三方库中,则可以进入 Google/StackOverflow 查看是否是已知问题以获取补丁 / 解决方法。
(3)解决运行时 OutOfMemoryError
第一步是检查是否允许 GC 从 PermGen 卸载类。在这方面,标准的 JVM 相当保守 - 类是天生的。因此,一旦加载,即使没有代码在使用它们,类也会保留在内存中。当应用程序动态创建许多类并且长时间不需要生成的类时,这可能会成为问题。在这种情况下,允许 JVM 卸载类定义可能会有所帮助。这可以通过在启动脚本中仅添加一个配置参数来实现:
-XX:+CMSClassUnloadingEnabled默认情况下,此选项设置为 false,因此要启用此功能,你需要在 Java 选项中显式设置。如果启用 CMSClassUnloadingEnabled,GC 也会扫描 PermGen 并删除不再使用的类。请记住,只有同时使用 UseConcMarkSweepGC 时此选项才起作用。
-XX:+UseConcMarkSweepGC在确保可以卸载类并且问题仍然存在之后,你应该继续进行堆转储分析–使用类似于以下命令的方法进行堆转储:
jmap -dump:file=dump.hprof,format=b <process-id>然后,使用你最喜欢的堆转储分析器(例如 Eclipse MAT)打开转储,然后根据已加载的类数查找最昂贵的类加载器。从此类加载器中,你可以继续提取已加载的类,并按实例对此类进行排序,以使可疑对象排在首位。
然后,对于每个可疑者,就需要你手动将根本原因追溯到生成此类的应用程序代码。
# #4.5. 元数据区空间不足
【错误】
Exception in thread "main" java.lang.OutOfMemoryError: Metaspace【原因】
Java8 以后,JVM 内存空间发生了很大的变化。取消了永久代,转而变为元数据区。
元数据区的内存不足,即方法区和运行时常量池的空间不足。
方法区用于存放 Class 的相关信息,如类名、访问修饰符、常量池、字段描述、方法描述等。
一个类要被垃圾收集器回收,判定条件是比较苛刻的。在经常动态生成大量 Class 的应用中,需要特别注意类的回收状况。这类常见除了 CGLib 字节码增强和动态语言以外,常见的还有:大量 JSP 或动态产生 JSP 文件的应用(JSP 第一次运行时需要编译为 Java 类)、基于 OSGi 的应用(即使是同一个类文件,被不同的加载器加载也会视为不同的类)等。
【示例】方法区出现 OutOfMemoryError
public class MethodAreaOutOfMemoryDemo {
public static void main(String[] args) {
while (true) {
Enhancer enhancer = new Enhancer();
enhancer.setSuperclass(Bean.class);
enhancer.setUseCache(false);
enhancer.setCallback(new MethodInterceptor() {
@Override
public Object intercept(Object obj, Method method, Object[] args, MethodProxy proxy) throws Throwable {
return proxy.invokeSuper(obj, args);
}
});
enhancer.create();
}
}
static class Bean {}
}【解决】
当由于元空间而面临 OutOfMemoryError 时,第一个解决方案应该是显而易见的。如果应用程序耗尽了内存中的 Metaspace 区域,则应增加 Metaspace 的大小。更改应用程序启动配置并增加以下内容:
-XX:MaxMetaspaceSize=512m上面的配置示例告诉 JVM,允许 Metaspace 增长到 512 MB。
另一种解决方案甚至更简单。你可以通过删除此参数来完全解除对 Metaspace 大小的限制,JVM 默认对 Metaspace 的大小没有限制。但是请注意以下事实:这样做可能会导致大量交换或达到本机物理内存而分配失败。
# #4.6. 无法新建本地线程
java.lang.OutOfMemoryError: Unable to create new native thread 这个错误意味着:Java 应用程序已达到其可以启动线程数的限制。
【原因】
当发起一个线程的创建时,虚拟机会在 JVM 内存创建一个 Thread 对象同时创建一个操作系统线程,而这个系统线程的内存用的不是 JVM 内存,而是系统中剩下的内存。
那么,究竟能创建多少线程呢?这里有一个公式:
线程数 = (MaxProcessMemory - JVMMemory - ReservedOsMemory) / (ThreadStackSize)【参数】
MaxProcessMemory- 一个进程的最大内存JVMMemory- JVM 内存ReservedOsMemory- 保留的操作系统内存ThreadStackSize- 线程栈的大小
给 JVM 分配的内存越多,那么能用来创建系统线程的内存就会越少,越容易发生 unable to create new native thread 。所以,JVM 内存不是分配的越大越好。
但是,通常导致 java.lang.OutOfMemoryError 的情况:无法创建新的本机线程需要经历以下阶段:
- JVM 内部运行的应用程序请求新的 Java 线程
- JVM 本机代码代理为操作系统创建新本机线程的请求
- 操作系统尝试创建一个新的本机线程,该线程需要将内存分配给该线程
- 操作系统将拒绝本机内存分配,原因是 32 位 Java 进程大小已耗尽其内存地址空间(例如,已达到(2-4)GB 进程大小限制)或操作系统的虚拟内存已完全耗尽
- 引发
java.lang.OutOfMemoryError: Unable to create new native thread错误。
【示例】
public class UnableCreateNativeThreadErrorDemo {
public static void main(String[] args) {
while (true) {
new Thread(new Runnable() {
@Override
public void run() {
try {
TimeUnit.MINUTES.sleep(5);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}).start();
}
}
}【处理】
可以通过增加操作系统级别的限制来绕过无法创建新的本机线程问题。例如,如果限制了 JVM 可在用户空间中产生的进程数,则应检查出并可能增加该限制:
[root@dev ~]# ulimit -a
core file size (blocks, -c) 0
--- cut for brevity ---
max user processes (-u) 1800通常, OutOfMemoryError 对新的本机线程的限制表示编程错误。当应用程序产生数千个线程时,很可能出了一些问题 — 很少有应用程序可以从如此大量的线程中受益。
解决问题的一种方法是开始进行线程转储以了解情况。
# #4.7. 直接内存溢出
由直接内存导致的内存溢出,一个明显的特征是在 Head Dump 文件中不会看见明显的异常,如果发现 OOM 之后 Dump 文件很小,而程序中又直接或间接使用了 NIO,就可以考虑检查一下是不是这方面的原因。
【示例】直接内存 OutOfMemoryError
/**
* 本机直接内存溢出示例
* 错误现象:java.lang.OutOfMemoryError
* VM Args:-Xmx20M -XX:MaxDirectMemorySize=10M
*/
public class DirectOutOfMemoryDemo {
private static final int _1MB = 1024 * 1024;
public static void main(String[] args) throws IllegalAccessException {
Field unsafeField = Unsafe.class.getDeclaredFields()[0];
unsafeField.setAccessible(true);
Unsafe unsafe = (Unsafe) unsafeField.get(null);
while (true) {
unsafe.allocateMemory(_1MB);
}
}
}# #5. StackOverflowError
对于 HotSpot 虚拟机来说,栈容量只由 -Xss 参数来决定如果线程请求的栈深度大于虚拟机所允许的最大深度,将抛出 StackOverflowError 异常。
从实战来说,栈溢出的常见原因:
- 递归函数调用层数太深
- 大量循环或死循环
【示例】递归函数调用层数太深导致 StackOverflowError
public class StackOverflowDemo {
private int stackLength = 1;
public void recursion() {
stackLength++;
recursion();
}
public static void main(String[] args) {
StackOverflowDemo obj = new StackOverflowDemo();
try {
obj.recursion();
} catch (Throwable e) {
System.out.println("栈深度:" + obj.stackLength);
e.printStackTrace();
}
}
}# JVM 垃圾收集
📦 本文以及示例源码已归档在 javacore(opens new window)
程序计数器、虚拟机栈和本地方法栈这三个区域属于线程私有的,只存在于线程的生命周期内,线程结束之后也会消失,因此不需要对这三个区域进行垃圾回收。垃圾回收主要是针对 Java 堆和方法区进行。
- \1. 对象活着吗
- \2. 垃圾收集算法
- \3. 垃圾收集器
- \4. 内存分配与回收策略
- 5. 参考资料
# #1. 对象活着吗
# #1.1. 引用计数算法
给对象添加一个引用计数器,当对象增加一个引用时计数器加 1,引用失效时计数器减 1。引用计数为 0 的对象可被回收。
两个对象出现循环引用的情况下,此时引用计数器永远不为 0,导致无法对它们进行回收。
public class ReferenceCountingGC {
public Object instance = null;
public static void main(String[] args) {
ReferenceCountingGC objectA = new ReferenceCountingGC();
ReferenceCountingGC objectB = new ReferenceCountingGC();
objectA.instance = objectB;
objectB.instance = objectA;
}
}因为循环引用的存在,所以 Java 虚拟机不适用引用计数算法。
# #1.2. 可达性分析算法
通过 GC Roots 作为起始点进行搜索,JVM 将能够到达到的对象视为存活,不可达的对象视为死亡。
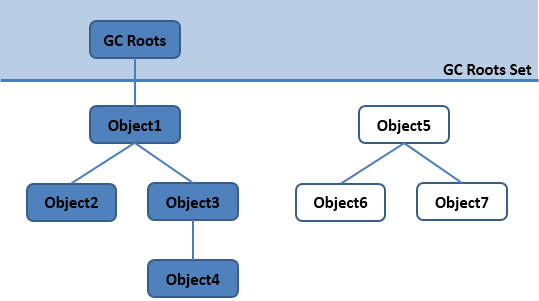
可达性分析算法
可作为 GC Roots 的对象包括下面几种:
- 虚拟机栈中引用的对象
- 本地方法栈中引用的对象(Native 方法)
- 方法区中,类静态属性引用的对象
- 方法区中,常量引用的对象
# #1.3. 引用类型
无论是通过引用计算算法判断对象的引用数量,还是通过可达性分析算法判断对象的引用链是否可达,判定对象是否可被回收都与引用有关。
Java 具有四种强度不同的引用类型。
# #强引用
被强引用(Strong Reference)关联的对象不会被垃圾收集器回收。
强引用:使用 new 一个新对象的方式来创建强引用。
Object obj = new Object();# #软引用
被软引用(Soft Reference)关联的对象,只有在内存不够的情况下才会被回收。
软引用:使用 SoftReference 类来创建软引用。
Object obj = new Object();
SoftReference<Object> sf = new SoftReference<Object>(obj);
obj = null; // 使对象只被软引用关联# #弱引用
被弱引用(Weak Reference)关联的对象一定会被垃圾收集器回收,也就是说它只能存活到下一次垃圾收集发生之前。
使用 WeakReference 类来实现弱引用。
Object obj = new Object();
WeakReference<Object> wf = new WeakReference<Object>(obj);
obj = null;WeakHashMap 的 Entry 继承自 WeakReference ,主要用来实现缓存。
private static class Entry<K,V> extends WeakReference<Object> implements Map.Entry<K,V>Tomcat 中的 ConcurrentCache 就使用了 WeakHashMap 来实现缓存功能。 ConcurrentCache 采取的是分代缓存,经常使用的对象放入 eden 中,而不常用的对象放入 longterm。eden 使用 ConcurrentHashMap 实现,longterm 使用 WeakHashMap ,保证了不常使用的对象容易被回收。
public final class ConcurrentCache<K, V> {
private final int size;
private final Map<K, V> eden;
private final Map<K, V> longterm;
public ConcurrentCache(int size) {
this.size = size;
this.eden = new ConcurrentHashMap<>(size);
this.longterm = new WeakHashMap<>(size);
}
public V get(K k) {
V v = this.eden.get(k);
if (v == null) {
v = this.longterm.get(k);
if (v != null)
this.eden.put(k, v);
}
return v;
}
public void put(K k, V v) {
if (this.eden.size() >= size) {
this.longterm.putAll(this.eden);
this.eden.clear();
}
this.eden.put(k, v);
}
}# #虚引用
又称为幽灵引用或者幻影引用。一个对象是否有虚引用的存在,完全不会对其生存时间构成影响,也无法通过虚引用取得一个对象实例。
为一个对象设置虚引用关联的唯一目的就是能在这个对象被收集器回收时收到一个系统通知。
使用 PhantomReference 来实现虚引用。
Object obj = new Object();
PhantomReference<Object> pf = new PhantomReference<Object>(obj);
obj = null;# #1.4. 方法区的回收
因为方法区主要存放永久代对象,而永久代对象的回收率比年轻代差很多,因此在方法区上进行回收性价比不高。
主要是对常量池的回收和对类的卸载。
类的卸载条件很多,需要满足以下三个条件,并且满足了也不一定会被卸载:
- 该类所有的实例都已经被回收,也就是 Java 堆中不存在该类的任何实例。
- 加载该类的
ClassLoader已经被回收。 - 该类对应的
java.lang.Class对象没有在任何地方被引用,也就无法在任何地方通过反射访问该类方法。
可以通过 -Xnoclassgc 参数来控制是否对类进行卸载。
在大量使用反射、动态代理、CGLib 等字节码框架、动态生成 JSP 以及 OSGi 这类频繁自定义 ClassLoader 的场景都需要虚拟机具备类卸载功能,以保证不会出现内存溢出。
# #1.5. finalize()
finalize() 类似 C++ 的析构函数,用来做关闭外部资源等工作。但是 try-finally 等方式可以做的更好,并且该方法运行代价高昂,不确定性大,无法保证各个对象的调用顺序,因此最好不要使用 finalize() 。
当一个对象可被回收时,如果需要执行该对象的 finalize() 方法,那么就有可能通过在该方法中让对象重新被引用,从而实现自救。
# #2. 垃圾收集算法
# #2.1. 垃圾收集性能
垃圾收集器的性能指标主要有两点:
- 停顿时间 - 停顿时间是因为 GC 而导致程序不能工作的时间长度。
- 吞吐量 - 吞吐量关注在特定的时间周期内一个应用的工作量的最大值。对关注吞吐量的应用来说长暂停时间是可以接受的。由于高吞吐量的应用关注的基准在更长周期时间上,所以快速响应时间不在考虑之内。
# #2.2. 标记 - 清除(Mark-Sweep)
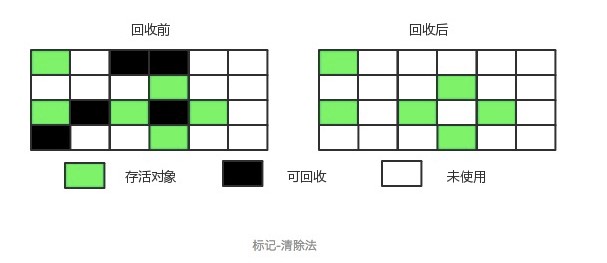
将需要回收的对象进行标记,然后清理掉被标记的对象。
不足:
- 标记和清除过程效率都不高;
- 会产生大量不连续的内存碎片,导致无法给大对象分配内存。
# #2.3. 标记 - 整理(Mark-Compact)
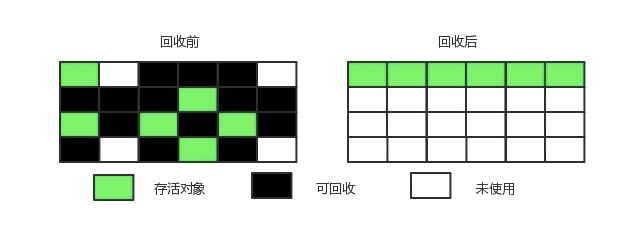
让所有存活的对象都向一端移动,然后直接清理掉端边界以外的内存。
这种做法能够解决内存碎片化的问题,但代价是压缩算法的性能开销。
# #2.4. 复制(Copying)
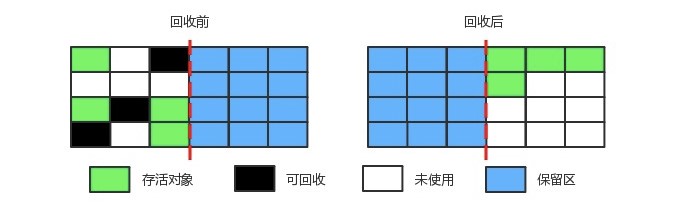
将内存划分为大小相等的两块,每次只使用其中一块,当这一块内存用完了就将还存活的对象复制到另一块上面,然后再把使用过的内存空间进行一次清理。
主要不足是只使用了内存的一半。
现在的商业虚拟机都采用这种收集算法来回收年轻代,但是并不是将内存划分为大小相等的两块,而是分为一块较大的 Eden 空间和两块较小的 Survior 空间,每次使用 Eden 空间和其中一块 Survivor。在回收时,将 Eden 和 Survivor 中还存活着的对象一次性复制到另一块 Survivor 空间上,最后清理 Eden 和使用过的那一块 Survivor。HotSpot 虚拟机的 Eden 和 Survivor 的大小比例默认为 8:1(可以通过参数 -XX:SurvivorRatio 来调整比例),保证了内存的利用率达到 90 %。如果每次回收有多于 10% 的对象存活,那么一块 Survivor 空间就不够用了,此时需要依赖于老年代进行分配担保,也就是借用老年代的空间存储放不下的对象。
# #2.5. 分代收集
现在的商业虚拟机采用分代收集算法,它根据对象存活周期将内存划分为几块,不同块采用适当的收集算法。
一般将 Java 堆分为年轻代和老年代。
- 年轻代使用:复制 算法
- 老年代使用:标记 - 清理 或者 标记 - 整理 算法
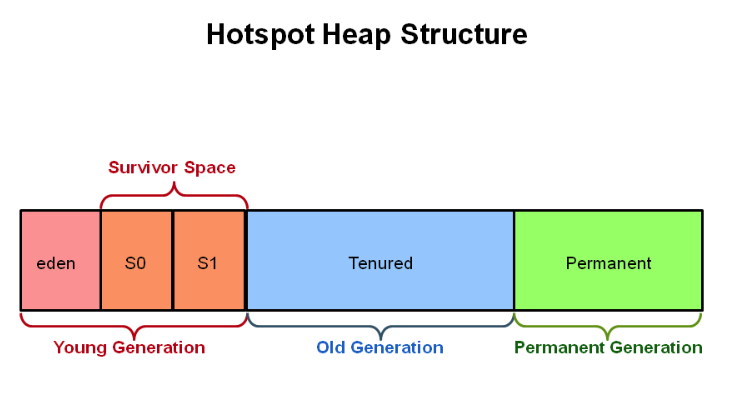
# #新生代
新生代是大部分对象创建和销毁的区域,在通常的 Java 应用中,绝大部分对象生命周期都是很短暂的。其内部又分为 Eden 区域,作为对象初始分配的区域;两个 Survivor ,有时候也叫 from 、 to 区域,被用来放置从 Minor GC 中保留下来的对象。
JVM 会随意选取一个 Survivor 区域作为 to ,然后会在 GC 过程中进行区域间拷贝,也就是将 Eden 中存活下来的对象和 from 区域的对象,拷贝到这个 to 区域。这种设计主要是为了防止内存的碎片化,并进一步清理无用对象。
Java 虚拟机会记录 Survivor 区中的对象一共被来回复制了几次。如果一个对象被复制的次数为 15(对应虚拟机参数 -XX:+MaxTenuringThreshold ),那么该对象将被晋升(promote)至老年代。另外,如果单个 Survivor 区已经被占用了 50%(对应虚拟机参数 -XX:TargetSurvivorRatio ),那么较高复制次数的对象也会被晋升至老年代。
# #老年代
放置长生命周期的对象,通常都是从 Survivor 区域拷贝过来的对象。当然,也有特殊情况,如果对象较大,JVM 会试图直接分配在 Eden 其他位置上;如果对象太大,完全无法在新生代找到足够长的连续空闲空间,JVM 就会直接分配到老年代。
# #永久代
这部分就是早期 Hotspot JVM 的方法区实现方式了,储存 Java 类元数据、常量池、Intern 字符串缓存。在 JDK 8 之后就不存在永久代这块儿了。
# #JVM 参数
这里顺便提一下,JVM 允许对堆空间大小、各代空间大小进行设置,以调整 JVM GC。
| 配置 | 描述 |
|---|---|
-Xss |
虚拟机栈大小。 |
-Xms |
堆空间初始值。 |
-Xmx |
堆空间最大值。 |
-Xmn |
新生代空间大小。 |
-XX:NewSize |
新生代空间初始值。 |
-XX:MaxNewSize |
新生代空间最大值。 |
-XX:NewRatio |
新生代与年老代的比例。默认为 2,意味着老年代是新生代的 2 倍。 |
-XX:SurvivorRatio |
新生代中调整 eden 区与 survivor 区的比例,默认为 8。即 eden 区为 80% 的大小,两个 survivor 分别为 10% 的大小。 |
-XX:PermSize |
永久代空间的初始值。 |
-XX:MaxPermSize |
永久代空间的最大值。 |
# #3. 垃圾收集器
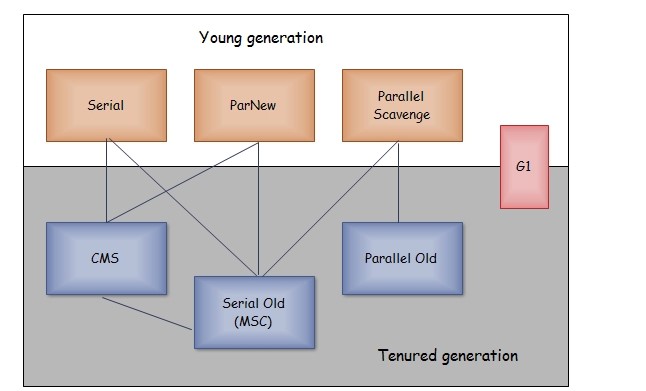
以上是 HotSpot 虚拟机中的 7 个垃圾收集器,连线表示垃圾收集器可以配合使用。
注:G1 垃圾收集器既可以回收年轻代内存,也可以回收老年代内存。而其他垃圾收集器只能针对特定代的内存进行回收。
# #3.1. 串行收集器
串行收集器(Serial)是最基本、发展历史最悠久的收集器。
串行收集器是 client 模式下的默认收集器配置。因为在客户端模式下,分配给虚拟机管理的内存一般来说不会很大。Serial 收集器收集几十兆甚至一两百兆的年轻代停顿时间可以控制在一百多毫秒以内,只要不是太频繁,这点停顿是可以接受的。
串行收集器采用单线程 stop-the-world 的方式进行收集。当内存不足时,串行 GC 设置停顿标识,待所有线程都进入安全点(Safepoint)时,应用线程暂停,串行 GC 开始工作,采用单线程方式回收空间并整理内存。
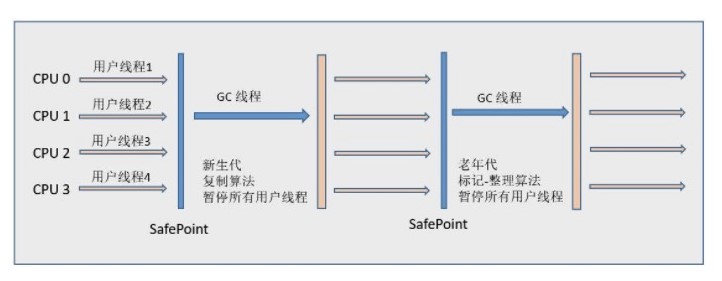
Serial / Serial Old 收集器运行示意图
单线程意味着复杂度更低、占用内存更少,垃圾回收效率高;但同时也意味着不能有效利用多核优势。事实上,串行收集器特别适合堆内存不高、单核甚至双核 CPU 的场合。
# #Serial 收集器
开启选项:
-XX:+UseSerialGC打开此开关后,使用 Serial + Serial Old 收集器组合来进行内存回收。
# #Serial Old 收集器
Serial Old 是 Serial 收集器的老年代版本,也是给 Client 模式下的虚拟机使用。如果用在 Server 模式下,它有两大用途:
- 在 JDK 1.5 以及之前版本(Parallel Old 诞生以前)中与 Parallel Scavenge 收集器搭配使用。
- 作为 CMS 收集器的后备预案,在并发收集发生 Concurrent Mode Failure 时使用。
# #3.2. 并行收集器
开启选项:
-XX:+UseParallelGC打开此开关后,使用 Parallel Scavenge + Serial Old 收集器组合来进行内存回收。
开启选项:
-XX:+UseParallelOldGC打开此开关后,使用 Parallel Scavenge + Parallel Old 收集器组合来进行内存回收。
其他收集器都是以关注停顿时间为目标,而并行收集器是以关注吞吐量(Throughput)为目标的垃圾收集器。
- 停顿时间越短就越适合需要与用户交互的程序,良好的响应速度能提升用户体验;
- 而高吞吐量则可以高效率地利用 CPU 时间,尽快完成程序的运算任务,主要适合在后台运算而不需要太多交互的任务。
吞吐量 = 运行用户代码时间 / (运行用户代码时间 + 垃圾收集时间)并行收集器是 server 模式下的默认收集器。
并行收集器与串行收集器工作模式相似,都是 stop-the-world 方式,只是暂停时并行地进行垃圾收集。并行收集器年轻代采用复制算法,老年代采用标记 - 整理,在回收的同时还会对内存进行压缩。并行收集器适合对吞吐量要求远远高于延迟要求的场景,并且在满足最差延时的情况下,并行收集器将提供最佳的吞吐量。
在注重吞吐量以及 CPU 资源敏感的场合,都可以优先考虑 Parallel Scavenge 收集器 + Parallel Old 收集器。
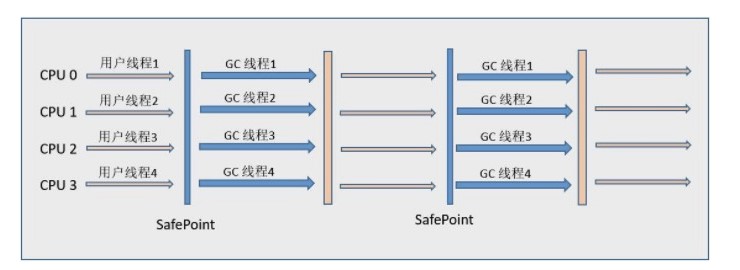
Parallel / Parallel Old 收集器运行示意图
# #Parallel Scavenge 收集器
Parallel Scavenge 收集器提供了两个参数用于精确控制吞吐量,分别是:
-XX:MaxGCPauseMillis- 控制最大垃圾收集停顿时间,收集器将尽可能保证内存回收时间不超过设定值。-XX:GCTimeRatio- 直接设置吞吐量大小的(值为大于 0 且小于 100 的整数)。
缩短停顿时间是以牺牲吞吐量和年轻代空间来换取的:年轻代空间变小,垃圾回收变得频繁,导致吞吐量下降。
Parallel Scavenge 收集器还提供了一个参数 -XX:+UseAdaptiveSizePolicy ,这是一个开关参数,打开参数后,就不需要手工指定年轻代的大小( -Xmn )、Eden 和 Survivor 区的比例( -XX:SurvivorRatio )、晋升老年代对象年龄( -XX:PretenureSizeThreshold )等细节参数了,虚拟机会根据当前系统的运行情况收集性能监控信息,动态调整这些参数以提供最合适的停顿时间或者最大的吞吐量,这种方式称为 GC 自适应的调节策略(GC Ergonomics)。
# #Parallel Old 收集器
是 Parallel Scavenge 收集器的老年代版本,使用多线程和 “标记 - 整理” 算法。
# #3.3. 并发标记清除收集器
开启选项:
-XX:+UseConcMarkSweepGC打开此开关后,使用 CMS + ParNew + Serial Old 收集器组合来进行内存回收。
并发标记清除收集器是以获取最短停顿时间为目标。
开启后,年轻代使用 ParNew 收集器;老年代使用 CMS 收集器,如果 CMS 产生的碎片过多,导致无法存放浮动垃圾,JVM 会出现 Concurrent Mode Failure ,此时使用 Serial Old 收集器来替代 CMS 收集器清理碎片。
# #CMS 收集器
CMS 收集器是一种以获取最短停顿时间为目标的收集器。
CMS(Concurrent Mark Sweep),Mark Sweep 指的是标记 - 清除算法。
# #CMS 回收机制
CMS 收集器运行步骤如下:
- 初始标记:仅仅只是标记一下 GC Roots 能直接关联到的对象,速度很快,需要停顿。
- 并发标记:进行 GC Roots Tracing 的过程,它在整个回收过程中耗时最长,不需要停顿。
- 重新标记:为了修正并发标记期间因用户程序继续运作而导致标记产生变动的那一部分对象的标记记录,需要停顿。
- 并发清除:回收在标记阶段被鉴定为不可达的对象。不需要停顿。
在整个过程中耗时最长的并发标记和并发清除过程中,收集器线程都可以与用户线程一起工作,不需要进行停顿。
CMS 收集器运行示意图
# #CMS 回收年轻代详细步骤
(1)堆空间被分割为三块空间
 年轻代分割成一个 Eden 区和两个 Survivor 区。年老代一个连续的空间。就地完成对象收集。除非有 FullGC 否则不会压缩。
年轻代分割成一个 Eden 区和两个 Survivor 区。年老代一个连续的空间。就地完成对象收集。除非有 FullGC 否则不会压缩。
(2)CMS 年轻代垃圾收集如何工作
年轻代被标为浅绿色,年老代被标记为蓝色。如果你的应用已经运行了一段时间,CMS 的堆看起来应该是这个样子。对象分散在年老代区域里。
使用 CMS,年老代对象就地释放。它们不会被来回移动。这个空间不会被压缩除非发生 FullGC。
(3)年轻代收集
从 Eden 和 Survivor 区复制活跃对象到另一个 Survivor 区。所有达到他们的年龄阈值的对象会晋升到年老代。
 (4) 年轻代回收之后
(4) 年轻代回收之后
一次年轻代垃圾收集之后,Eden 区和其中一个 Survivor 区被清空。
 最近晋升的对象以深蓝色显示在上图中,绿色的对象是年轻代幸免的还没有晋升到老年代对象。
最近晋升的对象以深蓝色显示在上图中,绿色的对象是年轻代幸免的还没有晋升到老年代对象。
# #CMS 回收年老代详细步骤
(1)CMS 的年老代收集
发生两次 stop the world 事件:初始标记和重新标记。当年老代达到特定的占用比例时,CMS 开始执行。
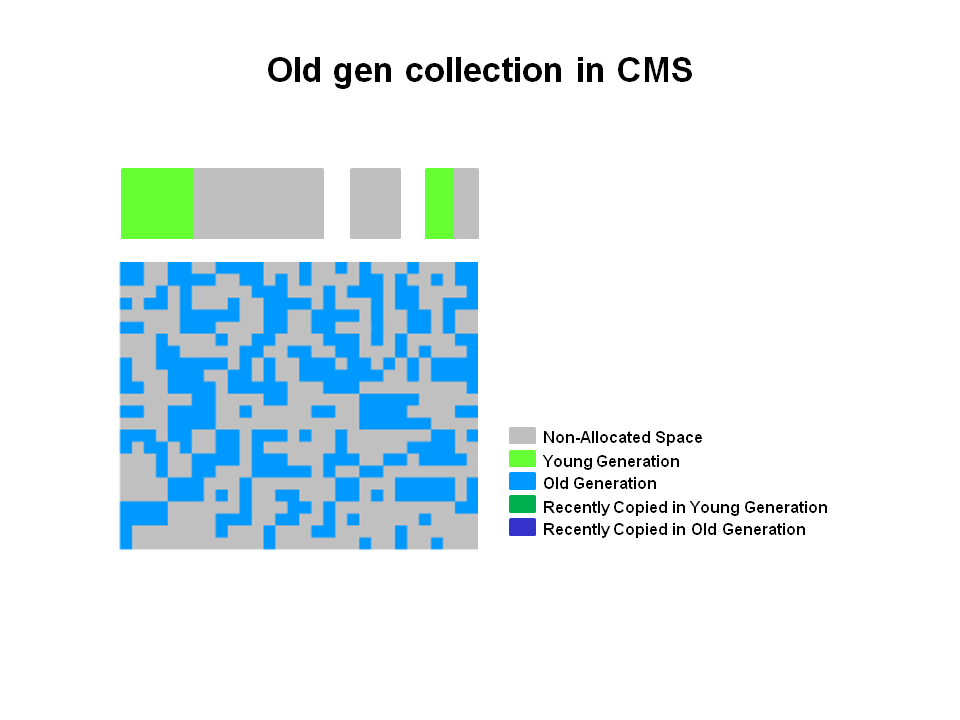
- 初始标记是一个短暂暂停的、可达对象被标记的阶段。
- 并发标记寻找活跃对象在应用连续执行时。
- 最后,在重新标记阶段,寻找在之前并发标记阶段中丢失的对象。
(2)年老代收集 - 并发清除
在之前阶段没有被标记的对象会被就地释放。不进行压缩操作。
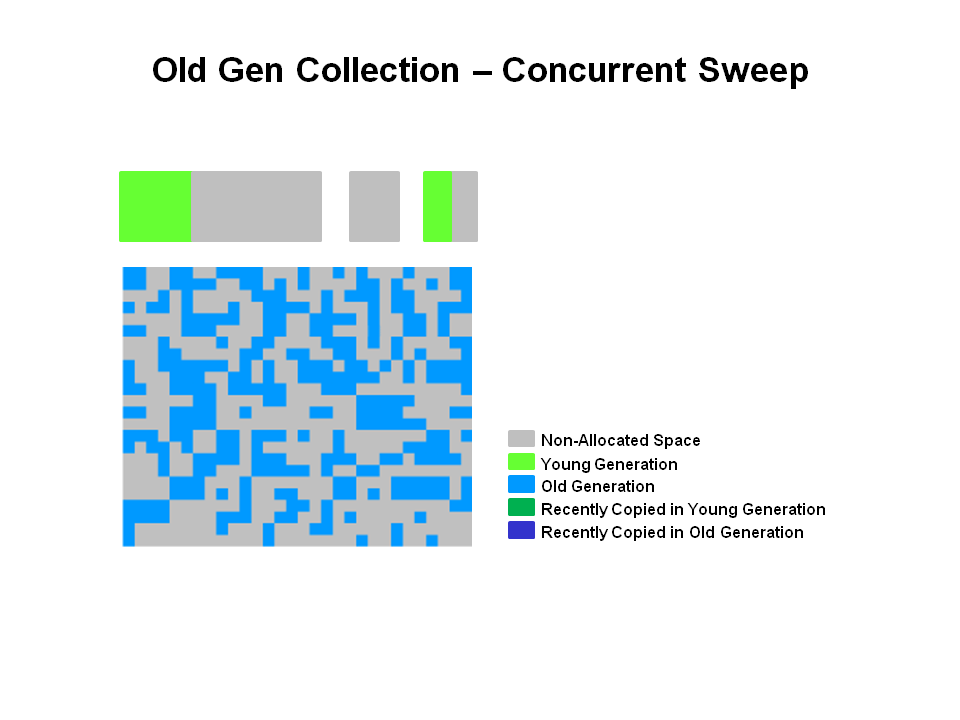 ** 注意:** 未被标记的对象等于死亡对象
** 注意:** 未被标记的对象等于死亡对象
(3)年老代收集 - 清除之后
清除阶段之后,你可以看到大量内存被释放。你还可以注意到没有进行压缩操作。
 最后,CMS 收集器会再次进入重新设置阶段,等待下一次垃圾收集时机的到来。
最后,CMS 收集器会再次进入重新设置阶段,等待下一次垃圾收集时机的到来。
# #CMS 特点
CMS 收集器具有以下缺点:
-
并发收集 - 并发指的是用户线程和 GC 线程同时运行。
-
吞吐量低 - 低停顿时间是以牺牲吞吐量为代价的,导致 CPU 利用率不够高。
-
无法处理浮动垃圾 - 可能出现
Concurrent Mode Failure
。浮动垃圾是指并发清除阶段由于用户线程继续运行而产生的垃圾,这部分垃圾只能到下一次 GC 时才能进行回收。由于浮动垃圾的存在,因此需要预留出一部分内存,意味着 CMS 收集不能像其它收集器那样等待老年代快满的时候再回收。
- 可以使用 `-XX:CMSInitiatingOccupancyFraction` 来改变触发 CMS 收集器工作的内存占用百分,如果这个值设置的太大,导致预留的内存不够存放浮动垃圾,就会出现 `Concurrent Mode Failure`,这时虚拟机将临时启用 Serial Old 收集器来替代 CMS 收集器。
-
标记 - 清除算法导致的空间碎片,往往出现老年代空间剩余,但无法找到足够大连续空间来分配当前对象,不得不提前触发一次 Full GC。
- 可以使用
-XX:+UseCMSCompactAtFullCollection,用于在 CMS 收集器要进行 Full GC 时开启内存碎片的合并整理,内存整理的过程是无法并发的,空间碎片问题没有了,但是停顿时间不得不变长了。 - 可以使用
-XX:CMSFullGCsBeforeCompaction,用于设置执行多少次不压缩的 Full GC 后,来一次带压缩的(默认为 0,表示每次进入 Full GC 时都要进行碎片整理)。
- 可以使用
# #ParNew 收集器
开启选项:
-XX:+UseParNewGC
ParNew 收集器其实是 Serial 收集器的多线程版本。
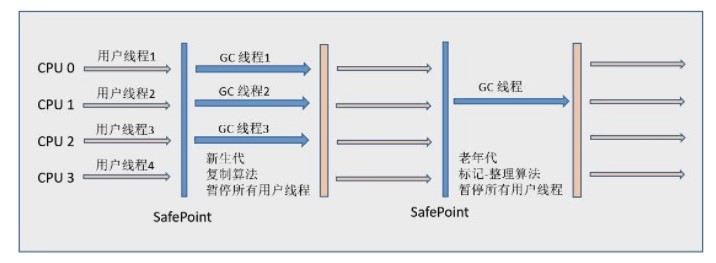
ParNew 收集器运行示意图
是 Server 模式下的虚拟机首选年轻代收集器,除了性能原因外,主要是因为除了 Serial 收集器,只有它能与 CMS 收集器配合工作。
ParNew 收集器也是使用 -XX:+UseConcMarkSweepGC 后的默认年轻代收集器。
ParNew 收集器默认开启的线程数量与 CPU 数量相同,可以使用 - XX:ParallelGCThreads 参数来设置线程数。
# #3.4. G1 收集器
开启选项:
-XX:+UseG1GC
前面提到的垃圾收集器一般策略是关注吞吐量或停顿时间。而 G1 是一种兼顾吞吐量和停顿时间的 GC 收集器。G1 是 Oracle JDK9 以后的默认 GC 收集器。G1 可以直观的设定停顿时间的目标,相比于 CMS GC,G1 未必能做到 CMS 在最好情况下的延时停顿,但是最差情况要好很多。
G1 最大的特点是引入分区的思路,弱化了分代的概念,合理利用垃圾收集各个周期的资源,解决了其他收集器甚至 CMS 的众多缺陷。
# #分代和分区
旧的垃圾收集器一般采取分代收集,Java 堆被分为年轻代、老年代和永久代。收集的范围都是整个年轻代或者整个老年代。
G1 取消了永久代,并把年轻代和老年代划分成多个大小相等的独立区域(Region),年轻代和老年代不再物理隔离。G1 可以直接对年轻代和老年代一起回收。

通过引入 Region 的概念,从而将原来的一整块内存空间划分成多个的小空间,使得每个小空间可以单独进行垃圾回收。这种划分方法带来了很大的灵活性,使得可预测的停顿时间模型成为可能。通过记录每个 Region 垃圾回收时间以及回收所获得的空间(这两个值是通过过去回收的经验获得),并维护一个优先列表,每次根据允许的收集时间,优先回收价值最大的 Region。
每个 Region 都有一个 Remembered Set,用来记录该 Region 对象的引用对象所在的 Region。通过使用 Remembered Set,在做可达性分析的时候就可以避免全堆扫描。
# #G1 回收机制
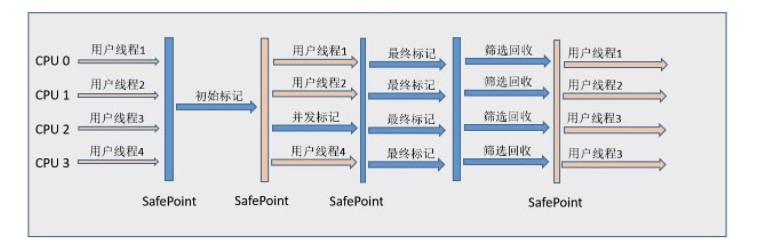
G1 收集器运行示意图
如果不计算维护 Remembered Set 的操作,G1 收集器的运作大致可划分为以下几个步骤:
- 初始标记
- 并发标记
- 最终标记 - 为了修正在并发标记期间因用户程序继续运作而导致标记产生变动的那一部分标记记录,虚拟机将这段时间对象变化记录在线程的 Remembered Set Logs 里面,最终标记阶段需要把 Remembered Set Logs 的数据合并到 Remembered Set 中。这阶段需要停顿线程,但是可并行执行。
- 筛选回收 - 首先对各个 Region 中的回收价值和成本进行排序,根据用户所期望的 GC 停顿是时间来制定回收计划。此阶段其实也可以做到与用户程序一起并发执行,但是因为只回收一部分 Region,时间是用户可控制的,而且停顿用户线程将大幅度提高收集效率。
具备如下特点:
- 空间整合:整体来看是基于 “标记 - 整理” 算法实现的收集器,从局部(两个 Region 之间)上来看是基于 “复制” 算法实现的,这意味着运行期间不会产生内存空间碎片。
- 可预测的停顿:能让使用者明确指定在一个长度为 M 毫秒的时间片段内,消耗在 GC 上的时间不得超过 N 毫秒。
# #G1 回收年轻代详细步骤
(1)G1 初始堆空间
堆空间是一个被分成许多固定大小区域的内存块。
 Java 虚拟机启动时选定区域大小。Java 虚拟机通常会指定 2000 个左右的大小相等、每个大小范围在 1 到 32M 的区域。
Java 虚拟机启动时选定区域大小。Java 虚拟机通常会指定 2000 个左右的大小相等、每个大小范围在 1 到 32M 的区域。
(2)G1 堆空间分配
实际上,这些区域被映射成 Eden、Survivor、年老代空间的逻辑表述形式。
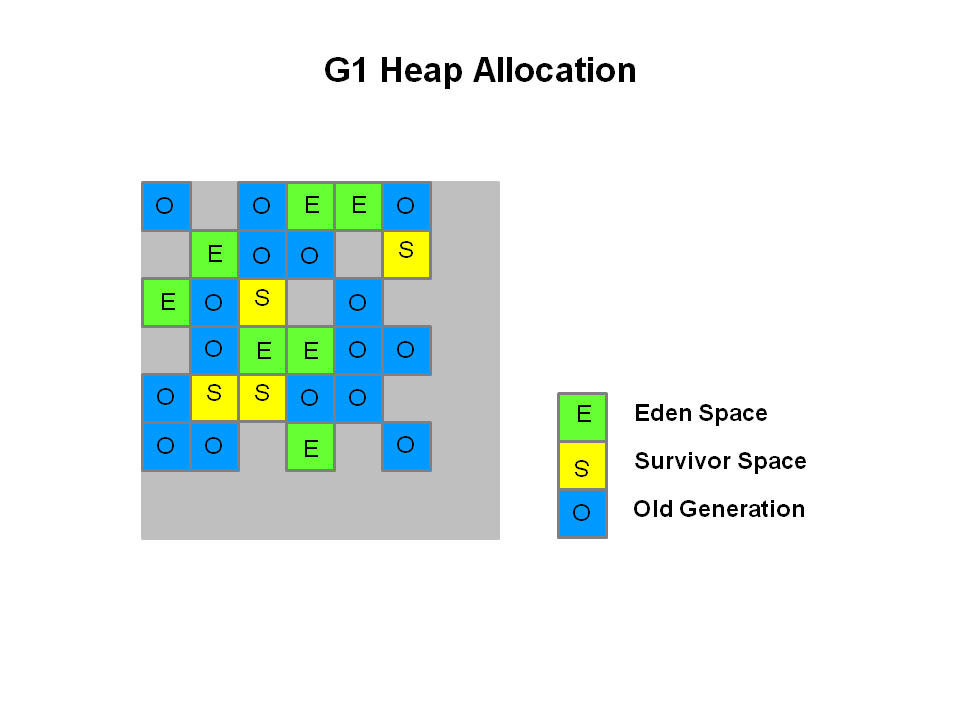 图片中的颜色表明了哪个区域被关联上什么角色。活跃对象从一个区域疏散(复制、移动) 到另一个区域。区域被设计为并行的方式收集,可以暂停或者不暂停所有的其它用户线程。
图片中的颜色表明了哪个区域被关联上什么角色。活跃对象从一个区域疏散(复制、移动) 到另一个区域。区域被设计为并行的方式收集,可以暂停或者不暂停所有的其它用户线程。
明显的区域可以被分配成 Eden、Survivor、Old 区域。另外,有第四种类型的区域叫做极大区域 (Humongous regions)。这些区域被设计成保持标准区域大小的 50% 或者更大的对象。它们被保存在一个连续的区域集合里。最后,最后一个类型的区域就是堆空间里没有使用的区域。
** 注意:** 写作此文章时,收集极大对象时还没有被优化。因此,你应该避免创建这个大小的对象。
(3)G1 的年轻代
堆空间被分割成大约 2000 个区域。最小 1M,最大 32M,蓝色区域保持年老代对象,绿色区域保持年轻代对象。
 ** 注意:** 区域没有必要像旧的收集器一样是保持连续的。
** 注意:** 区域没有必要像旧的收集器一样是保持连续的。
(4)G1 的年轻代收集
活跃对象会被疏散(复制、移动)到一个或多个 survivor 区域。如果达到晋升总阈值,对象会晋升到年老代区域。
 这是一个 stop the world 暂停。为下一次年轻代垃圾回收计算 Eden 和 Survivor 的大小。保留审计信息有助于计算大小。类似目标暂停时间的事情会被考虑在内。
这是一个 stop the world 暂停。为下一次年轻代垃圾回收计算 Eden 和 Survivor 的大小。保留审计信息有助于计算大小。类似目标暂停时间的事情会被考虑在内。
这个方法使重调区域大小变得很容易,按需把它们调大或调小。
(5)G1 年轻代回收的尾声
活跃对象被疏散到 Survivor 或者年老代区域。
 最近晋升的对象显示为深蓝色。Survivor 区域显示为绿色。
最近晋升的对象显示为深蓝色。Survivor 区域显示为绿色。
关于 G1 的年轻代回收做以下总结:
- 堆空间是一块单独的内存空间被分割成多个区域。
- 年轻代内存是由一组非连续的区域组成。这使得需要重调大小变得容易。
- 年轻代垃圾回收是 stop the world 事件,所有应用线程都会因此操作暂停。
- 年轻代垃圾收集使用多线程并行回收。
- 活跃对象被复制到新的 Survivor 区或者年老代区域。
# #G1 回收年老代详细步骤
(1)初始标记阶段
年轻代垃圾收集肩负着活跃对象初始标记的任务。在日志文件中被标为 GC pause (young)(inital-mark)
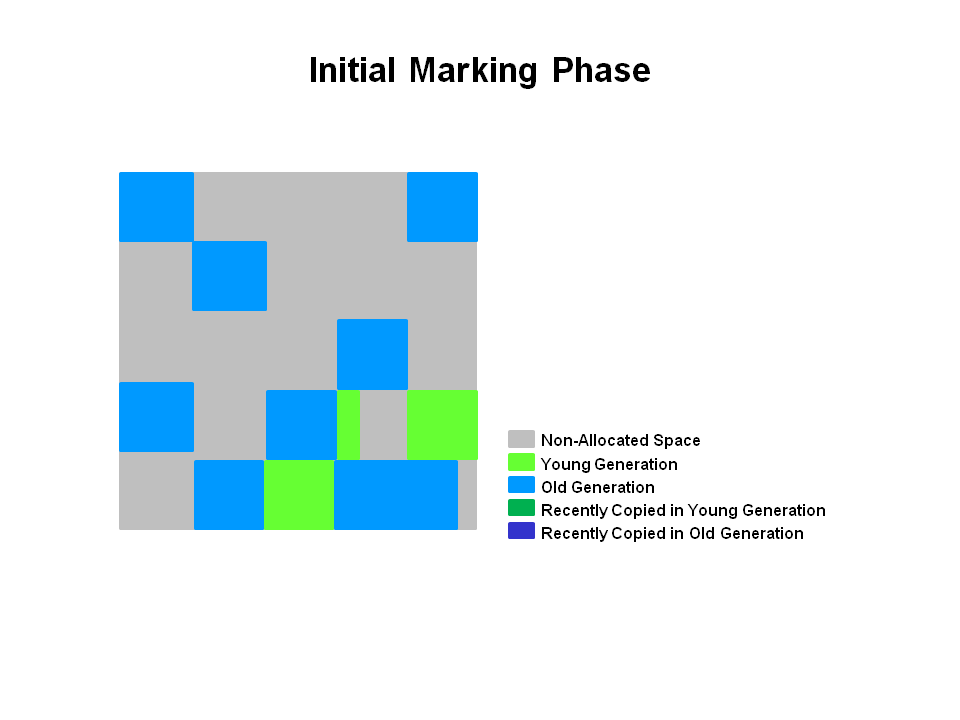 (2) 并发标记阶段
(2) 并发标记阶段
如果发现空区域 (“X” 标示的),在重新标记阶段它们会被马上清除掉。当然,决定活性的审计信息也在此时被计算。
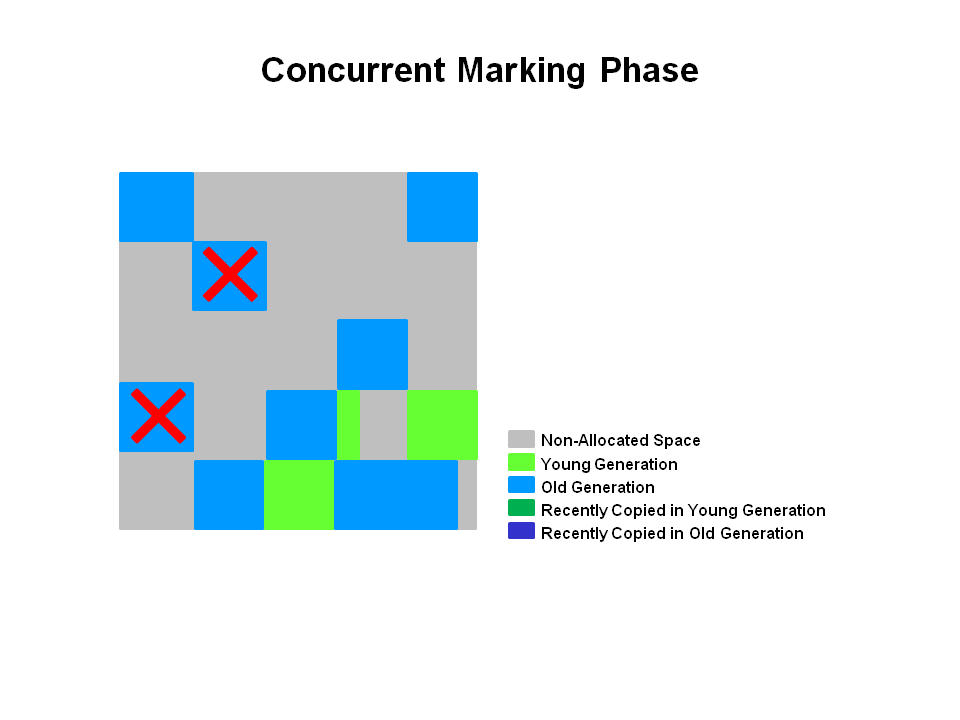 (3) 重新标记阶段
(3) 重新标记阶段
空的区域被清除和回收掉。所有区域的活性在此时计算。
 (4) 复制 / 清理阶段
(4) 复制 / 清理阶段
G1 选择活性最低的区域,这些区域能够以最快的速度回收。然后这些区域会在年轻代垃圾回收过程中被回收。在日志中被指示为 *[GC pause (mixed)]*。所以年轻代和年老代在同一时间被回收。
 (5) 复制 / 清理阶段之后
(5) 复制 / 清理阶段之后
被选择的区域已经被回收和压缩到图中显示的深蓝色区和深绿色区中。

# #3.5. 总结
| 收集器 | 串行 / 并行 / 并发 | 年轻代 / 老年代 | 收集算法 | 目标 | 适用场景 |
|---|---|---|---|---|---|
| Serial | 串行 | 年轻代 | 复制 | 响应速度优先 | 单 CPU 环境下的 Client 模式 |
| Serial Old | 串行 | 老年代 | 标记 - 整理 | 响应速度优先 | 单 CPU 环境下的 Client 模式、CMS 的后备预案 |
| ParNew | 串行 + 并行 | 年轻代 | 复制算法 | 响应速度优先 | 多 CPU 环境时在 Server 模式下与 CMS 配合 |
| Parallel Scavenge | 串行 + 并行 | 年轻代 | 复制算法 | 吞吐量优先 | 在后台运算而不需要太多交互的任务 |
| Parallel Old | 串行 + 并行 | 老年代 | 标记 - 整理 | 吞吐量优先 | 在后台运算而不需要太多交互的任务 |
| CMS | 并行 + 并发 | 老年代 | 标记 - 清除 | 响应速度优先 | 集中在互联网站或 B/S 系统服务端上的 Java 应用 |
| G1 | 并行 + 并发 | 年轻代 + 老年代 | 标记 - 整理 + 复制算法 | 响应速度优先 | 面向服务端应用,将来替换 CMS |
# #4. 内存分配与回收策略
对象的内存分配,也就是在堆上分配。主要分配在年轻代的 Eden 区上,少数情况下也可能直接分配在老年代中。
# #4.1. Minor GC
当 Eden 区空间不足时,触发 Minor GC。
Minor GC 发生在年轻代上,因为年轻代对象存活时间很短,因此 Minor GC 会频繁执行,执行的速度一般也会比较快。
Minor GC 工作流程:
- Java 应用不断创建对象,通常都是分配在
Eden区域,当其空间不足时(达到设定的阈值),触发 minor GC。仍然被引用的对象(绿色方块)存活下来,被复制到 JVM 选择的 Survivor 区域,而没有被引用的对象(黄色方块)则被回收。 - 经过一次 Minor GC,Eden 就会空闲下来,直到再次达到 Minor GC 触发条件。这时候,另外一个 Survivor 区域则会成为
To区域,Eden 区域的存活对象和From区域对象,都会被复制到To区域,并且存活的年龄计数会被加 1。 - 类似第二步的过程会发生很多次,直到有对象年龄计数达到阈值,这时候就会发生所谓的晋升(Promotion)过程,如下图所示,超过阈值的对象会被晋升到老年代。这个阈值是可以通过
-XX:MaxTenuringThreshold参数指定。
# #4.2. Full GC
Full GC 发生在老年代上,老年代对象和年轻代的相反,其存活时间长,因此 Full GC 很少执行,而且执行速度会比 Minor GC 慢很多。
# #内存分配策略
(一)对象优先在 Eden 分配
大多数情况下,对象在年轻代 Eden 区分配,当 Eden 区空间不够时,发起 Minor GC。
(二)大对象直接进入老年代
大对象是指需要连续内存空间的对象,最典型的大对象是那种很长的字符串以及数组。
经常出现大对象会提前触发垃圾收集以获取足够的连续空间分配给大对象。
-XX:PretenureSizeThreshold ,大于此值的对象直接在老年代分配,避免在 Eden 区和 Survivor 区之间的大量内存复制。
(三)长期存活的对象进入老年代
为对象定义年龄计数器,对象在 Eden 出生并经过 Minor GC 依然存活,将移动到 Survivor 中,年龄就增加 1 岁,增加到一定年龄则移动到老年代中。
-XX:MaxTenuringThreshold 用来定义年龄的阈值。
(四)动态对象年龄判定
虚拟机并不是永远地要求对象的年龄必须达到 MaxTenuringThreshold 才能晋升老年代,如果在 Survivor 区中相同年龄所有对象大小的总和大于 Survivor 空间的一半,则年龄大于或等于该年龄的对象可以直接进入老年代,无需等到 MaxTenuringThreshold 中要求的年龄。
(五)空间分配担保
在发生 Minor GC 之前,虚拟机先检查老年代最大可用的连续空间是否大于年轻代所有对象总空间,如果条件成立的话,那么 Minor GC 可以确认是安全的;如果不成立的话虚拟机会查看 HandlePromotionFailure 设置值是否允许担保失败,如果允许那么就会继续检查老年代最大可用的连续空间是否大于历次晋升到老年代对象的平均大小,如果大于,将尝试着进行一次 Minor GC,尽管这次 Minor GC 是有风险的;如果小于,或者 HandlePromotionFailure 设置不允许冒险,那这时也要改为进行一次 Full GC。
# #Full GC 的触发条件
对于 Minor GC,其触发条件非常简单,当 Eden 区空间满时,就将触发一次 Minor GC。而 Full GC 则相对复杂,有以下条件:
(1)调用 System.gc()
此方法的调用是建议虚拟机进行 Full GC,虽然只是建议而非一定,但很多情况下它会触发 Full GC,从而增加 Full GC 的频率,也即增加了间歇性停顿的次数。因此强烈建议能不使用此方法就不要使用,让虚拟机自己去管理它的内存。可通过 -XX:DisableExplicitGC 来禁止 RMI 调用 System.gc() 。
(2)老年代空间不足
老年代空间不足的常见场景为前文所讲的大对象直接进入老年代、长期存活的对象进入老年代等,当执行 Full GC 后空间仍然不足,则抛出 java.lang.OutOfMemoryError: Java heap space 。为避免以上原因引起的 Full GC,调优时应尽量做到让对象在 Minor GC 阶段被回收、让对象在年轻代多存活一段时间以及不要创建过大的对象及数组。
(3)方法区空间不足
JVM 规范中运行时数据区域中的方法区,在 HotSpot 虚拟机中又被习惯称为永久代,永久代中存放的是类的描述信息、常量、静态变量等数据,当系统中要加载的类、反射的类和调用的方法较多时,永久代可能会被占满,在未配置为采用 CMS GC 的情况下也会执行 Full GC。如果经过 Full GC 仍然回收不了,那么 JVM 会抛出 java.lang.OutOfMemoryError: PermGen space 错误。为避免永久代占满造成 Full GC 现象,可采用的方法为增大 Perm Gen 空间或转为使用 CMS GC。
(4)Minor GC 的平均晋升空间大小大于老年代可用空间
如果发现统计数据说之前 Minor GC 的平均晋升大小比目前老年代剩余的空间大,则不会触发 Minor GC 而是转为触发 Full GC。
(5)对象大小大于 To 区和老年代的可用内存
由 Eden 区、 From 区向 To 区复制时,对象大小大于 To 区可用内存,则把该对象转存到老年代,且老年代的可用内存小于该对象大小
# JVM 字节码
Java 之所以可以 “一次编译,到处运行”,一是因为 JVM 针对各种操作系统、平台都进行了定制,二是因为无论在什么平台,都可以编译生成固定格式的字节码(.class 文件)供 JVM 使用。
.class 文件是一组以 8 位字节为基础单位的二进制流,各个数据项严格按照顺序紧凑地排列在 .class 文件中,中间没有添加任何分隔符。整个 .class 文件本质上就是一张表。
- \1. 字节码
- \2. 字节码增强
- 3. 参考资料
# #1. 字节码
# #1.1. 什么是字节码
之所以被称之为字节码,是因为字节码文件由十六进制值组成,而 JVM 以两个十六进制值为一组,即以字节为单位进行读取。在 Java 中一般是用 javac 命令编译源代码为字节码文件,一个.java 文件从编译到运行的示例如下图所示。

对于开发人员,了解字节码可以更准确、直观地理解 Java 语言中更深层次的东西,比如通过字节码,可以很直观地看到 Volatile 关键字如何在字节码上生效。另外,字节码增强技术在 Spring AOP、各种 ORM 框架、热部署中的应用屡见不鲜,深入理解其原理对于我们来说大有裨益。除此之外,由于 JVM 规范的存在,只要最终可以生成符合规范的字节码就可以在 JVM 上运行,因此这就给了各种运行在 JVM 上的语言(如 Scala、Groovy、Kotlin)一种契机,可以扩展 Java 所没有的特性或者实现各种语法糖。理解字节码后再学习这些语言,可以 “逆流而上”,从字节码视角看它的设计思路,学习起来也 “易如反掌”。
# #1.2. 字节码结构
.java 文件通过 javac 编译后将得到一个.class 文件,比如编写一个简单的 ByteCodeDemo 类,如下图 2 的左侧部分:
编译后生成 ByteCodeDemo.class 文件,打开后是一堆十六进制数,按字节为单位进行分割后展示如图 2 右侧部分所示。上文提及过,JVM 对于字节码是有规范要求的,那么看似杂乱的十六进制符合什么结构呢?JVM 规范要求每一个字节码文件都要由十部分按照固定的顺序组成,整体结构如图 3 所示。接下来我们将一一介绍这十部分:
(1)魔数(Magic Number)
每个 .class 文件的头 4 个字节称为 魔数(magic number) ,它的唯一作用是确定这个文件是否为一个能被虚拟机接收的 .class 文件。魔数的固定值为: 0xCAFEBABE 。
有趣的是,魔数的固定值是 Java 之父 James Gosling 制定的,为 CafeBabe(咖啡宝贝),而 Java 的图标为一杯咖啡。
(2)版本号(Version)
版本号为魔数之后的 4 个字节,前两个字节表示次版本号(Minor Version),后两个字节表示主版本号(Major Version)。
举例来说,如果版本号为:“00 00 00 34”。那么,次版本号转化为十进制为 0,主版本号转化为十进制为 52,在 Oracle 官网中查询序号 52 对应的主版本号为 1.8,所以编译该文件的 Java 版本号为 1.8.0。
(3)常量池(Constant Pool)
紧接着主版本号之后的字节为常量池入口。
常量池主要存放两类常量:
- 字面量 - 如文本字符串、声明为
final的常量值。 - 符号引用
- 类和接口的全限定名
- 字段的名称和描述符
- 方法的名称和描述符
常量池整体上分为两部分:常量池计数器以及常量池数据区,如下图 4 所示。
- 常量池计数器(constant_pool_count) - 由于常量的数量不固定,所以需要先放置两个字节来表示常量池容量计数值。图 2 中示例代码的字节码前 10 个字节如下图 5 所示,将十六进制的 24 转化为十进制值为 36,排除掉下标 “0”,也就是说,这个类文件中共有 35 个常量。
- 常量池数据区 - 数据区是由(
constant_pool_count-1)个 cp_info 结构组成,一个 cp_info 结构对应一个常量。在字节码中共有 14 种类型的 cp_info(如下图 6 所示),每种类型的结构都是固定的。
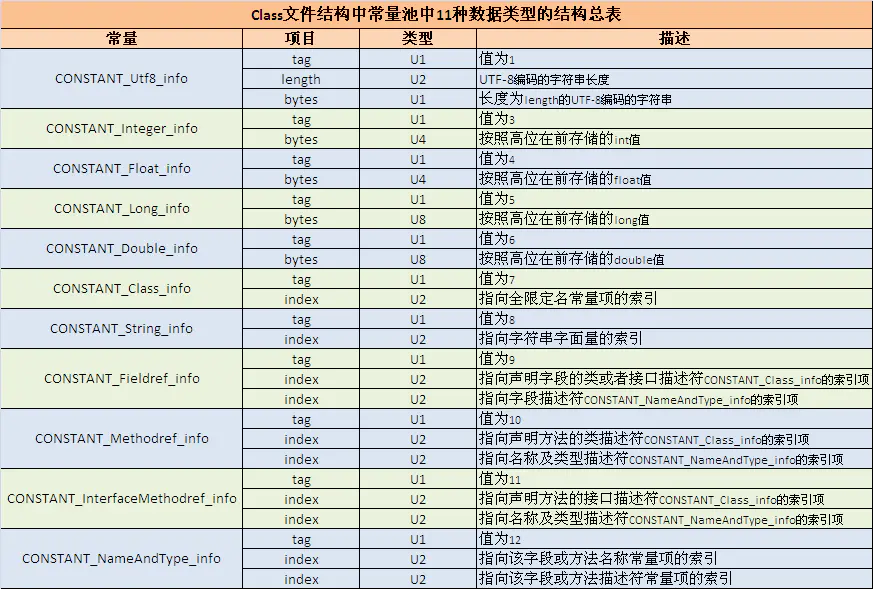
具体以 CONSTANT_utf8_info 为例,它的结构如下图 7 左侧所示。首先一个字节 “tag”,它的值取自上图 6 中对应项的 Tag,由于它的类型是 utf8_info,所以值为 “01”。接下来两个字节标识该字符串的长度 Length,然后 Length 个字节为这个字符串具体的值。从图 2 中的字节码摘取一个 cp_info 结构,如下图 7 右侧所示。将它翻译过来后,其含义为:该常量类型为 utf8 字符串,长度为一字节,数据为 “a”。
其他类型的 cp_info 结构在本文不再赘述,整体结构大同小异,都是先通过 Tag 来标识类型,然后后续 n 个字节来描述长度和(或)数据。先知其所以然,以后可以通过 javap -verbose ByteCodeDemo 命令,查看 JVM 反编译后的完整常量池,如下图 8 所示。可以看到反编译结果将每一个 cp_info 结构的类型和值都很明确地呈现了出来。
(4)访问标志
紧接着的 2 个字节代表访问标志,这个标志用于识别一些类或者接口的访问信息,描述该 Class 是类还是接口,以及是否被 public 、 abstract 、 final 等修饰符修饰。
JVM 规范规定了如下图 9 的访问标志(Access_Flag)。需要注意的是,JVM 并没有穷举所有的访问标志,而是使用按位或操作来进行描述的,比如某个类的修饰符为 Public Final,则对应的访问修饰符的值为 ACC_PUBLIC | ACC_FINAL,即 0x0001 | 0x0010=0x0011。
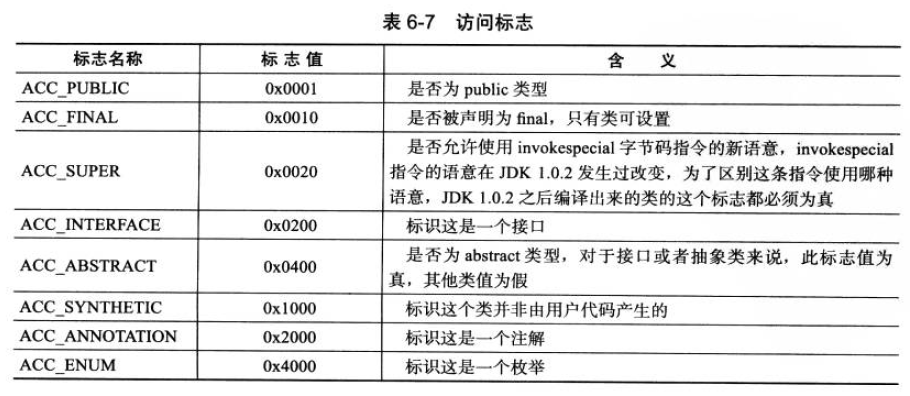 (5) 当前类名
(5) 当前类名
访问标志后的 2 个字节,描述的是当前类的全限定名。这两个字节保存的值为常量池中的索引值,根据索引值就能在常量池中找到这个类的全限定名。
(6)父类名称
当前类名后的 2 个字节,描述父类的全限定名,同上,保存的也是常量池中的索引值。
(7)接口信息
父类名称后为 2 字节的接口计数器,描述了该类或父类实现的接口数量。紧接着的 n 个字节是所有接口名称的字符串常量的索引值。
(8)字段表
字段表用于描述类和接口中声明的变量,包含类级别的变量以及实例变量,但是不包含方法内部声明的局部变量。字段表也分为两部分,第一部分为两个字节,描述字段个数;第二部分是每个字段的详细信息 fields_info。字段表结构如下图所示:
以图 2 中字节码的字段表为例,如下图 11 所示。其中字段的访问标志查图 9,0002 对应为 Private。通过索引下标在图 8 中常量池分别得到字段名为 “a”,描述符为 “I”(代表 int)。综上,就可以唯一确定出一个类中声明的变量 private int a。
(9)方法表
字段表结束后为方法表,方法表也是由两部分组成,第一部分为两个字节描述方法的个数;第二部分为每个方法的详细信息。方法的详细信息较为复杂,包括方法的访问标志、方法名、方法的描述符以及方法的属性,如下图所示:
方法的权限修饰符依然可以通过图 9 的值查询得到,方法名和方法的描述符都是常量池中的索引值,可以通过索引值在常量池中找到。而 “方法的属性” 这一部分较为复杂,直接借助 javap -verbose 将其反编译为人可以读懂的信息进行解读,如图 13 所示。可以看到属性中包括以下三个部分:
- “Code 区”:源代码对应的 JVM 指令操作码,在进行字节码增强时重点操作的就是 “Code 区” 这一部分。
- “LineNumberTable”:行号表,将 Code 区的操作码和源代码中的行号对应,Debug 时会起到作用(源代码走一行,需要走多少个 JVM 指令操作码)。
- “LocalVariableTable”:本地变量表,包含 This 和局部变量,之所以可以在每一个方法内部都可以调用 This,是因为 JVM 将 This 作为每一个方法的第一个参数隐式进行传入。当然,这是针对非 Static 方法而言。
(10)附加属性表
字节码的最后一部分,该项存放了在该文件中类或接口所定义属性的基本信息。
# #1.3. 字节码操作集合
在上图 13 中,Code 区的红色编号 0 ~ 17,就是.java 中的方法源代码编译后让 JVM 真正执行的操作码。为了帮助人们理解,反编译后看到的是十六进制操作码所对应的助记符,十六进制值操作码与助记符的对应关系,以及每一个操作码的用处可以查看 Oracle 官方文档进行了解,在需要用到时进行查阅即可。比如上图中第一个助记符为 iconst_2,对应到图 2 中的字节码为 0x05,用处是将 int 值 2 压入操作数栈中。以此类推,对 0~17 的助记符理解后,就是完整的 add () 方法的实现。
# #1.4. 操作数栈和字节码
JVM 的指令集是基于栈而不是寄存器,基于栈可以具备很好的跨平台性(因为寄存器指令集往往和硬件挂钩),但缺点在于,要完成同样的操作,基于栈的实现需要更多指令才能完成(因为栈只是一个 FILO 结构,需要频繁压栈出栈)。另外,由于栈是在内存实现的,而寄存器是在 CPU 的高速缓存区,相较而言,基于栈的速度要慢很多,这也是为了跨平台性而做出的牺牲。
我们在上文所说的操作码或者操作集合,其实控制的就是这个 JVM 的操作数栈。为了更直观地感受操作码是如何控制操作数栈的,以及理解常量池、变量表的作用,将 add () 方法的对操作数栈的操作制作为 GIF,如下图 14 所示,图中仅截取了常量池中被引用的部分,以指令 iconst_2 开始到 ireturn 结束,与图 13 中 Code 区 0~17 的指令一一对应:
# #1.5. 字节码工具
如果每次查看反编译后的字节码都使用 javap 命令的话,好非常繁琐。这里推荐一个 Idea 插件:jclasslib (opens new window)。使用效果如图 15 所示,代码编译后在菜单栏 "View" 中选择 "Show Bytecode With jclasslib",可以很直观地看到当前字节码文件的类信息、常量池、方法区等信息。
# #2. 字节码增强
# #2.1. Asm
对于需要手动操纵字节码的需求,可以使用 Asm,它可以直接生产 .class 字节码文件,也可以在类被加载入 JVM 之前动态修改类行为(如下图 17 所示)。
Asm 的应用场景有 AOP(Cglib 就是基于 Asm)、热部署、修改其他 jar 包中的类等。当然,涉及到如此底层的步骤,实现起来也比较麻烦。
Asm 有两类 API:核心 API 和树形 API
# #核心 API
Asm Core API 可以类比解析 XML 文件中的 SAX 方式,不需要把这个类的整个结构读取进来,就可以用流式的方法来处理字节码文件。好处是非常节约内存,但是编程难度较大。然而出于性能考虑,一般情况下编程都使用 Core API。在 Core API 中有以下几个关键类:
- ClassReader:用于读取已经编译好的.class 文件。
- ClassWriter:用于重新构建编译后的类,如修改类名、属性以及方法,也可以生成新的类的字节码文件。
- 各种 Visitor 类:如上所述,CoreAPI 根据字节码从上到下依次处理,对于字节码文件中不同的区域有不同的 Visitor,比如用于访问方法的 MethodVisitor、用于访问类变量的 FieldVisitor、用于访问注解的 AnnotationVisitor 等。为了实现 AOP,重点要使用的是 MethodVisitor。
# #树形 API
Asm Tree API 可以类比解析 XML 文件中的 DOM 方式,把整个类的结构读取到内存中,缺点是消耗内存多,但是编程比较简单。TreeApi 不同于 CoreAPI,TreeAPI 通过各种 Node 类来映射字节码的各个区域,类比 DOM 节点,就可以很好地理解这种编程方式。
# #2.2. Javassist
利用 Javassist 实现字节码增强时,可以无须关注字节码刻板的结构,其优点就在于编程简单。直接使用 java 编码的形式,而不需要了解虚拟机指令,就能动态改变类的结构或者动态生成类。
其中最重要的是 ClassPool、CtClass、CtMethod、CtField 这四个类:
CtClass(compile-time class)- 编译时类信息,它是一个 class 文件在代码中的抽象表现形式,可以通过一个类的全限定名来获取一个 CtClass 对象,用来表示这个类文件。ClassPool- 从开发视角来看,ClassPool 是一张保存 CtClass 信息的 HashTable,key 为类名,value 为类名对应的 CtClass 对象。当我们需要对某个类进行修改时,就是通过 pool.getCtClass (“className”) 方法从 pool 中获取到相应的 CtClass。CtMethod、CtField- 这两个比较好理解,对应的是类中的方法和属性。
# JVM 类加载
📦 本文以及示例源码已归档在 javacore(opens new window)
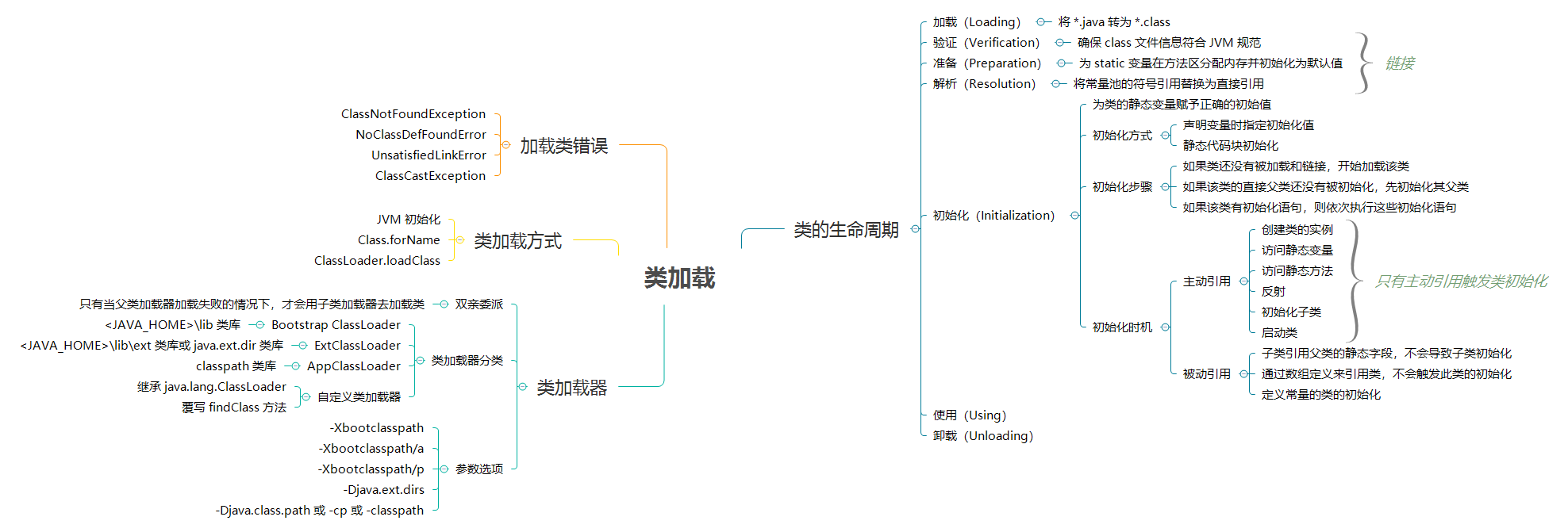
# #1. 类加载机制
类是在运行期间动态加载的。
类的加载指的是将类的 .class 文件中的二进制数据读入到内存中,将其放在运行时数据区的方法区内,然后在堆区创建一个 java.lang.Class 对象,用来封装类在方法区内的数据结构。类的加载的最终产品是位于堆区中的 Class 对象, Class 对象封装了类在方法区内的数据结构,并且向 Java 程序员提供了访问方法区内的数据结构的接口。
类加载器并不需要等到某个类被 “首次主动使用” 时再加载它,JVM 规范允许类加载器在预料某个类将要被使用时就预先加载它,如果在预先加载的过程中遇到了.class 文件缺失或存在错误,类加载器必须在程序首次主动使用该类时才报告错误(LinkageError 错误)如果这个类一直没有被程序主动使用,那么类加载器就不会报告错误
# #2. 类的生命周期
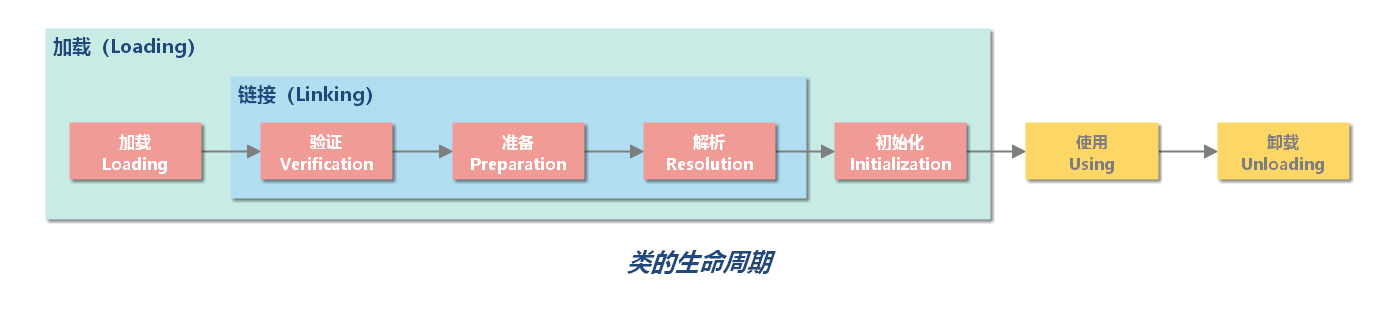
Java 类的完整生命周期包括以下几个阶段:
- 加载(Loading)
- 链接(Linking)
- 验证(Verification)
- 准备(Preparation)
- 解析(Resolution)
- 初始化(Initialization)
- 使用(Using)
- 卸载(Unloading)
加载、验证、准备、初始化和卸载这 5 个阶段的顺序是确定的,类的加载过程必须按照这种顺序按部就班地开始。而解析过程在某些情况下可以在初始化阶段之后再开始,这是为了支持 Java 的动态绑定。
类加载过程是指加载、验证、准备、解析和初始化这 5 个阶段。
# #2.1. (一)加载
加载是类加载的一个阶段,注意不要混淆。
加载,是指查找字节流,并且据此创建类的过程。
加载过程完成以下三件事:
- 通过一个类的全限定名来获取定义此类的二进制字节流。
- 将这个字节流所代表的静态存储结构转化为方法区的运行时存储结构。
- 在内存中生成一个代表这个类的
Class对象,作为方法区这个类的各种数据的访问入口。
其中二进制字节流可以从以下方式中获取:
- 从 ZIP 包读取,这很常见,最终成为日后 JAR、EAR、WAR 格式的基础。
- 从网络中获取,这种场景最典型的应用是 Applet。
- 运行时计算生成,这种场景使用得最多得就是动态代理技术,在
java.lang.reflect.Proxy中,就是用了ProxyGenerator.generateProxyClass的代理类的二进制字节流。 - 由其他文件生成,典型场景是 JSP 应用,即由 JSP 文件生成对应的 Class 类。
- 从数据库读取,这种场景相对少见,例如有些中间件服务器(如 SAP Netweaver)可以选择把程序安装到数据库中来完成程序代码在集群间的分发。 …
更详细内容会在 3. ClassLoader 介绍。
# #2.2. (二)验证
验证是链接阶段的第一步。验证的目标是确保 Class 文件的字节流中包含的信息符合当前虚拟机的要求,并且不会危害虚拟机自身的安全。
验证阶段大致会完成 4 个阶段的检验动作:
- 文件格式验证 - 验证字节流是否符合 Class 文件格式的规范,并且能被当前版本的虚拟机处理。
- 元数据验证 - 对字节码描述的信息进行语义分析,以保证其描述的信息符合 Java 语言规范的要求。
- 字节码验证 - 通过数据流和控制流分析,确保程序语义是合法、符合逻辑的。
- 符号引用验证 - 发生在虚拟机将符号引用转换为直接引用的时候,对类自身以外(常量池中的各种符号引用)的信息进行匹配性校验。
验证阶段是非常重要的,但不是必须的,它对程序运行期没有影响,如果所引用的类经过反复验证,那么可以考虑采用 -Xverifynone 参数来关闭大部分的类验证措施,以缩短虚拟机类加载的时间。
# #2.3. (三)准备
类变量是被 static 修饰的变量,准备阶段为 static 变量在方法区分配内存并初始化为默认值,使用的是方法区的内存。
实例变量不会在这阶段分配内存,它将会在对象实例化时随着对象一起分配在 Java 堆中。(实例化不是类加载的一个过程,类加载发生在所有实例化操作之前,并且类加载只进行一次,实例化可以进行多次)
初始值一般为 0 值,例如下面的类变量 value 被初始化为 0 而不是 123。
public static int value = 123;如果类变量是常量,那么会按照表达式来进行初始化,而不是赋值为 0。
public static final int value = 123;准备阶段有以下几点需要注意:
- 这时候进行内存分配的仅包括类变量(static),而不包括实例变量,实例变量会在对象实例化时随着对象一块分配在 Java 堆中。
- 这里所设置的初始值通常情况下是数据类型默认的零值(如
0、0L、null、false等),而不是被在 Java 代码中被显式地赋予的值。
假设一个类变量的定义为: public static int value = 3 ;
那么变量 value 在准备阶段过后的初始值为 0,而不是 3,因为这时候尚未开始执行任何 Java 方法,而把 value 赋值为 3 的 public static 指令是在程序编译后,存放于类构造器 () 方法之中的,所以把 value 赋值为 3 的动作将在初始化阶段才会执行。
这里还需要注意如下几点:
- 对基本数据类型来说,对于类变量(static)和全局变量,如果不显式地对其赋值而直接使用,则系统会为其赋予默认的零值,而对于局部变量来说,在使用前必须显式地为其赋值,否则编译时不通过。
- 对于同时被 static 和 final 修饰的常量,必须在声明的时候就为其显式地赋值,否则编译时不通过;而只被 final 修饰的常量则既可以在声明时显式地为其赋值,也可以在类初始化时显式地为其赋值,总之,在使用前必须为其显式地赋值,系统不会为其赋予默认零值。
- 对于引用数据类型 reference 来说,如数组引用、对象引用等,如果没有对其进行显式地赋值而直接使用,系统都会为其赋予默认的零值,即 null。
- 如果在数组初始化时没有对数组中的各元素赋值,那么其中的元素将根据对应的数据类型而被赋予默认的零值。
- 如果类字段的字段属性表中存在
ConstantValue属性,即同时被 final 和 static 修饰,那么在准备阶段变量 value 就会被初始化为 ConstValue 属性所指定的值。
假设上面的类变量 value 被定义为: public static final int value = 3 ;
编译时 Javac 将会为 value 生成 ConstantValue 属性,在准备阶段虚拟机就会根据 ConstantValue 的设置将 value 赋值为 3。我们可以理解为 static final 常量在编译期就将其结果放入了调用它的类的常量池中
# #2.4. (四)解析
在 class 文件被加载至 Java 虚拟机之前,这个类无法知道其他类及其方法、字段所对应的具体地址,甚至不知道自己方法、字段的地址。因此,每当需要引用这些成员时,Java 编译器会生成一个符号引用。在运行阶段,这个符号引用一般都能够无歧义地定位到具体目标上。
举例来说,对于一个方法调用,编译器会生成一个包含目标方法所在类的名字、目标方法的名字、接收参数类型以及返回值类型的符号引用,来指代所要调用的方法。
解析阶段目标是将常量池的符号引用替换为直接引用的过程。解析动作主要针对类或接口、字段、类方法、接口方法、方法类型、方法句柄和调用点限定符 7 类符号引用进行。
- 符号引用(Symbolic References) - 符号引用以一组符号来描述所引用的目标,符号可以是任何形式的字面量,只要使用时能无歧义地定位到目标即可。
- 直接引用(Direct Reference) - 直接引用可以是直接指向目标的指针、相对偏移量或是一个能间接定位到目标的句柄。
# #2.5. (五)初始化
在 Java 代码中,如果要初始化一个静态字段,可以在声明时直接赋值,也可以在静态代码块中对其赋值。
如果直接赋值的静态字段被 final 所修饰,并且它的类型是基本类型或字符串时,那么该字段便会被 Java 编译器标记成常量值(ConstantValue),其初始化直接由 Java 虚拟机完成。除此之外的直接赋值操作,以及所有静态代码块中的代码,则会被 Java 编译器置于同一方法中,并把它命名为 < clinit > 。
初始化阶段才真正开始执行类中的定义的 Java 程序代码。初始化,为类的静态变量赋予正确的初始值,JVM 负责对类进行初始化,主要对类变量进行初始化。
# #类初始化方式
- 声明类变量时指定初始值
- 使用静态代码块为类变量指定初始值
在准备阶段,类变量已经赋过一次系统要求的初始值,而在初始化阶段,根据程序员通过程序制定的主观计划去初始化类变量和其它资源。
# #类初始化步骤
- 如果类还没有被加载和链接,开始加载该类。
- 如果该类的直接父类还没有被初始化,先初始化其父类。
- 如果该类有初始化语句,则依次执行这些初始化语句。
# #类初始化时机
只有主动引用类的时候才会导致类的初始化。
(1)主动引用
类的主动引用包括以下六种:
- 创建类的实例 - 也就是
new对象 - 访问静态变量 - 访问某个类或接口的静态变量,或者对该静态变量赋值
- 访问静态方法
- 反射 - 如
Class.forName(“com.shengsiyuan.Test”) - 初始化子类 - 初始化某个类的子类,则其父类也会被初始化
- 启动类 - Java 虚拟机启动时被标明为启动类的类(
Java Test),直接使用java.exe命令来运行某个主类
(2)被动引用
以上 5 种场景中的行为称为对一个类进行主动引用。除此之外,所有引用类的方式都不会触发初始化,称为被动引用。被动引用的常见例子包括:
- 通过子类引用父类的静态字段,不会导致子类初始化。
System.out.println(SubClass.value); // value 字段在 SuperClass 中定义- 通过数组定义来引用类,不会触发此类的初始化。该过程会对数组类进行初始化,数组类是一个由虚拟机自动生成的、直接继承自
Object的子类,其中包含了数组的属性和方法。
SuperClass[] sca = new SuperClass[10];- 常量在编译阶段会存入调用类的常量池中,本质上并没有直接引用到定义常量的类,因此不会触发定义常量的类的初始化。
System.out.println(ConstClass.HELLOWORLD);# #类初始化细节
类初始化 <clinit>() 方法的细节:
- 是由编译器自动收集类中所有类变量的赋值动作和静态语句块(static {} 块)中的语句合并产生的,编译器收集的顺序由语句在源文件中出现的顺序决定。特别注意的是,静态语句块只能访问到定义在它之前的类变量,定义在它之后的类变量只能赋值,不能访问。例如以下代码:
public class Test {
static {
i = 0; // 给变量赋值可以正常编译通过
System.out.print(i); // 这句编译器会提示“非法向前引用”
}
static int i = 1;
}- 与类的构造函数(或者说实例构造器
<init>())不同,不需要显式的调用父类的构造器。虚拟机会自动保证在子类的<clinit>()方法运行之前,父类的<clinit>()方法已经执行结束。因此虚拟机中第一个执行<clinit>()方法的类肯定为java.lang.Object。 - 由于父类的
<clinit>()方法先执行,也就意味着父类中定义的静态语句块要优于子类的变量赋值操作。例如以下代码:
static class Parent {
public static int A = 1;
static {
A = 2;
}
}
static class Sub extends Parent {
public static int B = A;
}
public static void main(String[] args) {
System.out.println(Sub.B); // 输出结果是父类中的静态变量 A 的值,也就是 2。
}<clinit>()方法对于类或接口不是必须的,如果一个类中不包含静态语句块,也没有对类变量的赋值操作,编译器可以不为该类生成<clinit>()方法。- 接口中不可以使用静态语句块,但仍然有类变量初始化的赋值操作,因此接口与类一样都会生成
<clinit>()方法。但接口与类不同的是,执行接口的<clinit>()方法不需要先执行父接口的<clinit>()方法。只有当父接口中定义的变量使用时,父接口才会初始化。另外,接口的实现类在初始化时也一样不会执行接口的<clinit>()方法。 - 虚拟机会保证一个类的
<clinit>()方法在多线程环境下被正确的加锁和同步,如果多个线程同时初始化一个类,只会有一个线程执行这个类的<clinit>()方法,其它线程都会阻塞等待,直到活动线程执行<clinit>()方法完毕。如果在一个类的<clinit>()方法中有耗时的操作,就可能造成多个线程阻塞,在实际过程中此种阻塞很隐蔽。
# #3. ClassLoader
ClassLoader 即类加载器,负责将类加载到 JVM。在 Java 虚拟机外部实现,以便让应用程序自己决定如何去获取所需要的类。
JVM 加载 class 文件到内存有两种方式:
- 隐式加载 - JVM 自动加载需要的类到内存中。
- 显示加载 - 通过使用
ClassLoader来加载一个类到内存中。
# #3.1. 类与类加载器
如何判断两个类是否相等:类本身相等,并且使用同一个类加载器进行加载。这是因为每一个 ClassLoader 都拥有一个独立的类名称空间。
这里的相等,包括类的 Class 对象的 equals() 方法、 isAssignableFrom() 方法、 isInstance() 方法的返回结果为 true,也包括使用 instanceof 关键字做对象所属关系判定结果为 true。
# #3.2. 类加载器分类
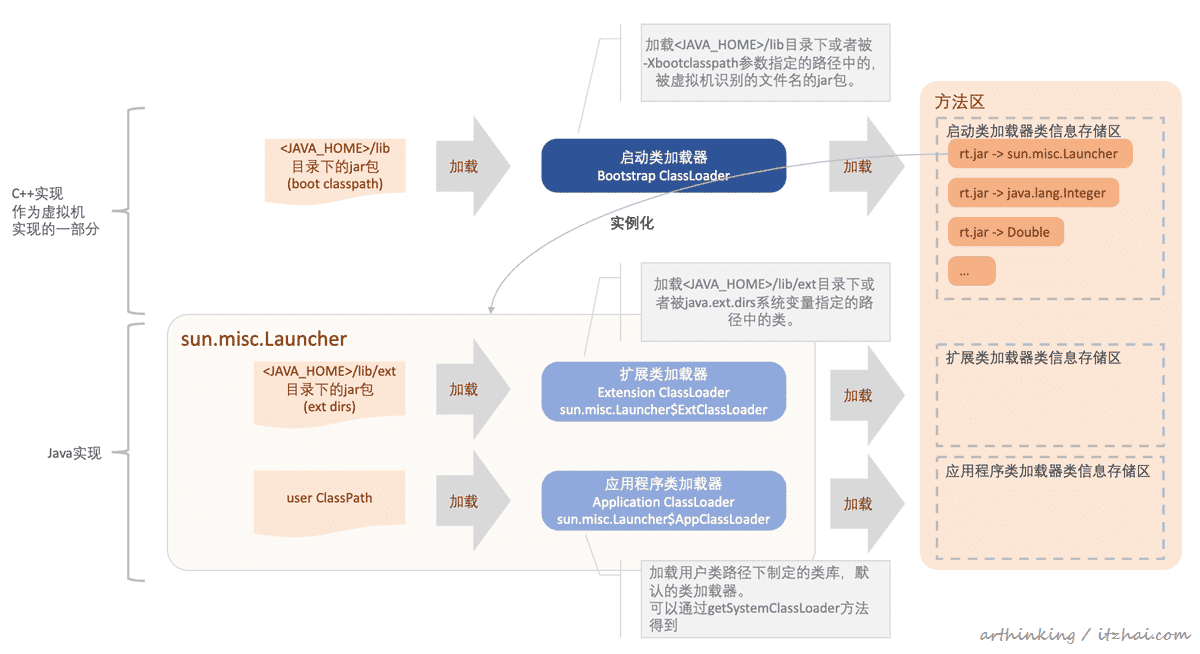
# #Bootstrap ClassLoader
Bootstrap ClassLoader ,即启动类加载器 ,负责加载 JVM 自身工作所需要的类。
Bootstrap ClassLoader 会将存放在 <JAVA_HOME>\lib 目录中的,或者被 -Xbootclasspath 参数所指定的路径中的,并且是虚拟机识别的(仅按照文件名识别,如 rt.jar,名字不符合的类库即使放在 lib 目录中也不会被加载)类库加载到虚拟机内存中。
Bootstrap ClassLoader 是由 C++ 实现的,它完全由 JVM 自己控制的,启动类加载器无法被 Java 程序直接引用,用户在编写自定义类加载器时,如果需要把加载请求委派给启动类加载器,直接使用 null 代替即可。
# #ExtClassLoader
ExtClassLoader ,即扩展类加载器,这个类加载器是由 ExtClassLoader(sun.misc.Launcher\$ExtClassLoader) 实现的。
ExtClassLoader 负责将 <JAVA_HOME>\lib\ext 或者被 java.ext.dir 系统变量所指定路径中的所有类库加载到内存中,开发者可以直接使用扩展类加载器。
# #AppClassLoader
AppClassLoader ,即应用程序类加载器,这个类加载器是由 AppClassLoader(sun.misc.Launcher\$AppClassLoader) 实现的。由于这个类加载器是 ClassLoader 中的 getSystemClassLoader() 方法的返回值,因此一般称为系统类加载器。
AppClassLoader 负责加载用户类路径(即 classpath )上所指定的类库,开发者可以直接使用这个类加载器,如果应用程序中没有自定义过自己的类加载器,一般情况下这个就是程序中默认的类加载器。
# #自定义类加载器
自定义类加载器可以做到如下几点:
- 在执行非置信代码之前,自动验证数字签名。
- 动态地创建符合用户特定需要的定制化构建类。
- 从特定的场所取得 java class,例如数据库中和网络中。
假设,我们需要自定义一个名为 FileSystemClassLoader 的类加载器,继承自 java.lang.ClassLoader ,用于加载文件系统上的类。它首先根据类的全名在文件系统上查找类的字节代码文件( .class 文件),然后读取该文件内容,最后通过 defineClass() 方法来把这些字节代码转换成 java.lang.Class 类的实例。
java.lang.ClassLoader 类的方法 loadClass() 实现了双亲委派模型的逻辑,因此自定义类加载器一般不去覆写它,而是通过覆写 findClass() 方法。
ClassLoader 常用的场景:
- 容器 - 典型应用:Servlet 容器(如:Tomcat、Jetty)、udf (Mysql、Hive)等。加载解压 jar 包或 war 包后,加载其 Class 到指定的类加载器中运行(通常需要考虑空间隔离)。
- 热部署、热插拔 - 应用启动后,动态获得某个类信息,然后加载到 JVM 中工作。很多著名的容器软件、框架(如:Spring 等),都使用
ClassLoader来实现自身的热部署。
【示例】自定义一个类加载器
public class FileSystemClassLoader extends ClassLoader {
private String rootDir;
public FileSystemClassLoader(String rootDir) {
this.rootDir = rootDir;
}
protected Class<?> findClass(String name) throws ClassNotFoundException {
byte[] classData = getClassData(name);
if (classData == null) {
throw new ClassNotFoundException();
} else {
return defineClass(name, classData, 0, classData.length);
}
}
private byte[] getClassData(String className) {
String path = classNameToPath(className);
try {
InputStream ins = new FileInputStream(path);
ByteArrayOutputStream baos = new ByteArrayOutputStream();
int bufferSize = 4096;
byte[] buffer = new byte[bufferSize];
int bytesNumRead;
while ((bytesNumRead = ins.read(buffer)) != -1) {
baos.write(buffer, 0, bytesNumRead);
}
return baos.toByteArray();
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
private String classNameToPath(String className) {
return rootDir + File.separatorChar
+ className.replace('.', File.separatorChar) + ".class";
}
}# #3.3. 双亲委派
理解双亲委派之前,先让我们看一个示例。
【示例】寻找类加载示例
public static void main(String[] args) {
ClassLoader loader = Thread.currentThread().getContextClassLoader();
System.out.println(loader);
System.out.println(loader.getParent());
System.out.println(loader.getParent().getParent());
}输出:
sun.misc.Launcher$AppClassLoader@18b4aac2
sun.misc.Launcher$ExtClassLoader@19e1023e
null从上面的结果可以看出,并没有获取到 ExtClassLoader 的父 Loader,原因是 Bootstrap Loader (引导类加载器)是用 C 语言实现的,找不到一个确定的返回父 Loader 的方式,于是就返回 null。
下图展示的类加载器之间的层次关系,称为类加载器的双亲委派模型(Parents Delegation Model)。该模型要求除了顶层的 Bootstrap ClassLoader 外,其余的类加载器都应有自己的父类加载器。这里类加载器之间的父子关系一般通过组合(Composition)关系来实现,而不是通过继承(Inheritance)的关系实现。
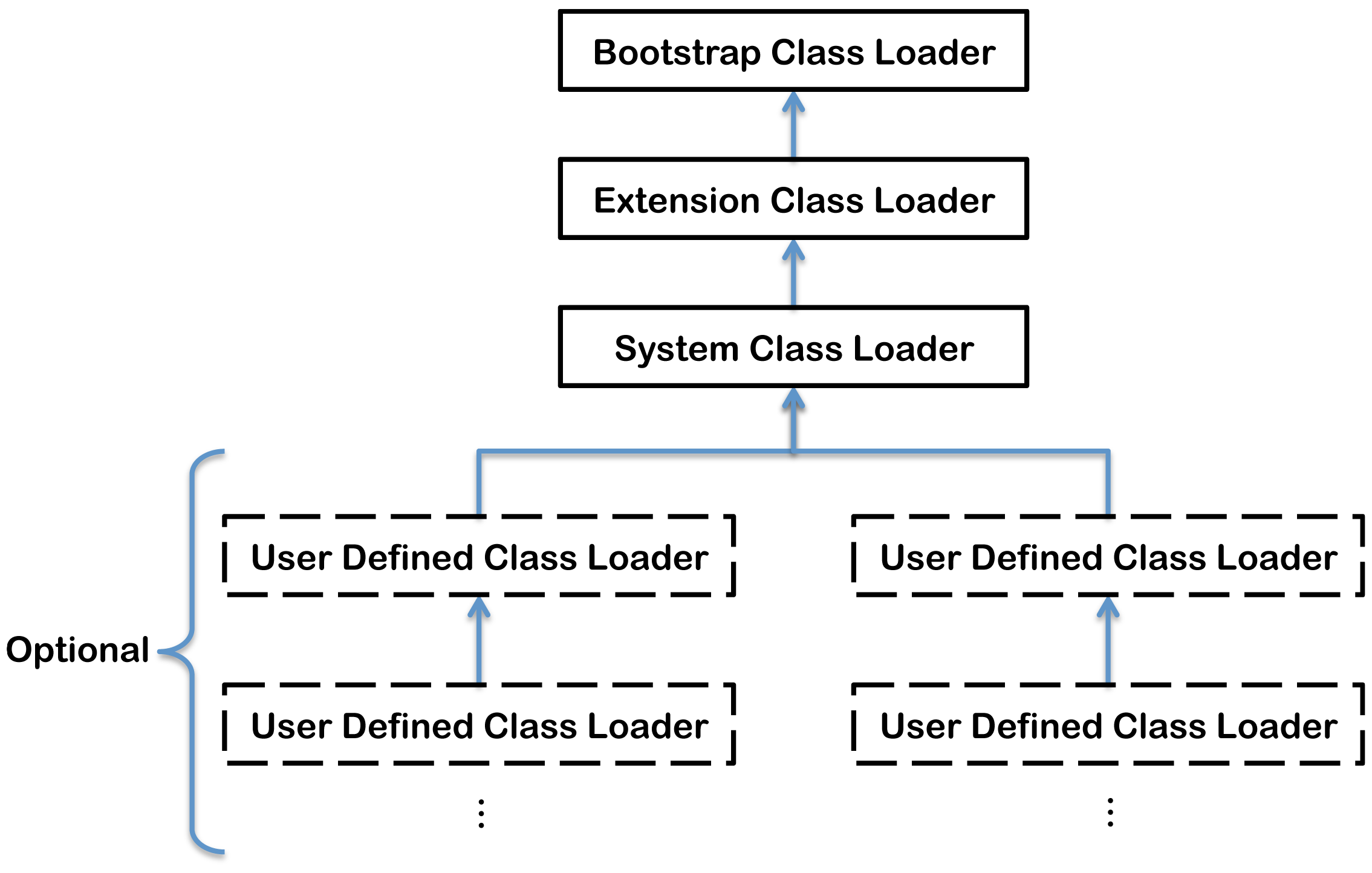
(1)工作过程
一个类加载器首先将类加载请求传送到父类加载器,只有当父类加载器无法完成类加载请求时才尝试加载。
(2)好处
使得 Java 类随着它的类加载器一起具有一种带有优先级的层次关系,从而使得基础类得到统一:
- 系统类防止内存中出现多份同样的字节码
- 保证 Java 程序安全稳定运行
例如: java.lang.Object 存放在 rt.jar 中,如果编写另外一个 java.lang.Object 的类并放到 classpath 中,程序可以编译通过。因为双亲委派模型的存在,所以在 rt.jar 中的 Object 比在 classpath 中的 Object 优先级更高,因为 rt.jar 中的 Object 使用的是启动类加载器,而 classpath 中的 Object 使用的是应用程序类加载器。正因为 rt.jar 中的 Object 优先级更高,因为程序中所有的 Object 都是这个 Object 。
(3)实现
以下是抽象类 java.lang.ClassLoader 的代码片段,其中的 loadClass() 方法运行过程如下:
public abstract class ClassLoader {
// The parent class loader for delegation
private final ClassLoader parent;
public Class<?> loadClass(String name) throws ClassNotFoundException {
return loadClass(name, false);
}
protected Class<?> loadClass(String name, boolean resolve) throws ClassNotFoundException {
synchronized (getClassLoadingLock(name)) {
// 首先判断该类型是否已经被加载
Class<?> c = findLoadedClass(name);
if (c == null) {
// 如果没有被加载,就委托给父类加载或者委派给启动类加载器加载
try {
if (parent != null) {
// 如果存在父类加载器,就委派给父类加载器加载
c = parent.loadClass(name, false);
} else {
// 如果不存在父类加载器,就检查是否是由启动类加载器加载的类,通过调用本地方法native Class findBootstrapClass(String name)
c = findBootstrapClassOrNull(name);
}
} catch (ClassNotFoundException e) {
// 如果父类加载器加载失败,会抛出 ClassNotFoundException
}
if (c == null) {
// 如果父类加载器和启动类加载器都不能完成加载任务,才调用自身的加载功能
c = findClass(name);
}
}
if (resolve) {
resolveClass(c);
}
return c;
}
}
protected Class<?> findClass(String name) throws ClassNotFoundException {
throw new ClassNotFoundException(name);
}
}【说明】
- 先检查类是否已经加载过,如果没有则让父类加载器去加载。
- 当父类加载器加载失败时抛出
ClassNotFoundException,此时尝试自己去加载。
# #3.4. ClassLoader 参数
在生产环境上启动 java 应用时,通常会指定一些 ClassLoader 参数,以加载应用所需要的 lib:
java -jar xxx.jar -classpath lib/*ClassLoader 相关参数选项:
| 参数选项 | ClassLoader 类型 | 说明 |
|---|---|---|
-Xbootclasspath |
Bootstrap ClassLoader |
设置 Bootstrap ClassLoader 搜索路径。【不常用】 |
-Xbootclasspath/a |
Bootstrap ClassLoader |
把路径添加到已存在的 Bootstrap ClassLoader 搜索路径后面。【常用】 |
-Xbootclasspath/p |
Bootstrap ClassLoader |
把路径添加到已存在的 Bootstrap ClassLoader 搜索路径前面。【不常用】 |
-Djava.ext.dirs |
ExtClassLoader |
设置 ExtClassLoader 搜索路径。 |
-Djava.class.path 或 -cp 或 -classpath |
AppClassLoader |
设置 AppClassLoader 搜索路径。 |
# #4. 类的加载
# #4.1. 类加载方式
类加载有三种方式:
- 命令行启动应用时候由 JVM 初始化加载
- 通过
Class.forName()方法动态加载 - 通过
ClassLoader.loadClass()方法动态加载
Class.forName() 和 ClassLoader.loadClass() 区别
Class.forName()将类的.class文件加载到 jvm 中之外,还会对类进行解释,执行类中的static块;ClassLoader.loadClass()只干一件事情,就是将.class文件加载到 jvm 中,不会执行static中的内容,只有在newInstance才会去执行static块。Class.forName(name, initialize, loader)带参函数也可控制是否加载static块。并且只有调用了newInstance()方法采用调用构造函数,创建类的对象 。
# #4.2. 加载类错误
# #ClassNotFoundException
ClassNotFoundException 异常出镜率极高。 ClassNotFoundException 表示当前 classpath 下找不到指定类。
常见问题原因:
- 调用
Class的forName()方法,未找到类。 - 调用
ClassLoader中的loadClass()方法,未找到类。 - 调用
ClassLoader中的findSystemClass()方法,未找到类。
【示例】执行以下代码,会抛出 ClassNotFoundException 异常:
public class ClassNotFoundExceptionDemo {
public static void main(String[] args) {
try {
Class.forName("NotFound");
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
}解决方法:检查 classpath 下有没有相应的 class 文件。
# #NoClassDefFoundError
常见问题原因:
- 类依赖的 Class 或者 jar 不存在。
- 类文件存在,但是存在不同的域中。
解决方法:现代 Java 项目,一般使用 maven 、 gradle 等构建工具管理项目,仔细检查找不到的类所在的 jar 包是否已添加为依赖。
# #UnsatisfiedLinkError
这个异常倒不是很常见,但是出错的话,通常是在 JVM 启动的时候如果一不小心将在 JVM 中的某个 lib 删除了,可能就会报这个错误了。
【示例】执行以下代码,会抛出 UnsatisfiedLinkError 错误。
public class UnsatisfiedLinkErrorDemo {
public native void nativeMethod();
static {
System.loadLibrary("NoLib");
}
public static void main(String[] args) {
new UnsatisfiedLinkErrorDemo().nativeMethod();
}
}【输出】
java.lang.UnsatisfiedLinkError: no NoLib in java.library.path
at java.lang.ClassLoader.loadLibrary(ClassLoader.java:1867)
at java.lang.Runtime.loadLibrary0(Runtime.java:870)
at java.lang.System.loadLibrary(System.java:1122)
at io.github.dunwu.javacore.jvm.classloader.exception.UnsatisfiedLinkErrorDemo.<clinit>(UnsatisfiedLinkErrorDemo.java:12)# #ClassCastException
ClassCastException 异常通常是在程序中强制类型转换失败时出现。
【示例】执行以下代码,会抛出 ClassCastException 异常。
public class ClassCastExceptionDemo {
public static void main(String[] args) {
Object obj = new Object();
EmptyClass newObj = (EmptyClass) obj;
}
static class EmptyClass {}
}【输出】
Exception in thread "main" java.lang.ClassCastException: java.lang.Object cannot be cast to io.github.dunwu.javacore.jvm.classloader.exception.ClassCastExceptionDemo$EmptyClass
at io.github.dunwu.javacore.jvm.classloader.exception.ClassCastExceptionDemo.main(ClassCastExceptionDemo.java:11)# JVM 实战
📦 本文以及示例源码已归档在 javacore(opens new window)
- \1. JVM 调优概述
- \2. GC 日志
- \3. GC 配置
- 4. 参考资料
# #1. JVM 调优概述
# #1.1. GC 性能指标
对于 JVM 调优来说,需要先明确调优的目标。 从性能的角度看,通常关注三个指标:
吞吐量(throughput)- 指不考虑 GC 引起的停顿时间或内存消耗,垃圾收集器能支撑应用达到的最高性能指标。停顿时间(latency)- 其度量标准是缩短由于垃圾啊收集引起的停顿时间或者完全消除因垃圾收集所引起的停顿,避免应用运行时发生抖动。垃圾回收频率- 久发生一次指垃圾回收呢?通常垃圾回收的频率越低越好,增大堆内存空间可以有效降低垃圾回收发生的频率,但同时也意味着堆积的回收对象越多,最终也会增加回收时的停顿时间。所以我们只要适当地增大堆内存空间,保证正常的垃圾回收频率即可。
大多数情况下调优会侧重于其中一个或者两个方面的目标,很少有情况可以兼顾三个不同的角度。
# #1.2. 调优原则
GC 优化的两个目标:
- 降低 Full GC 的频率
- 减少 Full GC 的执行时间
GC 优化的基本原则是:将不同的 GC 参数应用到两个及以上的服务器上然后比较它们的性能,然后将那些被证明可以提高性能或减少 GC 执行时间的参数应用于最终的工作服务器上。
# #降低 Minor GC 频率
如果新生代空间较小,Eden 区很快被填满,就会导致频繁 Minor GC,因此我们可以通过增大新生代空间来降低 Minor GC 的频率。
可能你会有这样的疑问,扩容 Eden 区虽然可以减少 Minor GC 的次数,但不会增加单次 Minor GC 的时间吗?如果单次 Minor GC 的时间增加,那也很难达到我们期待的优化效果呀。
我们知道,单次 Minor GC 时间是由两部分组成:T1(扫描新生代)和 T2(复制存活对象)。假设一个对象在 Eden 区的存活时间为 500ms,Minor GC 的时间间隔是 300ms,那么正常情况下,Minor GC 的时间为 :T1+T2。
当我们增大新生代空间,Minor GC 的时间间隔可能会扩大到 600ms,此时一个存活 500ms 的对象就会在 Eden 区中被回收掉,此时就不存在复制存活对象了,所以再发生 Minor GC 的时间为:两次扫描新生代,即 2T1。
可见,扩容后,Minor GC 时增加了 T1,但省去了 T2 的时间。通常在虚拟机中,复制对象的成本要远高于扫描成本。
如果在堆内存中存在较多的长期存活的对象,此时增加年轻代空间,反而会增加 Minor GC 的时间。如果堆中的短期对象很多,那么扩容新生代,单次 Minor GC 时间不会显著增加。因此,单次 Minor GC 时间更多取决于 GC 后存活对象的数量,而非 Eden 区的大小。
# #降低 Full GC 的频率
Full GC 相对来说会比 Minor GC 更耗时。减少进入老年代的对象数量可以显著降低 Full GC 的频率。
** 减少创建大对象:* 如果 * 对象占用内存过大,在 Eden 区被创建后会直接被传入老年代。在平常的业务场景中,我们习惯一次性从数据库中查询出一个大对象用于 web 端显示。例如,我之前碰到过一个一次性查询出 60 个字段的业务操作,这种大对象如果超过年轻代最大对象阈值,会被直接创建在老年代;即使被创建在了年轻代,由于年轻代的内存空间有限,通过 Minor GC 之后也会进入到老年代。这种大对象很容易产生较多的 Full GC。
我们可以将这种大对象拆解出来,首次只查询一些比较重要的字段,如果还需要其它字段辅助查看,再通过第二次查询显示剩余的字段。
** 增大堆内存空间:** 在堆内存不足的情况下,增大堆内存空间,且设置初始化堆内存为最大堆内存,也可以降低 Full GC 的频率。
# #降低 Full GC 的时间
Full GC 的执行时间比 Minor GC 要长很多,因此,如果在 Full GC 上花费过多的时间(超过 1s),将可能出现超时错误。
- 如果通过减小老年代内存来减少 Full GC 时间,可能会引起
OutOfMemoryError或者导致 Full GC 的频率升高。 - 另外,如果通过增加老年代内存来降低 Full GC 的频率,Full GC 的时间可能因此增加。
因此,你需要把老年代的大小设置成一个 “合适” 的值。
GC 优化需要考虑的 JVM 参数
| 类型 | 参数 | 描述 |
|---|---|---|
| 堆内存大小 | -Xms |
启动 JVM 时堆内存的大小 |
-Xmx |
堆内存最大限制 | |
| 新生代空间大小 | -XX:NewRatio |
新生代和老年代的内存比 |
-XX:NewSize |
新生代内存大小 | |
-XX:SurvivorRatio |
Eden 区和 Survivor 区的内存比 |
GC 优化时最常用的参数是 -Xms , -Xmx 和 -XX:NewRatio 。 -Xms 和 -Xmx 参数通常是必须的,所以 NewRatio 的值将对 GC 性能产生重要的影响。
有些人可能会问如何设置永久代内存大小,你可以用 -XX:PermSize 和 -XX:MaxPermSize 参数来进行设置,但是要记住,只有当出现 OutOfMemoryError 错误时你才需要去设置永久代内存。
# #1.3. GC 优化的过程
GC 优化的过程大致可分为以下步骤:
# #(1)监控 GC 状态
你需要监控 GC 从而检查系统中运行的 GC 的各种状态。
# #(2)分析 GC 日志
在检查 GC 状态后,你需要分析监控结构并决定是否需要进行 GC 优化。如果分析结果显示运行 GC 的时间只有 0.1-0.3 秒,那么就不需要把时间浪费在 GC 优化上,但如果运行 GC 的时间达到 1-3 秒,甚至大于 10 秒,那么 GC 优化将是很有必要的。
但是,如果你已经分配了大约 10GB 内存给 Java,并且这些内存无法省下,那么就无法进行 GC 优化了。在进行 GC 优化之前,你需要考虑为什么你需要分配这么大的内存空间,如果你分配了 1GB 或 2GB 大小的内存并且出现了 OutOfMemoryError ,那你就应该执行 ** 堆快照(heap dump)** 来消除导致异常的原因。
🔔 注意:
** 堆快照(heap dump)** 是一个用来检查 Java 内存中的对象和数据的内存文件。该文件可以通过执行 JDK 中的
jmap命令来创建。在创建文件的过程中,所有 Java 程序都将暂停,因此,不要在系统执行过程中创建该文件。
你可以在互联网上搜索 heap dump 的详细说明。
# #(3)选择合适 GC 回收器
如果你决定要进行 GC 优化,那么你需要选择一个 GC 回收器,并且为它设置合理 JVM 参数。此时如果你有多个服务器,请如上文提到的那样,在每台机器上设置不同的 GC 参数并分析它们的区别。
# #(4)分析结果
在设置完 GC 参数后就可以开始收集数据,请在收集至少 24 小时后再进行结果分析。如果你足够幸运,你可能会找到系统的最佳 GC 参数。如若不然,你还需要分析输出日志并检查分配的内存,然后需要通过不断调整 GC 类型 / 内存大小来找到系统的最佳参数。
# #(5)应用优化配置
如果 GC 优化的结果令人满意,就可以将参数应用到所有服务器上,并停止 GC 优化。
在下面的章节中,你将会看到上述每一步所做的具体工作。
# #2. GC 日志
# #2.1. 获取 GC 日志
获取 GC 日志有两种方式:
- 使用
jstat命令动态查看 - 在容器中设置相关参数打印 GC 日志
# #jstat 命令查看 GC
jstat -gc 统计垃圾回收堆的行为:
jstat -gc 1262
S0C S1C S0U S1U EC EU OC OU PC PU YGC YGCT FGC FGCT GCT
26112.0 24064.0 6562.5 0.0 564224.0 76274.5 434176.0 388518.3 524288.0 42724.7 320 6.417 1 0.398 6.815也可以设置间隔固定时间来打印:
jstat -gc 1262 2000 20这个命令意思就是每隔 2000ms 输出 1262 的 gc 情况,一共输出 20 次
# #打印 GC 的参数
通过 JVM 参数预先设置 GC 日志,通常有以下几种 JVM 参数设置:
-XX:+PrintGC 输出 GC 日志
-XX:+PrintGCDetails 输出 GC 的详细日志
-XX:+PrintGCTimeStamps 输出 GC 的时间戳(以基准时间的形式)
-XX:+PrintGCDateStamps 输出 GC 的时间戳(以日期的形式,如 2013-05-04T21:53:59.234+0800)
-XX:+PrintHeapAtGC 在进行 GC 的前后打印出堆的信息
-verbose:gc -Xloggc:../logs/gc.log 日志文件的输出路径如果是长时间的 GC 日志,我们很难通过文本形式去查看整体的 GC 性能。此时,我们可以通过 GCView (opens new window) 工具打开日志文件,图形化界面查看整体的 GC 性能。
【示例】Tomcat 设置示例
JAVA_OPTS="-server -Xms2000m -Xmx2000m -Xmn800m -XX:PermSize=64m -XX:MaxPermSize=256m -XX:SurvivorRatio=4
-verbose:gc -Xloggc:$CATALINA_HOME/logs/gc.log
-Djava.awt.headless=true
-XX:+PrintGCTimeStamps -XX:+PrintGCDetails
-Dsun.rmi.dgc.server.gcInterval=600000 -Dsun.rmi.dgc.client.gcInterval=600000
-XX:+UseConcMarkSweepGC -XX:MaxTenuringThreshold=15"-Xms2000m -Xmx2000m -Xmn800m -XX:PermSize=64m -XX:MaxPermSize=256mXms,即为 jvm 启动时得 JVM 初始堆大小,Xmx 为 jvm 的最大堆大小,xmn 为新生代的大小,permsize 为永久代的初始大小,MaxPermSize 为永久代的最大空间。-XX:SurvivorRatio=4SurvivorRatio 为新生代空间中的 Eden 区和救助空间 Survivor 区的大小比值,默认是 8,则两个 Survivor 区与一个 Eden 区的比值为 2:8, 一个 Survivor 区占整个年轻代的 1/10。调小这个参数将增大 survivor 区,让对象尽量在 survitor 区呆长一点,减少进入年老代的对象。去掉救助空间的想法是让大部分不能马上回收的数据尽快进入年老代,加快年老代的回收频率,减少年老代暴涨的可能性,这个是通过将 - XX:SurvivorRatio 设置成比较大的值(比如 65536) 来做到。-verbose:gc -Xloggc:$CATALINA_HOME/logs/gc.log将虚拟机每次垃圾回收的信息写到日志文件中,文件名由 file 指定,文件格式是平文件,内容和 - verbose:gc 输出内容相同。-Djava.awt.headless=trueHeadless 模式是系统的一种配置模式。在该模式下,系统缺少了显示设备、键盘或鼠标。-XX:+PrintGCTimeStamps -XX:+PrintGCDetails设置 gc 日志的格式-Dsun.rmi.dgc.server.gcInterval=600000 -Dsun.rmi.dgc.client.gcInterval=600000指定 rmi 调用时 gc 的时间间隔-XX:+UseConcMarkSweepGC -XX:MaxTenuringThreshold=15采用并发 gc 方式,经过 15 次 minor gc 后进入年老代
# #2.2. 分析 GC 日志
Young GC 回收日志:
2016-07-05T10:43:18.093+0800: 25.395: [GC [PSYoungGen: 274931K->10738K(274944K)] 371093K->147186K(450048K), 0.0668480 secs] [Times: user=0.17 sys=0.08, real=0.07 secs]Full GC 回收日志:
2016-07-05T10:43:18.160+0800: 25.462: [Full GC [PSYoungGen: 10738K->0K(274944K)] [ParOldGen: 136447K->140379K(302592K)] 147186K->140379K(577536K) [PSPermGen: 85411K->85376K(171008K)], 0.6763541 secs] [Times: user=1.75 sys=0.02, real=0.68 secs]通过上面日志分析得出,PSYoungGen、ParOldGen、PSPermGen 属于 Parallel 收集器。其中 PSYoungGen 表示 gc 回收前后年轻代的内存变化;ParOldGen 表示 gc 回收前后老年代的内存变化;PSPermGen 表示 gc 回收前后永久区的内存变化。young gc 主要是针对年轻代进行内存回收比较频繁,耗时短;full gc 会对整个堆内存进行回城,耗时长,因此一般尽量减少 full gc 的次数
通过两张图非常明显看出 gc 日志构成:
YOUNG GC
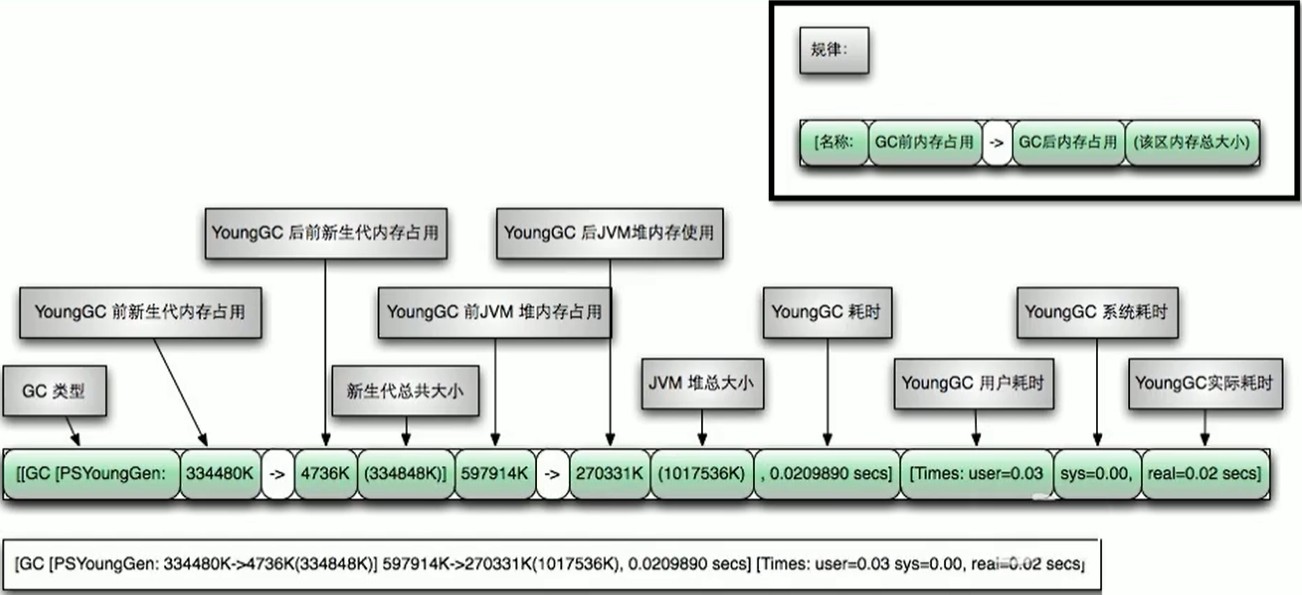
FULL GC
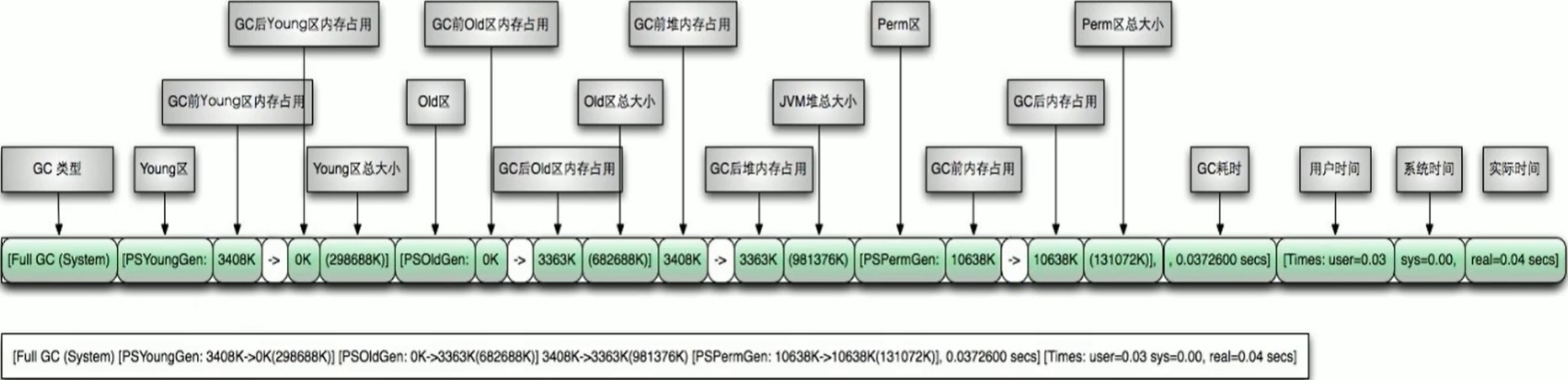
# #CPU 过高
定位步骤:
(1)执行 top -c 命令,找到 cpu 最高的进程的 id
(2)jstack PID 导出 Java 应用程序的线程堆栈信息。
示例:
jstack 6795
"Low Memory Detector" daemon prio=10 tid=0x081465f8 nid=0x7 runnable [0x00000000..0x00000000]
"CompilerThread0" daemon prio=10 tid=0x08143c58 nid=0x6 waiting on condition [0x00000000..0xfb5fd798]
"Signal Dispatcher" daemon prio=10 tid=0x08142f08 nid=0x5 waiting on condition [0x00000000..0x00000000]
"Finalizer" daemon prio=10 tid=0x08137ca0 nid=0x4 in Object.wait() [0xfbeed000..0xfbeeddb8]
at java.lang.Object.wait(Native Method)
- waiting on <0xef600848> (a java.lang.ref.ReferenceQueue$Lock)
at java.lang.ref.ReferenceQueue.remove(ReferenceQueue.java:116)
- locked <0xef600848> (a java.lang.ref.ReferenceQueue$Lock)
at java.lang.ref.ReferenceQueue.remove(ReferenceQueue.java:132)
at java.lang.ref.Finalizer$FinalizerThread.run(Finalizer.java:159)
"Reference Handler" daemon prio=10 tid=0x081370f0 nid=0x3 in Object.wait() [0xfbf4a000..0xfbf4aa38]
at java.lang.Object.wait(Native Method)
- waiting on <0xef600758> (a java.lang.ref.Reference$Lock)
at java.lang.Object.wait(Object.java:474)
at java.lang.ref.Reference$ReferenceHandler.run(Reference.java:116)
- locked <0xef600758> (a java.lang.ref.Reference$Lock)
"VM Thread" prio=10 tid=0x08134878 nid=0x2 runnable
"VM Periodic Task Thread" prio=10 tid=0x08147768 nid=0x8 waiting on condition在打印的堆栈日志文件中,tid 和 nid 的含义:
nid : 对应的 Linux 操作系统下的 tid 线程号,也就是前面转化的 16 进制数字
tid: 这个应该是 jvm 的 jmm 内存规范中的唯一地址定位在 CPU 过高的情况下,查找响应的线程,一般定位都是用 nid 来定位的。而如果发生死锁之类的问题,一般用 tid 来定位。
(3)定位 CPU 高的线程打印其 nid
查看线程下具体进程信息的命令如下:
top -H -p 6735
top - 14:20:09 up 611 days, 2:56, 1 user, load average: 13.19, 7.76, 7.82
Threads: 6991 total, 17 running, 6974 sleeping, 0 stopped, 0 zombie
%Cpu(s): 90.4 us, 2.1 sy, 0.0 ni, 7.0 id, 0.0 wa, 0.0 hi, 0.4 si, 0.0 st
KiB Mem: 32783044 total, 32505008 used, 278036 free, 120304 buffers
KiB Swap: 0 total, 0 used, 0 free. 4497428 cached Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
6800 root 20 0 27.299g 0.021t 7172 S 54.7 70.1 187:55.61 java
6803 root 20 0 27.299g 0.021t 7172 S 54.4 70.1 187:52.59 java
6798 root 20 0 27.299g 0.021t 7172 S 53.7 70.1 187:55.08 java
6801 root 20 0 27.299g 0.021t 7172 S 53.7 70.1 187:55.25 java
6797 root 20 0 27.299g 0.021t 7172 S 53.1 70.1 187:52.78 java
6804 root 20 0 27.299g 0.021t 7172 S 53.1 70.1 187:55.76 java
6802 root 20 0 27.299g 0.021t 7172 S 52.1 70.1 187:54.79 java
6799 root 20 0 27.299g 0.021t 7172 S 51.8 70.1 187:53.36 java
6807 root 20 0 27.299g 0.021t 7172 S 13.6 70.1 48:58.60 java
11014 root 20 0 27.299g 0.021t 7172 R 8.4 70.1 8:00.32 java
10642 root 20 0 27.299g 0.021t 7172 R 6.5 70.1 6:32.06 java
6808 root 20 0 27.299g 0.021t 7172 S 6.1 70.1 159:08.40 java
11315 root 20 0 27.299g 0.021t 7172 S 3.9 70.1 5:54.10 java
12545 root 20 0 27.299g 0.021t 7172 S 3.9 70.1 6:55.48 java
23353 root 20 0 27.299g 0.021t 7172 S 3.9 70.1 2:20.55 java
24868 root 20 0 27.299g 0.021t 7172 S 3.9 70.1 2:12.46 java
9146 root 20 0 27.299g 0.021t 7172 S 3.6 70.1 7:42.72 java由此可以看出占用 CPU 较高的线程,但是这些还不高,无法直接定位到具体的类。nid 是 16 进制的,所以我们要获取线程的 16 进制 ID:
printf "%x\n" 6800
输出结果:45cd然后根据输出结果到 jstack 打印的堆栈日志中查定位:
"catalina-exec-5692" daemon prio=10 tid=0x00007f3b05013800 nid=0x45cd waiting on condition [0x00007f3ae08e3000]
java.lang.Thread.State: TIMED_WAITING (parking)
at sun.misc.Unsafe.park(Native Method)
- parking to wait for <0x00000006a7800598> (a java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject)
at java.util.concurrent.locks.LockSupport.parkNanos(LockSupport.java:226)
at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.awaitNanos(AbstractQueuedSynchronizer.java:2082)
at java.util.concurrent.LinkedBlockingQueue.poll(LinkedBlockingQueue.java:467)
at org.apache.tomcat.util.threads.TaskQueue.poll(TaskQueue.java:86)
at org.apache.tomcat.util.threads.TaskQueue.poll(TaskQueue.java:32)
at java.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1068)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1130)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at org.apache.tomcat.util.threads.TaskThread$WrappingRunnable.run(TaskThread.java:61)
at java.lang.Thread.run(Thread.java:745)# #3. GC 配置
详细参数说明请参考官方文档:JavaHotSpot VM Options (opens new window),这里仅列举常用参数。
# #3.1. 堆大小设置
年轻代的设置很关键。
JVM 中最大堆大小有三方面限制:
- 相关操作系统的数据模型(32-bt 还是 64-bit)限制;
- 系统的可用虚拟内存限制;
- 系统的可用物理内存限制。
整个堆大小 = 年轻代大小 + 年老代大小 + 持久代大小- 持久代一般固定大小为
64m。使用-XX:PermSize设置。 - 官方推荐年轻代占整个堆的 3/8。使用
-Xmn设置。
# #3.2. JVM 内存配置
| 配置 | 描述 |
|---|---|
-Xss |
虚拟机栈大小。 |
-Xms |
堆空间初始值。 |
-Xmx |
堆空间最大值。 |
-Xmn |
新生代空间大小。 |
-XX:NewSize |
新生代空间初始值。 |
-XX:MaxNewSize |
新生代空间最大值。 |
-XX:NewRatio |
新生代与年老代的比例。默认为 2,意味着老年代是新生代的 2 倍。 |
-XX:SurvivorRatio |
新生代中调整 eden 区与 survivor 区的比例,默认为 8。即 eden 区为 80% 的大小,两个 survivor 分别为 10% 的大小。 |
-XX:PermSize |
永久代空间的初始值。 |
-XX:MaxPermSize |
永久代空间的最大值。 |
# #3.3. GC 类型配置
| 配置 | 描述 |
|---|---|
-XX:+UseSerialGC |
使用 Serial + Serial Old 垃圾回收器组合 |
-XX:+UseParallelGC |
使用 Parallel Scavenge + Parallel Old 垃圾回收器组合 |
-XX:+UseParallelOldGC |
使用 Parallel Old 垃圾回收器(JDK5 后已无用) |
-XX:+UseParNewGC |
使用 ParNew + Serial Old 垃圾回收器 |
-XX:+UseConcMarkSweepGC |
使用 CMS + ParNew + Serial Old 垃圾回收器组合 |
-XX:+UseG1GC |
使用 G1 垃圾回收器 |
-XX:ParallelCMSThreads |
并发标记扫描垃圾回收器 = 为使用的线程数量 |
# #3.4. 垃圾回收器通用参数
| 配置 | 描述 |
|---|---|
PretenureSizeThreshold |
晋升年老代的对象大小。默认为 0。比如设为 10M,则超过 10M 的对象将不在 eden 区分配,而直接进入年老代。 |
MaxTenuringThreshold |
晋升老年代的最大年龄。默认为 15。比如设为 10,则对象在 10 次普通 GC 后将会被放入年老代。 |
DisableExplicitGC |
禁用 System.gc() |
# #3.5. JMX
开启 JMX 后,可以使用 jconsole 或 jvisualvm 进行监控 Java 程序的基本信息和运行情况。
-Dcom.sun.management.jmxremote=true
-Dcom.sun.management.jmxremote.ssl=false
-Dcom.sun.management.jmxremote.authenticate=false
-Djava.rmi.server.hostname=127.0.0.1
-Dcom.sun.management.jmxremote.port=18888-Djava.rmi.server.hostname 指定 Java 程序运行的服务器, -Dcom.sun.management.jmxremote.port 指定服务监听端口。
# #3.6. 远程 DEBUG
如果开启 Java 应用的远程 Debug 功能,需要指定如下参数:
-Xdebug
-Xnoagent
-Djava.compiler=NONE
-Xrunjdwp:transport=dt_socket,address=28888,server=y,suspend=naddress 即为远程 debug 的监听端口。
# #3.7. HeapDump
-XX:-OmitStackTraceInFastThrow -XX:+HeapDumpOnOutOfMemoryError# #3.8. 辅助配置
| 配置 | 描述 |
|---|---|
-XX:+PrintGCDetails |
打印 GC 日志 |
-Xloggc:<filename> |
指定 GC 日志文件名 |
-XX:+HeapDumpOnOutOfMemoryError |
内存溢出时输出堆快照文件 |
# JVM 命令行工具
Java 程序员免不了故障排查工作,所以经常需要使用一些 JVM 工具。
JDK 自带了一些实用的命令行工具来监控、分析 JVM 信息,掌握它们,非常有助于 TroubleShooting。
以下是较常用的 JDK 命令行工具:
| 名称 | 描述 |
|---|---|
jps |
JVM 进程状态工具。显示系统内的所有 JVM 进程。 |
jstat |
JVM 统计监控工具。监控虚拟机运行时状态信息,它可以显示出 JVM 进程中的类装载、内存、GC、JIT 编译等运行数据。 |
jmap |
JVM 堆内存分析工具。用于打印 JVM 进程对象直方图、类加载统计。并且可以生成堆转储快照(一般称为 heapdump 或 dump 文件)。 |
jstack |
JVM 栈查看工具。用于打印 JVM 进程的线程和锁的情况。并且可以生成线程快照(一般称为 threaddump 或 javacore 文件)。 |
jhat |
用来分析 jmap 生成的 dump 文件。 |
jinfo |
JVM 信息查看工具。用于实时查看和调整 JVM 进程参数。 |
jcmd |
JVM 命令行调试 工具。用于向 JVM 进程发送调试命令。 |
# #1. jps
jps(JVM Process Status Tool) (opens new window) 是虚拟机进程状态工具。它可以显示指定系统内所有的 HotSpot 虚拟机进程状态信息。jps 通过 RMI 协议查询开启了 RMI 服务的远程虚拟机进程状态。
# #1.1. jps 命令用法
jps [option] [hostid]
jps [-help]如果不指定 hostid 就默认为当前主机或服务器。
常用参数:
-
option \- 选项参数 - `-m` - 输出 JVM 启动时传递给 main() 的参数。 - `-l` - 输出主类的全名,如果进程执行的是 jar 包,输出 jar 路径。 - `-v` - 显示传递给 JVM 的参数。 - `-q` - 仅输出本地 JVM 进程 ID。 - `-V` - 仅输出本地 JVM 标识符。 - `hostid` - RMI 注册表中注册的主机名。如果不指定 hostid 就默认为当前主机或服务器。 其中 `option`、`hostid` 参数也可以不写。 ### [#](https://dunwu.github.io/javacore/jvm/jvm-cli-tools.html#_1-2-jps-使用示例)1.2. jps 使用示例 【示例】列出本地 Java 进程 ```shell $ jps 18027 Java2Demo.JAR 18032 jps 18005 jstat
【示例】列出本地 Java 进程 ID
$ jps -q
8841
1292
5398【示例】列出本地 Java 进程 ID,并输出主类的全名,如果进程执行的是 jar 包,输出 jar 路径
$ jps -l remote.domain
3002 /opt/jdk1.7.0/demo/jfc/Java2D/Java2Demo.JAR
2857 sun.tools.jstatd.jstatd# #2. jstat
jstat(JVM statistics Monitoring) (opens new window),是虚拟机统计信息监视工具。jstat 用于监视虚拟机运行时状态信息,它可以显示出虚拟机进程中的类装载、内存、垃圾收集、JIT 编译等运行数据。
# #2.1. jstat 命令用法
命令格式:
jstat [option] VMID [interval] [count]常用参数:
-
option \- 选项参数,用于指定用户需要查询的虚拟机信息 - `-class` - 监视类装载、卸载数量、总空间以及类装载所耗费的时间 - `-compiler`:显示 JIT 编译的相关信息; - `-gc`:监视 Java 堆状况,包括 Eden 区、两个 survivor 区、老年代、永久代等区的容量、已用空间、GC 时间合计等信息。 - `-gccapacity`:显示各个代的容量以及使用情况; - `-gcmetacapacity`:显示 Metaspace 的大小; - `-gcnew`:显示新生代信息; - `-gcnewcapacity`:显示新生代大小和使用情况; - `-gcold`:显示老年代和永久代的信息; - `-gcoldcapacity`:显示老年代的大小; - `-gcutil`:显示垃圾回收统计信息; - `-gccause`:显示垃圾回收的相关信息(通 -gcutil),同时显示最后一次或当前正在发生的垃圾回收的诱因; - `-printcompilation`:输出 JIT 编译的方法信息。 - `VMID` - 如果是本地虚拟机进程,则 VMID 与 LVMID 是一致的;如果是远程虚拟机进程,那 VMID 的格式应当是:`[protocol:][//]lvmid[@hostname[:port]/servername]` - `interval` - 查询间隔 - `count` - 查询次数 > 【参考】更详细说明可以参考:[jstat 命令查看 jvm 的 GC 情况(opens new window)](https://www.cnblogs.com/yjd_hycf_space/p/7755633.html) ### [#](https://dunwu.github.io/javacore/jvm/jvm-cli-tools.html#_2-2-jstat-使用示例)2.2. jstat 使用示例 #### [#](https://dunwu.github.io/javacore/jvm/jvm-cli-tools.html#类加载统计)类加载统计 使用 `jstat -class pid` 命令可以查看编译统计信息。 【参数】 - Loaded - 加载 class 的数量 - Bytes - 所占用空间大小 - Unloaded - 未加载数量 - Bytes - 未加载占用空间 - Time - 时间 【示例】查看类加载信息 ```shell $ jstat -class 7129 Loaded Bytes Unloaded Bytes Time 26749 50405.3 873 1216.8 19.75
# #编译统计
使用 jstat -compiler pid 命令可以查看编译统计信息。
【示例】
$ jstat -compiler 7129
Compiled Failed Invalid Time FailedType FailedMethod
42030 2 0 302.53 1 org/apache/felix/framework/BundleWiringImpl$BundleClassLoader findClass【参数】
- Compiled - 编译数量
- Failed - 失败数量
- Invalid - 不可用数量
- Time - 时间
- FailedType - 失败类型
- FailedMethod - 失败的方法
# #GC 统计
使用 jstat -gc pid time 命令可以查看 GC 统计信息。
【示例】以 250 毫秒的间隔进行 7 个采样,并显示 - gcutil 选项指定的输出。
$ jstat -gcutil 21891 250 7
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
0.00 97.02 70.31 66.80 95.52 89.14 7 0.300 0 0.000 0.300
0.00 97.02 86.23 66.80 95.52 89.14 7 0.300 0 0.000 0.300
0.00 97.02 96.53 66.80 95.52 89.14 7 0.300 0 0.000 0.300
91.03 0.00 1.98 68.19 95.89 91.24 8 0.378 0 0.000 0.378
91.03 0.00 15.82 68.19 95.89 91.24 8 0.378 0 0.000 0.378
91.03 0.00 17.80 68.19 95.89 91.24 8 0.378 0 0.000 0.378
91.03 0.00 17.80 68.19 95.89 91.24 8 0.378 0 0.000 0.378【示例】以 1 秒的间隔进行 4 个采样,并显示 - gc 选项指定的输出。
$ jstat -gc 25196 1s 4
S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
20928.0 20928.0 0.0 0.0 167936.0 8880.5 838912.0 80291.2 106668.0 100032.1 12772.0 11602.2 760 14.332 580 656.218 670.550
20928.0 20928.0 0.0 0.0 167936.0 8880.5 838912.0 80291.2 106668.0 100032.1 12772.0 11602.2 760 14.332 580 656.218 670.550
20928.0 20928.0 0.0 0.0 167936.0 8880.5 838912.0 80291.2 106668.0 100032.1 12772.0 11602.2 760 14.332 580 656.218 670.550
20928.0 20928.0 0.0 0.0 167936.0 8880.5 838912.0 80291.2 106668.0 100032.1 12772.0 11602.2 760 14.332 580 656.218 670.550参数说明:
S0C:年轻代中 To Survivor 的容量(单位 KB);S1C:年轻代中 From Survivor 的容量(单位 KB);S0U:年轻代中 To Survivor 目前已使用空间(单位 KB);S1U:年轻代中 From Survivor 目前已使用空间(单位 KB);EC:年轻代中 Eden 的容量(单位 KB);EU:年轻代中 Eden 目前已使用空间(单位 KB);OC:Old 代的容量(单位 KB);OU:Old 代目前已使用空间(单位 KB);MC:Metaspace 的容量(单位 KB);MU:Metaspace 目前已使用空间(单位 KB);YGC:从应用程序启动到采样时年轻代中 gc 次数;YGCT:从应用程序启动到采样时年轻代中 gc 所用时间 (s);FGC:从应用程序启动到采样时 old 代(全 gc)gc 次数;FGCT:从应用程序启动到采样时 old 代(全 gc)gc 所用时间 (s);GCT:从应用程序启动到采样时 gc 用的总时间 (s)。
注:更详细的参数含义可以参考官方文档:http://docs.oracle.com/javase/8/docs/technotes/tools/unix/jstat.html
# #3. jmap
jmap(JVM Memory Map) (opens new window) 是 Java 内存映像工具。jmap 用于生成堆转储快照(一般称为 heapdump 或 dump 文件)。jmap 不仅能生成 dump 文件,还可以查询
finalize执行队列、Java 堆和永久代的详细信息,如当前使用率、当前使用的是哪种收集器等。如果不使用这个命令,还可以使用
-XX:+HeapDumpOnOutOfMemoryError参数来让虚拟机出现 OOM 的时候,自动生成 dump 文件。
# #3.1. jmap 命令用法
命令格式:
jmap [option] pidoption 选项参数:
-dump- 生成堆转储快照。-dump:live只保存堆中的存活对象。-finalizerinfo- 显示在 F-Queue 队列等待执行finalizer方法的对象-heap- 显示 Java 堆详细信息。-histo- 显示堆中对象的统计信息,包括类、实例数量、合计容量。-histo:live只统计堆中的存活对象。-permstat- to print permanent generation statistics-F- 当 - dump 没有响应时,强制生成 dump 快照
# #3.2. jstat 使用示例
# #生成 heapdump 快照
dump 堆到文件,format 指定输出格式,live 指明是活着的对象,file 指定文件名
$ jmap -dump:live,format=b,file=dump.hprof 28920
Dumping heap to /home/xxx/dump.hprof ...
Heap dump file createddump.hprof 这个后缀是为了后续可以直接用 MAT (Memory Anlysis Tool) 等工具打开。
# #查看实例数最多的类
$ jmap -histo 29527 | head -n 6
num #instances #bytes class name
----------------------------------------------
1: 13673280 1438961864 [C
2: 1207166 411277184 [I
3: 7382322 347307096 [Ljava.lang.Object;# #查看指定进程的堆信息
注意:使用 CMS GC 情况下, jmap -heap PID 的执行有可能会导致 java 进程挂起。
$ jmap -heap 12379
Attaching to process ID 12379, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 17.0-b16
using thread-local object allocation.
Parallel GC with 6 thread(s)
Heap Configuration:
MinHeapFreeRatio = 40
MaxHeapFreeRatio = 70
MaxHeapSize = 83886080 (80.0MB)
NewSize = 1310720 (1.25MB)
MaxNewSize = 17592186044415 MB
OldSize = 5439488 (5.1875MB)
NewRatio = 2
SurvivorRatio = 8
PermSize = 20971520 (20.0MB)
MaxPermSize = 88080384 (84.0MB)
Heap Usage:
PS Young Generation
Eden Space:
capacity = 9306112 (8.875MB)
used = 5375360 (5.1263427734375MB)
free = 3930752 (3.7486572265625MB)
57.761608714788736% used
From Space:
capacity = 9306112 (8.875MB)
used = 3425240 (3.2665634155273438MB)
free = 5880872 (5.608436584472656MB)
36.80634834397007% used
To Space:
capacity = 9306112 (8.875MB)
used = 0 (0.0MB)
free = 9306112 (8.875MB)
0.0% used
PS Old Generation
capacity = 55967744 (53.375MB)
used = 48354640 (46.11457824707031MB)
free = 7613104 (7.2604217529296875MB)
86.39733629427693% used
PS Perm Generation
capacity = 62062592 (59.1875MB)
used = 60243112 (57.452308654785156MB)
free = 1819480 (1.7351913452148438MB)
97.06831451706046% used# #4. jstack
jstack(Stack Trace for java) (opens new window) 是 Java 堆栈跟踪工具。jstack 用来打印目标 Java 进程中各个线程的栈轨迹,以及这些线程所持有的锁,并可以生成 java 虚拟机当前时刻的线程快照(一般称为 threaddump 或 javacore 文件)。
线程快照是当前虚拟机内每一条线程正在执行的方法堆栈的集合,生成线程快照的主要目的是定位线程出现长时间停顿的原因,如线程间死锁、死循环、请求外部资源导致的长时间等待等。
jstack 通常会结合 top -Hp pid 或 pidstat -p pid -t 一起查看具体线程的状态,也经常用来排查一些死锁的异常。
线程出现停顿的时候通过 jstack 来查看各个线程的调用堆栈,就可以知道没有响应的线程到底在后台做什么事情,或者等待什么资源。 如果 java 程序崩溃生成 core 文件,jstack 工具可以用来获得 core 文件的 java stack 和 native stack 的信息,从而可以轻松地知道 java 程序是如何崩溃和在程序何处发生问题。另外,jstack 工具还可以附属到正在运行的 java 程序中,看到当时运行的 java 程序的 java stack 和 native stack 的信息,如果现在运行的 java 程序呈现 hung 的状态,jstack 是非常有用的。
# #4.1. jstack 命令用法
命令格式:
jstack [option] pidoption 选项参数
-F- 当正常输出请求不被响应时,强制输出线程堆栈-l- 除堆栈外,显示关于锁的附加信息-m- 打印 java 和 jni 框架的所有栈信息
# #4.2. thread dump 文件

一个 Thread Dump 文件大致可以分为五个部分。
# #第一部分:Full thread dump identifier
这一部分是内容最开始的部分,展示了快照文件的生成时间和 JVM 的版本信息。
2017-10-19 10:46:44
Full thread dump Java HotSpot(TM) 64-Bit Server VM (24.79-b02 mixed mode):# #第二部分:Java EE middleware, third party & custom application Threads
这是整个文件的核心部分,里面展示了 JavaEE 容器(如 tomcat、resin 等)、自己的程序中所使用的线程信息。
"resin-22129" daemon prio=10 tid=0x00007fbe5c34e000 nid=0x4cb1 waiting on condition [0x00007fbe4ff7c000]
java.lang.Thread.State: WAITING (parking)
at sun.misc.Unsafe.park(Native Method)
at java.util.concurrent.locks.LockSupport.park(LockSupport.java:315)
at com.caucho.env.thread2.ResinThread2.park(ResinThread2.java:196)
at com.caucho.env.thread2.ResinThread2.runTasks(ResinThread2.java:147)
at com.caucho.env.thread2.ResinThread2.run(ResinThread2.java:118)参数说明:
"resin-22129"** 线程名称:** 如果使用 java.lang.Thread 类生成一个线程的时候,线程名称为 Thread-(数字) 的形式,这里是 resin 生成的线程;daemon** 线程类型:** 线程分为守护线程 (daemon) 和非守护线程 (non-daemon) 两种,通常都是守护线程;prio=10** 线程优先级:** 默认为 5,数字越大优先级越高;tid=0x00007fbe5c34e000**JVM 线程的 id:**JVM 内部线程的唯一标识,通过 java.lang.Thread.getId () 获取,通常用自增的方式实现;nid=0x4cb1** 系统线程 id:** 对应的系统线程 id(Native Thread ID),可以通过 top 命令进行查看,现场 id 是十六进制的形式;waiting on condition** 系统线程状态:** 这里是系统的线程状态;[0x00007fbe4ff7c000]** 起始栈地址:** 线程堆栈调用的其实内存地址;java.lang.Thread.State: WAITING (parking)**JVM 线程状态:** 这里标明了线程在代码级别的状态。- ** 线程调用栈信息:** 下面就是当前线程调用的详细栈信息,用于代码的分析。堆栈信息应该从下向上解读,因为程序调用的顺序是从下向上的。
# #第三部分:HotSpot VM Thread
这一部分展示了 JVM 内部线程的信息,用于执行内部的原生操作。下面常见的集中内置线程:
# #“Attach Listener”
该线程负责接收外部命令,执行该命令并把结果返回给调用者,此种类型的线程通常在桌面程序中出现。
"Attach Listener" daemon prio=5 tid=0x00007fc6b6800800 nid=0x3b07 waiting on condition [0x0000000000000000]
java.lang.Thread.State: RUNNABLE# #“DestroyJavaVM”
执行 main() 的线程在执行完之后调用 JNI 中的 jni_DestroyJavaVM() 方法会唤起 DestroyJavaVM 线程,处于等待状态,等待其它线程(java 线程和 native 线程)退出时通知它卸载 JVM。
"DestroyJavaVM" prio=5 tid=0x00007fc6b3001000 nid=0x1903 waiting on condition [0x0000000000000000]
java.lang.Thread.State: RUNNABLE# #“Service Thread”
用于启动服务的线程
"Service Thread" daemon prio=10 tid=0x00007fbea81b3000 nid=0x5f2 runnable [0x0000000000000000]
java.lang.Thread.State: RUNNABLE# #“CompilerThread”
用来调用 JITing,实时编译装卸类。通常 JVM 会启动多个线程来处理这部分工作,线程名称后面的数字也会累加,比如 CompilerThread1。
"C2 CompilerThread1" daemon prio=10 tid=0x00007fbea814b000 nid=0x5f1 waiting on condition [0x0000000000000000]
java.lang.Thread.State: RUNNABLE
"C2 CompilerThread0" daemon prio=10 tid=0x00007fbea8142000 nid=0x5f0 waiting on condition [0x0000000000000000]
java.lang.Thread.State: RUNNABLE# #“Signal Dispatcher”
Attach Listener 线程的职责是接收外部 jvm 命令,当命令接收成功后,会交给 signal dispather 线程去进行分发到各个不同的模块处理命令,并且返回处理结果。 signal dispather 线程也是在第一次接收外部 jvm 命令时,进行初始化工作。
"Signal Dispatcher" daemon prio=10 tid=0x00007fbea81bf800 nid=0x5ef runnable [0x0000000000000000]
java.lang.Thread.State: RUNNABLE# #“Finalizer”
这个线程也是在 main 线程之后创建的,其优先级为 10,主要用于在垃圾收集前,调用对象的 finalize() 方法;关于 Finalizer 线程的几点:
- 只有当开始一轮垃圾收集时,才会开始调用 finalize () 方法;因此并不是所有对象的 finalize () 方法都会被执行;
- 该线程也是 daemon 线程,因此如果虚拟机中没有其他非 daemon 线程,不管该线程有没有执行完 finalize () 方法,JVM 也会退出;
- JVM 在垃圾收集时会将失去引用的对象包装成 Finalizer 对象(Reference 的实现),并放入 ReferenceQueue,由 Finalizer 线程来处理;最后将该 Finalizer 对象的引用置为 null,由垃圾收集器来回收;
JVM 为什么要单独用一个线程来执行 finalize() 方法呢?
如果 JVM 的垃圾收集线程自己来做,很有可能由于在 finalize () 方法中误操作导致 GC 线程停止或不可控,这对 GC 线程来说是一种灾难。
"Finalizer" daemon prio=10 tid=0x00007fbea80da000 nid=0x5eb in Object.wait() [0x00007fbeac044000]
java.lang.Thread.State: WAITING (on object monitor)
at java.lang.Object.wait(Native Method)
at java.lang.ref.ReferenceQueue.remove(ReferenceQueue.java:135)
- locked <0x00000006d173c1a8> (a java.lang.ref.ReferenceQueue$Lock)
at java.lang.ref.ReferenceQueue.remove(ReferenceQueue.java:151)
at java.lang.ref.Finalizer$FinalizerThread.run(Finalizer.java:209)# #“Reference Handler”
JVM 在创建 main 线程后就创建 Reference Handler 线程,其优先级最高,为 10,它主要用于处理引用对象本身(软引用、弱引用、虚引用)的垃圾回收问题 。
"Reference Handler" daemon prio=10 tid=0x00007fbea80d8000 nid=0x5ea in Object.wait() [0x00007fbeac085000]
java.lang.Thread.State: WAITING (on object monitor)
at java.lang.Object.wait(Native Method)
at java.lang.Object.wait(Object.java:503)
at java.lang.ref.Reference$ReferenceHandler.run(Reference.java:133)
- locked <0x00000006d173c1f0> (a java.lang.ref.Reference$Lock)# #“VM Thread”
JVM 中线程的母体,根据 HotSpot 源码中关于 vmThread.hpp 里面的注释,它是一个单例的对象(最原始的线程)会产生或触发所有其他的线程,这个单例的 VM 线程是会被其他线程所使用来做一些 VM 操作(如清扫垃圾等)。 在 VM Thread 的结构体里有一个 VMOperationQueue 列队,所有的 VM 线程操作 (vm_operation) 都会被保存到这个列队当中,VMThread 本身就是一个线程,它的线程负责执行一个自轮询的 loop 函数 (具体可以参考:VMThread.cpp 里面的 void VMThread::loop ()) ,该 loop 函数从 VMOperationQueue 列队中按照优先级取出当前需要执行的操作对象 (VM_Operation),并且调用 VM_Operation->evaluate 函数去执行该操作类型本身的业务逻辑。 VM 操作类型被定义在 vm_operations.hpp 文件内,列举几个:ThreadStop、ThreadDump、PrintThreads、GenCollectFull、GenCollectFullConcurrent、CMS_Initial_Mark、CMS_Final_Remark…… 有兴趣的同学,可以自己去查看源文件。
"VM Thread" prio=10 tid=0x00007fbea80d3800 nid=0x5e9 runnable# #第四部分:HotSpot GC Thread
JVM 中用于进行资源回收的线程,包括以下几种类型的线程:
# #“VM Periodic Task Thread”
该线程是 JVM 周期性任务调度的线程,它由 WatcherThread 创建,是一个单例对象。该线程在 JVM 内使用得比较频繁,比如:定期的内存监控、JVM 运行状况监控。
"VM Periodic Task Thread" prio=10 tid=0x00007fbea82ae800 nid=0x5fa waiting on condition可以使用 jstat 命令查看 GC 的情况,比如查看某个进程没有存活必要的引用可以使用命令 jstat -gcutil 250 7 参数中 pid 是进程 id,后面的 250 和 7 表示每 250 毫秒打印一次,总共打印 7 次。 这对于防止因为应用代码中直接使用 native 库或者第三方的一些监控工具的内存泄漏有非常大的帮助。
# #“GC task thread#0 (ParallelGC)”
垃圾回收线程,该线程会负责进行垃圾回收。通常 JVM 会启动多个线程来处理这个工作,线程名称中 #后面的数字也会累加。
"GC task thread#0 (ParallelGC)" prio=5 tid=0x00007fc6b480d000 nid=0x2503 runnable
"GC task thread#1 (ParallelGC)" prio=5 tid=0x00007fc6b2812000 nid=0x2703 runnable
"GC task thread#2 (ParallelGC)" prio=5 tid=0x00007fc6b2812800 nid=0x2903 runnable
"GC task thread#3 (ParallelGC)" prio=5 tid=0x00007fc6b2813000 nid=0x2b03 runnable如果在 JVM 中增加了 -XX:+UseConcMarkSweepGC 参数将会启用 CMS (Concurrent Mark-Sweep)GC Thread 方式,以下是该模式下的线程类型:
# #“Gang worker#0 (Parallel GC Threads)”
原来垃圾回收线程 GC task thread#0 (ParallelGC) 被替换为 Gang worker#0 (Parallel GC Threads)。Gang worker 是 JVM 用于年轻代垃圾回收 (minor gc) 的线程。
"Gang worker#0 (Parallel GC Threads)" prio=10 tid=0x00007fbea801b800 nid=0x5e4 runnable
"Gang worker#1 (Parallel GC Threads)" prio=10 tid=0x00007fbea801d800 nid=0x5e7 runnable# #“Concurrent Mark-Sweep GC Thread”
并发标记清除垃圾回收器(就是通常所说的 CMS GC)线程, 该线程主要针对于年老代垃圾回收。
"Concurrent Mark-Sweep GC Thread" prio=10 tid=0x00007fbea8073800 nid=0x5e8 runnable# #“Surrogate Locker Thread (Concurrent GC)”
此线程主要配合 CMS 垃圾回收器来使用,是一个守护线程,主要负责处理 GC 过程中 Java 层的 Reference(指软引用、弱引用等等)与 jvm 内部层面的对象状态同步。
"Surrogate Locker Thread (Concurrent GC)" daemon prio=10 tid=0x00007fbea8158800 nid=0x5ee waiting on condition [0x0000000000000000]
java.lang.Thread.State: RUNNABLE这里以 WeakHashMap 为例进行说明,首先是一个关键点:
- WeakHashMap 和 HashMap 一样,内部有一个 Entry [] 数组;
- WeakHashMap 的 Entry 比较特殊,它的继承体系结构为 Entry->WeakReference->Reference;
- Reference 里面有一个全局锁对象:Lock,它也被称为 pending_lock,注意:它是静态对象;
- Reference 里面有一个静态变量:pending;
- Reference 里面有一个静态内部类:ReferenceHandler 的线程,它在 static 块里面被初始化并且启动,启动完成后处于 wait 状态,它在一个 Lock 同步锁模块中等待;
- WeakHashMap 里面还实例化了一个 ReferenceQueue 列队
假设,WeakHashMap 对象里面已经保存了很多对象的引用,JVM 在进行 CMS GC 的时候会创建一个 ConcurrentMarkSweepThread(简称 CMST)线程去进行 GC。ConcurrentMarkSweepThread 线程被创建的同时会创建一个 SurrogateLockerThread(简称 SLT)线程并且启动它,SLT 启动之后,处于等待阶段。 CMST 开始 GC 时,会发一个消息给 SLT 让它去获取 Java 层 Reference 对象的全局锁:Lock。直到 CMS GC 完毕之后,JVM 会将 WeakHashMap 中所有被回收的对象所属的 WeakReference 容器对象放入到 Reference 的 pending 属性当中(每次 GC 完毕之后,pending 属性基本上都不会为 null 了),然后通知 SLT 释放并且 notify 全局锁:Lock。此时激活了 ReferenceHandler 线程的 run 方法,使其脱离 wait 状态,开始工作了。 ReferenceHandler 这个线程会将 pending 中的所有 WeakReference 对象都移动到它们各自的列队当中,比如当前这个 WeakReference 属于某个 WeakHashMap 对象,那么它就会被放入相应的 ReferenceQueue 列队里面(该列队是链表结构)。 当我们下次从 WeakHashMap 对象里面 get、put 数据或者调用 size 方法的时候,WeakHashMap 就会将 ReferenceQueue 列队中的 WeakReference 依依 poll 出来去和 Entry [] 数据做比较,如果发现相同的,则说明这个 Entry 所保存的对象已经被 GC 掉了,那么将 Entry [] 内的 Entry 对象剔除掉。
# #第五部分:JNI global references count
这一部分主要回收那些在 native 代码上被引用,但在 java 代码中却没有存活必要的引用,对于防止因为应用代码中直接使用 native 库或第三方的一些监控工具的内存泄漏有非常大的帮助。
JNI global references: 830下一篇文章将要讲述一个直接找出 CPU 100% 线程的例子。
# #4.3. 系统线程状态
系统线程有如下状态:
# #deadlock
死锁线程,一般指多个线程调用期间进入了相互资源占用,导致一直等待无法释放的情况。
【示例】deadlock 示例
"DEADLOCK_TEST-1" daemon prio=6 tid=0x000000000690f800 nid=0x1820 waiting for monitor entry [0x000000000805f000]
java.lang.Thread.State: BLOCKED (on object monitor)
at com.nbp.theplatform.threaddump.ThreadDeadLockState$DeadlockThread.goMonitorDeadlock(ThreadDeadLockState.java:197)
- waiting to lock <0x00000007d58f5e60> (a com.nbp.theplatform.threaddump.ThreadDeadLockState$Monitor)
at com.nbp.theplatform.threaddump.ThreadDeadLockState$DeadlockThread.monitorOurLock(ThreadDeadLockState.java:182)
- locked <0x00000007d58f5e48> (a com.nbp.theplatform.threaddump.ThreadDeadLockState$Monitor)
at com.nbp.theplatform.threaddump.ThreadDeadLockState$DeadlockThread.run(ThreadDeadLockState.java:135)
Locked ownable synchronizers:
- None
"DEADLOCK_TEST-2" daemon prio=6 tid=0x0000000006858800 nid=0x17b8 waiting for monitor entry [0x000000000815f000]
java.lang.Thread.State: BLOCKED (on object monitor)
at com.nbp.theplatform.threaddump.ThreadDeadLockState$DeadlockThread.goMonitorDeadlock(ThreadDeadLockState.java:197)
- waiting to lock <0x00000007d58f5e78> (a com.nbp.theplatform.threaddump.ThreadDeadLockState$Monitor)
at com.nbp.theplatform.threaddump.ThreadDeadLockState$DeadlockThread.monitorOurLock(ThreadDeadLockState.java:182)
- locked <0x00000007d58f5e60> (a com.nbp.theplatform.threaddump.ThreadDeadLockState$Monitor)
at com.nbp.theplatform.threaddump.ThreadDeadLockState$DeadlockThread.run(ThreadDeadLockState.java:135)
Locked ownable synchronizers:
- None
"DEADLOCK_TEST-3" daemon prio=6 tid=0x0000000006859000 nid=0x25dc waiting for monitor entry [0x000000000825f000]
java.lang.Thread.State: BLOCKED (on object monitor)
at com.nbp.theplatform.threaddump.ThreadDeadLockState$DeadlockThread.goMonitorDeadlock(ThreadDeadLockState.java:197)
- waiting to lock <0x00000007d58f5e48> (a com.nbp.theplatform.threaddump.ThreadDeadLockState$Monitor)
at com.nbp.theplatform.threaddump.ThreadDeadLockState$DeadlockThread.monitorOurLock(ThreadDeadLockState.java:182)
- locked <0x00000007d58f5e78> (a com.nbp.theplatform.threaddump.ThreadDeadLockState$Monitor)
at com.nbp.theplatform.threaddump.ThreadDeadLockState$DeadlockThread.run(ThreadDeadLockState.java:135)
Locked ownable synchronizers:
- None# #runnable
一般指该线程正在执行状态中,该线程占用了资源,正在处理某个操作,如通过 SQL 语句查询数据库、对某个文件进行写入等。
# #blocked
线程正处于阻塞状态,指当前线程执行过程中,所需要的资源长时间等待却一直未能获取到,被容器的线程管理器标识为阻塞状态,可以理解为等待资源超时的线程。
【示例】blocked 示例
"BLOCKED_TEST pool-1-thread-2" prio=6 tid=0x0000000007673800 nid=0x260c waiting for monitor entry [0x0000000008abf000]
java.lang.Thread.State: BLOCKED (on object monitor)
at com.nbp.theplatform.threaddump.ThreadBlockedState.monitorLock(ThreadBlockedState.java:43)
- waiting to lock <0x0000000780a000b0> (a com.nbp.theplatform.threaddump.ThreadBlockedState)
at com.nbp.theplatform.threaddump.ThreadBlockedState$2.run(ThreadBlockedState.java:26)
at java.util.concurrent.ThreadPoolExecutor$Worker.runTask(ThreadPoolExecutor.java:886)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:908)
at java.lang.Thread.run(Thread.java:662)
Locked ownable synchronizers:
- <0x0000000780b0c6a0> (a java.util.concurrent.locks.ReentrantLock$NonfairSync)
"BLOCKED_TEST pool-1-thread-3" prio=6 tid=0x00000000074f5800 nid=0x1994 waiting for monitor entry [0x0000000008bbf000]
java.lang.Thread.State: BLOCKED (on object monitor)
at com.nbp.theplatform.threaddump.ThreadBlockedState.monitorLock(ThreadBlockedState.java:42)
- waiting to lock <0x0000000780a000b0> (a com.nbp.theplatform.threaddump.ThreadBlockedState)
at com.nbp.theplatform.threaddump.ThreadBlockedState$3.run(ThreadBlockedState.java:34)
at java.util.concurrent.ThreadPoolExecutor$Worker.runTask(ThreadPoolExecutor.java:886
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:908)
at java.lang.Thread.run(Thread.java:662)
Locked ownable synchronizers:
- <0x0000000780b0e1b8> (a java.util.concurrent.locks.ReentrantLock$NonfairSync)# #waiting on condition
线程正处于等待资源或等待某个条件的发生,具体的原因需要结合下面堆栈信息进行分析。
(1)如果堆栈信息明确是应用代码,则证明该线程正在等待资源,一般是大量读取某种资源且该资源采用了资源锁的情况下,线程进入等待状态,等待资源的读取,或者正在等待其他线程的执行等。
(2)如果发现有大量的线程都正处于这种状态,并且堆栈信息中得知正等待网络读写,这是因为网络阻塞导致线程无法执行,很有可能是一个网络瓶颈的征兆:
- 网络非常繁忙,几乎消耗了所有的带宽,仍然有大量数据等待网络读写;
- 网络可能是空闲的,但由于路由或防火墙等原因,导致包无法正常到达;
所以一定要结合系统的一些性能观察工具进行综合分析,比如 netstat 统计单位时间的发送包的数量,看是否很明显超过了所在网络带宽的限制;观察 CPU 的利用率,看系统态的 CPU 时间是否明显大于用户态的 CPU 时间。这些都指向由于网络带宽所限导致的网络瓶颈。
(3)还有一种常见的情况是该线程在 sleep,等待 sleep 的时间到了,将被唤醒。
【示例】等待状态样例
"IoWaitThread" prio=6 tid=0x0000000007334800 nid=0x2b3c waiting on condition [0x000000000893f000]
java.lang.Thread.State: WAITING (parking)
at sun.misc.Unsafe.park(Native Method)
- parking to wait for <0x00000007d5c45850> (a java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject)
at java.util.concurrent.locks.LockSupport.park(LockSupport.java:156)
at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:1987)
at java.util.concurrent.LinkedBlockingDeque.takeFirst(LinkedBlockingDeque.java:440)
at java.util.concurrent.LinkedBlockingDeque.take(LinkedBlockingDeque.java:629)
at com.nbp.theplatform.threaddump.ThreadIoWaitState$IoWaitHandler2.run(ThreadIoWaitState.java:89)
at java.lang.Thread.run(Thread.java:662)# #waiting for monitor entry 或 in Object.wait ()
Moniter 是 Java 中用以实现线程之间的互斥与协作的主要手段,它可以看成是对象或者 class 的锁,每个对象都有,也仅有一个 Monitor。
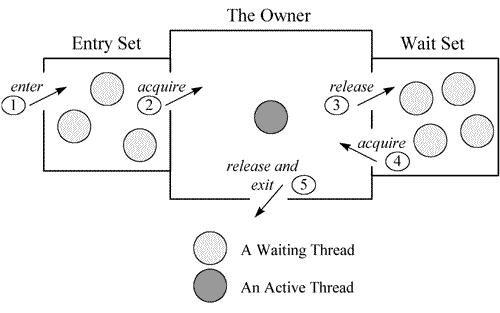
从上图可以看出,每个 Monitor 在某个时刻只能被一个线程拥有,该线程就是 “Active Thread”,而其他线程都是 “Waiting Thread”,分别在两个队列 "Entry Set" 和 "Waint Set" 里面等待。其中在 “Entry Set” 中等待的线程状态是 waiting for monitor entry ,在 “Wait Set” 中等待的线程状态是 in Object.wait() 。
(1)"Entry Set" 里面的线程。
我们称被 synchronized 保护起来的代码段为临界区,对应的代码如下:
synchronized(obj) {
}当一个线程申请进入临界区时,它就进入了 “Entry Set” 队列中,这时候有两种可能性:
- 该 Monitor 不被其他线程拥有,"Entry Set" 里面也没有其他等待的线程。本线程即成为相应类或者对象的 Monitor 的 Owner,执行临界区里面的代码;此时在 Thread Dump 中显示线程处于 “Runnable” 状态。
- 该 Monitor 被其他线程拥有,本线程在 “Entry Set” 队列中等待。此时在 Thread Dump 中显示线程处于 “waiting for monity entry” 状态。
临界区的设置是为了保证其内部的代码执行的原子性和完整性,但因为临界区在任何时间只允许线程串行通过,这和我们使用多线程的初衷是相反的。如果在多线程程序中大量使用 synchronized,或者不适当的使用它,会造成大量线程在临界区的入口等待,造成系统的性能大幅下降。如果在 Thread Dump 中发现这个情况,应该审视源码并对其进行改进。
(2)"Wait Set" 里面的线程
当线程获得了 Monitor,进入了临界区之后,如果发现线程继续运行的条件没有满足,它则调用对象(通常是被 synchronized 的对象)的 wait () 方法,放弃 Monitor,进入 "Wait Set" 队列。只有当别的线程在该对象上调用了 notify () 或者 notifyAll () 方法,"Wait Set" 队列中的线程才得到机会去竞争,但是只有一个线程获得对象的 Monitor,恢复到运行态。"Wait Set" 中的线程在 Thread Dump 中显示的状态为 in Object.wait ()。通常来说,当 CPU 很忙的时候关注 Runnable 状态的线程,反之则关注 waiting for monitor entry 状态的线程。
# #4.4. jstack 使用示例
# #找出某 Java 进程中最耗费 CPU 的 Java 线程
(1)找出 Java 进程
假设应用名称为 myapp:
$ jps | grep myapp
29527 myapp.jar得到进程 ID 为 21711
(2)找出该进程内最耗费 CPU 的线程,可以使用 ps -Lfp pid 或者 ps -mp pid -o THREAD, tid, time 或者 top -Hp pid
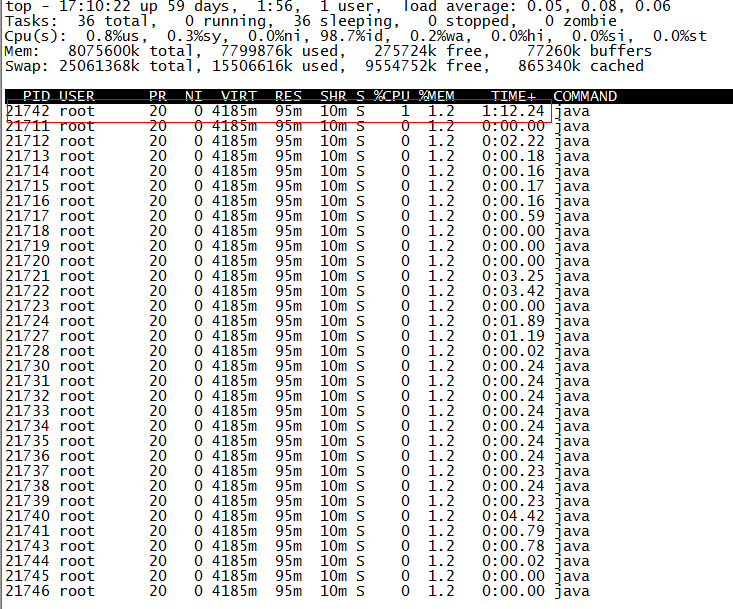 TIME 列就是各个 Java 线程耗费的 CPU 时间,CPU 时间最长的是线程 ID 为 21742 的线程,用
TIME 列就是各个 Java 线程耗费的 CPU 时间,CPU 时间最长的是线程 ID 为 21742 的线程,用
printf "%x\n" 21742得到 21742 的十六进制值为 54ee,下面会用到。
(3)使用 jstack 打印线程堆栈信息
下一步终于轮到 jstack 上场了,它用来输出进程 21711 的堆栈信息,然后根据线程 ID 的十六进制值 grep,如下:
$ jstack 21711 | grep 54ee
"PollIntervalRetrySchedulerThread" prio=10 tid=0x00007f950043e000 nid=0x54ee in Object.wait() [0x00007f94c6eda000]可以看到 CPU 消耗在 PollIntervalRetrySchedulerThread 这个类的 Object.wait() 。
注:上面的例子中,默认只显示了一行信息,但很多时候我们希望查看更详细的调用栈。可以通过指定
-A <num>的方式来显示行数。例如:jstack -l <pid> | grep <thread-hex-id> -A 10
(4)分析代码
我找了下我的代码,定位到下面的代码:
// Idle wait
getLog().info("Thread [" + getName() + "] is idle waiting...");
schedulerThreadState = PollTaskSchedulerThreadState.IdleWaiting;
long now = System.currentTimeMillis();
long waitTime = now + getIdleWaitTime();
long timeUntilContinue = waitTime - now;
synchronized(sigLock) {
try {
if(!halted.get()) {
sigLock.wait(timeUntilContinue);
}
}
catch (InterruptedException ignore) {
}
}它是轮询任务的空闲等待代码,上面的 sigLock.wait(timeUntilContinue) 就对应了前面的 Object.wait() 。
# #生成 threaddump 文件
可以使用 jstack -l <pid> > <file-path> 命令生成 threaddump 文件
【示例】生成进程 ID 为 8841 的 Java 进程的 threaddump 文件。
jstack -l 8841 > /home/threaddump.txt# #5. jinfo
jinfo(JVM Configuration info) (opens new window),是 Java 配置信息工具。jinfo 用于实时查看和调整虚拟机运行参数。如传递给 Java 虚拟机的
-X(即输出中的 jvm_args)、-XX参数(即输出中的 VM Flags),以及可在 Java 层面通过System.getProperty获取的-D参数(即输出中的 System Properties)。
之前的 jps -v 口令只能查看到显示指定的参数,如果想要查看未被显示指定的参数的值就要使用 jinfo 口令。
jinfo 命令格式:
jinfo [option] pidoption 选项参数:
-flag- 输出指定 args 参数的值-sysprops- 输出系统属性,等同于System.getProperties()
【示例】jinfo 使用示例
$ jinfo -sysprops 29527
Attaching to process ID 29527, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.222-b10
...# #6. jhat
jhat (JVM Heap Analysis Tool),是虚拟机堆转储快照分析工具。jhat 与 jmap 搭配使用,用来分析 jmap 生成的 dump 文件。jhat 内置了一个微型的 HTTP/HTML 服务器,生成 dump 的分析结果后,可以在浏览器中查看。
注意:一般不会直接在服务器上进行分析,因为 jhat 是一个耗时并且耗费硬件资源的过程,一般把服务器生成的 dump 文件,用 jvisualvm 、Eclipse Memory Analyzer、IBM HeapAnalyzer 等工具来分析。
命令格式:
jhat [dumpfile]# JVM GUI 工具
Java 程序员免不了故障排查工作,所以经常需要使用一些 JVM 工具。
本文系统性的介绍一下常用的 JVM GUI 工具。
- \1. jconsole
- \2. jvisualvm
- \3. MAT
- 4. JProfile
- \5. Arthas
- 6. 参考资料
# #1. jconsole
jconsole 是 JDK 自带的 GUI 工具。jconsole (Java Monitoring and Management Console) 是一种基于 JMX 的可视化监视与管理工具。
jconsole 的管理功能是针对 JMX MBean 进行管理,由于 MBean 可以使用代码、中间件服务器的管理控制台或所有符合 JMX 规范的软件进行访问。
注意:使用 jconsole 的前提是 Java 应用开启 JMX。
# #1.1. 开启 JMX
Java 应用开启 JMX 后,可以使用 jconsole 或 jvisualvm 进行监控 Java 程序的基本信息和运行情况。
开启方法是,在 java 指令后,添加以下参数:
-Dcom.sun.management.jmxremote=true
-Dcom.sun.management.jmxremote.ssl=false
-Dcom.sun.management.jmxremote.authenticate=false
-Djava.rmi.server.hostname=127.0.0.1
-Dcom.sun.management.jmxremote.port=18888-Djava.rmi.server.hostname- 指定 Java 程序运行的服务器-Dcom.sun.management.jmxremote.port- 指定 JMX 服务监听端口
# #1.2. 连接 jconsole
如果是本地 Java 进程,jconsole 可以直接绑定连接。
如果是远程 Java 进程,需要连接 Java 进程的 JMX 端口。
# #1.3. jconsole 界面
进入 jconsole 应用后,可以看到以下 tab 页面。
概述- 显示有关 Java VM 和监视值的概述信息。内存- 显示有关内存使用的信息。内存页相当于可视化的jstat命令。线程- 显示有关线程使用的信息。类- 显示有关类加载的信息。VM 摘要- 显示有关 Java VM 的信息。MBean- 显示有关 MBean 的信息。
# #2. jvisualvm
jvisualvm 是 JDK 自带的 GUI 工具。jvisualvm (All-In-One Java Troubleshooting Tool) 是多合一故障处理工具。它支持运行监视、故障处理、性能分析等功能。
个人觉得 jvisualvm 比 jconsole 好用。
# #2.1. jvisualvm 概述页面
jvisualvm 概述页面可以查看当前 Java 进程的基本信息,如:JDK 版本、Java 进程、JVM 参数等。
# #2.2. jvisualvm 监控页面
在 jvisualvm 监控页面,可以看到 Java 进程的 CPU、内存、类加载、线程的实时变化。
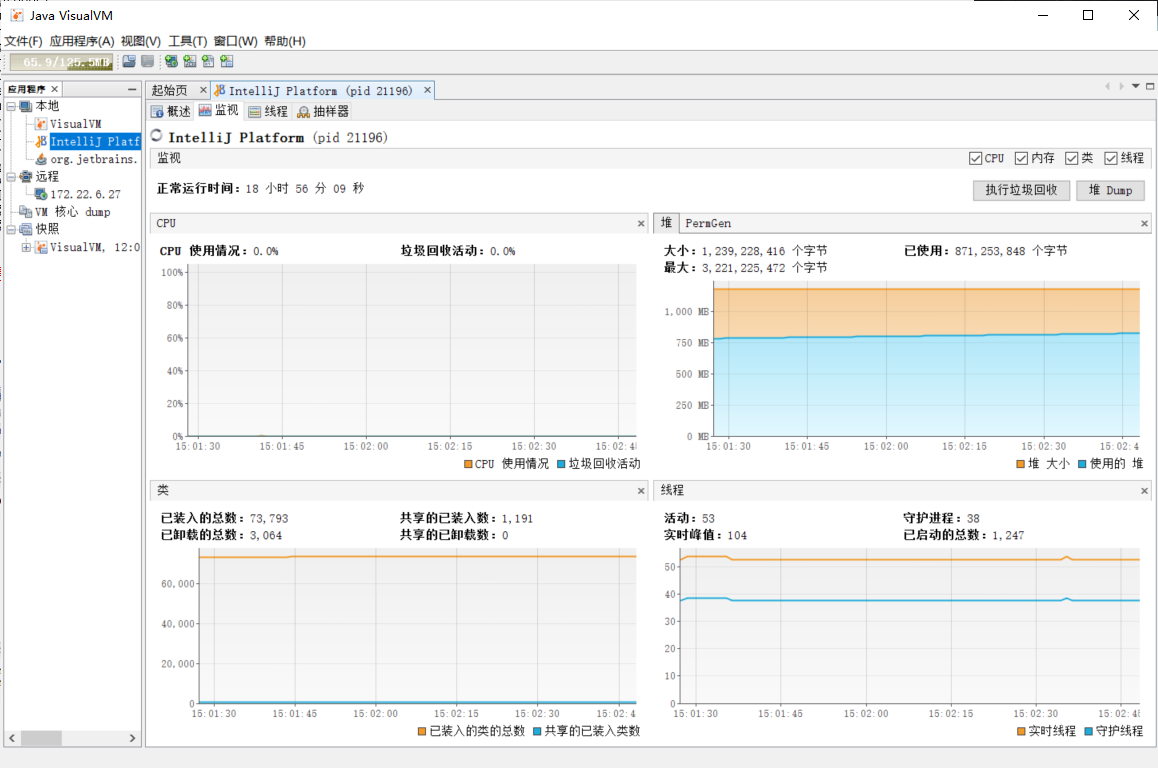
# #2.3. jvisualvm 线程页面
jvisualvm 线程页面展示了当前的线程状态。
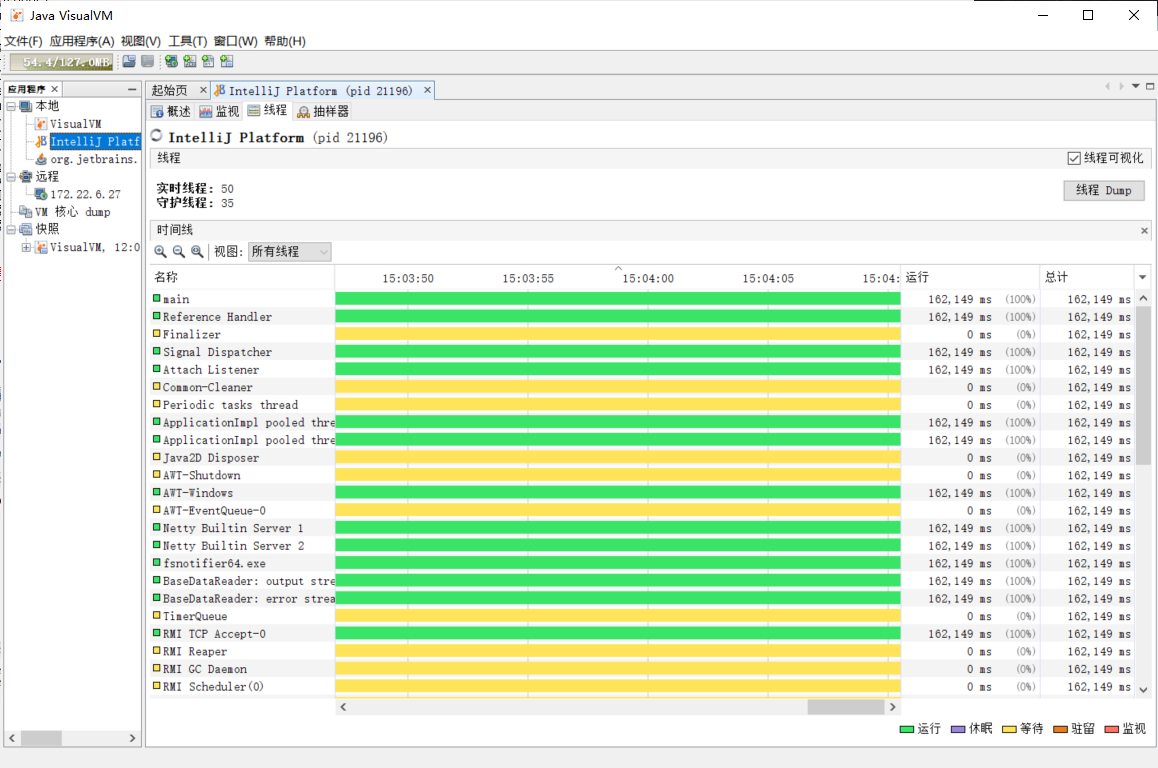
jvisualvm 还可以生成线程 Dump 文件,帮助进一步分析线程栈信息。
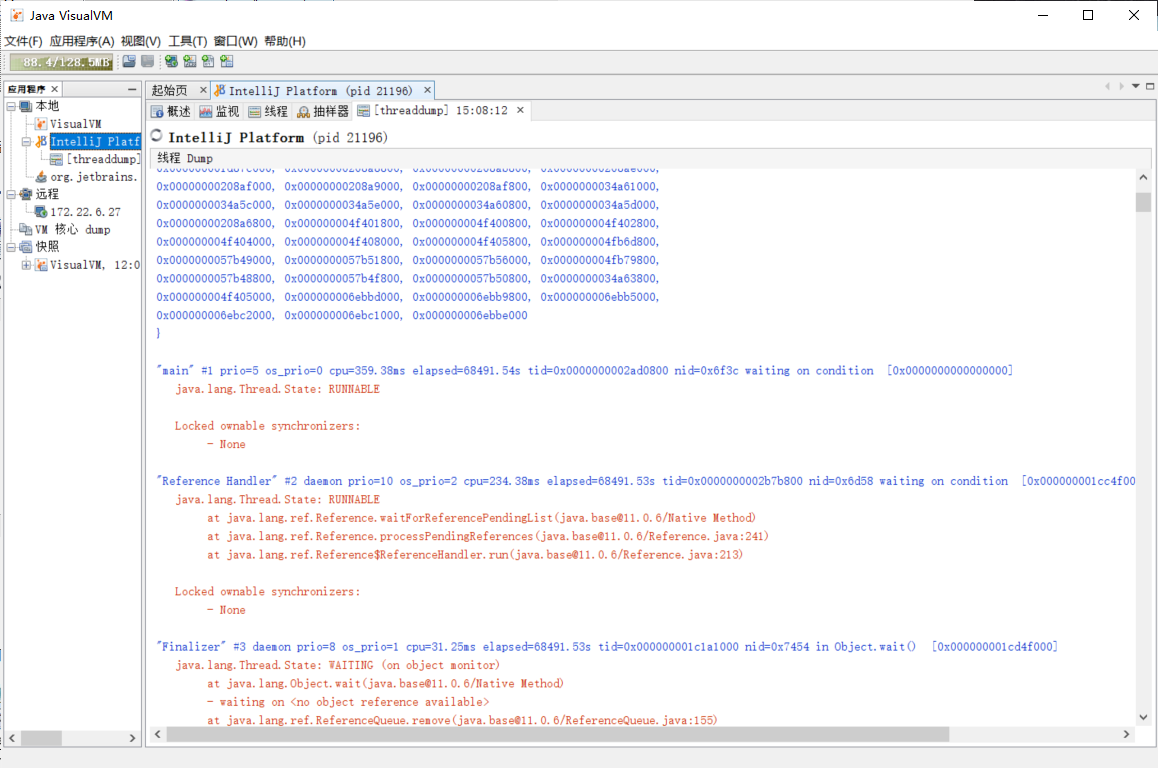
# #2.4. jvisualvm 抽样器页面
jvisualvm 可以对 CPU、内存进行抽样,帮助我们进行性能分析。

# #3. MAT
MAT (opens new window) 即 Eclipse Memory Analyzer Tool 的缩写。
MAT 本身也能够获取堆的二进制快照。该功能将借助 jps 列出当前正在运行的 Java 进程,以供选择并获取快照。由于 jps 会将自己列入其中,因此你会在列表中发现一个已经结束运行的 jps 进程。
MAT 可以独立安装(官方下载地址 (opens new window)),也可以作为 Eclipse IDE 的插件安装。
# #3.1. MAT 配置
MAT 解压后,安装目录下有个 MemoryAnalyzer.ini 文件。
MemoryAnalyzer.ini` 中有个重要的参数 `Xmx` 表示最大内存,默认为:`-vmargs -Xmx1024m如果试图用 MAT 导入的 dump 文件超过 1024 M,会报错:
An internal error occurred during: "Parsing heap dump from XXX"此时,可以适当调整 Xmx 大小。如果设置的 Xmx 数值过大,本机内存不足以支撑,启动 MAT 会报错:
Failed to create the Java Virtual Machine# #3.2. MAT 分析
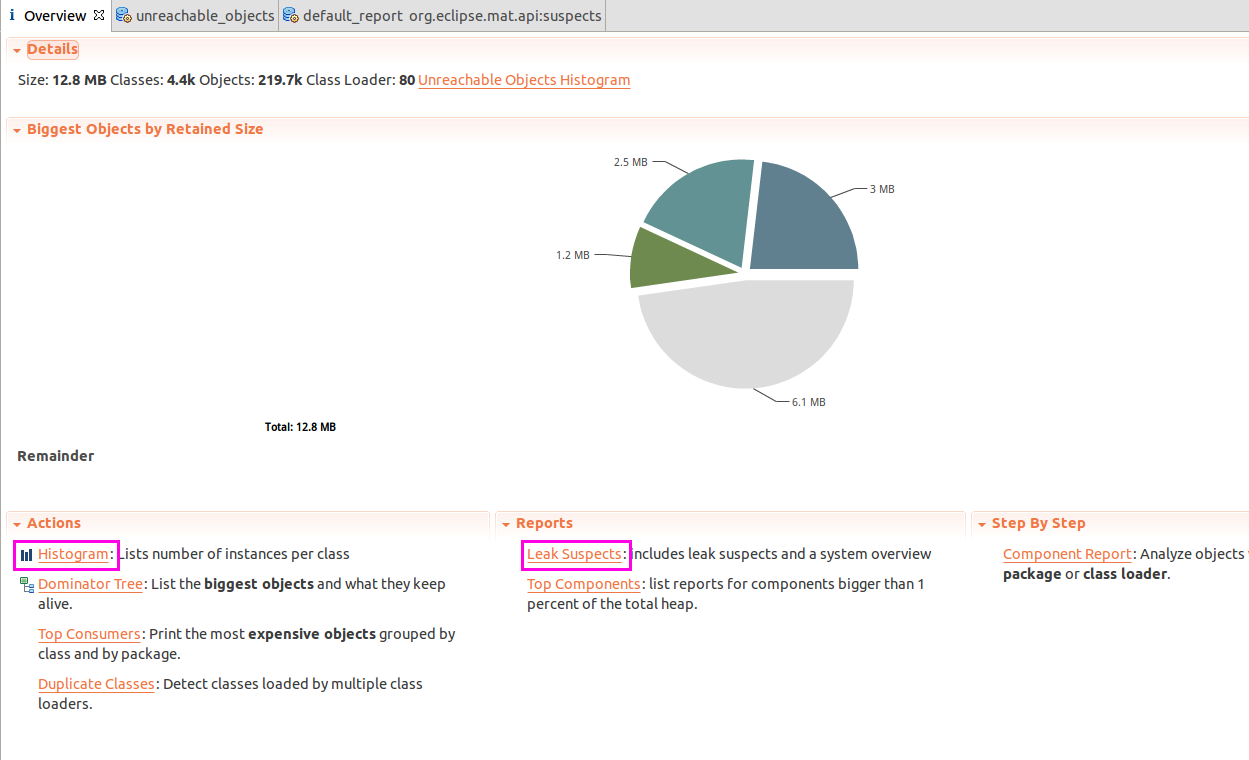
点击 Leak Suspects 可以进入内存泄漏页面。
(1)首先,可以查看饼图了解内存的整体消耗情况
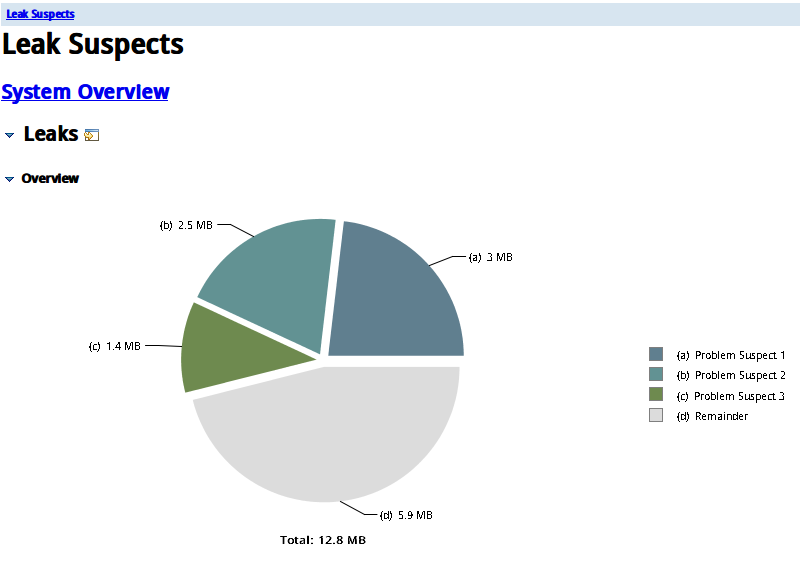
(2)缩小范围,寻找问题疑似点
可以点击进入详情页面,在详情页面 Shortest Paths To the Accumulation Point 表示 GC root 到内存消耗聚集点的最短路径,如果某个内存消耗聚集点有路径到达 GC root,则该内存消耗聚集点不会被当做垃圾被回收。
为了找到内存泄露,我获取了两个堆转储文件,两个文件获取时间间隔是一天(因为内存只是小幅度增长,短时间很难发现问题)。对比两个文件的对象,通过对比后的结果可以很方便定位内存泄露。
MAT 同时打开两个堆转储文件,分别打开 Histogram,如下图。在下图中方框 1 按钮用于对比两个 Histogram,对比后在方框 2 处选择 Group By package,然后对比各对象的变化。不难发现 heap3.hprof 比 heap6.hprof 少了 64 个 eventInfo 对象,如果对代码比较熟悉的话想必这样一个结果是能够给程序员一定的启示的。而我也是根据这个启示差找到了最终内存泄露的位置。 
# #4. JProfile
JProfiler (opens new window) 是一款性能分析工具。
由于它是收费的,所以我本人使用较少。但是,它确实功能强大,且方便使用,还可以和 Intellij Idea 集成。

# #5. Arthas
Arthas (opens new window) 是 Alibaba 开源的 Java 诊断工具,深受开发者喜爱。在线排查问题,无需重启;动态跟踪 Java 代码;实时监控 JVM 状态。
Arthas 支持 JDK 6+,支持 Linux/Mac/Windows,采用命令行交互模式,同时提供丰富的 Tab 自动补全功能,进一步方便进行问题的定位和诊断。
# #5.1. Arthas 基础命令
- help—— 查看命令帮助信息
- cat (opens new window)—— 打印文件内容,和 linux 里的 cat 命令类似
- echo (opens new window)–打印参数,和 linux 里的 echo 命令类似
- grep (opens new window)—— 匹配查找,和 linux 里的 grep 命令类似
- tee (opens new window)—— 复制标准输入到标准输出和指定的文件,和 linux 里的 tee 命令类似
- pwd (opens new window)—— 返回当前的工作目录,和 linux 命令类似
- cls—— 清空当前屏幕区域
- session—— 查看当前会话的信息
- reset (opens new window)—— 重置增强类,将被 Arthas 增强过的类全部还原,Arthas 服务端关闭时会重置所有增强过的类
- version—— 输出当前目标 Java 进程所加载的 Arthas 版本号
- history—— 打印命令历史
- quit—— 退出当前 Arthas 客户端,其他 Arthas 客户端不受影响
- stop—— 关闭 Arthas 服务端,所有 Arthas 客户端全部退出
- keymap (opens new window)——Arthas 快捷键列表及自定义快捷键
# #5.2. Arthas jvm 相关命令
- dashboard (opens new window)—— 当前系统的实时数据面板
- thread (opens new window)—— 查看当前 JVM 的线程堆栈信息
- jvm (opens new window)—— 查看当前 JVM 的信息
- sysprop (opens new window)—— 查看和修改 JVM 的系统属性
- sysenv (opens new window)—— 查看 JVM 的环境变量
- vmoption (opens new window)—— 查看和修改 JVM 里诊断相关的 option
- perfcounter (opens new window)—— 查看当前 JVM 的 Perf Counter 信息
- logger (opens new window)—— 查看和修改 logger
- getstatic (opens new window)—— 查看类的静态属性
- ognl (opens new window)—— 执行 ognl 表达式
- mbean (opens new window)—— 查看 Mbean 的信息
- heapdump (opens new window)——dump java heap, 类似 jmap 命令的 heap dump 功能
# #5.3. Arthas class/classloader 相关命令
- sc (opens new window)—— 查看 JVM 已加载的类信息
- sm (opens new window)—— 查看已加载类的方法信息
- jad (opens new window)—— 反编译指定已加载类的源码
- mc (opens new window)—— 内存编译器,内存编译
.java文件为.class文件 - redefine (opens new window)—— 加载外部的
.class文件,redefine 到 JVM 里 - dump (opens new window)——dump 已加载类的 byte code 到特定目录
- classloader (opens new window)—— 查看 classloader 的继承树,urls,类加载信息,使用 classloader 去 getResource
# #5.4. Arthas monitor/watch/trace 相关命令
请注意,这些命令,都通过字节码增强技术来实现的,会在指定类的方法中插入一些切面来实现数据统计和观测,因此在线上、预发使用时,请尽量明确需要观测的类、方法以及条件,诊断结束要执行
stop或将增强过的类执行reset命令。
- monitor (opens new window)—— 方法执行监控
- watch (opens new window)—— 方法执行数据观测
- trace (opens new window)—— 方法内部调用路径,并输出方法路径上的每个节点上耗时
- stack (opens new window)—— 输出当前方法被调用的调用路径
- tt (opens new window)—— 方法执行数据的时空隧道,记录下指定方法每次调用的入参和返回信息,并能对这些不同的时间下调用进行观测
# Java 应用故障诊断
# #一、故障定位思路
Java 应用出现线上故障,如何进行诊断?
我们在定位线上问题时要有一个整体的思路,顺藤摸瓜,才能较快的找到问题原因。
一般来说,服务器故障诊断的整体思路如下:
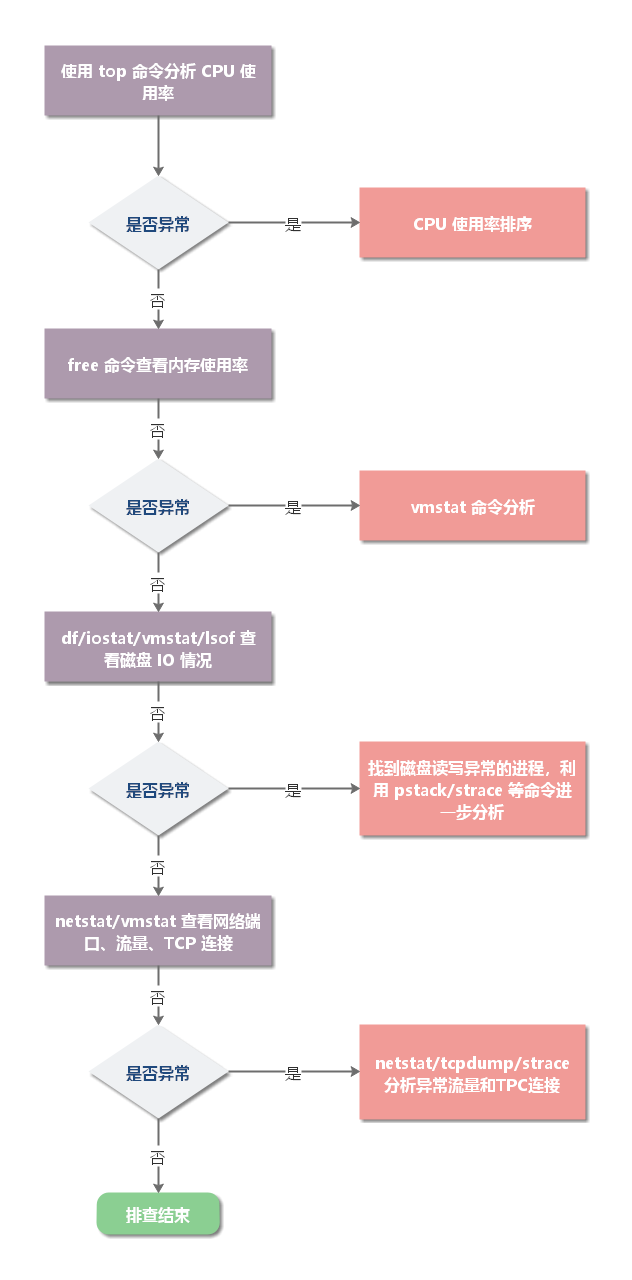
应用故障诊断思路:
# #二、CPU 问题
一、CPU 使用率过高:往往是由于程序逻辑问题导致的。常见导致 CPU 飙升的问题场景如:死循环,无限递归、频繁 GC、线程上下文切换过多。
二、CPU 始终升不上去:往往是由于程序中存在大量 IO 操作并且时间很长(数据库读写、日志等)。
# #查找 CPU 占用率较高的进程、线程
线上环境的 Java 应用可能有多个进程、线程,所以,要先找到 CPU 占用率较高的进程、线程。
(1)使用 ps 命令查看 xxx 应用的进程 ID(PID)
ps -ef | grep xxx也可以使用 jps 命令来查看。
(2)如果应用有多个进程,可以用 top 命令查看哪个占用 CPU 较高。
(3)用 top -Hp pid 来找到 CPU 使用率比较高的一些线程。
(4)将占用 CPU 最高的 PID 转换为 16 进制,使用 printf '%x\n' pid 得到 nid
(5)使用 jstack pic | grep 'nid' -C5 命令,查看堆栈信息:
$ jstack 7129 | grep '0x1c23' -C5
at java.lang.Object.wait(Object.java:502)
at java.lang.ref.Reference.tryHandlePending(Reference.java:191)
- locked <0x00000000b5383ff0> (a java.lang.ref.Reference$Lock)
at java.lang.ref.Reference$ReferenceHandler.run(Reference.java:153)
"main" #1 prio=5 os_prio=0 tid=0x00007f4df400a800 nid=0x1c23 in Object.wait() [0x00007f4dfdec8000]
java.lang.Thread.State: WAITING (on object monitor)
at java.lang.Object.wait(Native Method)
- waiting on <0x00000000b5384018> (a org.apache.felix.framework.util.ThreadGate)
at org.apache.felix.framework.util.ThreadGate.await(ThreadGate.java:79)
- locked <0x00000000b5384018> (a org.apache.felix.framework.util.ThreadGate)(6)更常见的操作是用 jstack 生成堆栈快照,然后基于快照文件进行分析。生成快照命令:
jstack -F -l pid >> threaddump.log(7)分析堆栈信息
一般来说,状态为 WAITING 、 TIMED_WAITING 、 BLOCKED 的线程更可能出现问题。可以执行以下命令查看线程状态统计:
cat threaddump.log | grep "java.lang.Thread.State" | sort -nr | uniq -c如果存在大量 WAITING 、 TIMED_WAITING 、 BLOCKED ,那么多半是有问题啦。
# #是否存在频繁 GC
如果应用频繁 GC,也可能导致 CPU 飙升。为何频繁 GC 可以使用 jstack 来分析问题(分析和解决频繁 GC 问题,在后续讲解)。
那么,如何判断 Java 进程 GC 是否频繁?
可以使用 jstat -gc pid 1000 命令来观察 GC 状态。
$ jstat -gc 29527 200 5
S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
22528.0 22016.0 0.0 21388.2 4106752.0 921244.7 5592576.0 2086826.5 110716.0 103441.1 12416.0 11167.7 3189 90.057 10 2.140 92.197
22528.0 22016.0 0.0 21388.2 4106752.0 921244.7 5592576.0 2086826.5 110716.0 103441.1 12416.0 11167.7 3189 90.057 10 2.140 92.197
22528.0 22016.0 0.0 21388.2 4106752.0 921244.7 5592576.0 2086826.5 110716.0 103441.1 12416.0 11167.7 3189 90.057 10 2.140 92.197
22528.0 22016.0 0.0 21388.2 4106752.0 921244.7 5592576.0 2086826.5 110716.0 103441.1 12416.0 11167.7 3189 90.057 10 2.140 92.197
22528.0 22016.0 0.0 21388.2 4106752.0 921244.7 5592576.0 2086826.5 110716.0 103441.1 12416.0 11167.7 3189 90.057 10 2.140 92.197# #是否存在频繁上下文切换
针对频繁上下文切换问题,可以使用 vmstat pid 命令来进行查看。
$ vmstat 7129
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 6836 737532 1588 3504956 0 0 1 4 5 3 0 0 100 0 0其中, cs 一列代表了上下文切换的次数。
【解决方法】
如果,线程上下文切换很频繁,可以考虑在应用中针对线程进行优化,方法有:
- 无锁并发:多线程竞争时,会引起上下文切换,所以多线程处理数据时,可以用一些办法来避免使用锁,如将数据的 ID 按照 Hash 取模分段,不同的线程处理不同段的数据;
- CAS 算法:Java 的 Atomic 包使用 CAS 算法来更新数据,而不需要加锁;
- 最少线程:避免创建不需要的线程,比如任务很少,但是创建了很多线程来处理,这样会造成大量线程都处于等待状态;
- 使用协程:在单线程里实现多任务的调度,并在单线程里维持多个任务间的切换;
# #三、内存问题
内存问题诊断起来相对比 CPU 麻烦一些,场景也比较多。主要包括 OOM、GC 问题和堆外内存。一般来讲,我们会先用 free 命令先来检查一发内存的各种情况。
诊断内存问题,一般首先会用 free 命令查看一下机器的物理内存使用情况。
$ free
total used free shared buff/cache available
Mem: 8011164 3767900 735364 8804 3507900 3898568
Swap: 5242876 6836 5236040# #四、磁盘问题
# #查看磁盘空间使用率
可以使用 df -hl 命令查看磁盘空间使用率。
$ df -hl
Filesystem Size Used Avail Use% Mounted on
devtmpfs 494M 0 494M 0% /dev
tmpfs 504M 0 504M 0% /dev/shm
tmpfs 504M 58M 447M 12% /run
tmpfs 504M 0 504M 0% /sys/fs/cgroup
/dev/sda2 20G 5.7G 13G 31% /
/dev/sda1 380M 142M 218M 40% /boot
tmpfs 101M 0 101M 0% /run/user/0# #查看磁盘读写性能
可以使用 iostat 命令查看磁盘读写性能。
iostat -d -k -x
Linux 3.10.0-327.el7.x86_64 (elk-server) 03/07/2020 _x86_64_ (4 CPU)
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.14 0.01 1.63 0.42 157.56 193.02 0.00 2.52 11.43 2.48 0.60 0.10
scd0 0.00 0.00 0.00 0.00 0.00 0.00 8.00 0.00 0.27 0.27 0.00 0.27 0.00
dm-0 0.00 0.00 0.01 1.78 0.41 157.56 177.19 0.00 2.46 12.09 2.42 0.59 0.10
dm-1 0.00 0.00 0.00 0.00 0.00 0.00 16.95 0.00 1.04 1.04 0.00 1.02 0.00# #查看具体的文件读写情况
可以使用 lsof -p pid 命令
# #五、网络问题
# #无法连接
可以通过 ping 命令,查看是否能连通。
通过 netstat -nlp | grep <port> 命令,查看服务端口是否在工作。
# #网络超时
网络超时问题大部分出在应用层面。超时大体可以分为连接超时和读写超时,某些使用连接池的客户端框架还会存在获取连接超时和空闲连接清理超时。
- 读写超时。readTimeout/writeTimeout,有些框架叫做 so_timeout 或者 socketTimeout,均指的是数据读写超时。注意这边的超时大部分是指逻辑上的超时。soa 的超时指的也是读超时。读写超时一般都只针对客户端设置。
- 连接超时。connectionTimeout,客户端通常指与服务端建立连接的最大时间。服务端这边 connectionTimeout 就有些五花八门了,jetty 中表示空闲连接清理时间,tomcat 则表示连接维持的最大时间。
- 其他。包括连接获取超时 connectionAcquireTimeout 和空闲连接清理超时 idleConnectionTimeout。多用于使用连接池或队列的客户端或服务端框架。
我们在设置各种超时时间中,需要确认的是尽量保持客户端的超时小于服务端的超时,以保证连接正常结束。
在实际开发中,我们关心最多的应该是接口的读写超时了。
如何设置合理的接口超时是一个问题。如果接口超时设置的过长,那么有可能会过多地占用服务端的 tcp 连接。而如果接口设置的过短,那么接口超时就会非常频繁。
服务端接口明明 rt 降低,但客户端仍然一直超时又是另一个问题。这个问题其实很简单,客户端到服务端的链路包括网络传输、排队以及服务处理等,每一个环节都可能是耗时的原因。
# #TCP 队列溢出
tcp 队列溢出是个相对底层的错误,它可能会造成超时、rst 等更表层的错误。因此错误也更隐蔽,所以我们单独说一说。 
如上图所示,这里有两个队列:syns queue (半连接队列)、accept queue(全连接队列)。三次握手,在 server 收到 client 的 syn 后,把消息放到 syns queue,回复 syn+ack 给 client,server 收到 client 的 ack,如果这时 accept queue 没满,那就从 syns queue 拿出暂存的信息放入 accept queue 中,否则按 tcp_abort_on_overflow 指示的执行。
tcp_abort_on_overflow 0 表示如果三次握手第三步的时候 accept queue 满了那么 server 扔掉 client 发过来的 ack。tcp_abort_on_overflow 1 则表示第三步的时候如果全连接队列满了,server 发送一个 rst 包给 client,表示废掉这个握手过程和这个连接,意味着日志里可能会有很多 connection reset / connection reset by peer 。
那么在实际开发中,我们怎么能快速定位到 tcp 队列溢出呢?
netstat 命令,执行 netstat -s | egrep “listen|LISTEN”  如上图所示,overflowed 表示全连接队列溢出的次数,sockets dropped 表示半连接队列溢出的次数。
如上图所示,overflowed 表示全连接队列溢出的次数,sockets dropped 表示半连接队列溢出的次数。
ss 命令,执行 ss -lnt  上面看到 Send-Q 表示第三列的 listen 端口上的全连接队列最大为 5,第一列 Recv-Q 为全连接队列当前使用了多少。
上面看到 Send-Q 表示第三列的 listen 端口上的全连接队列最大为 5,第一列 Recv-Q 为全连接队列当前使用了多少。
接着我们看看怎么设置全连接、半连接队列大小吧:
全连接队列的大小取决于 min (backlog, somaxconn)。backlog 是在 socket 创建的时候传入的,somaxconn 是一个 os 级别的系统参数。而半连接队列的大小取决于 max (64, /proc/sys/net/ipv4/tcp_max_syn_backlog)。
在日常开发中,我们往往使用 servlet 容器作为服务端,所以我们有时候也需要关注容器的连接队列大小。在 tomcat 中 backlog 叫做 acceptCount ,在 jetty 里面则是 acceptQueueSize 。
# #RST 异常
RST 包表示连接重置,用于关闭一些无用的连接,通常表示异常关闭,区别于四次挥手。
在实际开发中,我们往往会看到 connection reset / connection reset by peer 错误,这种情况就是 RST 包导致的。
端口不存在
如果像不存在的端口发出建立连接 SYN 请求,那么服务端发现自己并没有这个端口则会直接返回一个 RST 报文,用于中断连接。
主动代替 FIN 终止连接
一般来说,正常的连接关闭都是需要通过 FIN 报文实现,然而我们也可以用 RST 报文来代替 FIN,表示直接终止连接。实际开发中,可设置 SO_LINGER 数值来控制,这种往往是故意的,来跳过 TIMED_WAIT,提供交互效率,不闲就慎用。
客户端或服务端有一边发生了异常,该方向对端发送 RST 以告知关闭连接
我们上面讲的 tcp 队列溢出发送 RST 包其实也是属于这一种。这种往往是由于某些原因,一方无法再能正常处理请求连接了 (比如程序崩了,队列满了),从而告知另一方关闭连接。
接收到的 TCP 报文不在已知的 TCP 连接内
比如,一方机器由于网络实在太差 TCP 报文失踪了,另一方关闭了该连接,然后过了许久收到了之前失踪的 TCP 报文,但由于对应的 TCP 连接已不存在,那么会直接发一个 RST 包以便开启新的连接。
一方长期未收到另一方的确认报文,在一定时间或重传次数后发出 RST 报文
这种大多也和网络环境相关了,网络环境差可能会导致更多的 RST 报文。
之前说过 RST 报文多会导致程序报错,在一个已关闭的连接上读操作会报 connection reset ,而在一个已关闭的连接上写操作则会报 connection reset by peer 。通常我们可能还会看到 broken pipe 错误,这是管道层面的错误,表示对已关闭的管道进行读写,往往是在收到 RST,报出 connection reset 错后继续读写数据报的错,这个在 glibc 源码注释中也有介绍。
我们在诊断故障时候怎么确定有 RST 包的存在呢?当然是使用 tcpdump 命令进行抓包,并使用 wireshark 进行简单分析了。 tcpdump -i en0 tcp -w xxx.cap ,en0 表示监听的网卡。 
接下来我们通过 wireshark 打开抓到的包,可能就能看到如下图所示,红色的就表示 RST 包了。 
# #TIME_WAIT 和 CLOSE_WAIT
TIME_WAIT 和 CLOSE_WAIT 是啥意思相信大家都知道。 在线上时,我们可以直接用命令 netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}' 来查看 time-wait 和 close_wait 的数量
用 ss 命令会更快 ss -ant | awk '{++S[$1]} END {for(a in S) print a, S[a]}'

# #TIME_WAIT
time_wait 的存在一是为了丢失的数据包被后面连接复用,二是为了在 2MSL 的时间范围内正常关闭连接。它的存在其实会大大减少 RST 包的出现。
过多的 time_wait 在短连接频繁的场景比较容易出现。这种情况可以在服务端做一些内核参数调优:
#表示开启重用。允许将TIME-WAIT sockets重新用于新的TCP连接,默认为0,表示关闭
net.ipv4.tcp_tw_reuse = 1
#表示开启TCP连接中TIME-WAIT sockets的快速回收,默认为0,表示关闭
net.ipv4.tcp_tw_recycle = 1当然我们不要忘记在 NAT 环境下因为时间戳错乱导致数据包被拒绝的坑了,另外的办法就是改小 tcp_max_tw_buckets ,超过这个数的 time_wait 都会被干掉,不过这也会导致报 time wait bucket table overflow 的错。
# #CLOSE_WAIT
close_wait 往往都是因为应用程序写的有问题,没有在 ACK 后再次发起 FIN 报文。close_wait 出现的概率甚至比 time_wait 要更高,后果也更严重。往往是由于某个地方阻塞住了,没有正常关闭连接,从而渐渐地消耗完所有的线程。
想要定位这类问题,最好是通过 jstack 来分析线程堆栈来诊断问题,具体可参考上述章节。这里仅举一个例子。
开发同学说应用上线后 CLOSE_WAIT 就一直增多,直到挂掉为止,jstack 后找到比较可疑的堆栈是大部分线程都卡在了 countdownlatch.await 方法,找开发同学了解后得知使用了多线程但是确没有 catch 异常,修改后发现异常仅仅是最简单的升级 sdk 后常出现的 class not found 。
# #六、GC 问题
GC 问题除了影响 CPU 也会影响内存,诊断思路也是一致的。
(1)通常,先使用 jstat 来查看分代变化情况,比如 minor gc 或 full gc 次数是不是太频繁、耗时太久。
线程量太大,且不被及时 GC 也会引发 OOM,大部分就是之前说的 unable to create new native thread 。除了 jstack 细细分析 dump 文件外,我们一般先会看下总体线程。
可以执行以下命令中任意一个,没来查看当前进程创建的总线程数。
pstreee -p pid | wc -l
ls -l /proc/pid/task | wc -l堆内内存泄漏总是和 GC 异常相伴。不过 GC 问题不只是和内存问题相关,还有可能引起 CPU 负载、网络问题等系列并发症,只是相对来说和内存联系紧密些,所以我们在此单独总结一下 GC 相关问题。
我们在 cpu 章介绍了使用 jstat 来获取当前 GC 分代变化信息。而更多时候,我们是通过 GC 日志来诊断问题的,在启动参数中加上 -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps 来开启 GC 日志。 常见的 Minor GC、Full GC 日志含义在此就不做赘述了。
针对 gc 日志,我们就能大致推断出 Minor GC 与 fullGC 是否过于频繁或者耗时过长,从而对症下药。我们下面将对 G1 垃圾收集器来做分析,这边也建议大家使用 G1 -XX:+UseG1GC 。
# #OOM
查看 GC 日志,如果有明显提示 OOM 问题,那就可以根据提示信息,较为快速的定位问题。
OOM 定位可以参考:JVM 内存管理 之 OutOfMemoryError
# #Minor GC
# #Minor GC 过频
Minor GC 频繁一般是短周期的 Java 小对象较多。
(1)先考虑是不是 Eden 区 / 新生代设置的太小了,看能否通过调整 -Xmn、-XX:SurvivorRatio 等参数设置来解决问题。
(2)如果参数正常,但是 Minor GC 频率还是太高,就需要使用 jmap 和 MAT 对 dump 文件进行进一步诊断了。
# #Minor GC 耗时过长
Minor GC 耗时过长问题就要看 GC 日志里耗时耗在哪一块了。
以 G1 GC 日志为例,可以关注 Root Scanning、Object Copy、Ref Proc 等阶段。Ref Proc 耗时长,就要注意引用相关的对象。Root Scanning 耗时长,就要注意线程数、跨代引用。Object Copy 则需要关注对象生存周期。而且耗时分析它需要横向比较,就是和其他项目或者正常时间段的耗时比较。
# #Full GC 过频
G1 中更多的还是 mixedGC,但 mixedGC 可以和 Minor GC 思路一样去诊断。触发 fullGC 了一般都会有问题,G1 会退化使用 Serial 收集器来完成垃圾的清理工作,暂停时长达到秒级别,可以说是半跪了。
fullGC 的原因可能包括以下这些,以及参数调整方面的一些思路:
- 并发阶段失败:在并发标记阶段,MixGC 之前老年代就被填满了,那么这时候 G1 就会放弃标记周期。这种情况,可能就需要增加堆大小,或者调整并发标记线程数
-XX:ConcGCThreads。 - 晋升失败:在 GC 的时候没有足够的内存供存活 / 晋升对象使用,所以触发了 Full GC。这时候可以通过
-XX:G1ReservePercent来增加预留内存百分比,减少-XX:InitiatingHeapOccupancyPercent来提前启动标记,-XX:ConcGCThreads来增加标记线程数也是可以的。 - 大对象分配失败:大对象找不到合适的 region 空间进行分配,就会进行 fullGC,这种情况下可以增大内存或者增大
-XX:G1HeapRegionSize。 - 程序主动执行 System.gc ():不要随便写就对了。
另外,我们可以在启动参数中配置 -XX:HeapDumpPath=/xxx/dump.hprof 来 dump fullGC 相关的文件,并通过 jinfo 来进行 gc 前后的 dump
jinfo -flag +HeapDumpBeforeFullGC pid
jinfo -flag +HeapDumpAfterFullGC pid这样得到 2 份 dump 文件,对比后主要关注被 gc 掉的问题对象来定位问题。
# #七、常用 Linux 命令
在故障排查时,有一些 Linux 命令十分有用,建议掌握。
# #top
top 命令可以实时动态地查看系统的整体运行情况,是一个综合了多方信息监测系统性能和运行信息的实用工具。
通常,会使用 top -Hp pid 查看具体线程使用系统资源情况。
命令详情参考:http://man.linuxde.net/top
# #vmstat
vmstat 是一款指定采样周期和次数的功能性监测工具,我们可以看到,它不仅可以统计内存的使用情况,还可以观测到 CPU 的使用率、swap 的使用情况。但 vmstat 一般很少用来查看内存的使用情况,而是经常被用来观察进程的上下文切换。
- r:等待运行的进程数;
- b:处于非中断睡眠状态的进程数;
- swpd:虚拟内存使用情况;
- free:空闲的内存;
- buff:用来作为缓冲的内存数;
- si:从磁盘交换到内存的交换页数量;
- so:从内存交换到磁盘的交换页数量;
- bi:发送到块设备的块数;
- bo:从块设备接收到的块数;
- in:每秒中断数;
- cs:每秒上下文切换次数;
- us:用户 CPU 使用时间;
- sy:内核 CPU 系统使用时间;
- id:空闲时间;
- wa:等待 I/O 时间;
- st:运行虚拟机窃取的时间。
# 面试题
# 基础
# #工具类
# #String
String 类能被继承吗?
String,StringBuffer,StringBuilder 的区别。
String 类不能被继承。因为其被 final 修饰,所以无法被继承。
StringBuffer,StringBuilder 拼接字符串,使用 append 比 String 效率高。因为 String 会隐式 new String 对象。
StringBuffer 主要方法都用 synchronized 修饰,是线程安全的;而 StringBuilder 不是。
# #面向对象
抽象类和接口的区别?
类可以继承多个类么?接口可以继承多个接口么?类可以实现多个接口么?
类只能继承一个类,但是可以实现多个接口。接口可以继承多个接口。
继承和聚合的区别在哪?
一般,能用聚合就别用继承。
# #反射
# #⭐ 创建实例
反射创建实例有几种方式?
通过反射来创建实例对象主要有两种方式:
- 用
Class对象的newInstance方法。 - 用
Constructor对象的newInstance方法。
# #⭐ 加载实例
加载实例有几种方式?
Class.forName (“className”) 和 ClassLoader.laodClass (“className”) 有什么区别?
Class.forName("className")加载的是已经初始化到 JVM 中的类。ClassLoader.laodClass("className")装载的是还没有初始化到 JVM 中的类。
# #⭐⭐ 动态代理
动态代理有几种实现方式?有什么特点?
JDK 动态代理和 CGLIB 动态代理有什么区别?
(1)JDK 方式
代理类与委托类实现同一接口,主要是通过代理类实现 InvocationHandler 并重写 invoke 方法来进行动态代理的,在 invoke 方法中将对方法进行处理。
JDK 动态代理特点:
- 优点:相对于静态代理模式,不需要硬编码接口,代码复用率高。
- 缺点:强制要求代理类实现
InvocationHandler接口。
(2)CGLIB
CGLIB 底层,其实是借助了 ASM 这个强大的 Java 字节码框架去进行字节码增强操作。
CGLIB 动态代理特点:
优点:使用字节码增强,比 JDK 动态代理方式性能高。可以在运行时对类或者是接口进行增强操作,且委托类无需实现接口。
缺点:不能对 final 类以及 final 方法进行代理。
# #JDK8
# #其他
# #⭐ hashcode
有
==运算符了,为什么还需要 equals 啊?说一说你对 java.lang.Object 对象中 hashCode 和 equals 方法的理解。在什么场景下需 要重新实现这两个方法。
有没有可能 2 个不相等的对象有相同的 hashcode
(1)有 == 运算符了,为什么还需要 equals 啊?
equals 等价于 == , 而 == 运算符是判断两个对象是不是同一个对象,即他们的地址是否相等。而覆写 equals 更多的是追求两个对象在逻辑上的相等,你可以说是值相等,也可说是内容相等。
(2)说一说你对 java.lang.Object 对象中 hashCode 和 equals 方法的理解。在什么场景下需 要重新实现这两个方法。
在集合查找时,hashcode 能大大降低对象比较次数,提高查找效率!
(3)有没有可能 2 个不相等的对象有相同的 hashcode
有可能。
- 如果两个对象 equals,Java 运行时环境会认为他们的 hashcode 一定相等。
- 如果两个对象不 equals,他们的 hashcode 有可能相等。
- 如果两个对象 hashcode 相等,他们不一定 equals。
- 如果两个对象 hashcode 不相等,他们一定不 equals。
# #IO
# #NIO
什么是 NIO?
NIO 和 BIO、AIO 有何差别?
# #序列化
# #⭐ 序列化问题
序列化、反序列化有哪些问题?如何解决?
Java 的序列化能保证对象状态的持久保存,但是遇到一些对象结构复杂的情况还是难以处理,这里归纳一下:
- 当父类继承
Serializable接口时,所有子类都可以被序列化。 - 子类实现了
Serializable接口,父类没有,则父类的属性不会被序列化(不报错,数据丢失),子类的属性仍可以正确序列化。 - 如果序列化的属性是对象,则这个对象也必须实现
Serializable接口,否则会报错。 - 在反序列化时,如果对象的属性有修改或删减,则修改的部分属性会丢失,但不会报错。
- 在反序列化时,如果
serialVersionUID被修改,则反序列化时会失败。
# #容器
# #List
# #ArrayList 和 LinkedList 有什么区别?
ArrayList 是数组链表,访问效率更高。
LinkedList 是双链表,数据有序存储。
# #Map
请描述 HashMap 的实现原理?
# #并发
# #并发简介
# #什么是进程?什么是线程?进程和线程的区别?
- 什么是进程?
- 简言之,进程可视为一个正在运行的程序。
- 进程是具有一定独立功能的程序关于某个数据集合上的一次运行活动。进程是操作系统进行资源分配的基本单位。
- 什么是线程?
- 线程是操作系统进行调度的基本单位。
- 进程 vs. 线程
- 一个程序至少有一个进程,一个进程至少有一个线程。
- 线程比进程划分更细,所以执行开销更小,并发性更高。
- 进程是一个实体,拥有独立的资源;而同一个进程中的多个线程共享进程的资源。
# #并发(多线程)编程的好处是什么?
- 更有效率的利用多处理器核心
- 更快的响应时间
- 更好的编程模型
# #并发一定比串行更快吗?
答:否。
要点:创建线程和线程上下文切换有一定开销。
说明:即使是单核处理器也支持多线程。CPU 通过给每个线程分配时间切片的算法来循环执行任务,当前任务执行一个时间片后会切换到下一个任务。但是,在切换前会保持上一个任务的状态,以便下次切换回这个任务时,可以再加载这个任务的状态。所以任务从保存到再加载的过程就是一次上下文切换。
引申
- 如何减少上下文切换?
- 尽量少用锁
- CAS 算法
- 线程数要合理
- 协程:在单线程中实现多任务调度,并在单线程中维持多个任务的切换
# #如何让正在运行的线程暂停一段时间?
我们可以使用 Thread 类的 Sleep () 方法让线程暂停一段时间。
需要注意的是,这并不会让线程终止,一旦从休眠中唤醒线程,线程的状态将会被改变为 Runnable,并且根据线程调度,它将得到执行。
# #什么是线程调度器 (Thread Scheduler) 和时间分片 (Time Slicing)?
线程调度器是一个操作系统服务,它负责为 Runnable 状态的线程分配 CPU 时间。一旦我们创建一个线程并启动它,它的执行便依赖于线程调度器的实现。
时间分片是指将可用的 CPU 时间分配给可用的 Runnable 线程的过程。
分配 CPU 时间可以基于线程优先级或者线程等待的时间。线程调度并不受到 Java 虚拟机控制,所以由应用程序来控制它是更好的选择(也就是说不要让你的程序依赖于线程的优先级)。
# #在多线程中,什么是上下文切换 (context-switching)?
上下文切换是存储和恢复 CPU 状态的过程,它使得线程执行能够从中断点恢复执行。上下文切换是多任务操作系统和多线程环境的基本特征。
# #如何确保线程安全?
- 原子类 (atomic concurrent classes)
- 锁
volatile关键字- 不变类和线程安全类
# #什么是死锁 (Deadlock)?如何分析和避免死锁?
死锁是指两个以上的线程永远相互阻塞的情况,这种情况产生至少需要两个以上的线程和两个以上的资源。
分析死锁,我们需要查看 Java 应用程序的线程转储。我们需要找出那些状态为 BLOCKED 的线程和他们等待的资源。每个资源都有一个唯一的 id,用这个 id 我们可以找出哪些线程已经拥有了它的对象锁。
避免嵌套锁,只在需要的地方使用锁和避免无限期等待是避免死锁的通常办法。
# #线程基础
# #Java 线程生命周期中有哪些状态?各状态之间如何切换?
java.lang.Thread.State 中定义了 6 种不同的线程状态,在给定的一个时刻,线程只能处于其中的一个状态。
以下是各状态的说明,以及状态间的联系:
-
开始(New) - 还没有调用
start()方法的线程处于此状态。 -
可运行(Runnable) - 已经调用了
start()方法的线程状态。此状态意味着,线程已经准备好了,一旦被线程调度器分配了 CPU 时间片,就可以运行线程。 -
阻塞(Blocked) - 阻塞状态。线程阻塞的线程状态等待监视器锁定。处于阻塞状态的线程正在等待监视器锁定,以便在调用
Object.wait()之后输入同步块 / 方法或重新输入同步块 / 方法。 -
等待(Waiting)
\- 等待状态。一个线程处于等待状态,是由于执行了 3 个方法中的任意方法:
- `Object.wait()`
- `Thread.join()`
- `LockSupport.park()`
- 定时等待(Timed waiting)
\- 等待指定时间的状态。一个线程处于定时等待状态,是由于执行了以下方法中的任意方法:
- `Thread.sleep(sleeptime)`
- `Object.wait(timeout)`
- `Thread.join(timeout)`
- `LockSupport.parkNanos(timeout)`
- `LockSupport.parkUntil(timeout)`
- 终止 (Terminated) - 线程
run()方法执行结束,或者因异常退出了run()方法,则该线程结束生命周期。死亡的线程不可再次复生。
👉 参考阅读:Java
ThreadMethods andThreadStates (opens new window)👉 参考阅读:Java 线程的 5 种状态及切换 (透彻讲解)(opens new window)
# #创建线程有哪些方式?这些方法各自利弊是什么?
创建线程主要有三种方式:
1. 继承 Thread 类
- 定义
Thread类的子类,并重写该类的run()方法,该run()方法的方法体就代表了线程要完成的任务。因此把run()方法称为执行体。 - 创建
Thread子类的实例,即创建了线程对象。 - 调用线程对象的
start()方法来启动该线程。
2. 实现 Runnable 接口
- 定义
Runnable接口的实现类,并重写该接口的run()方法,该run()方法的方法体同样是该线程的线程执行体。 - 创建
Runnable实现类的实例,并以此实例作为Thread对象,该Thread对象才是真正的线程对象。 - 调用线程对象的 start () 方法来启动该线程。
3. 通过 Callable 接口和 Future 接口
- 创建
Callable接口的实现类,并实现call()方法,该call()方法将作为线程执行体,并且有返回值。 - 创建
Callable实现类的实例,使用FutureTask类来包装Callable对象,该FutureTask对象封装了该Callable对象的call()方法的返回值。 - 使用
FutureTask对象作为Thread对象的 target 创建并启动新线程。 - 调用
FutureTask对象的get()方法来获得子线程执行结束后的返回值
三种创建线程方式对比
- 实现
Runnable接口优于继承Thread类,因为根据开放封闭原则 —— 实现接口更便于扩展; - 实现
Runnable接口的线程没有返回值;而使用Callable/Future方式可以让线程有返回值。
# #什么是 Callable 和 Future ?什么是 FutureTask ?
什么是 Callable 和 Future ?
Java 5 在 concurrency 包中引入了 Callable 接口,它和 Runnable 接口很相似,但它可以返回一个对象或者抛出一个异常。
Callable 接口使用泛型去定义它的返回类型。 Executors 类提供了一些有用的方法去在线程池中执行 Callable 内的任务。由于 Callable 任务是并行的,我们必须等待它返回的结果。 Future 对象为我们解决了这个问题。在线程池提交 Callable 任务后返回了一个 Future 对象,使用它我们可以知道 Callable 任务的状态和得到 Callable 返回的执行结果。 Future 提供了 get() 方法让我们可以等待 Callable 结束并获取它的执行结果。
什么是 FutureTask ?
FutureTask 是 Future 的一个基础实现,我们可以将它同 Executors 使用处理异步任务。通常我们不需要使用 FutureTask 类,单当我们打算重写 Future 接口的一些方法并保持原来基础的实现是,它就变得非常有用。我们可以仅仅继承于它并重写我们需要的方法。阅读 Java FutureTask 例子,学习如何使用它。
👉 参考阅读:Java 并发编程:Callable、Future 和 FutureTask (opens new window)
# # start() 和 run() 有什么区别?可以直接调用 Thread 类的 run() 方法么?
run()方法是线程的执行体。start()方法负责启动线程,然后 JVM 会让这个线程去执行run()方法。
可以直接调用 Thread 类的 run() 方法么?
- 可以。但是如果直接调用
Thread的run()方法,它的行为就会和普通的方法一样。 - 为了在新的线程中执行我们的代码,必须使用
start()方法。
# # sleep() 、 yield() 、 join() 方法有什么区别?为什么 sleep() 和 yield() 方法是静态(static)的?
yield()
yield()方法可以让当前正在执行的线程暂停,但它不会阻塞该线程,它只是将该线程从 Running 状态转入Runnable状态。- 当某个线程调用了
yield()方法暂停之后,只有优先级与当前线程相同,或者优先级比当前线程更高的处于就绪状态的线程才会获得执行的机会。
sleep()
sleep()方法需要指定等待的时间,它可以让当前正在执行的线程在指定的时间内暂停执行,进入 Blocked 状态。- 该方法既可以让其他同优先级或者高优先级的线程得到执行的机会,也可以让低优先级的线程得到执行机会。
- 但是,
sleep()方法不会释放 “锁标志”,也就是说如果有synchronized同步块,其他线程仍然不能访问共享数据。
join()
join()方法会使当前线程转入 Blocked 状态,等待调用join()方法的线程结束后才能继续执行。
为什么 sleep() 和 yield() 方法是静态(static)的?
Thread类的sleep()和yield()方法将处理 Running 状态的线程。所以在其他处于非 Running 状态的线程上执行这两个方法是没有意义的。这就是为什么这些方法是静态的。它们可以在当前正在执行的线程中工作,并避免程序员错误的认为可以在其他非运行线程调用这些方法。
👉 参考阅读:Java 线程中 yield 与 join 方法的区别 (opens new window)👉 参考阅读:sleep (),wait (),yield () 和 join () 方法的区别 (opens new window)
# #Java 的线程优先级如何控制?高优先级的 Java 线程一定先执行吗?
Java 中的线程优先级如何控制
- Java 中的线程优先级的范围是
[1,10],一般来说,高优先级的线程在运行时会具有优先权。可以通过thread.setPriority(Thread.MAX_PRIORITY)的方式设置,默认优先级为5。
高优先级的 Java 线程一定先执行吗
- 即使设置了线程的优先级,也无法保证高优先级的线程一定先执行。
- 原因:这是因为 Java 线程优先级依赖于操作系统的支持,然而,不同的操作系统支持的线程优先级并不相同,不能很好的和 Java 中线程优先级一一对应。
- 结论:Java 线程优先级控制并不可靠。
# #什么是守护线程?为什么要用守护线程?如何创建守护线程?
什么是守护线程
- 守护线程(Daemon Thread)是在后台执行并且不会阻止 JVM 终止的线程。
- 与守护线程(Daemon Thread)相反的,叫用户线程(User Thread),也就是非守护线程。
为什么要用守护线程
- 守护线程的优先级比较低,用于为系统中的其它对象和线程提供服务。典型的应用就是垃圾回收器。
如何创建守护线程
- 使用
thread.setDaemon(true)可以设置 thread 线程为守护线程。 - 注意点:
- 正在运行的用户线程无法设置为守护线程,所以
thread.setDaemon(true)必须在thread.start()之前设置,否则会抛出llegalThreadStateException异常; - 一个守护线程创建的子线程依然是守护线程。
- 不要认为所有的应用都可以分配给守护线程来进行服务,比如读写操作或者计算逻辑。
- 正在运行的用户线程无法设置为守护线程,所以
# #线程间是如何通信的?
当线程间是可以共享资源时,线程间通信是协调它们的重要的手段。 Object 类中 wait() , notify() 和 notifyAll() 方法可以用于线程间通信关于资源的锁的状态。
👉 参考阅读:Java 并发编程:线程间协作的两种方式:wait、notify、notifyAll 和 Condition (opens new window)
# #为什么线程通信的方法 wait() , notify() 和 notifyAll() 被定义在 Object 类里?
Java 的每个对象中都有一个锁 (monitor,也可以成为监视器) 并且 wait() 、 notify() 等方法用于等待对象的锁或者通知其他线程对象的监视器可用。在 Java 的线程中并没有可供任何对象使用的锁和同步器。这就是为什么这些方法是 Object 类的一部分,这样 Java 的每一个类都有用于线程间通信的基本方法
# #为什么 wait() , notify() 和 notifyAll() 必须在同步方法或者同步块中被调用?
当一个线程需要调用对象的 wait() 方法的时候,这个线程必须拥有该对象的锁,接着它就会释放这个对象锁并进入等待状态直到其他线程调用这个对象上的 notify() 方法。同样的,当一个线程需要调用对象的 notify() 方法时,它会释放这个对象的锁,以便其他在等待的线程就可以得到这个对象锁。
由于所有的这些方法都需要线程持有对象的锁,这样就只能通过同步来实现,所以他们只能在同步方法或者同步块中被调用。
# #并发机制的底层实现
# #⭐⭐⭐ synchronized
synchronized有什么作用?
synchronized的原理是什么?同步方法和同步块,哪个更好?
JDK1.6 对
synchronized做了哪些优化?使用
synchronized修饰静态方法和非静态方法有什么区别?
作用
synchronized 可以保证在同一个时刻,只有一个线程可以执行某个方法或者某个代码块。
synchronized 有 3 种应用方式:
- 同步实例方法 - 对于普通同步方法,锁是当前实例对象
- 同步静态方法 - 对于静态同步方法,锁是当前类的
Class对象 - 同步代码块 - 对于同步方法块,锁是
synchonized括号里配置的对象
原理
synchronized 经过编译后,会在同步块的前后分别形成 monitorenter 和 monitorexit 这两个字节码指令,这两个字节码指令都需要一个引用类型的参数来指明要锁定和解锁的对象。如果 synchronized 明确制定了对象参数,那就是这个对象的引用;如果没有明确指定,那就根据 synchronized 修饰的是实例方法还是静态方法,去对对应的对象实例或 Class 对象来作为锁对象。
synchronized 同步块对同一线程来说是可重入的,不会出现锁死问题。
synchronized 同步块是互斥的,即已进入的线程执行完成前,会阻塞其他试图进入的线程。
优化
Java 1.6 以后, synchronized 做了大量的优化,其性能已经与 Lock 、 ReadWriteLock 基本上持平。
synchronized 的优化是将锁粒度分为不同级别, synchronized 会根据运行状态动态的由低到高调整锁级别(偏向锁 -> 轻量级锁 -> 重量级锁),以减少阻塞。
同步方法 or 同步块?
- 同步块是更好的选择。
- 因为它不会锁住整个对象(当然你也可以让它锁住整个对象)。同步方法会锁住整个对象,哪怕这个类中有多个不相关联的同步块,这通常会导致他们停止执行并需要等待获得这个对象上的锁。
# #⭐ volatile
volatile有什么作用?
volatile的原理是什么?
volatile能代替锁吗?
volatile和synchronized的区别?
volatile 无法替代 synchronized ,因为 volatile 无法保证操作的原子性。
作用
被 volatile 关键字修饰的变量有两层含义:
- 保证了不同线程对这个变量进行操作时的可见性,即一个线程修改了某个变量的值,这新值对其他线程来说是立即可见的。
- 禁止指令重排序。
原理
观察加入 volatile 关键字和没有加入 volatile 关键字时所生成的汇编代码发现,加入 volatile 关键字时,会多出一个 lock 前缀指令。
lock 前缀指令实际上相当于一个内存屏障(也成内存栅栏),内存屏障会提供 3 个功能:
- 它确保指令重排序时不会把其后面的指令排到内存屏障之前的位置,也不会把前面的指令排到内存屏障的后面;即在执行到内存屏障这句指令时,在它前面的操作已经全部完成;
- 它会强制将对缓存的修改操作立即写入主存;
- 如果是写操作,它会导致其他 CPU 中对应的缓存行无效。
volatile 和 synchronized 的区别?
volatile本质是在告诉 jvm 当前变量在寄存器(工作内存)中的值是不确定的,需要从主存中读取;synchronized则是锁定当前变量,只有当前线程可以访问该变量,其他线程被阻塞住。volatile仅能使用在变量级别;synchronized 则可以使用在变量、方法、和类级别的。volatile仅能实现变量的修改可见性,不能保证原子性;而synchronized则可以保证变量的修改可见性和原子性volatile不会造成线程的阻塞;synchronized 可能会造成线程的阻塞。volatile标记的变量不会被编译器优化;synchronized 标记的变量可以被编译器优化。
# #⭐⭐ CAS
什么是 CAS?
CAS 有什么作用?
CAS 的原理是什么?
CAS 的三大问题?
作用
CAS(Compare and Swap),字面意思为比较并交换。CAS 有 3 个操作数,分别是:内存值 V,旧的预期值 A,要修改的新值 B。当且仅当预期值 A 和内存值 V 相同时,将内存值 V 修改为 B,否则什么都不做。
原理
Java 主要利用 Unsafe 这个类提供的 CAS 操作。 Unsafe 的 CAS 依赖的是 JV M 针对不同的操作系统实现的 Atomic::cmpxchg 指令。
三大问题
- ABA 问题:因为 CAS 需要在操作值的时候检查下值有没有发生变化,如果没有发生变化则更新,但是如果一个值原来是 A,变成了 B,又变成了 A,那么使用 CAS 进行检查时会发现它的值没有发生变化,但是实际上却变化了。ABA 问题的解决思路就是使用版本号。在变量前面追加上版本号,每次变量更新的时候把版本号加一,那么 A-B-A 就会变成 1A-2B-3A。
- 循环时间长开销大。自旋 CAS 如果长时间不成功,会给 CPU 带来非常大的执行开销。如果 JVM 能支持处理器提供的 pause 指令那么效率会有一定的提升,pause 指令有两个作用,第一它可以延迟流水线执行指令(de-pipeline), 使 CPU 不会消耗过多的执行资源,延迟的时间取决于具体实现的版本,在一些处理器上延迟时间是零。第二它可以避免在退出循环的时候因内存顺序冲突(memory order violation)而引起 CPU 流水线被清空(CPU pipeline flush),从而提高 CPU 的执行效率。
- 只能保证一个共享变量的原子操作。当对一个共享变量执行操作时,我们可以使用循环 CAS 的方式来保证原子操作,但是对多个共享变量操作时,循环 CAS 就无法保证操作的原子性,这个时候就可以用锁,或者有一个取巧的办法,就是把多个共享变量合并成一个共享变量来操作。比如有两个共享变量 i = 2,j=a,合并一下 ij=2a,然后用 CAS 来操作 ij。从 Java1.5 开始 JDK 提供了 AtomicReference 类来保证引用对象之间的原子性,你可以把多个变量放在一个对象里来进行 CAS 操作。
# #⭐ ThreadLocal
ThreadLocal有什么作用?
ThreadLocal的原理是什么?如何解决
ThreadLocal内存泄漏问题?
作用
ThreadLocal 是一个存储线程本地副本的工具类。
原理
Thread 类中维护着一个 ThreadLocal.ThreadLocalMap 类型的成员 threadLocals 。这个成员就是用来存储当前线程独占的变量副本。
ThreadLocalMap 是 ThreadLocal 的内部类,它维护着一个 Entry 数组, Entry 用于保存键值对,其 key 是 ThreadLocal 对象,value 是传递进来的对象(变量副本)。 Entry 继承了 WeakReference ,所以是弱引用。
内存泄漏问题
ThreadLocalMap 的 Entry 继承了 WeakReference ,所以它的 key ( ThreadLocal 对象)是弱引用,而 value (变量副本)是强引用。
- 如果
ThreadLocal对象没有外部强引用来引用它,那么ThreadLocal对象会在下次 GC 时被回收。 - 此时,
Entry中的 key 已经被回收,但是 value 由于是强引用不会被垃圾收集器回收。如果创建ThreadLocal的线程一直持续运行,那么 value 就会一直得不到回收,产生内存泄露。
那么如何避免内存泄漏呢?方法就是:使用 ThreadLocal 的 set 方法后,显示的调用 remove 方法 。
# #内存模型
# #什么是 Java 内存模型
- Java 内存模型即 Java Memory Model,简称 JMM。JMM 定义了 JVM 在计算机内存 (RAM) 中的工作方式。JMM 是隶属于 JVM 的。
- 并发编程领域两个关键问题:线程间通信和线程间同步
- 线程间通信机制
- 共享内存 - 线程间通过写 - 读内存中的公共状态来隐式进行通信。
- 消息传递 - java 中典型的消息传递方式就是 wait () 和 notify ()。
- 线程间同步机制
- 在共享内存模型中,必须显示指定某个方法或某段代码在线程间互斥地执行。
- 在消息传递模型中,由于发送消息必须在接收消息之前,因此同步是隐式进行的。
- Java 的并发采用的是共享内存模型
- JMM 决定一个线程对共享变量的写入何时对另一个线程可见。
- 线程之间的共享变量存储在主内存(main memory)中,每个线程都有一个私有的本地内存(local memory),本地内存中存储了该线程以读 / 写共享变量的副本。
- JMM 把内存分成了两部分:线程栈区和堆区
- 线程栈
- JVM 中运行的每个线程都拥有自己的线程栈,线程栈包含了当前线程执行的方法调用相关信息,我们也把它称作调用栈。随着代码的不断执行,调用栈会不断变化。
- 线程栈还包含了当前方法的所有本地变量信息。线程中的本地变量对其它线程是不可见的。
- 堆区
- 堆区包含了 Java 应用创建的所有对象信息,不管对象是哪个线程创建的,其中的对象包括原始类型的封装类(如 Byte、Integer、Long 等等)。不管对象是属于一个成员变量还是方法中的本地变量,它都会被存储在堆区。
- 一个本地变量如果是原始类型,那么它会被完全存储到栈区。
- 一个本地变量也有可能是一个对象的引用,这种情况下,这个本地引用会被存储到栈中,但是对象本身仍然存储在堆区。
- 对于一个对象的成员方法,这些方法中包含本地变量,仍需要存储在栈区,即使它们所属的对象在堆区。
- 对于一个对象的成员变量,不管它是原始类型还是包装类型,都会被存储到堆区。
- 线程栈
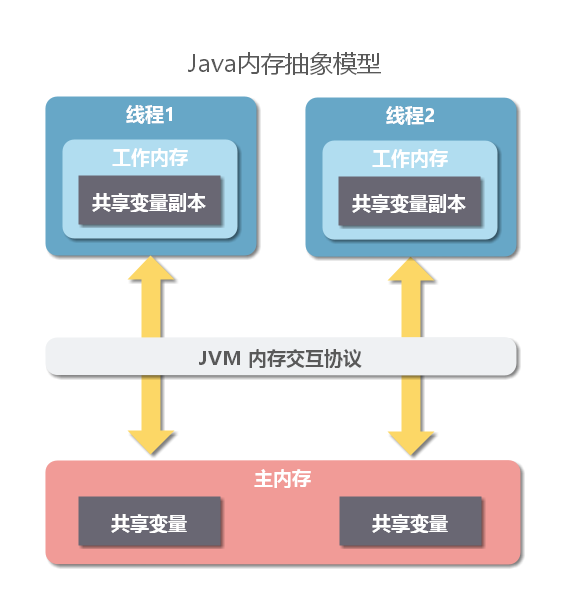
# #同步容器和并发容器
👉 参考阅读:Java 并发容器 (opens new window)
# #⭐ 同步容器
什么是同步容器?
有哪些常见同步容器?
它们是如何实现线程安全的?
同步容器真的线程安全吗?
类型
Vector`、`Stack`、`Hashtable作用 / 原理
同步容器的同步原理就是在方法上用 synchronized 修饰。 synchronized 可以保证在同一个时刻,只有一个线程可以执行某个方法或者某个代码块。
synchronized 的互斥同步会产生阻塞和唤醒线程的开销。显然,这种方式比没有使用 synchronized 的容器性能要差。
线程安全
同步容器真的绝对安全吗?
其实也未必。在做复合操作(非原子操作)时,仍然需要加锁来保护。常见复合操作如下:
- 迭代:反复访问元素,直到遍历完全部元素;
- 跳转:根据指定顺序寻找当前元素的下一个(下 n 个)元素;
- 条件运算:例如若没有则添加等;
# #⭐⭐⭐ ConcurrentHashMap
请描述 ConcurrentHashMap 的实现原理?
ConcurrentHashMap 为什么放弃了分段锁?
基础数据结构原理和 HashMap 一样,JDK 1.7 采用 数组+单链表;JDK 1.8 采用数组+单链表+红黑树。
并发安全特性的实现:
JDK 1.7:
- 使用分段锁,设计思路是缩小锁粒度,提高并发吞吐。
- 写数据时,会使用可重入锁去锁住分段(segment)。
JDK 1.8:
-
取消分段锁,直接采用
transient volatile HashEntry<K,V>[] table保存数据,采用 table 数组元素作为锁,从而实现了对每一行数据进行加锁,进一步减少并发冲突的概率。 -
写数据时,使用是 CAS +
synchronized
。
- 根据 key 计算出 hashcode 。
- 判断是否需要进行初始化。
- `f` 即为当前 key 定位出的 Node,如果为空表示当前位置可以写入数据,利用 CAS 尝试写入,失败则自旋保证成功。
- 如果当前位置的 `hashcode == MOVED == -1`,则需要进行扩容。
- 如果都不满足,则利用 synchronized 锁写入数据。
- 如果数量大于 `TREEIFY_THRESHOLD` 则要转换为红黑树。
# #⭐⭐ CopyOnWriteArrayList
CopyOnWriteArrayList 的作用?
CopyOnWriteArrayList 的原理?
作用
CopyOnWrite 字面意思为写入时复制。CopyOnWriteArrayList 是线程安全的 ArrayList。
原理
- 在
CopyOnWriteAarrayList中,读操作不同步,因为它们在内部数组的快照上工作,所以多个迭代器可以同时遍历而不会相互阻塞(1,2,4)。 - 所有的写操作都是同步的。他们在备份数组(3)的副本上工作。写操作完成后,后备阵列将被替换为复制的阵列,并释放锁定。支持数组变得易变,所以替换数组的调用是原子(5)。
- 写操作后创建的迭代器将能够看到修改的结构(6,7)。
- 写时复制集合返回的迭代器不会抛出 ConcurrentModificationException,因为它们在数组的快照上工作,并且无论后续的修改(2,4)如何,都会像迭代器创建时那样完全返回元素。
# #并发锁
👉 参考阅读:Java 并发锁 (opens new window)
# #⭐⭐ 锁类型
Java 中有哪些锁?
这些锁有什么特性?
可重入锁
-
ReentrantLock、ReentrantReadWriteLock是可重入锁。这点,从其命名也不难看出。 -
synchronized也是一个可重入锁。
公平锁与非公平锁
-
synchronized只支持非公平锁。 -
ReentrantLock、ReentrantReadWriteLock,默认是非公平锁,但支持公平锁。
独享锁与共享锁
-
synchronized、ReentrantLock只支持独享锁。 -
ReentrantReadWriteLock其写锁是独享锁,其读锁是共享锁。读锁是共享锁使得并发读是非常高效的,读写,写读 ,写写的过程是互斥的。
悲观锁与乐观锁
- 悲观锁在 Java 中的应用就是通过使用
synchronized和Lock显示加锁来进行互斥同步,这是一种阻塞同步。 - 乐观锁在 Java 中的应用就是采用 CAS 机制(CAS 操作通过
Unsafe类提供,但这个类不直接暴露为 API,所以都是间接使用,如各种原子类)。
偏向锁、轻量级锁、重量级锁
Java 1.6 以前,重量级锁一般指的是 synchronized ,而轻量级锁指的是 volatile 。
Java 1.6 以后,针对 synchronized 做了大量优化,引入 4 种锁状态: 无锁状态、偏向锁、轻量级锁和重量级锁。锁可以单向的从偏向锁升级到轻量级锁,再从轻量级锁升级到重量级锁 。
分段锁
分段锁其实是一种锁的设计,并不是具体的一种锁。典型:JDK1.7 之前的 ConcurrentHashMap
显示锁和内置锁
- 内置锁:
synchronized - 显示锁:
ReentrantLock、ReentrantReadWriteLock等。
# #⭐⭐ AQS
什么是 AQS?
AQS 的作用是什么?
AQS 的原理?
作用
AbstractQueuedSynchronizer (简称 AQS)是队列同步器,顾名思义,其主要作用是处理同步。它是并发锁和很多同步工具类的实现基石(如 ReentrantLock 、 ReentrantReadWriteLock 、 Semaphore 等)。
AQS 提供了对独享锁与共享锁的支持。
原理
(1)数据结构
-
state
volatile \- AQS 使用一个整型的 变量来 维护同步状态 。 - 这个整数状态的意义由子类来赋予,如`ReentrantLock` 中该状态值表示所有者线程已经重复获取该锁的次数,`Semaphore` 中该状态值表示剩余的许可数量。 - `head` 和 `tail` - AQS **维护了一个 `Node` 类型(AQS 的内部类)的双链表来完成同步状态的管理**。这个双链表是一个双向的 FIFO 队列,通过 `head` 和 `tail` 指针进行访问。当 **有线程获取锁失败后,就被添加到队列末尾**。 (2)获取独占锁 AQS 中使用 `acquire(int arg)` 方法获取独占锁,其大致流程如下: 1. 先尝试获取同步状态,如果获取同步状态成功,则结束方法,直接返回。 2. 如果获取同步状态不成功,AQS 会不断尝试利用 CAS 操作将当前线程插入等待同步队列的队尾,直到成功为止。 3. 接着,不断尝试为等待队列中的线程节点获取独占锁。 (3)释放独占锁 AQS 中使用 `release(int arg)` 方法释放独占锁,其大致流程如下: 1. 先尝试获取解锁线程的同步状态,如果获取同步状态不成功,则结束方法,直接返回。 2. 如果获取同步状态成功,AQS 会尝试唤醒当前线程节点的后继节点。 (4)获取共享锁 AQS 中使用 `acquireShared(int arg)` 方法获取共享锁。 `acquireShared` 方法和 `acquire` 方法的逻辑很相似,区别仅在于自旋的条件以及节点出队的操作有所不同。 成功获得共享锁的条件如下: - `tryAcquireShared(arg)` 返回值大于等于 0 (这意味着共享锁的 permit 还没有用完)。 - 当前节点的前驱节点是头结点。 (5)释放共享锁 AQS 中使用 `releaseShared(int arg)` 方法释放共享锁。 `releaseShared` 首先会尝试释放同步状态,如果成功,则解锁一个或多个后继线程节点。释放共享锁和释放独享锁流程大体相似,区别在于: 对于独享模式,如果需要 SIGNAL,释放仅相当于调用头节点的 `unparkSuccessor`。 #### [#](https://dunwu.github.io/javacore/java-interview.html#⭐⭐-reentrantlock)⭐⭐ ReentrantLock > 什么是 ReentrantLock? > > 什么是可重入锁? > > ReentrantLock 有什么用? > > ReentrantLock 原理? **作用** **`ReentrantLock` 提供了一组无条件的、可轮询的、定时的以及可中断的锁操作** `ReentrantLock` 的特性如下: - **`ReentrantLock` 提供了与 `synchronized` 相同的互斥性、内存可见性和可重入性**。 - `ReentrantLock` 支持公平锁和非公平锁(默认)两种模式。 - ``` ReentrantLock
实现了
Lock
接口,支持了
synchronized
所不具备的
灵活性
。
- `synchronized` 无法中断一个正在等待获取锁的线程
- `synchronized` 无法在请求获取一个锁时无休止地等待
原理
ReentrantLock 基于其内部类 ReentrantLock.Sync 实现, Sync 继承自 AQS。它有两个子类:
ReentrantLock.FairSync- 公平锁。ReentrantLock.NonfairSync- 非公平锁。
本质上,就是基于 AQS 实现。
# #⭐ ReentrantReadWriteLock
ReentrantReadWriteLock 是什么?
ReentrantReadWriteLock 的作用?
ReentrantReadWriteLock 的原理?
作用
ReentrantReadWriteLock 是一个可重入的读写锁。 ReentrantReadWriteLock 维护了一对读写锁,将读写锁分开,有利于提高并发效率。
原理
ReentrantReadWriteLock 本质上也是基于 AQS 实现。有三个核心字段:
sync- 内部类ReentrantReadWriteLock.Sync对象。与ReentrantLock类似,它有两个子类:ReentrantReadWriteLock.FairSync和ReentrantReadWriteLock.NonfairSync,分别表示公平锁和非公平锁的实现。readerLock- 内部类ReentrantReadWriteLock.ReadLock对象,这是一把读锁。writerLock- 内部类ReentrantReadWriteLock.WriteLock对象,这是一把写锁。
# #⭐ Condition
Condition 有什么用?
使用 Lock 的线程,彼此如何通信?
作用
可以理解为,什么样的锁配什么样的钥匙。
内置锁( synchronized )配合内置条件队列( wait 、 notify 、 notifyAll ),显式锁( Lock )配合显式条件队列( Condition )。
# #⭐⭐ 死锁
如何避免死锁?
- 避免一个线程同时获取多个锁
- 避免一个线程在锁内同时占用多个资源,尽量保证每个锁只占用一个资源
- 尝试使用定时锁 lock.tryLock (timeout),避免锁一直不能释放
- 对于数据库锁,加锁和解锁必须在一个数据库连接中里,否则会出现解锁失败的情况。
# #原子变量类
👉 参考阅读:Java 原子类 (opens new window)
# #⭐ 原子类简介
为什么要用原子类?
用过哪些原子类?
作用
常规的锁( Lock 、 sychronized )由于是阻塞式的,势必影响并发吞吐量。
volatile 号称轻量级的锁,但不能保证原子性。
为了兼顾原子性和锁的性能问题,所以引入了原子类。
类型
原子变量类可以分为 4 组:
- 基本类型
AtomicBoolean- 布尔类型原子类AtomicInteger- 整型原子类AtomicLong- 长整型原子类
- 引用类型
AtomicReference- 引用类型原子类AtomicMarkableReference- 带有标记位的引用类型原子类AtomicStampedReference- 带有版本号的引用类型原子类
- 数组类型
AtomicIntegerArray- 整形数组原子类AtomicLongArray- 长整型数组原子类AtomicReferenceArray- 引用类型数组原子类
- 属性更新器类型
AtomicIntegerFieldUpdater- 整型字段的原子更新器。AtomicLongFieldUpdater- 长整型字段的原子更新器。AtomicReferenceFieldUpdater- 原子更新引用类型里的字段。
# #⭐ 原子类的原理
- 处理器实现原子操作:使用总线锁保证原子性,使用缓存锁保证原子性(修改内存地址,缓存一致性机制:阻止同时修改由 2 个以上的处理器缓存的内存区域数据)
- JAVA 实现原子操作:循环使用 CAS (自旋 CAS)实现原子操作
# #并发工具类
# #⭐ CountDownLatch
CountDownLatch 作用?
CountDownLatch 原理?
作用
字面意思为 递减计数锁。用于控制一个或者多个线程等待多个线程。
CountDownLatch 维护一个计数器 count,表示需要等待的事件数量。 countDown 方法递减计数器,表示有一个事件已经发生。调用 await 方法的线程会一直阻塞直到计数器为零,或者等待中的线程中断,或者等待超时。
原理
CountDownLatch 是基于 AQS ( AbstractQueuedSynchronizer ) 实现的。
# #⭐ CyclicBarrier
CyclicBarrier 有什么用?
CyclicBarrier 的原理是什么?
CyclicBarrier 和 CountDownLatch 有什么区别?
作用
字面意思是 循环栅栏。 CyclicBarrier 可以让一组线程等待至某个状态(遵循字面意思,不妨称这个状态为栅栏)之后再全部同时执行。之所以叫循环栅栏是因为:当所有等待线程都被释放以后, CyclicBarrier 可以被重用。
CyclicBarrier 维护一个计数器 count。每次执行 await 方法之后,count 加 1,直到计数器的值和设置的值相等,等待的所有线程才会继续执行。
原理
CyclicBarrier 是基于 ReentrantLock 和 Condition 实现的。
区别
CyclicBarrier 和 CountDownLatch 都可以用来让一组线程等待其它线程。与 CyclicBarrier 不同的是, CountdownLatch 不能重用。
# #⭐ Semaphore
Semaphore 作用?
作用
字面意思为 信号量。 Semaphore 用来控制同时访问某个特定资源的操作数量,或者同时执行某个指定操作的数量。
Semaphore 管理着一组虚拟的许可(permit),permit 的初始数量可通过构造方法来指定。每次执行 acquire 方法可以获取一个 permit,如果没有就等待;而 release 方法可以释放一个 permit。
Semaphore可以用于实现资源池,如数据库连接池。Semaphore可以用于将任何一种容器变成有界阻塞容器。
# #线程池
👉 参考阅读:Java 线程池 (opens new window)
# #⭐⭐ ThreadPoolExecutor
ThreadPoolExecutor有哪些参数,各自有什么用?
ThreadPoolExecutor工作原理?
原理
参数
java.uitl.concurrent.ThreadPoolExecutor 类是 Executor 框架中最核心的一个类。
ThreadPoolExecutor 有四个构造方法,前三个都是基于第四个实现。第四个构造方法定义如下:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {参数说明:
-
corePoolSize
execute \- 核心线程数量 。当有新任务通过 方法提交时 ,线程池会执行以下判断: - 如果运行的线程数少于 `corePoolSize`,则创建新线程来处理任务,即使线程池中的其他线程是空闲的。 - 如果线程池中的线程数量大于等于 `corePoolSize` 且小于 `maximumPoolSize`,则只有当 `workQueue` 满时才创建新的线程去处理任务; - 如果设置的 `corePoolSize` 和 `maximumPoolSize` 相同,则创建的线程池的大小是固定的。这时如果有新任务提交,若 `workQueue` 未满,则将请求放入 `workQueue` 中,等待有空闲的线程去从 `workQueue` 中取任务并处理; - 如果运行的线程数量大于等于 `maximumPoolSize`,这时如果 `workQueue` 已经满了,则使用 `handler` 所指定的策略来处理任务; - 所以,任务提交时,判断的顺序为 `corePoolSize` => `workQueue` => `maximumPoolSize`。 - ``` maximumPoolSize
\-
最大线程数量
。
- 如果队列满了,并且已创建的线程数小于最大线程数,则线程池会再创建新的线程执行任务。
- 值得注意的是:如果使用了无界的任务队列这个参数就没什么效果。
-
keepAliveTime: 线程保持活动的时间 。 - 当线程池中的线程数量大于 `corePoolSize` 的时候,如果这时没有新的任务提交,核心线程外的线程不会立即销毁,而是会等待,直到等待的时间超过了 `keepAliveTime`。 - 所以,如果任务很多,并且每个任务执行的时间比较短,可以调大这个时间,提高线程的利用率。 - `unit` - **`keepAliveTime` 的时间单位**。有 7 种取值。可选的单位有天(DAYS),小时(HOURS),分钟(MINUTES),毫秒(MILLISECONDS),微秒(MICROSECONDS, 千分之一毫秒)和毫微秒(NANOSECONDS, 千分之一微秒)。 - ``` workQueue
\-
等待执行的任务队列
。用于保存等待执行的任务的阻塞队列。 可以选择以下几个阻塞队列。
- ```
ArrayBlockingQueue
\-
有界阻塞队列
。
- 此队列是**基于数组的先进先出队列(FIFO)**。
- 此队列创建时必须指定大小。
- ```
LinkedBlockingQueue
\-
无界阻塞队列
。
- 此队列是**基于链表的先进先出队列(FIFO)**。
- 如果创建时没有指定此队列大小,则默认为 `Integer.MAX_VALUE`。
- 吞吐量通常要高于 `ArrayBlockingQueue`。
- 使用 `LinkedBlockingQueue` 意味着: `maximumPoolSize` 将不起作用,线程池能创建的最大线程数为 `corePoolSize`,因为任务等待队列是无界队列。
- `Executors.newFixedThreadPool` 使用了这个队列。
- ```
SynchronousQueue
```
\-
不会保存提交的任务,而是将直接新建一个线程来执行新来的任务
。
- 每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态。
- 吞吐量通常要高于 `LinkedBlockingQueue`。
- `Executors.newCachedThreadPool` 使用了这个队列。
- `PriorityBlockingQueue` - **具有优先级的无界阻塞队列**。
-
threadFactory- 线程工厂。可以通过线程工厂给每个创建出来的线程设置更有意义的名字。 -
handler- 饱和策略。它是 RejectedExecutionHandler 类型的变量。当队列和线程池都满了,说明线程池处于饱和状态,那么必须采取一种策略处理提交的新任务。线程池支持以下策略:AbortPolicy- 丢弃任务并抛出异常。这也是默认策略。DiscardPolicy- 丢弃任务,但不抛出异常。DiscardOldestPolicy- 丢弃队列最前面的任务,然后重新尝试执行任务(重复此过程)。CallerRunsPolicy- 只用调用者所在的线程来运行任务。- 如果以上策略都不能满足需要,也可以通过实现
RejectedExecutionHandler接口来定制处理策略。如记录日志或持久化不能处理的任务。
# #⭐ Executors
Executors 提供了哪些内置的线程池?
这些线程池各自有什么特性?适合用于什么场景?
Executors 为 Executor,ExecutorService,ScheduledExecutorService,ThreadFactory 和 Callable 类提供了一些工具方法。
(1)newSingleThreadExecutor
创建一个单线程的线程池。
只会创建唯一的工作线程来执行任务,保证所有任务按照指定顺序 (FIFO, LIFO, 优先级) 执行。 如果这个唯一的线程因为异常结束,那么会有一个新的线程来替代它 。
单工作线程最大的特点是:可保证顺序地执行各个任务。
(2)newFixedThreadPool
创建一个固定大小的线程池。
每次提交一个任务就会新创建一个工作线程,如果工作线程数量达到线程池最大线程数,则将提交的任务存入到阻塞队列中。
FixedThreadPool 是一个典型且优秀的线程池,它具有线程池提高程序效率和节省创建线程时所耗的开销的优点。但是,在线程池空闲时,即线程池中没有可运行任务时,它不会释放工作线程,还会占用一定的系统资源。
(3)newCachedThreadPool
创建一个可缓存的线程池。
- 如果线程池大小超过处理任务所需要的线程数,就会回收部分空闲的线程;
- 如果长时间没有往线程池中提交任务,即如果工作线程空闲了指定的时间(默认为 1 分钟),则该工作线程将自动终止。终止后,如果你又提交了新的任务,则线程池重新创建一个工作线程。
- 此线程池不会对线程池大小做限制,线程池大小完全依赖于操作系统(或者说 JVM)能够创建的最大线程大小。 因此,使用
CachedThreadPool时,一定要注意控制任务的数量,否则,由于大量线程同时运行,很有会造成系统瘫痪。
(4)newScheduleThreadPool
创建一个大小无限的线程池。此线程池支持定时以及周期性执行任务的需求。






